Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Obtenga información sobre la cloudFiles.useManagedFileEvents opción con Auto Loader, que proporciona una detección de archivos eficaz.
¿Cómo funciona Auto Loader con eventos de archivo?
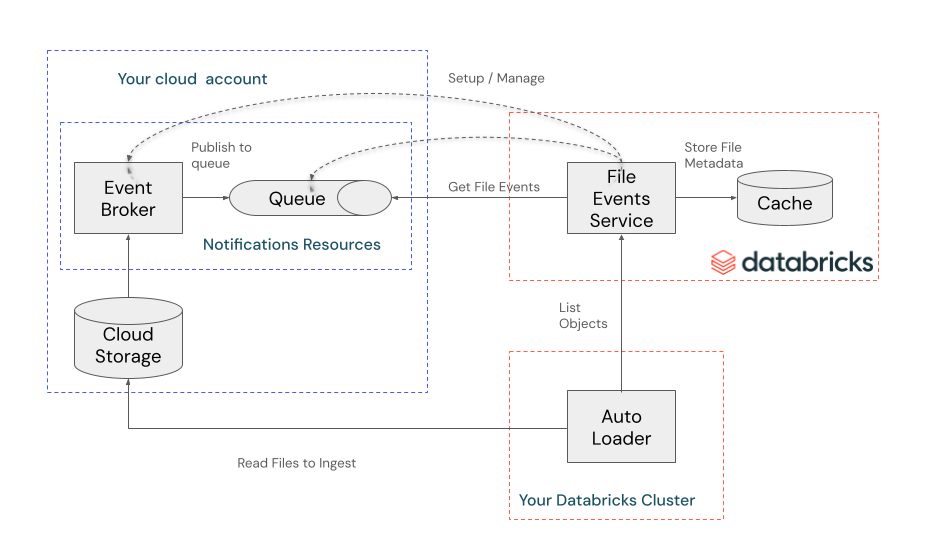
El cargador automático con eventos de archivo usa la funcionalidad de notificaciones de eventos de archivo proporcionada por proveedores en la nube. Puede configurar contenedores de almacenamiento en la nube para publicar notificaciones en eventos de archivo, como la creación y modificación de archivos nuevos. Por ejemplo, con las notificaciones de eventos de Amazon S3, una nueva llegada de archivos puede desencadenar una notificación a un tema de Amazon SNS. Una cola de Amazon SQS se puede suscribir al tópico de SNS para el procesamiento asincrónico del evento.
En el diagrama siguiente se muestra este patrón:

Los eventos de archivo de Databricks son un servicio que configura recursos en la nube para monitorizar eventos de archivo. Como alternativa, puede configurar los recursos en la nube usted mismo y proporcionar su propia cola de almacenamiento.
Una vez configurados los recursos en la nube, el servicio escucha los eventos de archivo y almacena en caché la información de metadatos del archivo. Auto Loader usa esta memoria caché para detectar archivos cuando se ejecuta con el cloudFiles.useManagedFileEvents establecido en true.
En el diagrama siguiente se muestran estas interacciones:
Cuando una secuencia se ejecuta por primera vez con cloudFiles.useManagedFileEvents establecido en true, Auto Loader realiza una lista completa de directorios de la ruta de acceso de carga para detectar todos los archivos y sincronizarse con la memoria caché de eventos de archivos (asegurar una posición de lectura válida en la memoria caché y almacenarla en el punto de control de la secuencia). Las ejecuciones posteriores de Auto Loader detectan nuevos archivos leyendo directamente desde la memoria caché de eventos de archivo mediante la posición de lectura almacenada y no requieren la lista de directorios.
Se recomienda ejecutar las secuencias del cargador automático al menos una vez cada 7 días para aprovechar la detección incremental de archivos de la memoria caché. Si no ejecuta Auto Loader con esta frecuencia, la posición de lectura almacenada deja de ser válida y Auto Loader debe realizar un listado completo del directorio para ponerse al día con la memoria caché de eventos de archivo.
¿Cuándo usa Auto Loader con eventos de archivo la lista de directorios?
Auto Loader realiza una lista de directorios completa cuando:
- Inicio de una nueva transmisión
- Migración de una secuencia desde una lista de directorios o notificaciones de archivos heredadas
- Se cambia la ruta de carga de un flujo
- El cargador automático con eventos de archivo no se ejecuta durante más de 7 días.
- Las actualizaciones en la ubicación externa invalidan la posición de lectura de Auto Loader. Algunos ejemplos son cuando los eventos de archivo están desactivados y activados de nuevo, cuando se cambia la ruta de acceso de la ubicación externa o cuando se proporciona una cola diferente para la ubicación externa.
Auto Loader siempre realiza una lista completa en la primera ejecución, incluso cuando includeExistingFiles se establece en false. Este indicador le permite ingerir todos los archivos creados después de la hora de inicio de la secuencia. Auto Loader enumera todo el directorio para detectar todos los archivos creados después de la hora de inicio de la secuencia, proteger una posición de lectura en la caché de eventos de archivo y almacenarlo en el punto de control. Las ejecuciones posteriores leen directamente desde la memoria caché de eventos de archivo y no requieren una lista de directorios.
El servicio de eventos de archivos de Databricks también realiza listas de directorios completas periódicamente en la ubicación externa para confirmar que no ha perdido ningún archivo (por ejemplo, si la cola proporcionada está mal configurada). Las primeras listas de directorios completos comienzan en cuanto se habilitan los eventos de archivo en la ubicación externa. Las listados subsecuentes se producen periódicamente siempre que haya al menos un flujo de Auto Loader utilizando eventos de archivo para la ingesta de datos.
Procedimientos recomendados para el cargador automático con eventos de archivo
Siga estos procedimientos recomendados para optimizar el rendimiento y la confiabilidad al usar Auto Loader con eventos de archivo.
Uso de volúmenes para una detección de archivos óptima
Para obtener un rendimiento mejorado, Databricks recomienda crear un volumen externo para cada ruta de acceso o subdirectorio desde el cual Auto Loader carga datos y proporcionar rutas de acceso de volumen (por ejemplo, /Volumes/someCatalog/someSchema/someVolume) a Auto Loader en lugar de rutas de acceso a la nube (por ejemplo, s3://bucket/path/to/volume). Esto optimiza la detección de archivos porque Auto Loader puede enumerar el volumen mediante un patrón de acceso a datos optimizado.
Considere usar activadores de llegada de archivos para canalizaciones impulsadas por eventos
En el caso del procesamiento de datos controlado por eventos, considere la posibilidad de usar un desencadenador de llegada de archivos en lugar de una canalización continua. Los desencadenadores de llegada de archivos inician automáticamente la canalización cuando llegan nuevos archivos, lo que proporciona un mejor uso de los recursos y la eficiencia de los costos, ya que el clúster solo se ejecuta cuando hay nuevos archivos que procesar.
Configura intervalos adecuados con desencadenadores continuos
Se recomienda usar desencadenadores de llegada de archivos para procesar archivos tan pronto como lleguen. Sin embargo, si el caso de uso requiere el uso de desencadenadores continuos como Trigger.ProcessingTime, se recomienda configurar los intervalos de desencadenador en 1 minute o superior (se establece mediante pipelines.trigger.interval cuando se usan canalizaciones declarativas de Spark de Lakeflow). Esto reduce la frecuencia de consulta para comprobar si han llegado nuevos archivos y permite que un mayor número de secuencias se ejecuten simultáneamente desde el espacio de trabajo.
Limitaciones del cargador automático con eventos de archivo
- No se admiten reescrituras de ruta. Las reescrituras de ruta de acceso se usan cuando se montan múltiples buckets o contenedores en DBFS, que es un patrón de uso obsoleto.
Para obtener una lista general de las limitaciones de los eventos de archivo, consulte Limitaciones de eventos de archivo.
Preguntas más frecuentes
Encuentren respuestas a las preguntas más frecuentes acerca de Auto Loader con eventos de archivos.
¿Cómo puedo confirmar que los eventos de archivo están configurados correctamente?
Haga clic en el botón Probar conexión en la página de ubicación externa. Si los eventos de archivo están configurados correctamente, verá una marca de verificación verde para el elemento de lectura de eventos de archivo . Si acaba de crear la ubicación externa y ha habilitado los eventos de archivo en el modo Automatic, la prueba muestra Skipped mientras Databricks configura notificaciones para la ubicación externa. Espere unos minutos y, a continuación, haga clic en Probar conexión de nuevo. Si Databricks no tiene los permisos necesarios para configurar o leer eventos de archivo, verá un error para el elemento de lectura de eventos de archivo .
¿Puedo evitar una lista de directorios completa durante la ejecución inicial?
No. Incluso si includeExistingFiles se establece en false, el cargador automático realiza un listado de directorios para descubrir los archivos creados después del inicio de la secuencia y sincronizarse con la memoria caché de eventos de archivo (asegurar una posición de lectura válida en la memoria caché y almacenarla en el punto de control de la secuencia).
¿Debo establecer cloudFiles.backfillInterval para evitar que falten archivos?
No. Esta configuración se recomienda para el modo de notificación de archivos heredado porque los sistemas de notificaciones de almacenamiento en la nube podrían dar lugar a archivos que faltan o llegan tarde. Ahora, Databricks realiza listas de directorios completas periódicamente en la ubicación externa. Las primeras listas de directorios completos comienzan en cuanto se habilitan los eventos de archivo en la ubicación externa. Listados posteriores periódicamente siempre que haya al menos un flujo de Auto Loader que use eventos de archivo para ingerir datos.
Configuré eventos de archivo con una cola de almacenamiento proporcionada, pero la cola estaba mal configurada y perdí archivos. ¿Cómo puedo asegurarme de que Auto Loader ingiere los archivos que faltan cuando mi cola estaba mal configurada?
En primer lugar, confirme que la desconfiguración de la cola proporcionada está corregida. Para comprobarlo, haga clic en el botón Probar conexión en la página de ubicación externa. Si los eventos de archivo están configurados correctamente, verá una marca de verificación verde para el elemento de lectura de eventos de archivo .
Databricks realiza una lista completa de directorios para ubicaciones externas con eventos de archivo habilitados. Esta lista de directorios detecta los archivos que se han perdido durante el período de configuración incorrecta y los almacena en la caché de eventos de archivo.
Una vez corregido el error de configuración y Databricks completa la lista de directorios, Auto Loader seguirá leyendo desde la memoria caché de eventos de archivo e ingerirá automáticamente los archivos que faltan durante el período de configuración incorrecta.
¿Cómo obtiene Databricks los permisos para crear recursos en la nube y leer y eliminar mensajes de la cola?
Databricks usa los permisos concedidos en la credencial de almacenamiento asociada a la ubicación externa en la que se habilitan los eventos de archivo.