Uso de tablas en línea para el servicio de características en tiempo real
Importante
Las tablas en línea se encuentran en versión preliminar pública en las siguientes regiones: westus, eastus, eastus2, northeurope, . westeurope Para obtener información sobre los precios, consulte Precios de tablas en línea.
Una tabla en línea es una copia de solo lectura de una tabla delta que se almacena en formato orientado a filas optimizada para el acceso en línea. Las tablas en línea son tablas totalmente sin servidor que escalan automáticamente la capacidad de rendimiento con la carga de solicitudes y proporcionan baja latencia y acceso de alto rendimiento a los datos de cualquier escala. Las tablas en línea están diseñadas para trabajar con Mosaic AI Model Serving, Feature Serving y las aplicaciones de generación aumentada de recuperación (RAG), donde se usan para realizar búsquedas rápidas de datos.
También puede usar tablas en línea en consultas mediante la federación de Lakehouse. Al usar la federación de Lakehouse, debe usar un almacén de SQL sin servidor para acceder a las tablas en línea. Solo se admiten las operaciones de lectura (SELECT). Esta funcionalidad está pensada solo para fines interactivos o de depuración y no debe usarse para cargas de trabajo críticas o de producción.
La creación de una tabla en línea mediante la interfaz de usuario de Databricks es un proceso de un solo paso. Solo tiene que seleccionar la tabla Delta en el Explorador de catálogos y seleccionar Crear tabla en línea. También puede usar la API de REST o el SDK de Databricks para crear y administrar tablas en línea. Consulte Trabajar con tablas en línea mediante las API.
Requisitos
- El área de trabajo debe estar habilitada para Unity Catalog. Siga la documentación para crear un Metastore de Unity Catalog, habilitarlo en un área de trabajo y crear un catálogo.
- Un modelo debe registrarse en el Catálogo de Unity para acceder a las tablas en línea.
Trabajar con tablas en línea mediante la interfaz de usuario
En esta sección se describe cómo crear y eliminar tablas en línea y cómo comprobar el estado y desencadenar actualizaciones de tablas en línea.
Crear una tabla en línea mediante la interfaz de usuario
Puede crear una tabla en línea mediante Catalog Explorer. Para obtener información sobre los permisos necesarios, vea Permisos de usuario.
Para crear una tabla en línea, la tabla Delta de origen debe tener una clave principal. Si la tabla Delta que desea usar no tiene una clave principal, cree una siguiendo estas instrucciones: Uso de una tabla Delta existente en Unity Catalog como tabla de características.
En Catalog Explorer, vaya a la tabla de origen que desea sincronizar con una tabla en línea. En el menú Crear, seleccione Tabla en línea.
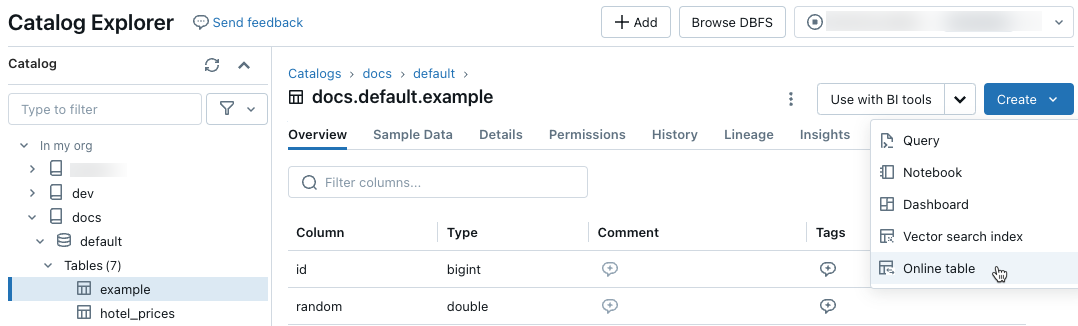
Use los selectores del cuadro de diálogo para configurar la tabla en línea.
Nombre: Nombre que se usará para la tabla en línea en Catalog Explorer.
Clave principal: Columnas de la tabla de origen que se van a usar como claves principales en la tabla en línea.
Clave timeseries: (opcional). Columna de la tabla de origen que se va a usar como clave timeseries. Cuando se especifica, la tabla en línea solo incluye la fila con el valor de clave timeseries más reciente para cada clave principal.
