Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga más información sobre cómo iniciar una nueva evaluación gratuita.
En este tutorial, usará Azure PowerShell para crear una canalización de Data Factory que copie los datos de una base de datos de SQL Server a Azure Blob Storage. Cree y use una instancia de Integration Runtime autohospedado, que mueve los datos entre almacenes locales y en la nube.
Nota
En este artículo no se ofrece una introducción detallada al servicio Data Factory. Para más información, consulte Introducción a Azure Data Factory.
En este tutorial, realizará los siguientes pasos:
- Creación de una factoría de datos.
- Cree una instancia de Integration Runtime autohospedada.
- Creación de los servicios vinculados SQL Server y Azure Storage.
- Creación de los conjuntos de datos de SQL Server y Azure Blob.
- Creación de una canalización con una actividad de copia para mover los datos.
- Inicio de la ejecución de una canalización.
- Supervisión de la ejecución de la canalización
Requisitos previos
Suscripción de Azure
Antes de empezar, si no tiene una suscripción a Azure, cree una cuenta gratuita.
Roles de Azure
Para crear instancias de Data Factory, la cuenta de usuario que use para iniciar sesión en Azure debe tener un rol Colaborador o Propietario asignado o ser administrador de la suscripción de Azure.
Para ver los permisos que tiene en la suscripción, vaya a Azure Portal, seleccione su nombre de usuario en la esquina superior derecha y, después, seleccione Permisos. Si tiene acceso a varias suscripciones, elija la correspondiente. Para ver instrucciones de ejemplo sobre cómo agregar un usuario a un rol, consulte el artículo Asignación de roles de Azure mediante Azure Portal.
SQL Server 2014, 2016 y 2017
En este tutorial, usará una base de datos de SQL Server como almacén de datos de origen. La canalización de Data Factory que crea en este tutorial copia los datos de esta base de datos de SQL Server (origen) a Azure Blob Storage (receptor). Luego, cree una tabla denominada emp en la base de datos de SQL Server e inserte un par de entradas de ejemplo en la tabla.
Inicie SQL Server Management Studio. Si no está instalada en su equipo, vaya a Descarga de SQL Server Management Studio (SSMS).
Conéctese a una instancia de SQL Server con sus credenciales.
Cree una base de datos de ejemplo. En la vista de árbol, haga clic con el botón derecho en Bases de datos y, luego, seleccione Nueva base de datos.
En el cuadro de diálogo Nueva base de datos, escriba el nombre de la base de datos y haga clic en Aceptar.
Para crear la tabla emp e insertar en ella algunos datos de ejemplo, ejecute el siguiente script de consulta en la base de datos. En la vista de árbol, haga clic con el botón derecho en la base de datos que ha creado y, después, haga clic en Nueva consulta.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Cuenta de Azure Storage
En esta guía de inicio rápido, use una cuenta de Azure Storage (en concreto Blob Storage) de uso general como almacén de datos de destino o receptor en este tutorial. Si no dispone de una cuenta de Azure Storage de uso general, consulte Creación de una cuenta de almacenamiento. La canalización de Data Factory que crea en este tutorial copia los datos de la base de datos de SQL Server (origen) a esta instancia de Azure Blob Storage (receptor).
Obtener un nombre y una clave de cuenta de Storage
En este tutorial, use el nombre y la clave de su cuenta de Azure Storage. Para obtener el nombre y la clave de una cuenta de almacenamiento, siga estos pasos:
Inicie sesión en Azure Portal con el nombre de usuario y la contraseña de Azure.
En el panel izquierdo, seleccione Más servicios, use la palabra clave Almacenamiento para realizar el filtro y, luego, seleccione Cuentas de almacenamiento.
