Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo y por qué Databricks mide los tokens por segundo para las cargas de trabajo de rendimiento aprovisionadas para las API de Foundation Model.
El rendimiento de los modelos de lenguaje grande (LLM) se mide a menudo en términos de tokens por segundo. Al configurar los puntos de conexión de servicio del modelo de producción, es importante tener en cuenta el número de solicitudes que la aplicación envía al punto de conexión. Si lo hace, le ayuda a comprender si el punto de conexión debe configurarse para escalar de forma que no afecte a la latencia.
Al configurar los intervalos de escalabilidad horizontal para los puntos de conexión implementados con rendimiento aprovisionado, Databricks encontró que resulta más fácil razonar sobre las entradas que entran en el sistema usando tokens.
¿Qué son los tokens?
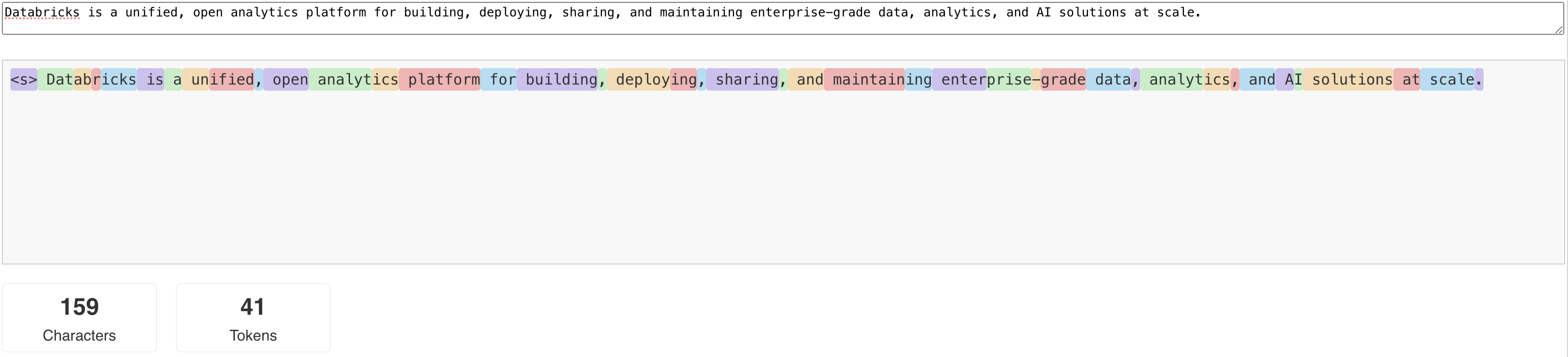
Las LLM leen y generan texto en términos de lo que se denomina token. Los tokens pueden ser palabras o sub-palabras, y las reglas exactas para dividir texto en tokens varían de modelo a modelo. Por ejemplo, puede usar herramientas en línea para ver cómo el tokenizador de Llama convierte palabras en tokens.
En el diagrama siguiente se muestra un ejemplo de cómo el tokenizador llama divide el texto:
¿Por qué medir el rendimiento de LLM en términos de tokens por segundo?
Tradicionalmente, los puntos de conexión de servicio se configuran en función del número de solicitudes simultáneas por segundo (RPS). Sin embargo, una solicitud de inferencia de LLM determinada toma diferentes cantidades de tiempo en función del número de tokens que se pasan y de cuántos se generan, lo que puede estar desequilibrado entre las solicitudes. Por lo tanto, para decidir cuánto hay que escalar horizontalmente su punto de conexión de manera realista es necesario medir la escalabilidad de reducción horizontal en términos del contenido de la solicitud: los tokens.
Los distintos casos de uso incluyen diferentes ratios de token de entrada y salida:
- Distintas longitudes de contextos de entrada: aunque algunas solicitudes pueden implicar solo algunos tokens de entrada, por ejemplo, una pregunta corta, otras pueden implicar cientos o incluso miles de tokens, como un documento largo para el resumen. Esta variabilidad hace que sea desafiante configurar un punto de conexión de servicio basado únicamente en RPS, ya que no tiene en cuenta las diferentes demandas de procesamiento de las diversas solicitudes.
- Diferentes longitudes de salida en función del caso de uso: los distintos casos de uso de los LLM pueden dar lugar a longitudes de tokens de salida muy diferentes. La generación de tokens de salida es la parte más intensiva del tiempo de inferencia de LLM, por lo que esto puede afectar drásticamente al rendimiento. Por ejemplo, el resumen implica respuestas más cortas y concisas, pero la generación de texto, como escribir artículos o descripciones de productos, puede generar respuestas mucho más largas.
