Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Obtenga información sobre cómo crear conexiones en el Explorador de catálogos que almacenan los detalles de autenticación de los orígenes de ingesta administrados de Lakeflow Connect. Cualquier usuario con privilegios USE CONNECTION o ALL PRIVILEGES en la conexión puede crear canalizaciones de ingesta administradas a partir de orígenes como Salesforce y SQL Server.
Un usuario administrador debe completar los pasos descritos en este artículo si los usuarios que crearán canalizaciones:
- son usuarios que no son administradores.
- usará las API de Databricks, los SDK de Databricks, la CLI de Databricks o los conjuntos de recursos de Databricks.
Estas interfaces requieren que los usuarios especifiquen una conexión existente al crear una canalización.
Como alternativa, los usuarios administradores pueden crear una conexión y una canalización al mismo tiempo en la interfaz de usuario de ingesta de datos. Consulte Conectores administrados en Lakeflow Connect.
Lakeflow Connect frente a Lakehouse Federation
La Federación de Lakehouse permite consultar orígenes de datos externos sin mover los datos. Cuando tenga que elegir entre Lakeflow Connect y Federación de Lakehouse, elija Federación de Lakehouse para informes ad hoc o trabajo de prueba de concepto en las canalizaciones de ETL. Consulte ¿Qué es la Federación Lakehouse?
Requisitos de privilegios
Los privilegios de usuario necesarios para conectarse a un origen de ingesta administrado dependen de la interfaz que elija:
Interfaz de usuario de ingesta de datos
Los usuarios administradores pueden crear una conexión y una canalización al mismo tiempo. Este asistente de ingesta de un extremo a otro solo está disponible en la interfaz de usuario. No todos los conectores de ingesta administrados admiten la creación de canalizaciones basadas en la interfaz de usuario.
Explorador de catálogos
El uso del Explorador de catálogos separa la creación de conexiones de la creación de la canalización. Esto permite a los administradores crear conexiones para que los usuarios que no son administradores creen canalizaciones con.
Si los usuarios que crearán canalizaciones son usuarios que no son administradores o planean usar las API de Databricks, los SDK de Databricks, la CLI de Databricks o Los conjuntos de recursos de Databricks, un administrador debe crear primero la conexión en el Explorador de catálogos. Estas interfaces requieren que los usuarios especifiquen una conexión existente al crear una canalización.
| Escenario | Interfaces admitidas | Privilegios de usuario necesarios |
|---|---|---|
| Un usuario administrador crea una conexión y una canalización de ingesta al mismo tiempo. | Interfaz de usuario de ingesta de datos |
|
| Un usuario administrador crea una conexión para que los usuarios que no son administradores creen canalizaciones con. | Admin:
No es administrador:
|
Admin:
No es administrador:
|
Confluencia
Para crear una conexión de Confluence en el Explorador de catálogos, haga lo siguiente:
Complete la configuración de origen. Use los detalles de autenticación que obtenga para crear la conexión.
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Datos externos > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , escriba un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione Confluence.
En el menú desplegable Tipo de autenticación , seleccione OAuth.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba las siguientes credenciales:
-
Dominio: el nombre de dominio de la instancia de Confluence (por ejemplo,
your-domain.atlassian.net). No incluyahttps://niwww. - Secreto de cliente: secreto de cliente de la configuración de origen.
- Id. de cliente: identificador de cliente de la configuración de origen.
-
Dominio: el nombre de dominio de la instancia de Confluence (por ejemplo,
Haga clic en Iniciar sesión con Confluence.
Se le redirigirá a la página de autorización de Atlassian.
Escriba las credenciales de Confluence y complete el proceso de autenticación.
Se le redirigirá al área de trabajo de Azure Databricks.
Haga clic en Crear conexión.
Dynamics 365
Importante
Esta característica está en versión preliminar pública.
Un administrador de área de trabajo o un administrador de metastore debe configurar Microsoft Dynamics 365 como origen de datos para la ingesta en Azure Databricks mediante Lakeflow Connect. Vea Configuración del origen de datos para la ingestión de Microsoft Dynamics 365.
Lakeflow Connect admite la ingesta de datos de Microsoft Dynamics 365. Esto incluye ambas aplicaciones integradas en Dataverse y aplicaciones que no son de Dataverse (como Finance & Operations) que se pueden conectar a Dataverse. El conector accede a los datos a través de Azure Synapse Link, que exporta datos D365 a Azure Data Lake Storage Gen2.