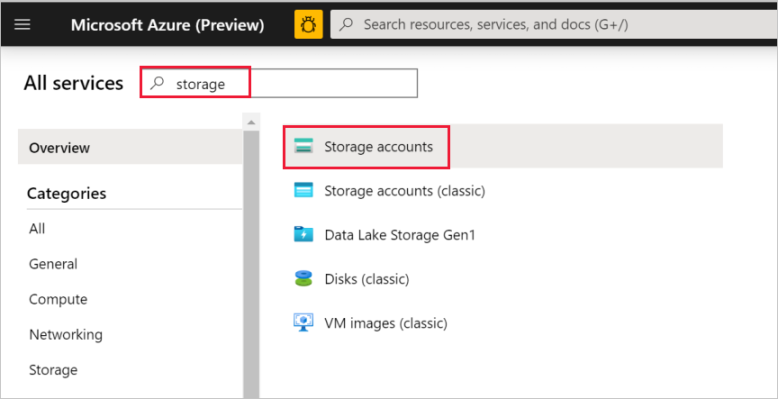
En la lista de cuentas de almacenamiento, filtre por su cuenta de almacenamiento (si fuera necesario) y, después, seleccione su cuenta de almacenamiento.
En la ventana Cuenta de almacenamiento, seleccione Claves de acceso.
En los cuadros Nombre de la cuenta de almacenamiento y key1, copie los valores y péguelos en el Bloc de notas, u otro editor, para su uso posterior en el tutorial.
Creación del contenedor adftutorial
En esta sección se crea un contenedor de blobs denominado adftutorial en la instancia de Azure Blob Storage.
En la ventana Cuenta de almacenamiento, cambie a Información general y, después, seleccione Blobs.
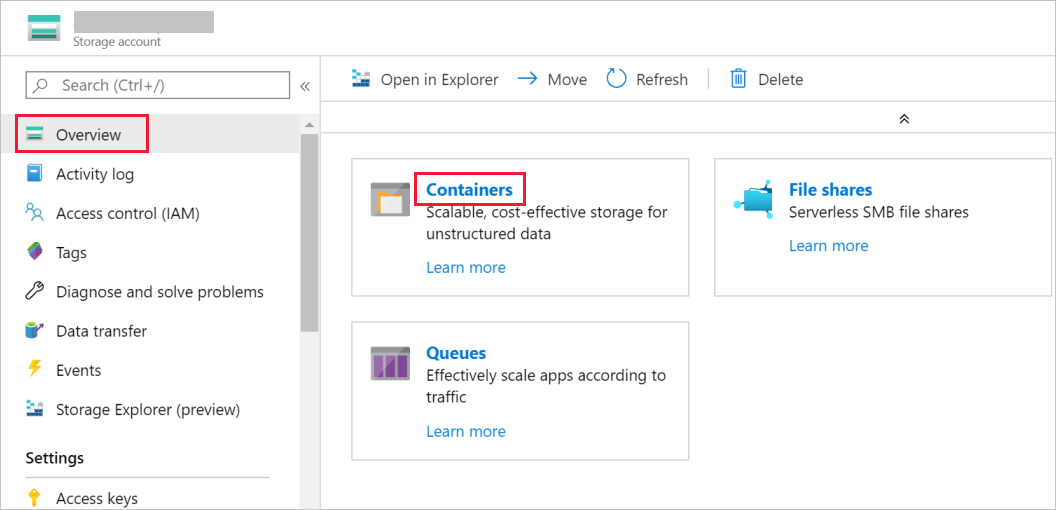
En la ventana Blob service, seleccione Contenedor.
En la ventana Nuevo contenedor, en el cuadro Nombre, escriba adftutorialy, después, seleccione Aceptar.
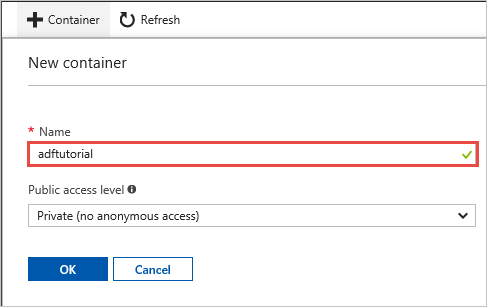
En la lista de contenedores, seleccione adftutorial.