¿Cómo se selecciona el intervalo de tokens por segundo para el punto de conexión?
Los puntos de conexión de servicio de rendimiento aprovisionados se configuran en términos de un intervalo de tokens por segundo que se puede enviar al punto de conexión. El punto de conexión se escala verticalmente para controlar la carga de la aplicación de producción. Se le cobra por hora en función del intervalo de tokens por segundo al que se escala el punto de conexión.
La mejor manera de saber qué tokens por segundo oscilan en el punto de conexión de servicio de rendimiento aprovisionado funciona para el caso de uso es realizar una prueba de carga con un conjunto de datos representativo. Consulte Realización de sus propias pruebas comparativas de puntos de conexión de LLM.
Hay dos factores importantes que se deben tener en cuenta:
- Cómo mide Databricks el rendimiento de los tokens por segundo del LLM.
- Funcionamiento del escalado automático.
Cómo mide Databricks el rendimiento de los tokens por segundo de LLM
Databricks compara los puntos de conexión con respecto a una carga de trabajo que representa tareas de resumen que son comunes en los casos de uso de generación aumentada de recuperación. En concreto, la carga de trabajo consta de:
- 2048 tokens de entrada
- 256 tokens de salida
Los intervalos de tokens que se muestran combinan el rendimiento del token de entrada y salida y, de forma predeterminada, optimizan para equilibrar el rendimiento y la latencia.
Pruebas comparativas de Databricks muestran que los usuarios pueden enviar tantos tokens por segundo simultáneamente al punto final, con un tamaño de lote de 1 por solicitud. Esto simula varias solicitudes que alcanzan el punto de conexión al mismo tiempo, lo que representa con mayor precisión cómo usaría realmente el punto de conexión en producción.
- Por ejemplo, si un punto de conexión de servicio de rendimiento aprovisionado tiene una tasa establecida de 2304 tokens por segundo (2048 + 256), se espera que una única solicitud con una entrada de 2048 tokens y una salida esperada de 256 tokens tarde aproximadamente un segundo en ejecutarse.
- Del mismo modo, si la tasa se establece en 5600, se puede esperar que una única solicitud, con los recuentos de tokens de entrada y salida anteriormente mencionados, tarde unos 0,5 segundos en ejecutarse. Es decir, el punto final puede procesar dos solicitudes similares en aproximadamente un segundo.
Si la carga de trabajo varía de la anterior, puede esperar que la latencia varíe con respecto a la tasa de rendimiento aprovisionada indicada. Como se indicó anteriormente, la generación de más tokens de salida es más intensiva que incluir más tokens de entrada. Si va a realizar la inferencia por lotes y desea calcular la cantidad de tiempo que tardará en completarse, puede calcular el número medio de tokens de entrada y salida y comparar con la carga de trabajo de pruebas comparativas de Databricks anterior.
- Por ejemplo, si tiene 1000 filas, con un recuento medio de tokens de entrada de 3000 y un recuento medio de tokens de salida de 500, y un rendimiento aprovisionado de 3500 tokens por segundo, puede tardar más de 1000 segundos en total (un segundo por fila) debido a que los recuentos de tokens promedio son mayores que el banco de pruebas de Databricks.
- Del mismo modo, si tiene 1000 filas, una entrada media de 1500 tokens, una salida media de 100 tokens y un rendimiento aprovisionado de 1600 tokens por segundo, puede tardar menos de 1000 segundos en total (un segundo por fila) debido a que el promedio de recuentos de tokens es menor que el banco de pruebas de Databricks.
Para calcular el rendimiento aprovisionado ideal necesario para completar la carga de trabajo de inferencia por lotes, puede usar el cuaderno en la inferencia de LlM de procesamiento por lotes mediante ai_query
Cómo funciona la escalabilidad automática
Model Serving incluye un sistema de escalado automático rápido que escala los recursos computacionales subyacentes para satisfacer la demanda de tokens por segundo de la aplicación. Databricks aumenta el rendimiento aprovisionado en bloques de tokens por segundo, por lo que se le cobra por unidades adicionales de rendimiento aprovisionado solo cuando las estás utilizando.
