Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se explica cómo usar la herramienta nativa de métricas de proceso en la interfaz de usuario de Azure Databricks para recopilar métricas clave de hardware y Spark. La interfaz de usuario de métricas está disponible para todas las finalidades y el proceso de trabajos.
Las métricas están disponibles casi en tiempo real con un retraso normal de menos de un minuto. Las métricas se almacenan en el almacenamiento administrado por Azure Databricks, no en el almacenamiento del cliente.
El proceso sin servidor para cuadernos y trabajos usa información de consulta en lugar de la interfaz de usuario de métricas. Para obtener más información sobre las métricas de proceso sin servidor, consulta Visualización de la información de consultas.
Acceso a la interfaz de usuario de métricas de proceso
Para ver la interfaz de usuario de métricas de proceso:
- Haga clic en Proceso en la barra lateral.
- Haga clic en el recurso de proceso para el que desea ver las métricas.
- Haga clic en la pestaña Métricas.
Las métricas de hardware de todos los nodos se muestran de forma predeterminada. Para ver las métricas de Spark, haga clic en la lista desplegable Hardware y seleccione Spark. También puede seleccionar GPU si la instancia está habilitada para GPU.
Filtrar métricas por período de tiempo
Puede ver las métricas históricas seleccionando un intervalo de tiempo mediante el filtro de selección de fecha. Las métricas se recopilan cada minuto, por lo que puede filtrar por cualquier intervalo de día, hora o minuto de los últimos 30 días. Haga clic en el icono de calendario para seleccionar entre intervalos de datos predefinidos o haga clic dentro del cuadro de texto para definir valores personalizados.
Nota:
Los intervalos de tiempo que se muestran en los gráficos se ajustan en función del período de tiempo que esté viendo. La mayoría de las métricas son promedios en función del intervalo de tiempo que está viendo actualmente.
También puede obtener las últimas métricas haciendo clic en el botón Actualizar.
Visualización de métricas en el nivel de nodo
De forma predeterminada, la página de métricas muestra las métricas de todos los nodos de un clúster (incluido el controlador) promedio durante el período de tiempo.
Para ver las métricas de nodos individuales, haga clic en el menú desplegable Todos los nodos y seleccione el nodo para el que desea ver las métricas. Las métricas de GPU solo están disponibles en el nivel de nodo individual. Las métricas de Spark no están disponibles para nodos individuales.
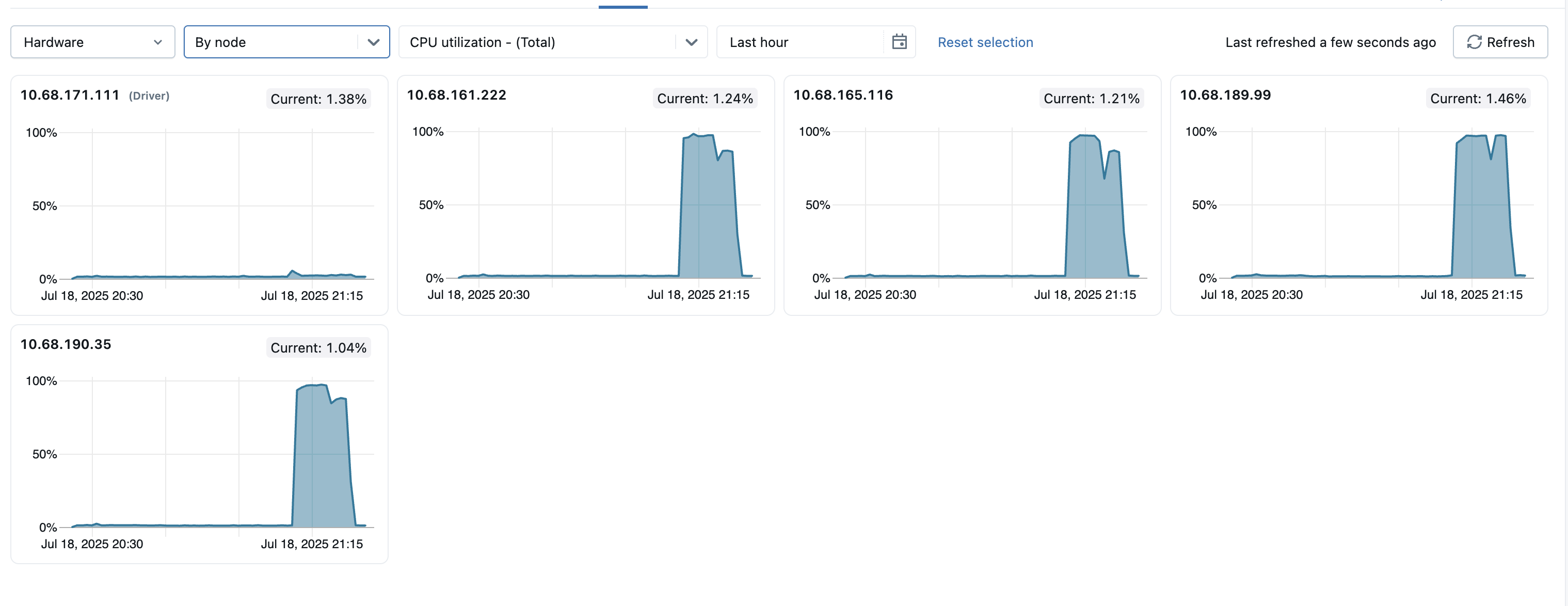
Para ayudar a identificar los nodos atípicos del clúster, también puede ver las métricas de todos los nodos individuales de una sola página. Para acceder a esta vista, haga clic en el menú desplegable Todos los nodos y seleccione Por nodo y, a continuación, seleccione la subcategoría de métricas que desea ver.