Mantenga abierta la ventana contenedor de adftutorial. Úselo para comprobar la salida al final de este tutorial. Data Factory crea automáticamente la carpeta de salida de este contenedor, por lo que no es necesario que el usuario la cree.
Windows PowerShell
Instalar Azure Powershell
Nota
Se recomienda usar el módulo Azure Az de PowerShell para interactuar con Azure. Para comenzar, consulte Instalación de Azure PowerShell. Para más información sobre cómo migrar al módulo Az de PowerShell, consulte Migración de Azure PowerShell de AzureRM a Az.
Si no está en el equipo, instale la versión más reciente de Azure PowerShell. Para obtener instrucciones detalladas, consulte Instalación y configuración de Azure PowerShell.
Inicio de sesión en PowerShell
Inicie PowerShell en su equipo y manténgalo abierto hasta que finalice este tutorial de inicio rápido. Si lo cierra y vuelve a abrirlo, tendrá que volver a ejecutar estos comandos.
Ejecute el siguiente comando y escriba el nombre de usuario y la contraseña de Azure que utiliza para iniciar sesión en Azure Portal:
Connect-AzAccountSi tiene varias suscripciones de Azure, ejecute el siguiente comando para seleccionar la suscripción con la que desea trabajar. Reemplace SubscriptionId con el identificador de la suscripción de Azure:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"
Crear una factoría de datos
Defina una variable para el nombre del grupo de recursos que usará en los comandos de PowerShell más adelante. Copie el comando siguiente en PowerShell, especifique el nombre del grupo de recursos de Azure (entre comillas dobles; por ejemplo,
"adfrg") y ejecute el comando.$resourceGroupName = "ADFTutorialResourceGroup"Para crear el grupo de recursos de Azure, ejecute el comando siguiente:
New-AzResourceGroup $resourceGroupName -location 'East US'Si el grupo de recursos ya existe, puede que no desee sobrescribirlo. Asigne otro valor a la variable
$resourceGroupNamey ejecute el comando de nuevo.Defina una variable para el nombre de la factoría de datos que pueda usar en los comandos de PowerShell más adelante. El nombre deben comenzar por una letra o un número y solo pueden contener letras, números y el carácter de guion (-).
Importante
Actualice el nombre de la factoría de datos por otro que sea globalmente único. Un ejemplo es ADFTutorialFactorySP1127.
$dataFactoryName = "ADFTutorialFactory"Defina una variable para la ubicación de la factoría de datos:
$location = "East US"Para crear la factoría de datos, ejecute el siguiente cmdlet
Set-AzDataFactoryV2:Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
Nota
- El nombre de la factoría de datos debe ser globalmente único. Si recibe el siguiente error, cambie el nombre y vuelva a intentarlo.
The specified data factory name 'ADFv2TutorialDataFactory' is already in use. Data factory names must be globally unique. - Para crear instancias de Data Factory, a la cuenta de usuario que use para iniciar sesión en Azure debe se le deben asignar los roles colaborador o propietario, o bien debe de ser de un administrador de la suscripción a Azure.
- Para una lista de las regiones de Azure en las que Data Factory está disponible actualmente, seleccione las regiones que le interesen en la página siguiente y expanda Análisis para poder encontrar Data Factory: Productos disponibles por región. Los almacenes de datos (Azure Storage, Azure SQL Database, etc.) y los procesos (Azure HDInsight, etc.) que usa la factoría de datos pueden encontrarse en otras regiones.
Creación de una instancia de Integration Runtime autohospedada
En esta sección se crea una instancia de Integration Runtime autohospedada y se asocia con un equipo local con la base de datos de SQL Server. Integration Runtime autohospedado es el componente que copia los datos de la base de datos de SQL Server del equipo a Azure Blob Storage.
