Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
La captura de datos modificados (CDC) es un patrón de integración de datos que captura los cambios realizados en los datos de un sistema de origen, como inserciones, actualizaciones y eliminaciones. Estos cambios, representados como una lista, se conocen normalmente como una fuente CDC. Puede procesar los datos mucho más rápido si utiliza un flujo CDC, en lugar de leer todo el conjunto de datos de origen. Las bases de datos transaccionales, como SQL Server, MySQL y Oracle, generan fuentes CDC. Las tablas delta generan su propia fuente CDC, conocida como fuente de distribución de datos modificados (CDF).
En el diagrama siguiente se muestra que cuando se actualiza una fila de una tabla de origen que contiene datos de empleado, genera un nuevo conjunto de filas en una fuente CDC que contiene solo los cambios. Cada fila de la fuente de datos CDC normalmente contiene metadatos adicionales, incluida la operación como UPDATE y una columna que se puede usar para ordenar de forma determinista cada fila de la fuente CDC, de manera que puedas manejar las actualizaciones fuera de orden. Por ejemplo, la columna sequenceNum del diagrama siguiente determina el orden de las filas en la fuente CDC.
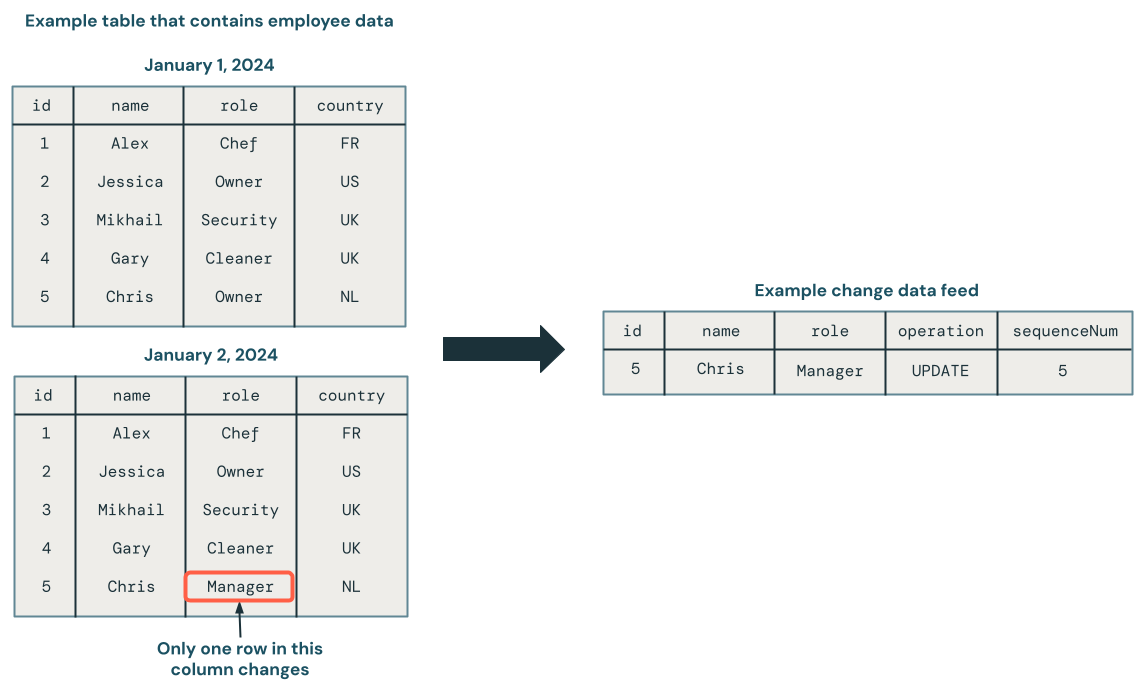
Procesamiento de un flujo de datos de cambios: mantenga solo los datos más recientes frente a mantener versiones anteriores de los datos.
El procesamiento de un flujo de datos modificado se conoce como dimensiones de variación lenta (SCD). Al procesar una fuente CDC, tiene la opción de hacer lo siguiente:
- ¿Mantiene solo los datos más recientes (es decir, sobrescribir los datos existentes)? Esto se conoce como tipo SCD 1.
- O bien, ¿mantiene un historial de cambios en los datos? Esto se conoce como tipo SCD 2.
El procesamiento del tipo 1 de SCD implica sobrescribir los datos antiguos con nuevos datos cada vez que se produce un cambio. Esto significa que no se mantiene ningún historial de los cambios. Solo está disponible la versión más reciente de los datos. Se trata de un enfoque sencillo y se suele usar cuando el historial de cambios no es importante, como corregir errores o actualizar campos no críticos, como direcciones de correo electrónico del cliente.
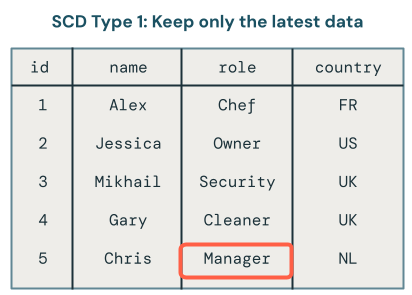
El procesamiento del tipo 2 de SCD mantiene un registro histórico de los cambios de datos mediante la creación de registros adicionales para capturar diferentes versiones de los datos a lo largo del tiempo. Cada versión de los datos tiene una marca de tiempo o se etiqueta con metadatos que permite a los usuarios realizar un seguimiento cuando se produce un cambio. Esto resulta útil cuando es importante realizar un seguimiento de la evolución de los datos, como el seguimiento de los cambios de dirección del cliente a lo largo del tiempo con fines de análisis.
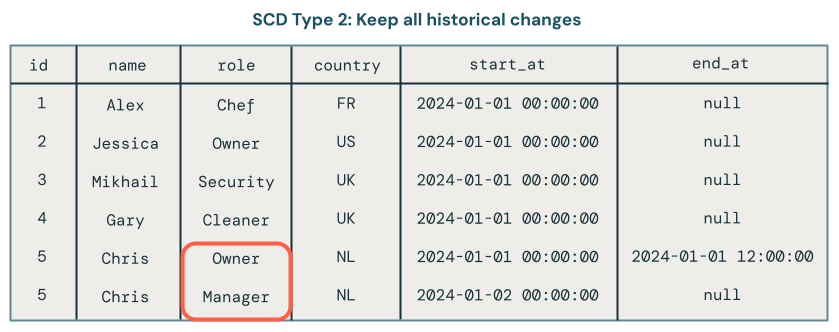
Ejemplos de procesamiento SCD Tipo 1 y Tipo 2 con canalizaciones declarativas Lakeflow Spark
Los ejemplos de esta sección muestran cómo usar SCD Type 1 y Type 2.
Paso 1: Preparación de los datos de ejemplo
En este ejemplo, creará un flujo CDC de muestra. En primer lugar, cree un cuaderno y pegue el código siguiente en él. Actualice las variables al principio del bloque de código a un catálogo y un esquema donde tenga permiso para crear tablas y vistas.
Este código crea una nueva tabla Delta que contiene varios registros de cambios. El esquema es el siguiente:
-
id- Entero, identificador único de este empleado -
name- cadena, nombre del empleado -
role- Rol de empleado, String -
country- Cadena, código de país, donde trabaja el empleado -
operation- Cambiar tipo(por ejemplo,INSERT,UPDATEoDELETE) -
sequenceNum- Entero, identifica el orden lógico de los eventos CDC en los datos de origen. Las canalizaciones declarativas de Spark de Lakeflow usan esta secuenciación para controlar los eventos de cambio que llegan fuera de orden.
# update these to the catalog and schema where you have permissions
# to create tables and views.
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
def write_employees_cdf_to_delta():
data = [
(1, "Alex", "chef", "FR", "INSERT", 1),
(2, "Jessica", "owner", "US", "INSERT", 2),
(3, "Mikhail", "security", "UK", "INSERT", 3),
(4, "Gary", "cleaner", "UK", "INSERT", 4),
(5, "Chris", "owner", "NL", "INSERT", 6),
# out of order update, this should be dropped from SCD Type 1
(5, "Chris", "manager", "NL", "UPDATE", 5),
(6, "Pat", "mechanic", "NL", "DELETE", 8),
(6, "Pat", "mechanic", "NL", "INSERT", 7)
]
columns = ["id", "name", "role", "country", "operation", "sequenceNum"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.{employees_cdf_table}")
write_employees_cdf_to_delta()
Puede obtener una vista previa de estos datos mediante el siguiente comando SQL:
SELECT *
FROM mycatalog.myschema.employees_cdf
Paso 2: Uso del tipo 1 de SCD para mantener solo los datos más recientes
Se recomienda usar la AUTO CDC API en canalizaciones declarativas de Lakeflow Spark para procesar una fuente de datos de cambio en una tabla SCD Type 1.
- Creación de un cuaderno.
- Pegue el código siguiente en él.
- Cree y conéctese a una canalización.
La employees_cdf función lee la tabla que acabamos de crear anteriormente como una secuencia porque la create_auto_cdc_flow API, que usará para el procesamiento de captura de datos modificados, espera un flujo de cambios como entrada. Lo encapsulas con un decorador @dp.temporary_view porque no quieres materializar esta secuencia en una tabla.
A continuación, se usa dp.create_target_table para crear una tabla de streaming que contenga el resultado del procesamiento de esta fuente de datos de cambios.
Por último, se usa dp.create_auto_cdc_flow para procesar el flujo de datos de cambios. Echemos un vistazo a cada argumento:
-
target: la tabla de streaming de destino, que definió anteriormente. -
source- Vista sobre el flujo de registros de cambios, que definió anteriormente. -
keys- Identifica filas únicas en la fuente de cambios. Dado que usaidcomo identificador único, solo debe proporcionaridcomo la única columna de identificación. -
sequence_by: el nombre de columna que especifica el orden lógico de los eventos CDC en los datos de origen. Necesita esta secuenciación para controlar los eventos de cambio que llegan fuera del orden. ProporcionesequenceNumcomo columna de secuenciación. -
apply_as_deletes- Dado que los datos de ejemplo contienen operaciones de eliminación, se utilizaapply_as_deletespara indicar cuándo un evento CDC debe tratarse comoDELETEen lugar de un upsert. -
except_column_list: contiene una lista de columnas que no desea incluir en la tabla de destino. En este ejemplo, usará este argumento para excluirsequenceNumyoperation. -
stored_as_scd_type: indica el tipo scD que desea usar.
from pyspark import pipelines as dp
from pyspark.sql.functions import col, expr, lit, when
from pyspark.sql.types import StringType, ArrayType
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table_current = "employees_current"
employees_table_historical = "employees_historical"
@dp.temporary_view
def employees_cdf():
return spark.readStream.format("delta").table(f"{catalog}.{schema}.{employees_cdf_table}")
dp.create_target_table(f"{catalog}.{schema}.{employees_table_current}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_current}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
Ejecute esta canalización haciendo clic en Iniciar.
A continuación, ejecute la consulta siguiente en el editor de SQL para comprobar que los registros de cambios se han procesado correctamente:
SELECT *
FROM mycatalog.myschema.employees_current
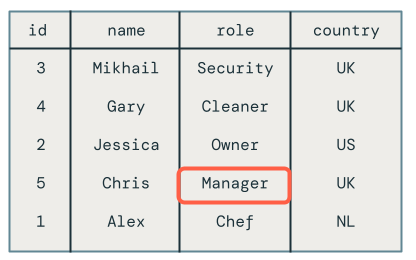
Nota:
La actualización fuera de orden para el empleado Chris se quitó correctamente, ya que su rol todavía está establecido en Propietario en vez de Gerente.
Paso 3: Uso del tipo 2 de SCD para mantener los datos históricos
En este ejemplo, creará una segunda tabla de destino, denominada employees_historical, que contiene un historial completo de cambios en los registros de empleados.
Agregue este código a la canalización. La única diferencia aquí es que stored_as_scd_type se establece en 2 en lugar de 1.
dp.create_target_table(f"{catalog}.{schema}.{employees_table_historical}")
dp.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_historical}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 2
)
Ejecute esta canalización haciendo clic en Iniciar.
A continuación, ejecute la consulta siguiente en el editor de SQL para comprobar que los registros de cambios se han procesado correctamente:
SELECT *
FROM mycatalog.myschema.employees_historical
Verá todos los cambios en los empleados, incluidos los empleados que se eliminaron, como Pat.
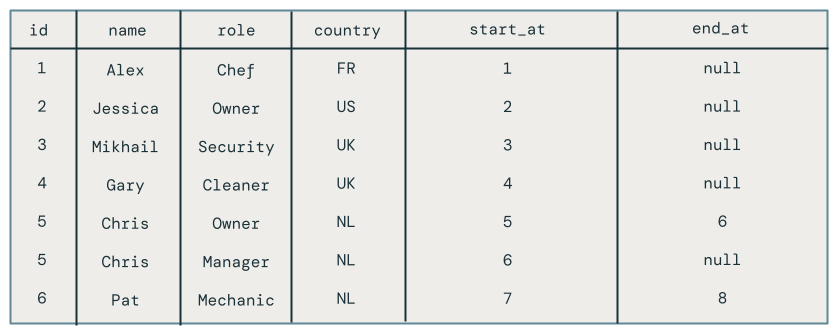
Paso 4: Limpieza de recursos
Cuando haya terminado, limpie los recursos siguiendo estos pasos:
Elimine la canalización:
Nota:
Al eliminar la canalización, se eliminan automáticamente las tablas
employeesyemployees_historical.- Haga clic en Trabajos y canalizaciones y busque el nombre de la canalización que se va a eliminar.
- Haga clic en el
 En la misma fila que el nombre de la canalización, haga clic en Eliminar.
En la misma fila que el nombre de la canalización, haga clic en Eliminar.
Elimine el cuaderno.
Elimine la tabla que contiene el flujo de datos de cambios:
- Haga clic en Nueva > consulta.
- Pegue y ejecute el código SQL siguiente, ajustando el catálogo y el esquema según corresponda:
DROP TABLE mycatalog.myschema.employees_cdf
Desventajas del uso MERGE INTO y foreachBatch de la captura de datos modificados
Databricks proporciona un comando SQL MERGE INTO que se puede usar con la API foreachBatch para insertar o actualizar filas en una tabla Delta. En esta sección se explora cómo se puede usar esta técnica para casos de uso sencillos, pero este método se vuelve cada vez más complejo y frágil cuando se aplica a escenarios reales.
En este ejemplo, utilizará el mismo flujo de datos de cambios de ejemplo que se utilizó en los ejemplos anteriores.
Implementación naive con MERGE INTO y foreachBatch
Cree un cuaderno y copie el código siguiente en él. Cambie las catalogvariables , schemay employees_table según corresponda. Las catalog variables y schema deben establecerse en ubicaciones del catálogo de Unity, donde puede crear tablas.
Al ejecutar el cuaderno, hace lo siguiente:
- Crea la tabla de destino en el
create_table. A diferencia decreate_auto_cdc_flow, que controla este paso automáticamente, debe especificar el esquema. - Lee el flujo de datos de cambios como un flujo. Cada microbatch se procesa mediante el
upsertToDeltamétodo , que ejecuta unMERGE INTOcomando .
catalog = "jobs"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table = "employees_merge"
def upsertToDelta(microBatchDF, batchId):
microBatchDF.createOrReplaceTempView("updates")
microBatchDF.sparkSession.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING)
""")
create_table()
cdcData = spark.readStream.table(f"{catalog}.{schema}.{employees_cdf_table}")
cdcData.writeStream \
.foreachBatch(upsertToDelta) \
.outputMode("append") \
.start()
Para ver los resultados, ejecute la siguiente consulta SQL:
SELECT *
FROM mycatalog.myschema.employees_merge
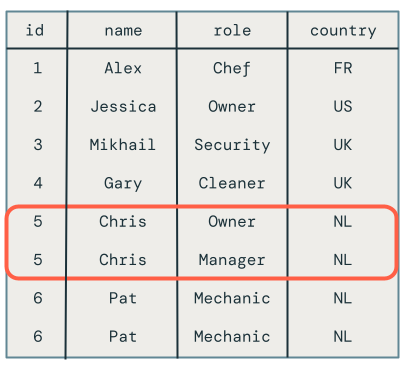
Desafortunadamente, los resultados son incorrectos, como se muestra a continuación:
Varias actualizaciones de la misma clave en el mismo microbatch
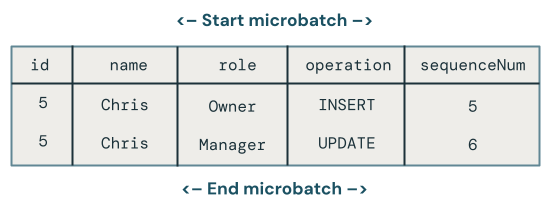
El primer problema es que el código no controla varias actualizaciones de la misma clave en el mismo microbatch. Por ejemplo, se usa INSERT para insertar el empleado Chris y, a continuación, actualizar su rol de Propietario a Administrador. Esto debería dar lugar a una fila, pero en su lugar hay dos filas.
¿Qué cambio gana cuando hay varias actualizaciones en la misma clave en un microbatch?
La lógica se vuelve más compleja. En el ejemplo de código siguiente, se recupera la fila más reciente por sequenceNum y solo combina esos datos en la tabla de destino de la siguiente manera:
- Agrupar por la clave principal,
id. - Toma todas las columnas de la fila que tiene el máximo
sequenceNumen el lote para dicha clave. - Explota la fila de vuelta.
Actualice el upsertToDelta método como se muestra a continuación y ejecute el código:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
Al consultar la tabla de destino, verá que el empleado llamado Chris tiene el rol correcto, pero todavía hay otros problemas para resolver porque todavía tiene registros eliminados que se muestran en la tabla de destino.
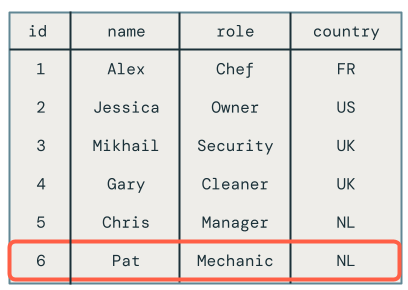
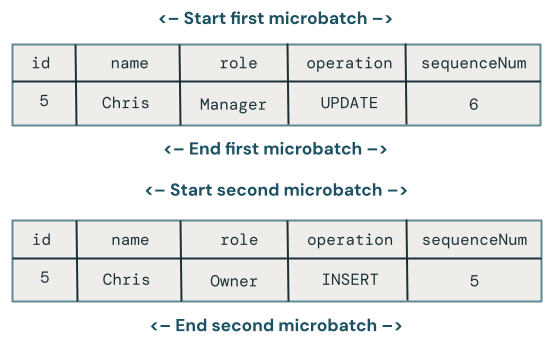
Actualizaciones desordenadas en microbatches
En esta sección se explora el problema de las actualizaciones desordenadas en microbatches. En el diagrama siguiente se muestra el problema: ¿qué ocurre si la fila de Chris tiene una UPDATE operación en el primer microbatch seguida de una INSERT en un microbatch posterior? El código no controla esto correctamente.
¿Qué cambio gana cuando hay actualizaciones desordenadas en la misma clave en varios microbatches?
Para corregirlo, expanda el código para almacenar una versión en cada fila de la siguiente manera:
- Almacene el objeto
sequenceNumcuando se actualizó por última vez una fila. - Para cada nueva fila, compruebe si la marca de tiempo es mayor que la almacenada y, a continuación, aplique la siguiente lógica:
- Si es mayor, utilice los nuevos datos del objetivo.
- De lo contrario, mantenga los datos en el origen.
En primer lugar, actualice el createTable método para almacenar sequenceNum , ya que lo usará para versionar cada fila:
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING, sequenceNum INT)
""")
A continuación, actualice upsertToDelta para controlar las versiones de fila. La cláusula UPDATE SET de MERGE INTO debe gestionar cada columna por separado.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Gestión de eliminaciones
Desafortunadamente, el código sigue teniendo un problema. No gestiona las operaciones DELETE, como se evidencia en el hecho de que el empleado Pat todavía está en la tabla de destino.
Supongamos que las eliminaciones llegan al mismo microbatch. Para controlarlos, actualice el upsertToDelta método de nuevo para eliminar la fila cuando el registro de datos modificados indique la eliminación, como se muestra a continuación:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN DELETE
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Control de las actualizaciones que llegan fuera de orden después de las eliminaciones
Desafortunadamente, el código anterior todavía no es del todo correcto porque no maneja los casos en los que un DELETE es seguido por un UPDATE desordenado a través de microbatches.
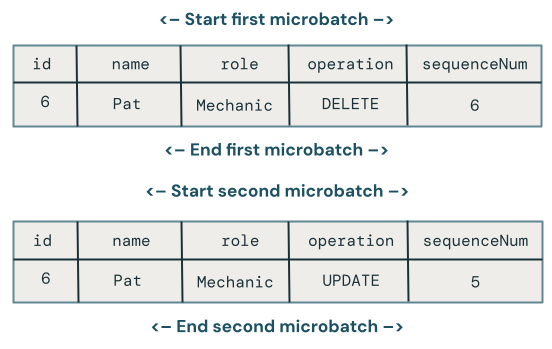
El algoritmo para manejar este caso debe recordar las eliminaciones para que pueda manejar las actualizaciones posteriores desordenadas. Para ello, siga estos pasos:
- En lugar de eliminar filas inmediatamente, elimínelas temporalmente con una marca de tiempo o
sequenceNum. Las filas eliminadas temporalmente se marcan como eliminadas. - Redirigir a todos los usuarios a una vista que filtre las lápidas.
- Cree un trabajo de limpieza que quite los lápidas a lo largo del tiempo.
Use el código siguiente:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN UPDATE SET DELETED_AT=now()
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Los usuarios no pueden usar la tabla de destino directamente, así que cree una vista que pueda consultar:
CREATE VIEW employees_v AS
SELECT * FROM employees_merge
WHERE DELETED_AT = NULL
Por último, cree un trabajo de limpieza que quite periódicamente las filas marcadas como eliminadas.
DELETE FROM employees_merge
WHERE DELETED_AT < now() - INTERVAL 1 DAY