Modo de sincronización: especifica cómo la canalización de sincronización actualiza la tabla en línea. Seleccione una de las instantáneas, desencadenadaso Continuas.
Directiva Descripción Snapshot La canalización se ejecuta una vez para tomar una instantánea de la tabla de origen y copiarla en la tabla en línea. Los cambios posteriores en la tabla de origen se reflejan automáticamente en la tabla en línea tomando una nueva instantánea del origen y creando una nueva copia. El contenido de la tabla en línea se actualiza de forma atómica. Desencadenado La canalización se ejecuta una vez para crear una copia de instantánea inicial de la tabla de origen en la tabla en línea. A diferencia del modo de sincronización de instantáneas, cuando se actualiza la tabla en línea, solo se recuperan los cambios desde la última ejecución de la canalización y se aplican a la tabla en línea. La actualización incremental se puede desencadenar manualmente o desencadenarse automáticamente según una programación. Continuo La canalización se ejecuta continuamente. Los cambios posteriores en la tabla de origen se aplican incrementalmente a la tabla en línea en modo de streaming en tiempo real. No es necesario actualizar manualmente.
Nota:
Para admitir desencadenado o modo de sincronización continua, la tabla de origen debe tener fuente de distribución de datos modificado habilitado.
- Cuando haya terminado, haga clic en Confirmar. Aparece la página de la tabla en línea.
- La nueva tabla en línea se crea en el catálogo, el esquema y el nombre especificados en el cuadro de diálogo de creación. En el Explorador de catálogos, la tabla en línea se indica mediante
 .
.
Obtención del estado y desencadenamiento de actualizaciones mediante la interfaz de usuario
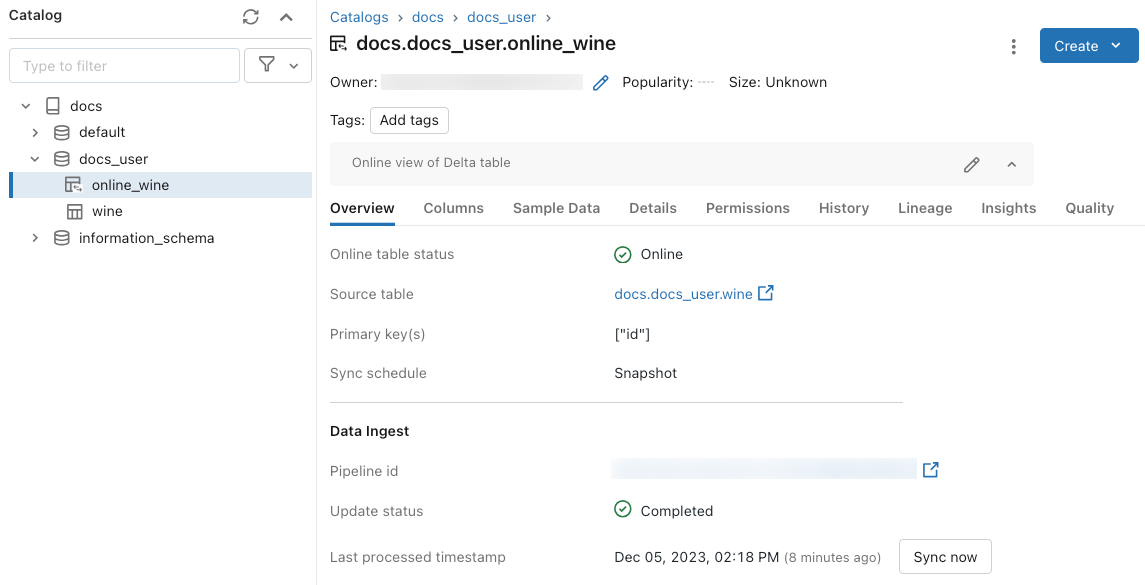
Para comprobar el estado de la tabla en línea, haga clic en el nombre de la tabla en el Catálogo para abrirla. Aparece la página de la tabla en línea con la pestaña Información general abierta. La sección Ingesta de datos muestra el estado de la actualización más reciente. Para desencadenar una actualización, haga clic en Sincronizar ahora. La sección Ingesta de datos también incluye un vínculo a la canalización de Delta Live Tables que actualiza la tabla.