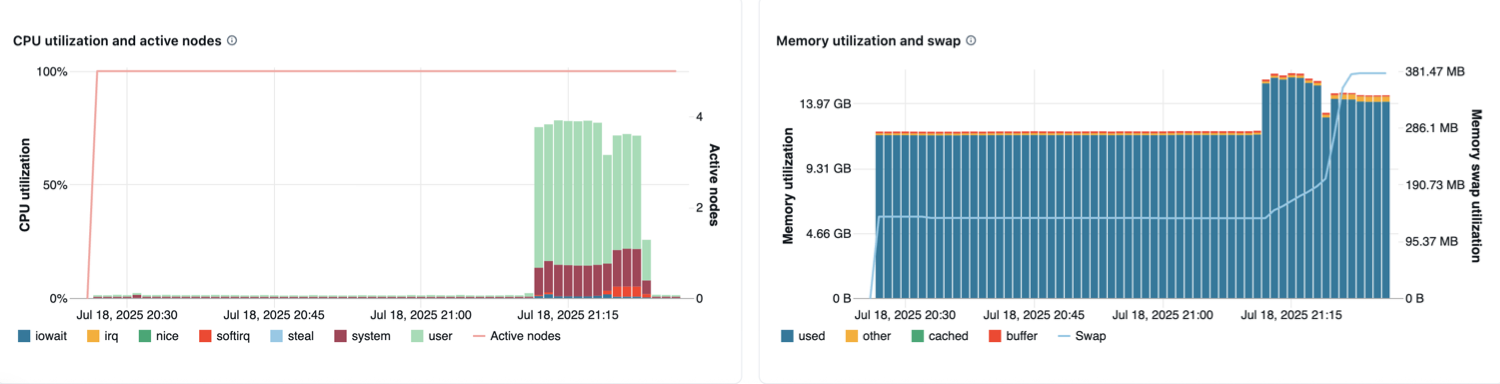
Gráficos de métricas de hardware
Los siguientes gráficos de métricas de GPU están disponibles para verlos en la interfaz de usuario de métricas de proceso:
-
Uso de CPU y nodos activos: el gráfico de líneas muestra el número de nodos activos en cada marca de tiempo para el proceso determinado. El gráfico de barras muestra el porcentaje de tiempo empleado en cada modo, en función del costo total de segundos de CPU. La métrica de uso es el promedio del intervalo de tiempo que se muestra en el gráfico. A continuación se muestran los modos de seguimiento:
- guest: si ejecuta máquinas virtuales, la CPU que usan esas máquinas virtuales
- iowait: tiempo dedicado a esperar la E/S
- idle: tiempo que la CPU no ha tenido nada que hacer
- irq: tiempo invertido en solicitudes de interrupción
- nice: tiempo utilizado por los procesos que tienen una gentileza positiva, es decir, una prioridad menor que otras tareas
- softirq: tiempo invertido en solicitudes de interrupción de software
- steal: si es una máquina virtual, tiempo que otras máquinas virtuales "roban" de las CPU
- system: tiempo invertido en el kernel
- user: tiempo invertido en el espacio de usuario
-
Uso e intercambio de memoria: el gráfico de líneas muestra el uso total del intercambio de memoria por modo, medido en bytes y promediado durante el intervalo de tiempo mostrado. El gráfico de barras muestra el uso total de memoria por modo, también medido en bytes y promedio durante el intervalo de tiempo mostrado. Se realiza el seguimiento de los siguientes tipos de uso:
- used: memoria total a nivel del sistema operativo en uso, incluida la memoria utilizada por los procesos en segundo plano que se ejecutan en un entorno de computación. Dado que los procesos en segundo plano y el controlador usan memoria, el uso puede aparecer incluso cuando no se ejecutan trabajos de Spark.