Cree una variable para el nombre del runtime de integración. Use un nombre único y anótelo. Lo usará más adelante en este tutorial.
$integrationRuntimeName = "ADFTutorialIR"Cree una instancia de Integration Runtime autohospedada.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $integrationRuntimeName -Type SelfHosted -Description "selfhosted IR description"Este es la salida de ejemplo:
Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Para recuperar el estado de la instancia de Integration Runtime creada, ejecute el siguiente comando:
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -StatusEste es la salida de ejemplo:
State : NeedRegistration Version : CreateTime : 9/10/2019 3:24:09 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {eu.frontend.clouddatahub.net} Nodes : {} Links : {} Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Description : selfhosted IR description Id : /subscriptions/<subscription ID>/resourceGroups/<resourceGroupName>/providers/Microsoft.DataFactory/factories/<dataFactoryName>/integrationruntimes/<integrationRuntimeName>Para recuperar las claves de autenticación para registrar la instancia de Integration Runtime autohospedado con el servicio Data Factory en la nube, ejecute el siguiente comando. Copie una de las claves (sin las comillas dobles) para registrar la instancia de Integration Runtime autohospedado que instalará en el equipo en el paso siguiente.
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-JsonEste es la salida de ejemplo:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }
Instalación de Integration Runtime
Descargue Microsoft Integration Runtime en un equipo Windows local y ejecute la instalación.
En el Asistente para la instalación de Microsoft Integration Runtime, haga clic en Siguiente.
En la ventana Contrato de licencia para el usuario final, acepte los términos del Contrato de licencia y haga clic en Siguiente.
En la ventana Carpeta de destino, seleccione Siguiente.
En la ventana Preparado para instalar Microsoft Integration Runtime, haga clic en Instalar.
En Ha completado el Asistente para la instalación de Microsoft Integration Runtime Setup, seleccione Finalizar.
En la ventana Registro de Integration Runtime (autohospedado) , pegue la clave que guardó en la sección anterior y haga clic en Registrar.
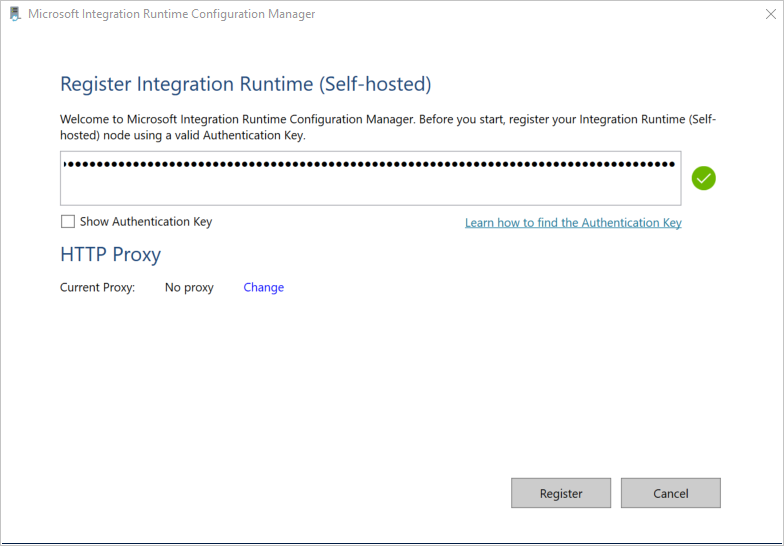
En la ventana Nuevo nodo de Integration Runtime (autohospedado) , seleccione Finalizar.
Cuando Integration Runtime autohospedado se haya registrado correctamente, se muestra el siguiente mensaje:
En la ventana Registro de Integration Runtime (autohospedado) , haga clic en Iniciar Configuration Manager.
