Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta documentación se ha retirado y es posible que no se actualice.
El paso a través de credenciales está en desuso a partir de Databricks Runtime 15.0 y se quitará en futuras versiones de Databricks Runtime. Databricks recomienda actualizar al catálogo de Unity. Unity Catalog simplifica la seguridad y la gobernanza de los datos al proporcionar un lugar central para administrar y auditar el acceso a los datos en varias áreas de trabajo de la cuenta. Consulte ¿Qué es Unity Catalog?
Para mejorar la seguridad y la posición de gobernanza, póngase en contacto con el representante de Databricks para deshabilitar el acceso directo de credenciales en la cuenta de Azure Databricks.
Nota:
Este artículo contiene referencias al término lista de permitidos, un término que Azure Databricks no usa. Cuando se elimine el término del software, se eliminará también de este artículo.
Puede autenticarse automáticamente en ADLS desde clústeres de Azure Databricks mediante la misma identidad de Id. de Entra de Microsoft que se usa para iniciar sesión en Azure Databricks. Al habilitar el paso directo de credenciales de Azure Data Lake Storage para el clúster, los comandos que se ejecutan en ese clúster pueden leer y escribir datos en Azure Data Lake Storage sin necesidad de configurar credenciales de entidad de servicio para acceder al almacenamiento.
El acceso directo de credenciales de Azure Data Lake Storage solo se admite con Azure Data Lake Storage. Azure Blob Storage no admite el paso de credenciales.
En este artículo se describe:
- Habilitación del paso de credenciales para clústeres estándar y de alta simultaneidad.
- Configuración del paso de credenciales e inicialización de recursos de almacenamiento en cuentas de ADLS.
- Acceso a recursos de ADLS directamente cuando se habilita el paso de credenciales.
- Acceso a recursos de ADLS mediante un punto de montaje cuando se habilita el paso de credenciales.
- Características y limitaciones admitidas al usar el paso de credenciales.
Requisitos
- Plan Premium. Consulte Actualización o degradación de un área de trabajo de Azure Databricks para más información sobre cómo actualizar un plan estándar a un plan Premium.
- Una cuenta de almacenamiento de Azure Data Lake Storage. Las cuentas de almacenamiento de Azure Data Lake Storage deben utilizar un espacio de nombres jerárquico para posibilitar el paso de credenciales mediante Azure Data Lake Storage. Consulte Creación de una cuenta de almacenamiento para obtener instrucciones sobre cómo crear una nueva cuenta de ADLS, incluido cómo habilitar el espacio de nombres jerárquico.
- Permisos de usuario configurados correctamente para Azure Data Lake Storage. Un administrador de Azure Databricks debe asegurarse de que los usuarios tengan los roles correctos, por ejemplo, colaborador de datos de Storage Blob, para leer y escribir los datos almacenados en Azure Data Lake Storage. Consulte Uso de Azure Portal para asignar un rol de Azure para el acceso a datos de blobs y colas.
- Comprender los privilegios de los administradores de áreas de trabajo en áreas de trabajo habilitadas para el acceso directo y revisar las asignaciones de administrador de área de trabajo existentes. Los administradores del área de trabajo pueden administrar las operaciones de su área de trabajo, incluida la adición de usuarios y entidades de servicio, la creación de clústeres y la delegación de otros usuarios para que sean administradores del área de trabajo. Las tareas de administración del área de trabajo, como la administración de la propiedad del trabajo y la visualización de cuadernos, pueden proporcionar acceso indirecto a los datos registrados en Azure Data Lake Storage. El administrador del área de trabajo es un rol con privilegios que debe distribuir con cuidado.
- No puede usar un clúster configurado con credenciales de ADLS, por ejemplo, credenciales de entidad de servicio, con acceso directo a credenciales.