Synapse Link para Dataverse a Azure Data Lake reemplaza el servicio anteriormente conocido como Exportación de datos a Azure Data Lake Storage Gen2 (Exportación a Data Lake).
Prerrequisitos
Un administrador de área de trabajo o un administrador de metatstore debe configurar Microsoft Dynamics 365 como origen de datos para la ingesta en Azure Databricks mediante Lakeflow Connect. Vea Configuración del origen de datos para la ingestión de Microsoft Dynamics 365.
Creación de una conexión
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Datos externos > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione Dynamics 365.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , especifique lo siguiente:
- Secreto de cliente: el valor del secreto para el registro de la aplicación Microsoft Entra ID. Obtenga esto de la configuración de origen.
- Id. de cliente: identificador único (id. de aplicación) para el registro de la aplicación de Id. de Microsoft Entra. Obtenga esto de la configuración de origen.
- Nombre de la cuenta de Azure Storage: el nombre de la cuenta de Azure Data Lake Storage Gen2 donde Synapse Link exporta los datos D365.
- Id. de inquilino: identificador único del inquilino de Microsoft Entra ID. Obtenga esto de la configuración de origen.
- Nombre del contenedor de ADLS: el nombre del contenedor dentro de la cuenta de Azure Data Lake Storage (ADLS) Gen2 donde se almacenan los datos D365.
Haga clic en Crear conexión.
Pasos siguientes
Cree una canalización de ingesta.
Datos sin procesar de Google Analytics
Se admiten los siguientes métodos de autenticación:
- U2M OAuth (recomendado)
- Autenticación de la cuenta de servicio mediante una clave JSON (en la interfaz de usuario, se denomina nombre de usuario y contraseña).
U2M OAuth
- En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
- En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
- En el menú desplegable Tipo de conexión , seleccione Datos sin procesar de Google Analytics.
- En el menú desplegable Tipo de autenticación , seleccione OAuth.
- (Opcional) Agregue un comentario.
- Haga clic en Next.
- En la página Autenticación , haga clic en Iniciar sesión en Google e inicie sesión con sus credenciales de cuenta de Google.
- En el símbolo del sistema para permitir que Lakeflow Connect acceda a su cuenta de Google, haga clic en Permitir.
- Una vez redirigido de nuevo al área de trabajo de Azure Databricks, haga clic en Crear conexión.
Autenticación de cuenta de servicio
- En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
- En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
- En el menú desplegable Tipo de conexión , seleccione Datos sin procesar de Google Analytics.
- En el menú desplegable Tipo de autenticación , seleccione Nombre de usuario y contraseña.
- (Opcional) Agregue un comentario.
- Haga clic en Next.
- En la página Autenticación , escriba la clave de cuenta de servicio de Google desde la configuración de origen en formato JSON.
- Haga clic en Crear conexión.
Jira
Para crear una conexión jira en el Explorador de catálogos, haga lo siguiente:
Complete la configuración de origen. Usará los detalles de autenticación que obtenga para crear la conexión.
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Datos externos > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione Jira.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba lo siguiente:
-
Host: el dominio para el origen de datos de Jira, incluido
http/https. - (Opcional) Puerto: puerto de una instancia de Jira local. El valor predeterminado es 443.
- Secreto de cliente: secreto de cliente de la configuración de origen.
- (Opcional) En las instalaciones: Seleccione si la instancia de Jira es en las instalaciones.
- Id. de cliente: identificador de cliente de la configuración de origen.
- (Opcional) Ruta de acceso de implementación de Jira: ruta de acceso de implementación local (por ejemplo, si la dirección URL es
http://<domain>:<port>/<path>, la ruta de acceso es<path>).
-
Host: el dominio para el origen de datos de Jira, incluido
Haga clic en Iniciar sesión con Jira y autorice la aplicación Azure Databricks.
Meta Ads
Prerrequisitos
Configure Meta Ads como origen de datos.
Creación de una conexión
- En el Explorador de catálogos, haga clic en Agregar y seleccione Agregar una conexión.
- En el menú desplegable Tipo de conexión , seleccione Meta Ads.
- Escriba un nombre para la conexión.
- En el campo App ID, escriba el App ID de su aplicación de Meta.