Cuando el nodo se conecte al servicio en la nube, se mostrará el servicio en la nube:
Para probar la conectividad a la base de datos de SQL Server, siga estos pasos:
a. En la ventana Configuration Manager, cambie a la pestaña Diagnósticos.
b. En el cuadro Tipo de origen de datos, seleccione SqlServer.
c. Escriba el nombre del servidor.
d. Escriba el nombre de la base de datos.
e. Seleccione el modo de autenticación.
f. Escriba el nombre de usuario.
g. Escriba la contraseña asociada con el nombre de usuario.
h. Para confirmar que Integration Runtime puede conectarse a SQL Server, seleccione Probar.
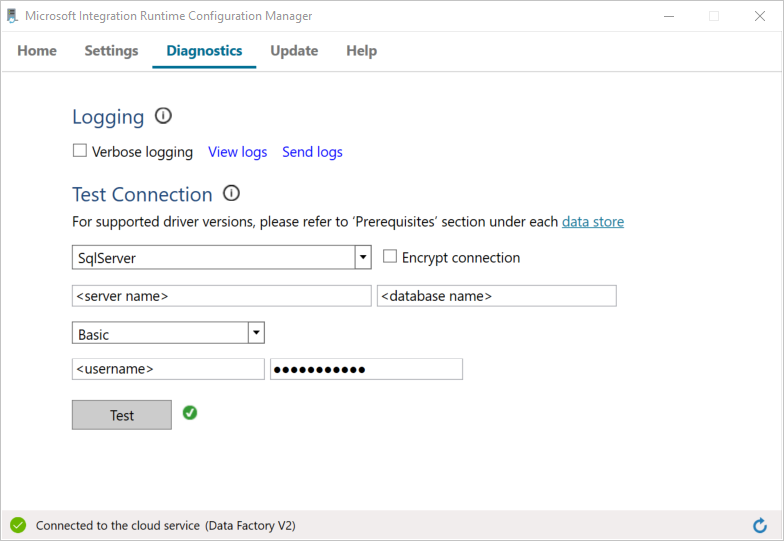
Si la conexión se ha realizado correctamente, verá una marca de verificación verde. De lo contrario, recibirá un mensaje de error asociado al error. Solucione los problemas y asegúrese de que Integration Runtime puede conectarse a la instancia de SQL Server.
Anote todos los valores anteriores, ya que los usará más adelante en este mismo tutorial.
Crear servicios vinculados
Para vincular los almacenes de datos y los servicios de proceso a la factoría de datos, cree servicios vinculados en una factoría de datos. En este tutorial, vincula su cuenta de Azure Storage y una instancia de SQL Server al almacén de datos. Los servicios vinculados tienen la información de conexión que usa el servicio Data Factory en el entorno de tiempo de ejecución para conectarse a ellos.
Creación de un servicio vinculado a Azure Storage (destino/receptor)
En este paso, vinculará su cuenta de Azure Storage a la factoría de datos.
Cree un archivo JSON llamado AzureStorageLinkedService.json en la carpeta C:\ADFv2Tutorial con el siguiente código. Si la carpeta ADFv2Tutorial no existe, créela.
Importante
Antes de guardar el archivo, sustituya <accountName> y <accountKey> por el nombre y la clave de su cuenta de Azure Storage. Los anotó en la sección Requisitos previos.
{ "name": "AzureStorageLinkedService", "properties": { "annotations": [], "type": "AzureBlobStorage", "typeProperties": { "connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountName>;AccountKey=<accountKey>;EndpointSuffix=core.windows.net" } } }En PowerShell, cambie a la carpeta C:\ADFv2Tutorial.