- free: memoria sin usar
- buffer: memoria usada por búferes de kernel
- cached: memoria usada por la caché del sistema de archivos en el nivel de sistema operativo
- Red recibida y transmitida: el número de bytes recibidos y transmitidos a través de la red por cada dispositivo, en función del intervalo de tiempo que se muestre en el gráfico.
- Espacio libre del sistema de archivos: el uso total del sistema de archivos por cada punto de montaje, medido en bytes y promedio en función del intervalo de tiempo que se muestre en el gráfico.
Gráficos de métricas de Spark
Los siguientes gráficos de métricas de Spark están disponibles para verlos en la interfaz de usuario de métricas de proceso:
- Distribución de carga del servidor: estos iconos muestran el uso de la CPU en el último minuto para cada nodo del recurso de proceso. Cada mosaico es un vínculo clicable que lleva a la página de métricas del nodo específico.
- Tareas activas: el número total de tareas que se ejecutan en cualquier momento determinado, en función del intervalo de tiempo que se muestre en el gráfico.
- Total de tareas con error: el número total de tareas que han producido errores en los ejecutores, se calcula en función del intervalo de tiempo que se muestre en el gráfico.
- Total de tareas completadas: el número total de tareas que se han completado en ejecutores, en función del intervalo de tiempo que se muestre en el gráfico.
- Número total de tareas: el número total de todas las tareas (en ejecución, con errores y completadas) en ejecutores, en función del intervalo de tiempo que se muestre en el gráfico.
-
Lectura de datos de mezcla total: tamaño total de datos de lectura de mezcla, medidos en bytes y promediados según el intervalo de tiempo que se muestra en el gráfico.
Shuffle readsignifica la suma de datos de lectura serializados en todos los ejecutores al principio de una fase. -
Total de escritura aleatoria: Tamaño total de los datos de escritura aleatoria, medidos en bytes y promedio en función del intervalo de tiempo que se muestre en el gráfico.
Shuffle Writees la suma de todos los datos serializados escritos en todos los ejecutores antes de transmitirlos (normalmente al final de una fase). - Duración total de la tarea: tiempo total transcurrido que la JVM ha dedicado a ejecutar tareas en ejecutores, medida en segundos y promedio en función del intervalo de tiempo que se muestra en el gráfico.
Gráficos de métricas de GPU
Nota:
Las métricas de GPU solo están disponibles en Databricks Runtime ML 13.3 y versiones posteriores.
Los siguientes gráficos de métricas de GPU están disponibles para verlos en la interfaz de usuario de métricas de proceso:
- Distribución de carga del servidor: en este gráfico se muestra el uso de la CPU durante el último minuto para cada nodo.
- Utilización del descodificador por GPU: El porcentaje promedio de utilización del descodificador de GPU, basado en el intervalo de tiempo que se muestra en el gráfico.
- Utilización del codificador por GPU: El porcentaje de utilización del codificador de GPU, promediado en función del intervalo de tiempo que se muestre en el gráfico.
- Uso de memoria del búfer de fotogramas por GPU en bytes: el uso de memoria del búfer de fotogramas, medido en bytes y promediado según el intervalo de tiempo que se muestre en el gráfico.
- Utilización de memoria por GPU: El porcentaje de utilización de la memoria de la GPU, calculado como un promedio basado en el intervalo de tiempo que se muestre en el gráfico.
- Utilización por GPU: El porcentaje de utilización de la GPU, promediado en función del intervalo de tiempo que se muestre en el gráfico.
Solución de problemas
Si ve métricas incompletas o que faltan durante un período, podría ser uno de los siguientes problemas:
- Una interrupción en el servicio Databricks responsable de consultar y almacenar métricas.
- Problemas de red en el lado del cliente.
- El proceso está o estaba en un estado incorrecto.