- En el campo Secreto de la aplicación, escriba el secreto de la aplicación de tu aplicación de Meta.
- Haga clic en Autenticar y crear conexión.
- En la ventana Autenticación meta, inicie sesión con su cuenta meta y conceda los permisos solicitados.
- Una vez que la autenticación se realiza correctamente, se crea la conexión.
MySQL
Prerrequisitos
Complete la configuración de origen. Usará los detalles de autenticación que obtenga para crear la conexión.
Creación de una conexión
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione MySQL.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba lo siguiente:
- Host: especifique el nombre de dominio de MySQL.
- Usuario y contraseña: escriba las credenciales de inicio de sesión de MySQL del usuario de replicación.
Haga clic en Crear conexión.
El botón Probar conexión produce un error actualmente para los usuarios creados con caching_sha2_password o sha256_password incluso cuando las credenciales son correctas. Se trata de un problema conocido.
Netsuite
El conector netSuite usa la autenticación basada en tokens.
Prerrequisitos
Complete la configuración de origen. Use los detalles de autenticación que obtenga para crear la conexión.
Creación de una conexión
Para crear una conexión de ingesta de NetSuite en el Explorador de catálogos, haga lo siguiente:
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione NetSuite.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba las siguientes credenciales:
- Clave de consumidor: la clave de consumidor de OAuth de la integración de NetSuite.
- Secreto del consumidor: el secreto del consumidor de la integración OAuth de NetSuite.
- ID del token: el identificador del token de acceso para el usuario de NetSuite.
- Token Secret: el secreto del token de acceso para el usuario de NetSuite.
- Role ID: el identificador interno del Rol Integrador de Almacenamiento de Datos en NetSuite.
- Host: el nombre de host de la dirección URL de JDBC de NetSuite.
- Puerto: número de puerto de la dirección URL de JDBC de NetSuite.
- ID de cuenta: la ID de cuenta de la dirección URL de JDBC de NetSuite.
Haga clic en Probar conexión para comprobar que puede conectarse a Netsuite.
Haga clic en Crear conexión.
PostgreSQL
Prerrequisitos
Configuración de PostgreSQL para la ingesta en Azure Databricks
Creación de una conexión
- En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
- En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
- En el menú desplegable Tipo de conexión , seleccione PostgreSQL.
- (Opcional) Agregue un comentario.
- Haga clic en Next.
- En la página Autenticación , en Host, especifique el nombre de dominio de PostgreSQL.
- En Usuario y contraseña, escriba las credenciales de inicio de sesión de PostgreSQL del usuario de replicación.
- Haga clic en Crear conexión.
Salesforce
Lakeflow Connect admite la ingesta de datos de la plataforma salesforce. Databricks también ofrece un conector de copia cero en Lakehouse Federation para ejecutar consultas federadas en Salesforce Data 360 (anteriormente Data Cloud).
Prerrequisitos
Salesforce aplica restricciones de uso a las aplicaciones conectadas. Los permisos de la tabla siguiente son necesarios para una autenticación correcta por primera vez. Si no tiene estos permisos, Salesforce bloquea la conexión y requiere que un administrador instale la aplicación conectada de Databricks.
| Condición | Permiso necesario |
|---|---|
| El control de acceso de API está habilitado. |
Customize Application y o Modify All Data o Manage Connected Apps |
| El control de acceso de API no está habilitado. | Approve Uninstalled Connected Apps |
Para obtener información general, consulte Preparación del cambio de restricciones de uso de aplicaciones conectadas en la documentación de Salesforce.
Creación de una conexión
Para crear una conexión de ingesta de Salesforce en el Explorador de catálogos, haga lo siguiente:
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione Salesforce.
(Opcional) Agregue un comentario.
Haga clic en Next.
Si va a realizar la ingesta desde una cuenta de espacio aislado de Salesforce, establezca Es espacio aislado en
true.Haga clic en Iniciar sesión con Salesforce.
Se le redirigirá a Salesforce.
Si va a ingerir desde un espacio aislado de Salesforce, haga clic en Usar dominio personalizado, proporcione la dirección URL del espacio aislado y, a continuación, haga clic en Continuar.