Set-Location 'C:\ADFv2Tutorial'Para crear el servicio vinculado, AzureStorageLinkedService, ejecute el siguiente cmdlet
Set-AzDataFactoryV2LinkedService:Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "AzureStorageLinkedService" -File ".\AzureStorageLinkedService.json"Este es una salida de ejemplo:
LinkedServiceName : AzureStorageLinkedService ResourceGroupName : <resourceGroup name> DataFactoryName : <dataFactory name> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureBlobStorageLinkedServiceSi recibe un error de "archivo no encontrado", confirme que existe el archivo, para lo que debe ejecutar el comando
dir. Si el nombre del archivo tiene la extensión .txt (por ejemplo, AzureStorageLinkedService.json.txt), quítela y vuelva a ejecutar el comando de PowerShell.
Creación y cifrado de un servicio vinculado de SQL Server (origen)
En este paso, vinculará la instancia de SQL Server a la factoría de datos.
Cree un archivo JSON llamado SqlServerLinkedService.json en la carpeta C:\ADFv2Tutorial mediante el siguiente código:
Importante
Seleccione la sección que se basa en la autenticación que usa para conectarse a SQL Server.
Uso de la autenticación de SQL (sa):
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<serverName>;initial catalog=<databaseName>;user id=<userName>;password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name> ", "type":"IntegrationRuntimeReference" } } }Con autenticación de Windows:
{ "name":"SqlServerLinkedService", "type":"Microsoft.DataFactory/factories/linkedservices", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<serverName>;initial catalog=<databaseName>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }Importante
- Seleccione la sección que se basa en la autenticación que usa para conectarse a su instancia de SQL Server.
- Reemplace <integration runtime name> por el nombre del entorno de ejecución de integración.
- Antes de guardar el archivo, reemplace <servername>, <databasename>, <username> y <password> por los valores de su instancia de SQL Server.
- Si necesita usar una barra diagonal inversa (\) en la cuenta del usuario o en el nombre del servidor, utilice el carácter de escape (\) antes. Por ejemplo, use mydomain\\myuser.
Para cifrar los datos confidenciales (nombre de usuario, contraseña, etc.), ejecute el cmdlet
New-AzDataFactoryV2LinkedServiceEncryptedCredential.
Este cifrado que las credenciales se cifran mediante la API de protección de datos (DPAPI). Las credenciales cifradas se almacenan de manera local en el nodo de Integration Runtime autohospedado (máquina local). La carga de salida se puede redirigir a otro archivo JSON (en este caso, encryptedLinkedService.json) que contiene las credenciales cifradas.New-AzDataFactoryV2LinkedServiceEncryptedCredential -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -IntegrationRuntimeName $integrationRuntimeName -File ".\SQLServerLinkedService.json" > encryptedSQLServerLinkedService.jsonEjecute el comando siguiente, que crea EncryptedSqlServerLinkedService:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $ResourceGroupName -Name "EncryptedSqlServerLinkedService" -File ".\encryptedSqlServerLinkedService.json"
Creación de conjuntos de datos
En este paso, crea conjuntos de datos de entrada y salida. Estos representan los datos de entrada y de salida para la operación de copia, en la que se copian datos de la base de datos de SQL Server a Azure Blob Storage.
Creación de un conjunto de datos para la base de datos de origen SQL Server
En este paso, defina un conjunto de datos que represente los datos de la instancia de la base de datos de SQL Server. El conjunto de datos es del tipo SqlServerTable. Hace referencia al servicio vinculado de SQL Server que creó en el paso anterior. El servicio vinculado tiene la información de conexión que el servicio Data Factory usa para conectarse a su instancia de SQL Server en el runtime. Este conjunto de datos especifica la tabla SQL de la base de datos que contiene los datos. En este tutorial, la tabla emp contiene los datos de origen.
Cree un archivo JSON denominado SqlServerDataset.json en la carpeta C:\ADFv2Tutorial con el siguiente código:
{ "name":"SqlServerDataset", "properties":{ "linkedServiceName":{ "referenceName":"EncryptedSqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ], "typeProperties":{ "schema":"dbo", "table":"emp" } } }Para crear el conjunto de datos SqlServerDataset, ejecute el cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerDataset" -File ".\SqlServerDataset.json"Este es la salida de ejemplo:
DatasetName : SqlServerDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
Creación de un conjunto de datos para Azure Blob Storage (receptor)
En este paso, se define un conjunto de datos que representa los datos que se van a copiar a Azure Blob Storage. El conjunto de datos es del tipo AzureBlob. Hace referencia al servicio vinculado Azure Storage que creó anteriormente en este tutorial.