Importante
No se puede autenticarse en Azure Data Lake Storage con sus credenciales de Microsoft Entra ID si se encuentra tras un firewall que no se ha configurado para permitir el tráfico a Microsoft Entra ID. Azure Firewall bloquea el acceso a Active Directory de forma predeterminada. Para permitir el acceso, configure la etiqueta de servicio AzureActiveDirectory. Puede encontrar información equivalente para las aplicaciones virtuales de red en la etiqueta AzureActiveDirectory en el archivo JSON de intervalos IP y etiquetas de servicio de Azure. Para más información, consulte Etiquetas de servicio de Azure Firewall.
Recomendaciones de registro
Puede registrar las identidades que se pasan al almacenamiento de ADLS en los registros de diagnóstico de Azure Storage. El registro de identidades permite que las solicitudes de ADLS se vinculen a usuarios individuales de clústeres de Azure Databricks. Activa el registro de diagnóstico en la cuenta de almacenamiento para empezar a recibir estos registros haciendo lo siguiente: configure mediante PowerShell con el comando Set-AzStorageServiceLoggingProperty. Especifique 2.0 como versión, ya que el formato de entrada de registro 2.0 incluye el nombre principal de usuario en la solicitud.
Habilitación del paso de credenciales de Azure Data Lake Storage para un clúster de alta simultaneidad
Los clústeres de alta simultaneidad se pueden compartir entre varios usuarios. Estos clústeres solo admiten Python y SQL con el paso de credenciales de Azure Data Lake Storage.
Importante
La habilitación del paso de credenciales de Azure Data Lake Storage para un clúster de alta simultaneidad bloquea todos los puertos del clúster, excepto los puertos 44, 53 y 80.
- Al crear un clúster, establezca Modo de clúster en Alta simultaneidad.
- En Opciones avanzadas, seleccione Habilitar el acceso directo de credenciales para el acceso a datos de nivel de usuario y permitir solo comandos de Python y SQL.

Habilitación del paso de credenciales de Azure Data Lake Storage para un clúster estándar
Los clústeres estándar con paso de credenciales se limitan a un solo usuario. Los clústeres estándar admiten Python, SQL, Scala y R. En Databricks Runtime 10.4 LTS y versiones posteriores, se admite sparklyr.
Debe asignar un usuario durante la creación del clúster, pero un usuario con los permisos CAN MANAGE lo puede modificar en cualquier momento para reemplazar al usuario original.
Importante
El usuario asignado al clúster debe tener al menos el permiso CAN ATTACH TO para el clúster con el fin de ejecutar comandos en él. Los administradores del área de trabajo y el creador del clúster tienen permisos CAN MANAGE, pero no pueden ejecutar comandos en el clúster a menos que sean el usuario del clúster designado.
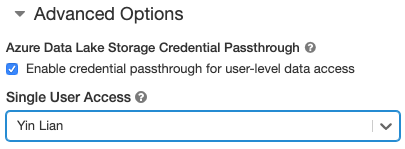
- Al crear un clúster, establezca el modo de clúster en Estándar.
- En Opciones avanzadas, seleccione Habilitar el acceso directo de credenciales para el acceso a datos de nivel de usuario y seleccione el nombre de usuario en la lista desplegable Acceso de usuario único .
Creación de un contenedor
Los contenedores proporcionan una manera de organizar los objetos en una cuenta de almacenamiento de Azure.
Acceso a Azure Data Lake Storage directamente mediante el paso de credenciales
Después de configurar el paso de credenciales de Azure Data Lake Storage y crear contenedores de almacenamiento, puede acceder a los datos directamente en Azure Data Lake Storage mediante una ruta de acceso abfss://.
Azure Data Lake Storage
Pitón
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/MyData.csv") %>% sdf_collect()
- Reemplace
<container-name>por el nombre de un contenedor en la cuenta de almacenamiento de ADLS. - Reemplace por
<storage-account-name>el nombre de la cuenta de almacenamiento de ADLS.
Montaje de Azure Data Lake Storage en DBFS mediante el paso de credenciales
Puede montar una cuenta de Azure Data Lake Storage o una carpeta dentro de ella para ¿Qué es DBFS?. El montaje es un puntero a una instancia de ADLS, por lo que los datos nunca se sincronizan localmente.