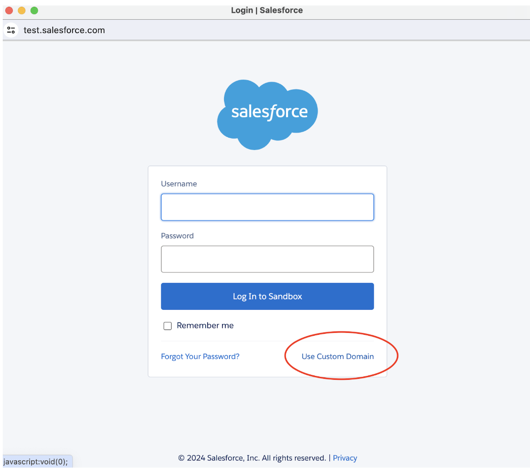
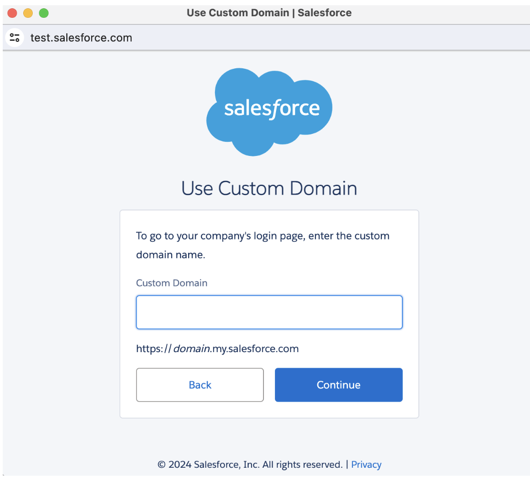
Escriba sus credenciales de Salesforce y haga clic en Iniciar sesión. Databricks recomienda iniciar sesión como usuario de Salesforce dedicado a la ingesta de Databricks.
Importante
Para fines de seguridad, solo se autentica si hace clic en un vínculo de OAuth 2.0 en la interfaz de usuario de Azure Databricks.
Después de volver al Asistente para ingesta, haga clic en Crear conexión.
ServiceNow
Los pasos para crear una conexión de ServiceNow en el Explorador de catálogos dependen del método OAuth que elija. Se admiten los métodos siguientes:
- U2M OAuth (recomendado)
- Credenciales de contraseña del propietario del recurso de OAuth (ROPC)
U2M OAuth
Configure ServiceNow para la ingesta de Azure Databricks. Usará los detalles de autenticación que obtenga para crear la conexión.
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione ServiceNow.
En el menú desplegable Tipo de autenticación , seleccione OAuth.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba lo siguiente:
- Dirección URL de instancia: dirección URL de la instancia de ServiceNow.
-
Ámbito de OAuth: deje el valor
useraccountpredeterminado . - Secreto de Cliente: El Secreto de Cliente que obtuvo en la configuración de origen.
- ID de cliente: el identificador de cliente que obtuvo en la configuración de origen.
Haga clic en Iniciar sesión con ServiceNow.
Inicie sesión con sus credenciales de ServiceNow.
Se le redirigirá al área de trabajo de Azure Databricks.
Haga clic en Crear conexión.
ROPC
Configure ServiceNow para la ingesta de Azure Databricks. Usará los detalles de autenticación que obtenga para crear la conexión.
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione ServiceNow.
En el menú desplegable Tipo de autenticación , seleccione Contraseña del propietario del recurso de OAuth.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba lo siguiente:
- Usuario: nombre de usuario de ServiceNow.
- Contraseña: contraseña de ServiceNow.
- Dirección URL de instancia: dirección URL de la instancia de ServiceNow.
- ID de cliente: el identificador de cliente que obtuvo en la configuración de origen.
- Secreto de Cliente: El Secreto de Cliente que obtuvo en la configuración de origen.
Haga clic en Crear conexión.
SharePoint (en inglés)
Se admiten los siguientes métodos de autenticación:
- OAuth M2M (versión preliminar pública)
- OAuth U2M
- OAuth con actualización manual del token
En la mayoría de los escenarios, Databricks recomienda OAuth de máquina a máquina (M2M). M2M limita los permisos del conector a un sitio específico. Sin embargo, si desea definir el ámbito de los permisos a los que pueda acceder el usuario autenticado, elija OAuth de usuario a máquina (U2M) en su lugar. Ambos métodos ofrecen actualización automatizada de tokens y mayor seguridad.
M2M
Complete la configuración de origen. Usará los detalles de autenticación que obtenga para crear la conexión.