El servicio vinculado tiene la información de conexión que Data Factory usa en el runtime para conectarse a su cuenta de Azure Storage. Este conjunto de datos especifica la carpeta del almacenamiento de Azure a la que se copian los datos desde la base de datos de SQL Server. En este tutorial, la carpeta es: adftutorial/fromonprem, donde adftutorial es el contenedor de blobs y fromonprem es la carpeta.
Cree un archivo JSON denominado AzureBlobDataset.json en la carpeta C:\ADFv2Tutorial con el siguiente código:
{ "name":"AzureBlobDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureStorageLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"DelimitedText", "typeProperties":{ "location":{ "type":"AzureBlobStorageLocation", "folderPath":"fromonprem", "container":"adftutorial" }, "columnDelimiter":",", "escapeChar":"\\", "quoteChar":"\"" }, "schema":[ ] }, "type":"Microsoft.DataFactory/factories/datasets" }Para crear el conjunto de datos AzureBlobDataset, ejecute el cmdlet
Set-AzDataFactoryV2Dataset.Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureBlobDataset" -File ".\AzureBlobDataset.json"Este es la salida de ejemplo:
DatasetName : AzureBlobDataset ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.DelimitedTextDataset
Crear una canalización
En este tutorial, creará una canalización con una actividad de copia. La actividad de copia usa SqlServerDataset como el conjunto de datos de entrada y AzureBlobDataset como conjunto de datos de salida. El tipo de origen se establece en SqlSource y el tipo de receptor en BlobSink.
Cree un archivo JSON denominado SqlServerToBlobPipeline.json en la carpeta C:\ADFv2Tutorial con el siguiente código:
{ "name":"SqlServerToBlobPipeline", "properties":{ "activities":[ { "name":"CopySqlServerToAzureBlobActivity", "type":"Copy", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource" }, "sink":{ "type":"DelimitedTextSink", "storeSettings":{ "type":"AzureBlobStorageWriteSettings" }, "formatSettings":{ "type":"DelimitedTextWriteSettings", "quoteAllText":true, "fileExtension":".txt" } }, "enableStaging":false }, "inputs":[ { "referenceName":"SqlServerDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"AzureBlobDataset", "type":"DatasetReference" } ] } ], "annotations":[ ] } }Para crear la canalización SqlServerToBlobPipeline, ejecute el cmdlet
Set-AzDataFactoryV2Pipeline.Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SQLServerToBlobPipeline" -File ".\SQLServerToBlobPipeline.json"Este es la salida de ejemplo:
PipelineName : SQLServerToBlobPipeline ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> Activities : {CopySqlServerToAzureBlobActivity} Parameters :
Creación de una ejecución de canalización
Inicie la ejecución de la canalización SQLServerToBlobPipeline y capture el identificador de dicha ejecución para poder supervisarla en el futuro.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName 'SQLServerToBlobPipeline'
Supervisión de la ejecución de la canalización
Para comprobar continuamente el estado de ejecución de la canalización SQLServerToBlobPipeline, ejecute el siguiente script en PowerShell e imprima el resultado final:
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" Start-Sleep -Seconds 30 } else { Write-Host "Pipeline 'SQLServerToBlobPipeline' run finished. Result:" -foregroundcolor "Yellow" $result break } }Este es el resultado de la ejecución de ejemplo:
ResourceGroupName : <resourceGroupName> DataFactoryName : <dataFactoryName> ActivityRunId : 24af7cf6-efca-4a95-931d-067c5c921c25 ActivityName : CopySqlServerToAzureBlobActivity ActivityType : Copy PipelineRunId : 7b538846-fd4e-409c-99ef-2475329f5729 PipelineName : SQLServerToBlobPipeline Input : {source, sink, enableStaging} Output : {dataRead, dataWritten, filesWritten, sourcePeakConnections...} LinkedServiceName : ActivityRunStart : 9/11/2019 7:10:37 AM ActivityRunEnd : 9/11/2019 7:10:58 AM DurationInMs : 21094 Status : Succeeded Error : {errorCode, message, failureType, target} AdditionalProperties : {[retryAttempt, ], [iterationHash, ], [userProperties, {}], [recoveryStatus, None]...}Mediante la ejecución del comando siguiente puede obtener el identificador de la ejecución de la canalización SQLServerToBlobPipeline y comprobar el resultado detallado de la ejecución de la actividad:
Write-Host "Pipeline 'SQLServerToBlobPipeline' run result:" -foregroundcolor "Yellow" ($result | Where-Object {$_.ActivityName -eq "CopySqlServerToAzureBlobActivity"}).Output.ToString()Este es el resultado de la ejecución de ejemplo:
{ "dataRead":36, "dataWritten":32, "filesWritten":1, "sourcePeakConnections":1, "sinkPeakConnections":1, "rowsRead":2, "rowsCopied":2, "copyDuration":18, "throughput":0.01, "errors":[ ], "effectiveIntegrationRuntime":"ADFTutorialIR", "usedParallelCopies":1, "executionDetails":[ { "source":{ "type":"SqlServer" }, "sink":{ "type":"AzureBlobStorage", "region":"CentralUS" }, "status":"Succeeded", "start":"2019-09-11T07:10:38.2342905Z", "duration":18, "usedParallelCopies":1, "detailedDurations":{ "queuingDuration":6, "timeToFirstByte":0, "transferDuration":5 } } ] }
Comprobación del resultado
La canalización automáticamente la carpeta de salida fromonprem en el contenedor de blobs adftutorial. Confirme que ve el archivo dbo.emp.txt en la carpeta de salida.
En Azure Portal, en la ventana Contenedor adftutorial, seleccione Actualizar para ver la carpeta de salida.
Seleccione
fromonpremen la lista de carpetas.Confirme que ve un archivo denominado
dbo.emp.txt.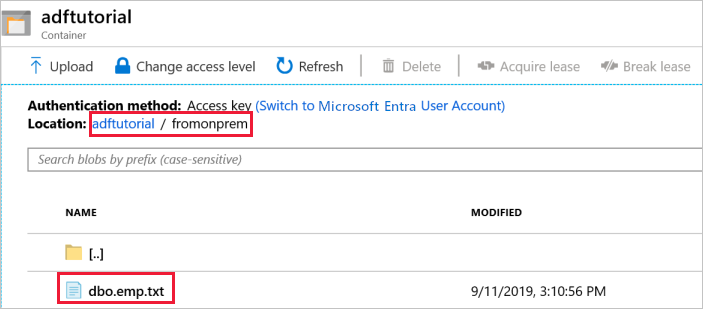
Contenido relacionado
La canalización de este ejemplo copia los datos de una ubicación a otra en Azure Blob Storage. Ha aprendido a:
- Creación de una factoría de datos.
- Cree una instancia de Integration Runtime autohospedada.
- Creación de los servicios vinculados SQL Server y Azure Storage.
- Creación de los conjuntos de datos de SQL Server y Azure Blob.
- Creación de una canalización con una actividad de copia para mover los datos.
- Inicio de la ejecución de una canalización.
- Supervisión de la ejecución de la canalización
Para ver una lista de los almacenes de datos compatibles con Data Factory, consulte los almacenes de datos disponibles.
Para obtener información acerca de cómo copiar datos de forma masiva de un origen a un destino, pase al tutorial siguiente: