Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aprenda a crear e implementar una canalización ETL (extracción, transformación y carga) con captura de datos modificados (CDC) mediante canalizaciones declarativas de Lakeflow para la orquestación de datos y el cargador automático. Una canalización de ETL implementa los pasos para leer datos de sistemas de origen, transformar esos datos en función de los requisitos, como comprobaciones de calidad de datos y desduplicación de registros, y escribir los datos en un sistema de destino, como un almacenamiento de datos o un lago de datos.
En este tutorial, usarás datos de una tabla en una customers base de datos MySQL para:
- Extraiga los cambios de una base de datos transaccional mediante Debezium o cualquier otra herramienta y guárdelas en un almacenamiento de objetos en la nube (carpeta S3, ADLS, GCS). Omitirá la configuración de un sistema CDC externo para simplificar el tutorial.
- Use Auto Loader para cargar incrementalmente los mensajes desde el almacenamiento de objetos en la nube y almacenar los mensajes sin procesar en la
customers_cdctabla. El cargador automático deducirá el esquema y controlará la evolución del esquema. - Agregue una vista
customers_cdc_cleanpara comprobar la calidad de los datos mediante las expectativas. Por ejemplo,idnunca debería sernullya que lo usarás para ejecutar tus operaciones upsert. - Realice el
AUTO CDC ... INTO(los upserts) en los datos del CDC limpios para aplicar los cambios a la tabla finalcustomers. - Mostrar cómo Las canalizaciones declarativas de Lakeflow pueden crear una dimensión de tipo 2 de variación lenta (SCD2) para realizar un seguimiento de todos los cambios.
El objetivo es ingerir los datos sin procesar en tiempo casi real y crear una tabla para tu equipo de analistas, asegurando a la vez la calidad de los datos.
El tutorial usa la arquitectura medallion Lakehouse, donde ingiere datos sin procesar a través de la capa de bronce, limpia y valida los datos con la capa de plata, y aplica el modelado dimensional y la agregación mediante la capa dorada. Consulte ¿Qué es la arquitectura de medallion lakehouse? para obtener más información.
El flujo que implementará tiene el siguiente aspecto:
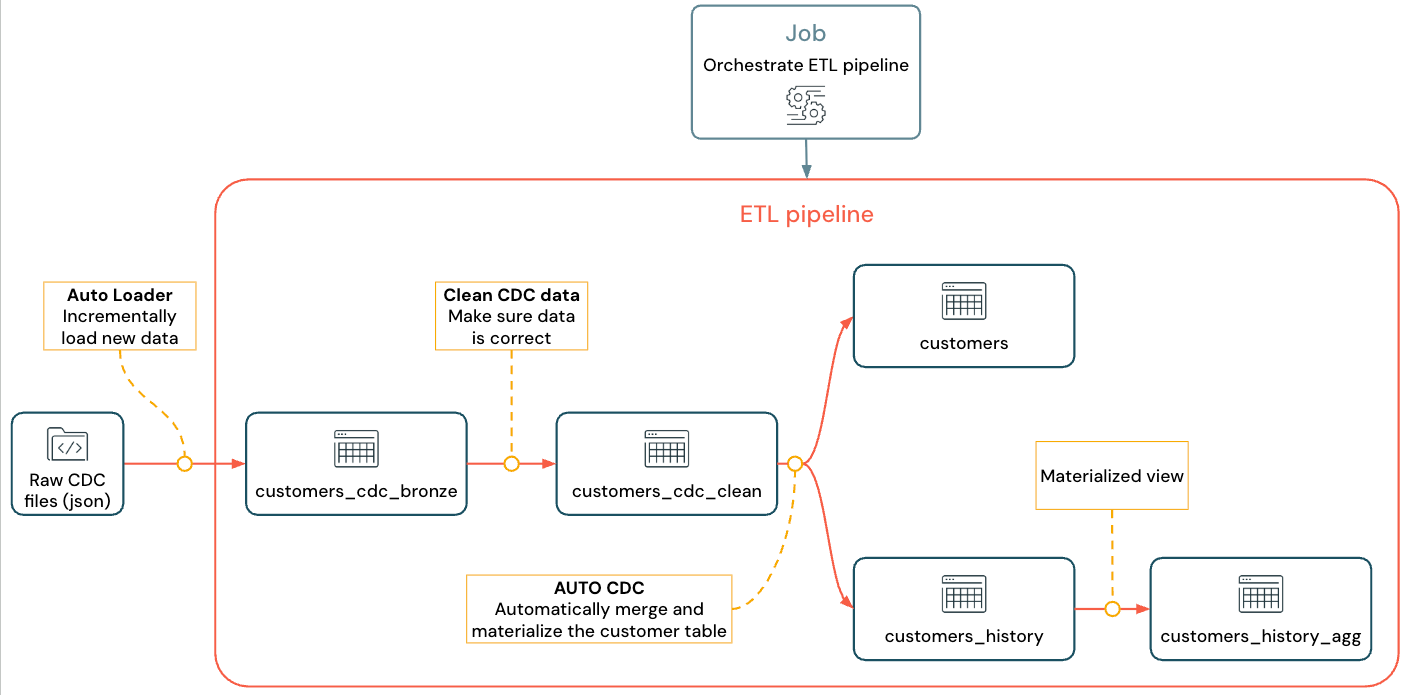
Para obtener más información sobre las canalizaciones declarativas de Lakeflow, Auto Loader y CDC, consulte Canalizaciones declarativas de Lakeflow, ¿Qué es Auto Loader?, y ¿Qué es la captura de datos de cambios (CDC)?
Requisitos
Para completar este tutorial, debe cumplir los siguientes requisitos:
- Inicie sesión en un área de trabajo de Azure Databricks.
- Tener habilitado el catálogo de Unity para el área de trabajo.
- Contar con computación sin servidor habilitada en su cuenta. Las canalizaciones declarativas de Lakeflow sin servidor no están disponibles en todas las regiones del área de trabajo. Consulte Características con disponibilidad regional limitada para las regiones disponibles.
- Tener permiso para crear un recurso de proceso o acceso a un recurso de proceso.
- Tener permisos para crear un nuevo esquema en un catálogo. Los permisos necesarios son
ALL PRIVILEGESoUSE CATALOGyCREATE SCHEMA. - Tener permisos para crear un nuevo volumen en un esquema existente. Los permisos necesarios son
ALL PRIVILEGESoUSE SCHEMAyCREATE VOLUME.
Captura de datos modificados en una canalización ETL
La captura de datos modificados (CDC) es el proceso que captura los cambios realizados en los registros realizados en una base de datos transaccional (por ejemplo, MySQL o PostgreSQL) o un almacenamiento de datos. CDC captura operaciones como la eliminación de datos, anexar y actualizar, normalmente como una secuencia para volver a materializar la tabla en sistemas externos. CDC permite la carga incremental sin necesidad de actualizar la carga por lotes.
Nota:
Para simplificar el tutorial, omita la configuración de un sistema CDC externo. Puede considerarlo en funcionamiento y guardar los datos CDC como archivos JSON en un almacenamiento de blobs (S3, ADLS, GCS).
Captura de CDC
Hay una variedad de herramientas CDC disponibles. Una de las soluciones líderes de código abierto es Debezium, pero otras implementaciones que simplifican el origen de datos existen, como Fivetran, Qlik Replicate, Streamset, Talend, Oracle GoldenGate y AWS DMS.
En este tutorial, usará datos CDC de un sistema externo como Debezium o DMS. Debezium captura todas las filas modificadas. Normalmente envía el historial de cambios de datos a los registros de Kafka o los guarda como un archivo.
Debe ingerir la información CDC de la tabla customers en formato JSON, comprobar que es correcta, y luego materializar la tabla de clientes en el Lakehouse.
Entrada de CDC desde Debezium
Para cada cambio, recibirá un mensaje JSON que contiene todos los campos de la fila que se actualizan (id, firstname, lastname, email, address). Además, tendrá información adicional de metadatos, entre las que se incluyen:
-
operation: código de operación, normalmente (DELETE,APPEND,UPDATE). -
operation_date: la fecha y la marca de tiempo del registro para cada acción de operación.
Las herramientas como Debezium pueden generar una salida más avanzada, como el valor de fila antes del cambio, pero este tutorial los omite por motivos de simplicidad.
Paso 0: Configuración de datos del tutorial
En primer lugar, debe crear un cuaderno e instalar los archivos de demostración usados en este tutorial en el área de trabajo.
Haga clic en Nuevo en la esquina superior izquierda.
Haga clic en Bloc de notas.
Cambie el título del cuaderno de Cuaderno sin título <fecha y hora> a Configuración del tutorial de canalizaciones.
Junto al título del cuaderno en la parte superior, establezca el lenguaje predeterminado del cuaderno en Python.
Para generar el conjunto de datos usado en el tutorial, escriba el código siguiente en la primera celda y escriba Mayús + Entrar para ejecutar el código:
# You can change the catalog, schema, dbName, and db. If you do so, you must also # change the names in the rest of the tutorial. catalog = "main" schema = dbName = db = "dbdemos_dlt_cdc" volume_name = "raw_data" spark.sql(f'CREATE CATALOG IF NOT EXISTS `{catalog}`') spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'CREATE SCHEMA IF NOT EXISTS `{catalog}`.`{schema}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{schema}`.`{volume_name}`') volume_folder = f"/Volumes/{catalog}/{db}/{volume_name}" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exists, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Para obtener una vista previa de los datos usados en este tutorial, escriba el código en la celda siguiente y escriba Mayús + Entrar para ejecutar el código:
display(spark.read.json("/Volumes/main/dbdemos_dlt_cdc/raw_data/customers"))
Paso 1: Creación de una canalización
Primero, creará una canalización ETL en Lakeflow Declarative Pipelines. Las canalizaciones declarativas de Lakeflow crean canalizaciones mediante la resolución de dependencias definidas en cuadernos o archivos ( denominados código fuente) mediante la sintaxis de canalizaciones declarativas de Lakeflow. Cada archivo de código fuente solo puede contener un idioma, pero puede agregar varios archivos o cuadernos específicos de un idioma en la canalización. Para obtener más información, consulte Canalizaciones declarativas de Lakeflow.
Importante
Deje el campo Código fuente en blanco para crear y configurar automáticamente un cuaderno para la creación de código fuente.
En este tutorial se utiliza la computación sin servidor y el catálogo de Unity. Para todas las opciones de configuración que no se especifican, use la configuración predeterminada. Si el proceso sin servidor no está habilitado o se admite en el área de trabajo, puede completar el tutorial como escrito mediante la configuración de proceso predeterminada. Si usa la configuración de proceso predeterminada, debe seleccionar manualmente Unity Catalog en Opciones de almacenamiento en la sección Destino de la interfaz de usuario de Crear Canalización.
Para crear una nueva canalización de ETL en Lakeflow declarative pipelines, siga estos pasos:
- En el área de trabajo, haga clic en
 Trabajos y canalizaciones en la barra lateral.
Trabajos y canalizaciones en la barra lateral. - En Nuevo, haga clic en Canalización ETL.
- En Nombre de canalización, escriba un nombre de canalización único.
- Active la casilla Sin servidor .
- Seleccione Desencadenado en modo de canalización. Esto ejecutará los flujos de streaming mediante el desencadenador AvailableNow, que procesa todos los datos existentes y, a continuación, apaga la secuencia.
- En Destino, para configurar una ubicación del catálogo de Unity donde se publican las tablas, seleccione un catálogo existente y escriba un nombre nuevo en Esquema para crear un nuevo esquema en el catálogo.
- Haga clic en Crear.
Aparece la interfaz de usuario de canalización para la nueva canalización.
Se crea y configura automáticamente un cuaderno de código fuente en blanco para la canalización. El cuaderno se crea en un nuevo directorio del directorio de usuario. El nombre del nuevo directorio y archivo coinciden con el nombre de la canalización. Por ejemplo: /Users/someone@example.com/my_pipeline/my_pipeline.
- Un vínculo para acceder a este cuaderno se encuentra en el campo Código fuente del panel Detalles de canalización . Haga clic en el vínculo para abrir el cuaderno antes de continuar con el paso siguiente.
- Haga clic en Conectar en la esquina superior derecha para abrir el menú de configuración de proceso.
- Mantenga el puntero sobre el nombre de la canalización que creó en el paso 1.
- Haga clic en Conectar.
- Junto al título del cuaderno en la parte superior, seleccione el lenguaje predeterminado del cuaderno (Python o SQL).
Importante
Los cuadernos solo pueden contener un solo lenguaje de programación. No mezcle código de Python y SQL en cuadernos de código fuente de canalización.
Al desarrollar canalizaciones declarativas de Lakeflow, puede elegir Python o SQL. En este tutorial se incluyen ejemplos de ambos lenguajes. En función de su elección de idioma, compruebe que selecciona el idioma predeterminado del cuaderno.
Para obtener más información sobre el soporte de notebooks para el desarrollo de código de canalizaciones declarativas de Lakeflow, consulte Desarrolle y depure canalizaciones ETL con un notebook en Canalizaciones declarativas de Lakeflow.
Paso 2: Ingesta incremental de datos con cargador automático
El primer paso es cargar los datos sin procesar del almacenamiento en la nube en una capa de bronce.
Esto puede ser difícil por varias razones, ya que debe:
- Operar a escala, con la capacidad de ingerir millones de archivos pequeños.
- Inferir el esquema y el tipo JSON.
- Controle registros incorrectos con un esquema JSON incorrecto.
- Atiende la evolución del esquema (por ejemplo, una nueva columna en la tabla de clientes).
Auto Loader simplifica esta ingesta, incluida la inferencia de esquemas y la evolución del esquema, para gestionar millones de archivos entrantes. Auto Loader está disponible en Python mediante cloudFiles y en SQL mediante SELECT * FROM STREAM read_files(...) y se puede usar con diversos formatos (JSON, CSV, Apache Avro, etc.):
Definir la tabla como una tabla de streaming garantizará que solo consuma nuevos datos entrantes. Si usted no la define como una tabla de transmisión, examinará y procesará todos los datos disponibles. Consulte Tablas de streaming para obtener más información.
Para ingerir los datos entrantes mediante el cargador automático, copie y pegue el código siguiente en la primera celda del cuaderno. Puede usar Python o SQL, en función del lenguaje predeterminado del cuaderno que eligió en el paso anterior.
Pitón
from dlt import * from pyspark.sql.functions import * # Create the target bronze table dlt.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load("/Volumes/main/dbdemos_dlt_cdc/raw_data/customers") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( "/Volumes/main/dbdemos_dlt_cdc/raw_data/customers", format => "json", inferColumnTypes => "true" )Haga clic en Iniciar para iniciar una actualización de la canalización conectada.
Paso 3: Limpieza y expectativas para realizar un seguimiento de la calidad de los datos
Una vez definida la capa de bronce, creará las capas de plata agregando expectativas para controlar la calidad de los datos comprobando las condiciones siguientes:
- El identificador nunca debe ser
null. - El tipo de operación CDC debe ser válido.
- Debe
jsonhaber sido leído adecuadamente por Auto Loader.
La fila se quitará si no se respeta una de estas condiciones.
Consulte Gestionar la calidad de los datos con expectativas de la canalización para obtener más información.
Haga clic en Editar e insertar celda a continuación para insertar una nueva celda vacía.
Para crear una capa de plata con una tabla limpia e imponer restricciones, copie y pegue el código siguiente en la nueva celda del cuaderno.
Pitón
dlt.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( dlt.read_stream("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;Haga clic en Iniciar para iniciar una actualización de la canalización conectada.
Paso 4: Materialización de la tabla de clientes con un flujo CDC automático
La customers tabla contendrá la vista más up-to-actualizada y será una réplica de la tabla original.
Esto no es sencillo para implementar manualmente. Debe tener en cuenta aspectos como la desduplicación de datos para mantener la fila más reciente.
Sin embargo, Las canalizaciones declarativas de Lakeflow resuelven estos desafíos con la AUTO CDC operación.
Haga clic en Editar e insertar celda a continuación para insertar una nueva celda vacía.
Para procesar los datos CDC mediante
AUTO CDCcanalizaciones declarativas de Lakeflow, copie y pegue el código siguiente en la nueva celda del cuaderno.Pitón
dlt.create_streaming_table(name="customers", comment="Clean, materialized customers") dlt.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;Haga clic en Iniciar para iniciar una actualización de la canalización conectada.
Paso 5: Dimensión lentamente cambiante de tipo 2 (SCD2)
A menudo es necesario crear una tabla de seguimiento de todos los cambios resultantes de APPEND, UPDATEy DELETE:
- Historial: quieres conservar un historial de todos los cambios en tu tabla.
- Rastreabilidad: quiere ver qué operación se ha producido.
SCD2 con canalizaciones declarativas de Lakeflow
Delta admite el flujo de datos modificados (CDF) y table_change puede consultar la modificación de la tabla en SQL y Python. Sin embargo, el uso principal de CDF es registrar las modificaciones en una canalización y no crear una vista completa de los cambios de la tabla desde el inicio.