Programar actualizaciones periódicas
En el caso de las tablas en línea con el modo de sincronización instantánea o desencadenada , puede programar actualizaciones periódicas automáticas. La programación de actualizaciones se administra mediante la canalización de Delta Live Tables que actualiza la tabla.
- En el Explorador de catálogos, vaya a la tabla en línea.
- En la sección Ingesta de datos , haga clic en el vínculo a la canalización.
- En la esquina superior derecha, haga clic en Programación y agregue una nueva programación o actualice las programaciones existentes.
Eliminación de una tabla en línea mediante la interfaz de usuario
En la página de la tabla en línea, seleccione Eliminar en el menú ![]() kebab.
kebab.
Trabajar con tablas en línea mediante API
También puede usar el SDK de Databricks o la API de REST para crear y administrar tablas en línea.
Para obtener información de referencia, consulte la documentación de referencia del SDK de Databricks para Python o la API de REST.
Requisitos
SDK de Databricks versión 0.20 o posterior.
Crear una tabla en línea mediante las API
SDK de Databricks: Python
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import *
w = WorkspaceClient(host='https://xxx.databricks.com', token='xxx')
# Create an online table
spec = OnlineTableSpec(
primary_key_columns=["pk_col"],
source_table_full_name="main.default.source_table",
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'})
)
online_table = OnlineTable(
name="main.default.my_online_table", # Fully qualified table name
spec=spec # Online table specification
)
w.online_tables.create_and_wait(table=online_table)
REST API
curl --request POST "https://xxx.databricks.com/api/2.0/online-tables" \
--header "Authorization: Bearer xxx" \
--data '{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["a"]
}
}'
La tabla en línea inicia automáticamente la sincronización después de su creación.
Obtención del estado y desencadenamiento de la actualización mediante las API
Es posible ver el estado y la especificación de la tabla en línea siguiendo el ejemplo siguiente. Si la tabla en línea no fuera continua y quisiera desencadenar una actualización manual de sus datos, use la API de canalización para hacerlo.
Use el identificador de canalización asociado a la tabla en línea en la especificación de tabla en línea e inicie una nueva actualización en la canalización para desencadenar la actualización. Esto equivale a hacer clic en Sincronizar ahora en la interfaz de usuario de la tabla en línea en el Explorador de catálogos.
SDK de Databricks: Python
pprint(w.online_tables.get('main.default.my_online_table'))
# Sample response
OnlineTable(name='main.default.my_online_table',
spec=OnlineTableSpec(perform_full_copy=None,
pipeline_id='some-pipeline-id',
primary_key_columns=['pk_col'],
run_continuously=None,
run_triggered={},
source_table_full_name='main.default.source_table',
timeseries_key=None),
status=OnlineTableStatus(continuous_update_status=None,
detailed_state=OnlineTableState.PROVISIONING,
failed_status=None,
message='Online Table creation is '
'pending. Check latest status in '
'Delta Live Tables: '
'https://xxx.databricks.com/pipelines/some-pipeline-id',
provisioning_status=None,
triggered_update_status=None))
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
w.pipelines.start_update(pipeline_id='some-pipeline-id', full_refresh=True)
REST API
curl --request GET \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
# Sample response
{
"name": "main.default.my_online_table",
"spec": {
"run_triggered": {},
"source_table_full_name": "main.default.source_table",
"primary_key_columns": ["pk_col"],
"pipeline_id": "some-pipeline-id"
},
"status": {
"detailed_state": "PROVISIONING",
"message": "Online Table creation is pending. Check latest status in Delta Live Tables: https://xxx.databricks.com#joblist/pipelines/some-pipeline-id"
}
}
# Trigger an online table refresh by calling the pipeline API. To discard all existing data
# in the online table before refreshing, set "full_refresh" to "True". This is useful if your
# online table sync is stuck due to, for example, the source table being deleted and recreated
# with the same name while the sync was running.
curl --request POST "https://xxx.databricks.com/api/2.0/pipelines/some-pipeline-id/updates" \
--header "Authorization: Bearer xxx" \
--data '{
"full_refresh": true
}'
Eliminación de una tabla en línea mediante las API
SDK de Databricks: Python
w.online_tables.delete('main.default.my_online_table')
REST API
curl --request DELETE \
"https://xxx.databricks.com/api/2.0/online-tables/main.default.my_online_table" \
--header "Authorization: Bearer xxx"
Al eliminar la tabla en línea, se detiene cualquier sincronización de datos en curso y se liberan todos sus recursos.