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Datos externos > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione Microsoft SharePoint.
En el menú desplegable Tipo de autenticación, seleccione OAuth de Máquina a Máquina.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba las siguientes credenciales para la aplicación microsoft Entra ID:
- Secreto de Cliente: el secreto de cliente que recuperó en la configuración de origen.
- Identificación de cliente: la identificación del cliente que recuperó en la configuración de origen.
-
Dominio: la dirección URL de la instancia de SharePoint con el formato siguiente:
https://MYINSTANCE.sharepoint.com - ID de inquilino: el identificador de inquilino que obtuvo en la configuración original.
Haga clic en Iniciar sesión con Microsoft SharePoint.
Se abre una nueva ventana. Después de iniciar sesión con las credenciales de SharePoint, se muestran los permisos que concede a la aplicación Entra ID.
Haga clic en Aceptar.
Se muestra un mensaje autorizado correctamente y se le redirige al área de trabajo de Azure Databricks.
Haga clic en Crear conexión.
U2M
Complete la configuración de origen. Usará los detalles de autenticación que obtenga para crear la conexión.
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Datos externos > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione Microsoft SharePoint.
En el menú desplegable Tipo de autenticación , seleccione OAuth.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba las siguientes credenciales para la aplicación microsoft Entra ID:
- Secreto de Cliente: el secreto de cliente que recuperó en la configuración de origen.
- Identificación de cliente: la identificación del cliente que recuperó en la configuración de origen.
-
Ámbito de OAuth: deje el ámbito de OAuth establecido en el valor rellenado previamente:
https://graph.microsoft.com/Sites.Read.All offline_access -