Las cosas se vuelven especialmente complejas de implementar si hay eventos desordenados. Si debe secuenciar los cambios por una marca de tiempo y recibir una modificación que se produjo en el pasado, debe anexar una nueva entrada en la tabla SCD y actualizar las entradas anteriores.
Lakeflow Declarative Pipelines elimina esta complejidad y le permite crear una tabla independiente que contenga todas las modificaciones desde el principio de los tiempos. A continuación, esta tabla se puede utilizar a gran escala, con particiones específicas o columnas de orden z, si es necesario. Los campos desordenados se controlarán de forma predeterminada en función de la _sequence_by
Para crear una tabla SCD2, debemos usar la opción: STORED AS SCD TYPE 2 en SQL o stored_as_scd_type="2" en Python.
Nota:
También puede limitar las columnas que la característica rastrea mediante la opción: TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
Haga clic en Editar e insertar celda a continuación para insertar una nueva celda vacía.
Copie y pegue el código siguiente en la nueva celda del cuaderno.
Pitón
# create the table dlt.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dlt.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW cusotmers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;Haga clic en Iniciar para iniciar una actualización de la canalización conectada.
Paso 6: Crear una vista materializada que realice un seguimiento de quién ha cambiado más su información.
La tabla customers_history contiene todos los cambios históricos que ha realizado un usuario en su información. Ahora creará una vista materializada simple en la capa dorada que realiza un seguimiento de quién ha cambiado su información más. Esto podría usarse para el análisis de detección de fraudes o las recomendaciones de usuario en un escenario real. Además, la aplicación de cambios con SCD2 ya ha quitado duplicados para nosotros, por lo que podemos contar directamente las filas por ID de usuario.
Haga clic en Editar e insertar celda a continuación para insertar una nueva celda vacía.
Copie y pegue el código siguiente en la nueva celda del cuaderno.
Pitón
@dlt.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( dlt.read("customers_history") .groupBy("id") .agg( count("address").alias("address_count"), count("email").alias("email_count"), count("firstname").alias("firstname_count"), count("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count("address") as address_count, count("email") AS email_count, count("firstname") AS firstname_count, count("lastname") AS lastname_count FROM customers_history GROUP BY idHaga clic en Iniciar para iniciar una actualización de la canalización conectada.
Paso 7: Crear un trabajo para ejecutar la canalización ETL
A continuación, cree un flujo de trabajo para automatizar los pasos de ingesta, procesamiento y análisis de datos mediante un trabajo de Databricks.
- En el área de trabajo, haga clic en Trabajos y canalizaciones en la barra lateral.
- En Nuevo, haga clic en Trabajo.
- En el cuadro de título de la tarea, reemplace Nueva fecha y hora< del trabajo > por el nombre del trabajo. Por ejemplo:
CDC customers workflow. - En el campo Nombre de tarea, escriba el nombre de la primera tarea, por ejemplo,
ETL_customers_data. - En Tipo, seleccione Canalización.
- En Canalización, seleccione la canalización que creó en el paso 1.
- Haga clic en Crear.
- Para ejecutar el flujo de trabajo, haga clic en Ejecutar ahora. Para ver los detalles de la ejecución, haga clic en la pestaña Ejecuciones . Haga clic en la tarea para ver los detalles de la ejecución de la tarea.
- Para ver los resultados cuando se completa el flujo de trabajo, haga clic en Ir a la última ejecución correcta o la hora de inicio de la ejecución del trabajo. Aparece la página Salida y muestra los resultados de la consulta.
Consulte Supervisión y observabilidad de trabajos de Lakeflow para más información sobre las ejecuciones de tareas.
Paso 8: Programar el trabajo
Para ejecutar la canalización de ETL según una programación, siga estos pasos:
- Haga clic en el Trabajos y canalizaciones en la barra lateral.
- Opcionalmente, seleccione los filtros Trabajos y Propiedad de mí .
- En la columna Nombre , haga clic en el nombre del trabajo. El panel lateral aparece como detalles del trabajo.
- Haga clic en Agregar desencadenador en el panel Programaciones y desencadenadores y seleccione Programado en Tipo de desencadenador.
- Especifique el período, la hora de inicio y la zona horaria.
- Haz clic en Guardar.