Al montar datos mediante un clúster habilitado con el acceso directo de credenciales de Azure Data Lake Storage, cualquier lectura o escritura en el punto de montaje usa las credenciales del identificador de Microsoft Entra. Este punto de montaje será visible para otros usuarios, pero los únicos usuarios que tendrán acceso de lectura y escritura son aquellos que:
- Tengan acceso a la cuenta de almacenamiento de Azure Data Lake Storage subyacente.
- Usen un clúster habilitado para el paso de credenciales de Azure Data Lake Storage.
Azure Data Lake Storage
Para montar un sistema de archivos de Azure Data Lake Storage o una carpeta dentro de él, use los siguientes comandos:
Pitón
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.windows.net/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- Reemplace
<container-name>por el nombre de un contenedor en la cuenta de almacenamiento de ADLS. - Reemplace por
<storage-account-name>el nombre de la cuenta de almacenamiento de ADLS. - Reemplace
<mount-name>por el nombre del punto de montaje previsto en DBFS.
Advertencia
No proporcione las claves de acceso de su cuenta de almacenamiento ni las credenciales del principal de servicio para autenticarse en el punto de montaje. Esto daría a otros usuarios acceso al sistema de archivos mediante esas credenciales. El propósito del paso directo de credenciales de Azure Data Lake Storage es evitar que tenga que usar esas credenciales y asegurarse de que el acceso al sistema de archivos está restringido a los usuarios que tienen acceso a la cuenta subyacente de Azure Data Lake Storage.
Seguridad
Es seguro compartir los clústeres de paso de credenciales de Azure Data Lake Storage con otros usuarios. Seréis aislados unos de otros y no podréis leer ni usar las credenciales de uno al otro.
Características admitidas
| Característica | Versión mínima de Databricks Runtime | Notas |
|---|---|---|
| Python y SQL | 5.5 | |
%run |
5.5 | |
| DBFS (sistema de archivos distribuido) | 5.5 | Las credenciales se pasan solo si la ruta de acceso de DBFS se dirige a una ubicación en Azure Data Lake Storage. En el caso de las rutas de acceso de DBFS que se resuelven en otros sistemas de almacenamiento, use otro método para especificar las credenciales. |
| Azure Data Lake Storage | 5.5 | |
| almacenamiento en caché de disco | 5.5 | |
| API de ML de PySpark | 5.5 |
No se admiten las clases de ML siguientes:
|
| Variables de difusión | 5.5 | Dentro de PySpark, hay un límite en el tamaño de las UDF de Python que se pueden construir, ya que las UDF de gran tamaño se envían como variables de difusión. |
| Bibliotecas con ámbito de Notebook | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6,0 | |
| sparklyr | 10.1 | |
| Organización de cuadernos y modularización de código en cuadernos | 6.1 | |
| API de ML de PySpark | 6.1 | Todas las clases de ML de PySpark admitidas. |
| Métricas del clúster | 6.1 | |
| Conexión de Databricks | 7.3 | El paso se admite en clústeres estándar. |
Limitaciones
Las siguientes características no se admiten con el paso de credenciales de Azure Data Lake Storage:
-
%fs(use en su lugar el comando dbutils.fs equivalente). - Trabajos de Databricks.
- La Referencia de la API de REST de Databricks.
- Unity Catalog.
-
Control de acceso a las tablas. Los permisos concedidos por la transferencia de credenciales de Azure Data Lake Storage podrían usarse para omitir los permisos detallados de las ACLs de tabla, mientras que las restricciones adicionales de las ACLs de tabla limitarán algunas de las ventajas que se obtienen de la transferencia de credenciales. En concreto:
- Si tiene permiso de Identificación de Entra de Microsoft para acceder a los archivos de datos que subyacen a una tabla determinada, tendrá permisos completos en esa tabla a través de la API de RDD, independientemente de las restricciones que se les hayan aplicado a través de ACLs de la tabla.
- Estarás limitado por los permisos ACL de la tabla solo cuando uses la API DataFrame. Verá advertencias sobre no tener permiso
SELECTen cualquier archivo si intenta leer archivos directamente con la API DataFrame, aunque podría leer esos archivos directamente mediante la API RDD. - No podrá leer las tablas respaldadas por sistemas de archivos distintos de Azure Data Lake Storage, incluso si tiene permiso de ACL de tabla para leer las tablas.
- Los métodos siguientes en objetos SparkContext (
sc) y SparkSession (spark):- Métodos en desuso.
- Métodos como
addFile()yaddJar()que permitirían a los usuarios que no son administradores llamar a código de Scala. - Cualquier método que tenga acceso a un sistema de archivos distinto de Azure Data Lake Storage (para acceder a otros sistemas de archivos de un clúster con el acceso directo de credenciales de Azure Data Lake Storage habilitado, use otro método para especificar sus credenciales y vea la sección sobre sistemas de archivos de confianza en Solución de problemas).
- Las API de Hadoop antiguas (
hadoopFile()yhadoopRDD()). - APIs de streaming, ya que las credenciales transmitidas expirarían mientras el flujo de datos aún estaba en ejecución.
- Los montajes de DBFS (
/dbfs) solo están disponibles en Databricks Runtime 7.3 LTS y versiones posteriores. Los puntos de montaje con el acceso directo a credenciales configurado no se admiten mediante esta ruta de acceso. - Azure Data Factory.
- MLflow en clústeres de alta simultaneidad.
- Paquete azureml-sdk de Python en clústeres de alta simultaneidad.
- No puede extender la duración de los tokens de acceso directo de Microsoft Entra ID mediante directivas de duración de tokens de Microsoft Entra ID. Como consecuencia, si envía un comando al clúster que tarda más de una hora, se producirá un error si se accede a un recurso de Azure Data Lake Storage después de la marca de 1 hora.
- Al usar Hive 2.3 y versiones posteriores, no se puede agregar una partición en un clúster con el acceso directo de credenciales habilitado. Para más información, consulte la sección de solución de problemas pertinente.
Solución de problemas
py4j.security.Py4JSecurityException: ... no está en la lista de permitidos
Esta excepción se produce cuando se ha tenido acceso a un método que Azure Databricks no se ha marcado explícitamente como seguro para los clústeres de acceso directo a las credenciales de Azure Data Lake Storage. En la mayoría de los casos, esto significa que el método podría permitir que un usuario de un clúster de credenciales de Azure Data Lake Storage acceda a las credenciales de otro usuario.
org.apache.spark.api.python.PythonSecurityException: Ruta de acceso... usa un sistema de archivos que no es de confianza
Esta excepción se produce cuando se ha intentado acceder a un sistema de archivos que el clúster de paso de credenciales de Azure Data Lake Storage desconoce que sea seguro. El uso de un sistema de archivos que no es de confianza podría permitir que un usuario de un clúster de paso a través de credenciales de Azure Data Lake Storage acceda a las credenciales de otro usuario, por lo que no se permiten todos los sistemas de archivos que no estamos seguros de que se usan de forma segura.
Para configurar el conjunto de sistemas de archivos de confianza en un clúster de paso a través de credenciales de Azure Data Lake Storage, establezca la clave spark.databricks.pyspark.trustedFilesystems conf de Spark en ese clúster para que sea una lista separada por comas de los nombres de clase que son implementaciones de confianza de org.apache.hadoop.fs.FileSystem.
Se produce un error al AzureCredentialNotFoundException agregar una partición cuando se habilita el paso a través de credenciales
Al usar Hive 2.3-3.1, si intenta agregar una partición en un clúster con el acceso directo de credenciales habilitado, se produce la siguiente excepción:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Token
Para evitar este problema, agregue particiones en un clúster sin el paso de credenciales habilitado.