Dominio: la dirección URL de la instancia de SharePoint con el formato siguiente:
https://MYINSTANCE.sharepoint.com - ID de inquilino: el identificador de inquilino que obtuvo en la configuración original.
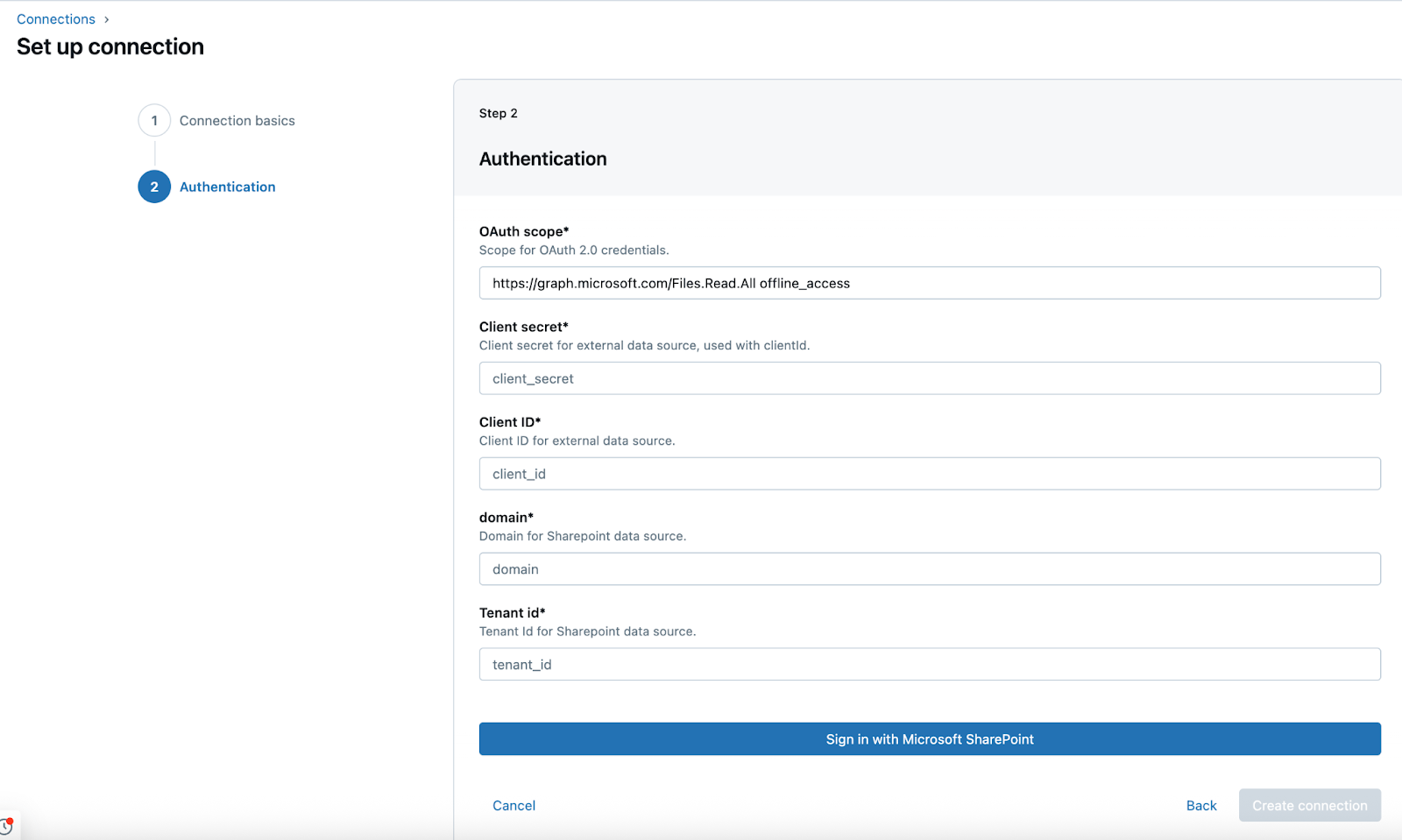
Haga clic en Iniciar sesión con Microsoft SharePoint.
Se abre una nueva ventana. Después de iniciar sesión con las credenciales de SharePoint, se muestran los permisos que concede a la aplicación Entra ID.
Haga clic en Aceptar.
Se muestra un mensaje autorizado correctamente y se le redirige al área de trabajo de Azure Databricks.
Haga clic en Crear conexión.
Token de actualización manual
Complete la configuración de origen. Usará los detalles de autenticación que obtenga para crear la conexión.
En el área de trabajo de Azure Databricks, haga clic en Catálogo > Datos externos > Conexiones > Crear conexión.
En la página Aspectos básicos de conexión del Asistente para configurar conexiones , especifique un nombre de conexión único.
En el menú desplegable Tipo de conexión , seleccione Microsoft SharePoint.
En el menú desplegable Tipo de autenticación , seleccione Token de actualización de OAuth.
(Opcional) Agregue un comentario.
Haga clic en Next.
En la página Autenticación , escriba las siguientes credenciales para la aplicación microsoft Entra ID:
- ID de inquilino: el identificador de inquilino que obtuvo en la configuración original.
- Identificación de cliente: la identificación del cliente que recuperó en la configuración de origen.
- Secreto de Cliente: el secreto de cliente que recuperó en la configuración de origen.
- Token de actualización: el token de actualización que recuperó en la configuración de la fuente.
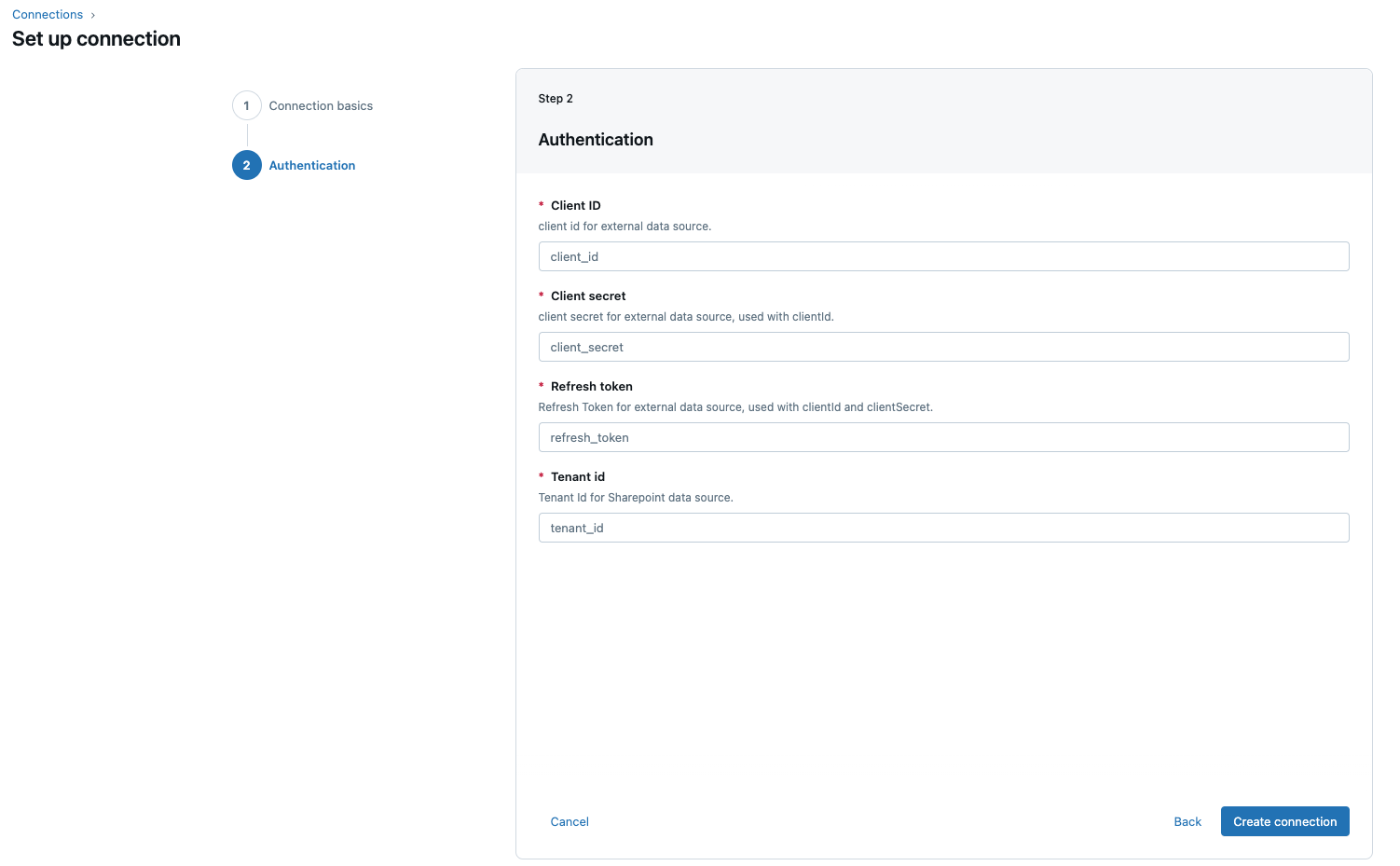
Haga clic en Crear conexión.
Servidor SQL
Para crear una conexión de Microsoft SQL Server en el Explorador de catálogos, haga lo siguiente:
- En las áreas de trabajo de Azure Databricks, haga clic en Catálogo > Datos externos > Conexiones.
- Haga clic en Crear conexión.
- Escriba un Nombre de conexión único.
- Para Tipo de conexión seleccione SQL Server.
- Para Host, especifique el nombre de dominio de SQL Server.
- Para Usuario y contraseña, escriba las credenciales de inicio de sesión de SQL Server.
- Haga clic en Crear.
Informes de Workday
Para crear una conexión de informes de Workday en el Explorador de catálogos, haga lo siguiente:
- Cree credenciales de acceso de Workday. Para obtener instrucciones, consulte Configuración de informes de Workday para la ingesta.
- En el área de trabajo de Azure Databricks, haga clic en Catálogo > Ubicaciones externas > Conexiones > Crear conexión.
- En Nombre de la conexión, escriba un nombre único para la conexión de Workday.
- En Tipo de conexión, seleccione Workday Reports.
- En Tipo de autenticación, seleccione Token de actualización de OAuth o Nombre de usuario y contraseña (autenticación básica) y haga clic en Siguiente.
- (Token de actualización de OAuth) En la página Autenticación , escriba el identificador de cliente, el secreto de cliente y el token de actualización que obtuvo en la configuración de origen.
- (Autenticación básica) Escriba el nombre de usuario y la contraseña de Workday.
- Haga clic en Crear conexión.
Paso siguiente
Después de crear una conexión al origen de ingesta administrado en el Explorador de catálogos, cualquier usuario con USE CONNECTION privilegios o ALL PRIVILEGES en la conexión puede crear una canalización de ingesta de las maneras siguientes:
- Asistente para ingesta (solo conectores admitidos)
- Conjuntos de recursos de Databricks
- API de Databricks
- SDK de Databricks
- CLI de Databricks
Para obtener instrucciones para crear una canalización, consulte la documentación del conector administrado.