Servicio de datos de tabla en línea mediante una característica que sirve el punto de conexión
En el caso de los modelos y las aplicaciones hospedadas fuera de Databricks, puede crear un punto de conexión de servicio de características para atender características de tablas en línea. El punto de conexión hace que las características estén disponibles en baja latencia mediante una API REST.
Cree una especificación de características.
Al crear una especificación de característica, especifique la tabla Delta de origen. Esto permite usar la especificación de características tanto en escenarios sin conexión como en línea. Para las búsquedas en línea, el punto de conexión de servicio usa automáticamente la tabla en línea para realizar búsquedas de características de baja latencia.
La tabla Delta de origen y la tabla en línea deben usar la misma clave principal.
La especificación de características se puede ver en la pestaña función del Catalog Explorer.
from databricks.feature_engineering import FeatureEngineeringClient, FeatureLookup fe = FeatureEngineeringClient() fe.create_feature_spec( name="catalog.default.user_preferences_spec", features=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ] )Cree un punto de conexión de servicio de características.
En este paso se supone que ha creado una tabla en línea denominada
user_preferences_online_tableque sincroniza los datos de la tabla Deltauser_preferences. Use la especificación de características para crear un punto de conexión de servicio de características. El punto de conexión hace que los datos estén disponibles a través de una API REST mediante la tabla en línea asociada.Nota:
El usuario que realiza esta operación debe ser el propietario de la tabla sin conexión y la tabla en línea.
SDK de Databricks: Python
from databricks.sdk import WorkspaceClient from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput workspace = WorkspaceClient() # Create endpoint endpoint_name = "fse-location" workspace.serving_endpoints.create_and_wait( name=endpoint_name, config=EndpointCoreConfigInput( served_entities=[ ServedEntityInput( entity_name=feature_spec_name, scale_to_zero_enabled=True, workload_size="Small" ) ] ) )API de Python
from databricks.feature_engineering.entities.feature_serving_endpoint import ( ServedEntity, EndpointCoreConfig, ) fe.create_feature_serving_endpoint( name="user-preferences", config=EndpointCoreConfig( served_entities=ServedEntity( feature_spec_name="catalog.default.user_preferences_spec", workload_size="Small", scale_to_zero_enabled=True ) ) )Obtenga datos del punto de conexión de servicio de características.
Para acceder al punto de conexión de la API, envíe una solicitud HTTP GET a la dirección URL del punto de conexión. En el ejemplo se muestra cómo hacerlo con las API de Python. Para ver otros lenguajes y herramientas, consulte Servicio de características.
# Set up credentials export DATABRICKS_TOKEN=...url = "https://{workspace_url}/serving-endpoints/user-preferences/invocations" headers = {'Authorization': f'Bearer {DATABRICKS_TOKEN}', 'Content-Type': 'application/json'} data = { "dataframe_records": [{"user_id": user_id}] } data_json = json.dumps(data, allow_nan=True) response = requests.request(method='POST', headers=headers, url=url, data=data_json) if response.status_code != 200: raise Exception(f'Request failed with status {response.status_code}, {response.text}') print(response.json()['outputs'][0]['hotel_preference'])
Uso de tablas en línea con aplicaciones RAG
Las aplicaciones RAG son un caso de uso común para las tablas en línea. Puede crear una tabla en línea para los datos estructurados que necesita la aplicación RAG y hospedarla en un punto de conexión de servicio de características. La aplicación RAG usa el punto de conexión de servicio de características para buscar datos relevantes de la tabla en línea.
Los pasos típicos son los siguientes:
- Cree un punto de conexión de servicio de características.
- Cree una herramienta mediante LangChain o cualquier paquete similar que use el punto de conexión para buscar datos relevantes.
- Use la herramienta en un agente de LangChain o un agente similar para recuperar los datos pertinentes.
- Cree un punto de conexión de servicio de modelos para hospedar la aplicación.
Para obtener instrucciones paso a paso y un cuaderno de ejemplo, consulte Ejemplo de ingeniería de características: aplicación RAG estructurada.
Ejemplos de cuadernos
En el cuaderno siguiente se muestra cómo publicar características en tablas en línea para la búsqueda automatizada de características y servicio en tiempo real.
Cuaderno de demostración de tablas en línea
Uso de tablas en línea con Mosaic AI Model Serving
Puede usar tablas en línea para buscar características de Mosaic AI Model Serving. Al sincronizar una tabla de características con una tabla en línea, los modelos entrenados mediante características de esa tabla de características buscan automáticamente los valores de características de la tabla en línea durante la inferencia. No se requiere ninguna configuración adicional.
Use un
FeatureLookuppara entrenar el modelo.Para el entrenamiento del modelo, use características de la tabla de características sin conexión del conjunto de entrenamiento del modelo, como se muestra en el ejemplo siguiente:
training_set = fe.create_training_set( df=id_rt_feature_labels, label='quality', feature_lookups=[ FeatureLookup( table_name="user_preferences", lookup_key="user_id" ) ], exclude_columns=['user_id'], )Sirva el modelo con Mosaic AI Model Serving. El modelo busca automáticamente las características de la tabla en línea. Consulte Búsqueda automática de características con Databricks Model Serving para obtener más información.
Permisos de usuario de
Debe tener los permisos siguientes para crear una tabla en línea:
SELECTprivilegios en la tabla de origen.USE_CATALOGprivilegios en el catálogo de destino.USE_SCHEMAyCREATE_TABLEprivilegios en el esquema de destino.
Para administrar la canalización de sincronización de datos de una tabla en línea, debe ser el propietario de la tabla en línea o conceder el privilegio REFRESH en la tabla en línea. Los usuarios que no tienen USE_CATALOG y USE_SCHEMA privilegios en el catálogo no verán la tabla en línea en Catalog Explorer.
El metastore del Unity Catalog debe tener Modelo de privilegios versión 1.0.
Modelo de permisos de punto de conexión
Se crea automáticamente una entidad de servicio única para una característica que atiende o modelo de punto de conexión con permisos limitados necesarios para consultar datos de tablas en línea. Esta entidad de servicio permite a los puntos de conexión acceder a los datos independientemente del usuario que creó el recurso y garantiza que el punto de conexión pueda seguir funcionando si el creador deja el área de trabajo.
La duración de esta entidad de servicio es la duración del punto de conexión. Los registros de auditoría pueden indicar registros generados por el sistema para el propietario del Unity Catalog que concede privilegios necesarios a esta entidad de servicio.
Limitaciones
- Solo se admite una tabla en línea por tabla de origen.
- Una tabla en línea y su tabla de origen pueden tener como máximo 1000 columnas.
- Las columnas de tipos de datos ARRAY, MAP o STRUCT no se pueden usar como claves principales en la tabla en línea.
- Si una columna se usa como clave principal en la tabla en línea, se omiten todas las filas de la tabla de origen donde la columna contiene valores NULL.
- Las tablas externas, del sistema y internas no se admiten como tablas de origen.
- Las tablas de origen sin la fuente de distribución de datos de cambio delta habilitada solo admiten el modo de sincronización de instantáneas de .
- Las tablas delta Sharing solo se admiten en el modo de sincronización de Instantáneas.
- Los nombres de catálogo, esquema y tabla de las tablas en línea solo pueden contener caracteres alfanuméricos y caracteres de subrayado, y no deben comenzar con números. No se permiten guiones (
-). - Las columnas de tipo String están limitadas a la longitud de 64 KB.
- Los nombres de columna están limitados a 64 caracteres de longitud.
- El tamaño máximo de la fila es de 2 MB.
- El tamaño combinado de todas las tablas en línea de una tienda de metadatos del Unity Catalog durante la versión preliminar pública es de 2 TB de datos de usuario sin comprimir.
- El número máximo de consultas por segundo (QPS) es 12.000. Póngase en contacto con el equipo de la cuenta de Databricks para aumentar el límite.
Solución de problemas
No veo la opción Crear tabla en línea
La causa suele ser que la tabla desde la que intenta sincronizar (la tabla de origen) no es un tipo admitido. Asegúrese de que la tabla de origen Tipo protegible (que se muestra en Catalog Explorer de pestaña Detalles ) es una de las opciones admitidas a continuación:
TABLE_EXTERNALTABLE_DELTATABLE_DELTA_EXTERNALTABLE_DELTASHARINGTABLE_DELTASHARING_MUTABLETABLE_STREAMING_LIVE_TABLETABLE_STANDARDTABLE_FEATURE_STORETABLE_FEATURE_STORE_EXTERNALTABLE_VIEWTABLE_VIEW_DELTASHARINGTABLE_MATERIALIZED_VIEW
No puedo seleccionar Desencadenados o modos de sincronización Continuos al crear una tabla en línea
Esto sucede si la tabla de origen no tiene habilitada la fuente de distribución de datos de cambios delta o si es una vista Vista o materializada. Para usar el modo de sincronizaciónIncremental habilite la fuente de distribución de datos modificados en la tabla de origen o use una tabla que no sea de vista.
Error en la actualización de la tabla en línea o el estado parece estar sin conexión
Para empezar a solucionar este error, haga clic en el identificador de canalización que aparece en la pestaña Información general de la tabla en línea del Explorador de catálogos.
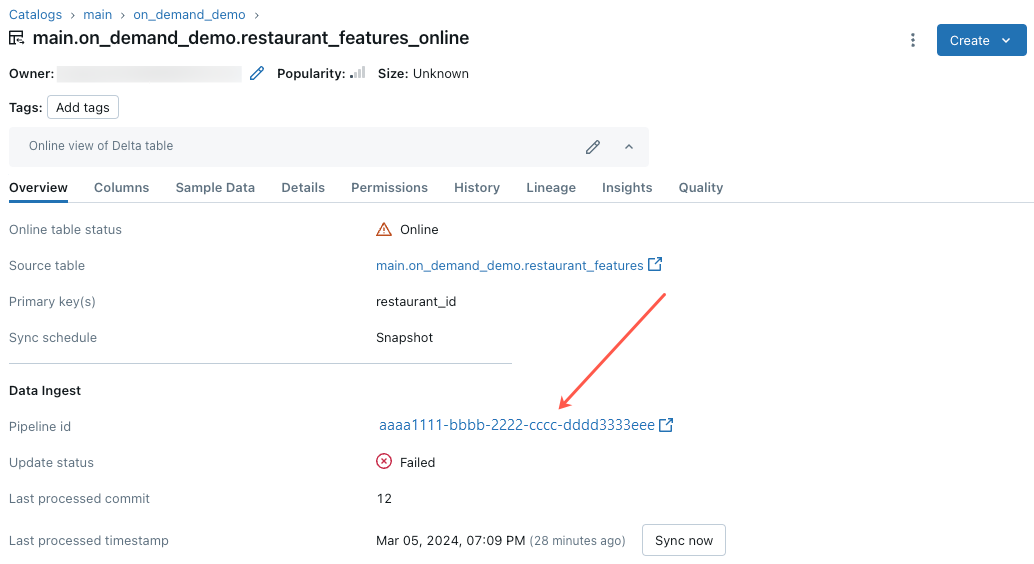
En la página de la interfaz de usuario de canalización que aparece, haga clic en la entrada que indique “No se pudo resolver el flujo ‘__online_table”.
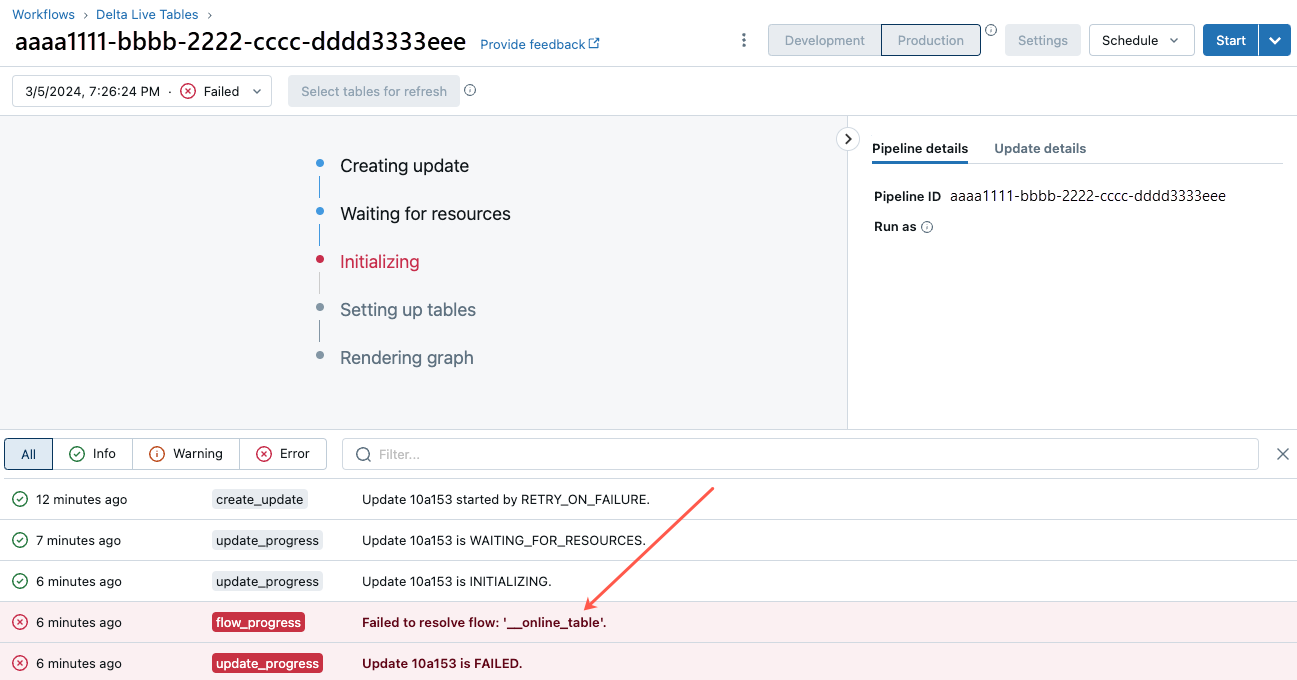
Aparece un elemento emergente con detalles en la sección Detalles del error.
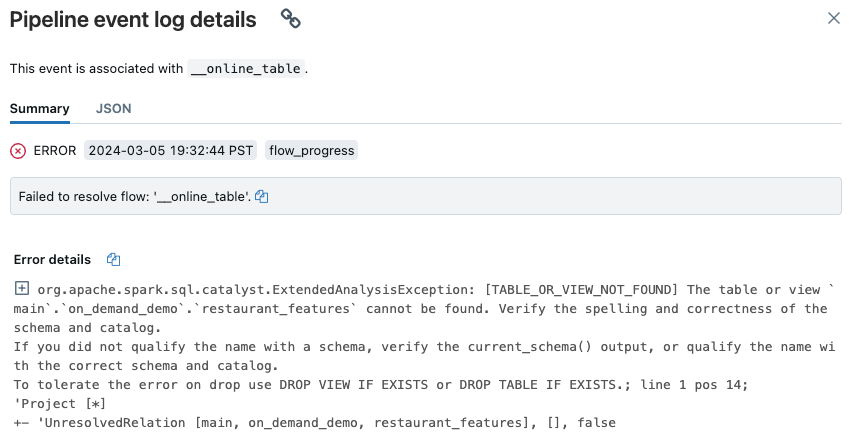
Entre las causas de errores habituales se incluyen los que se indican a continuación:
La tabla de origen se eliminó, o se eliminó y se volvió a crear con el mismo nombre mientras la tabla en línea se sincronizaba. Esto es especialmente común con las tablas en línea continuas, ya que se sincronizan constantemente.
No se puede acceder a la tabla de origen a través de Proceso sin servidor debido a la configuración del firewall. En esta situación, la sección Detalles del error podría mostrar el mensaje de error “No se pudo iniciar el servicio DLT en el clúster xxx…”.
El tamaño agregado de las tablas en línea supera el límite de metastore de 2 TB (tamaño sin comprimir). El límite de 2 TB hace referencia al tamaño sin comprimir después de expandir la tabla Delta en formato orientado a filas. El tamaño de la tabla en formato de fila puede ser significativamente mayor que el tamaño de la tabla Delta que se muestra en el Explorador de catálogos, haciendo referencia al tamaño comprimido de la tabla en formato orientado a columnas. La diferencia puede ser tan grande como 100x, dependiendo del contenido de la tabla.
Para calcular el tamaño expandido de fila y sin comprimir de una tabla Delta, use la siguiente consulta desde una instancia de SQL Warehouse sin servidor. La consulta devuelve el tamaño estimado de la tabla expandida en bytes. La ejecución correcta de esta consulta también confirmará que Proceso sin servidor puede acceder a la tabla de origen.
SELECT sum(length(to_csv(struct(*)))) FROM `source_table`;