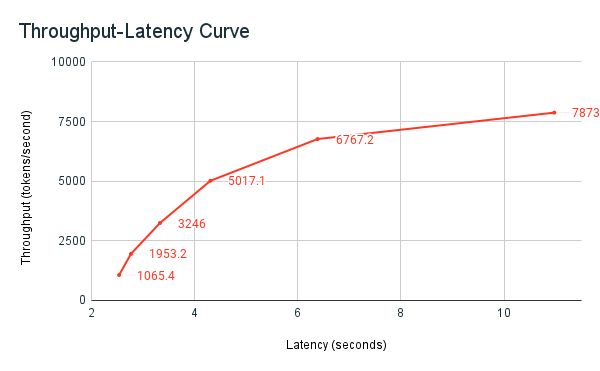
El siguiente gráfico de rendimiento y latencia muestra un punto de conexión aprovisionado y probado con un número creciente de solicitudes paralelas. El primer punto representa 1 solicitud, la segunda, 2 solicitudes paralelas, la tercera, 4 solicitudes paralelas, etc. A medida que aumenta el número de solicitudes y, a su vez, la demanda de tokens por segundo, se observa que el rendimiento aprovisionado también aumenta. Este aumento indica que el escalado automático aumenta la capacidad de cómputo disponible. Sin embargo, es posible que empiece a ver que el rendimiento comienza a estabilizarse, alcanzando un límite de aproximadamente 8000 fichas por segundo a medida que se hacen más solicitudes paralelas. La latencia total aumenta a medida que más solicitudes tienen que esperar en la cola antes de procesarse porque el proceso asignado se usa simultáneamente.
Nota:
Puede mantener el rendimiento coherente desactivando el escalado a cero y configurando un rendimiento mínimo en el punto de servicio. Al hacerlo, se evita la necesidad de esperar a que el extremo aumente su capacidad.
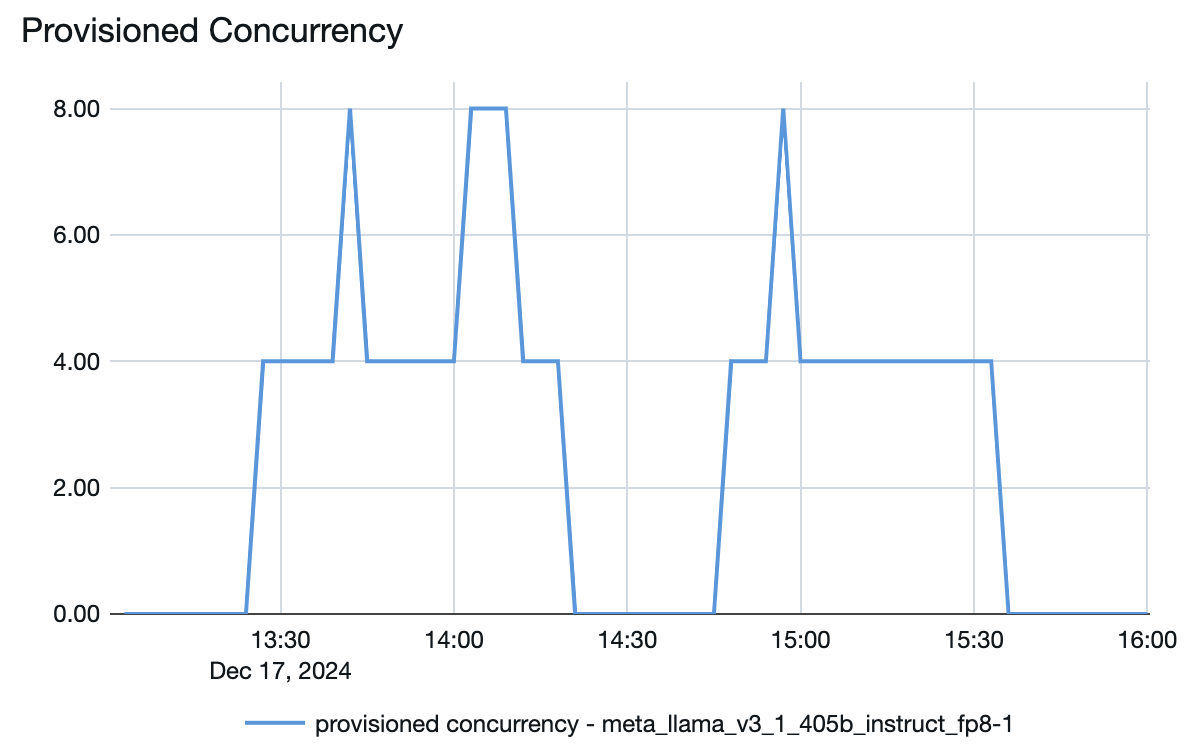
También puede ver desde el punto de conexión de servicio del modelo cómo se activan o reducen los recursos en función de la demanda:
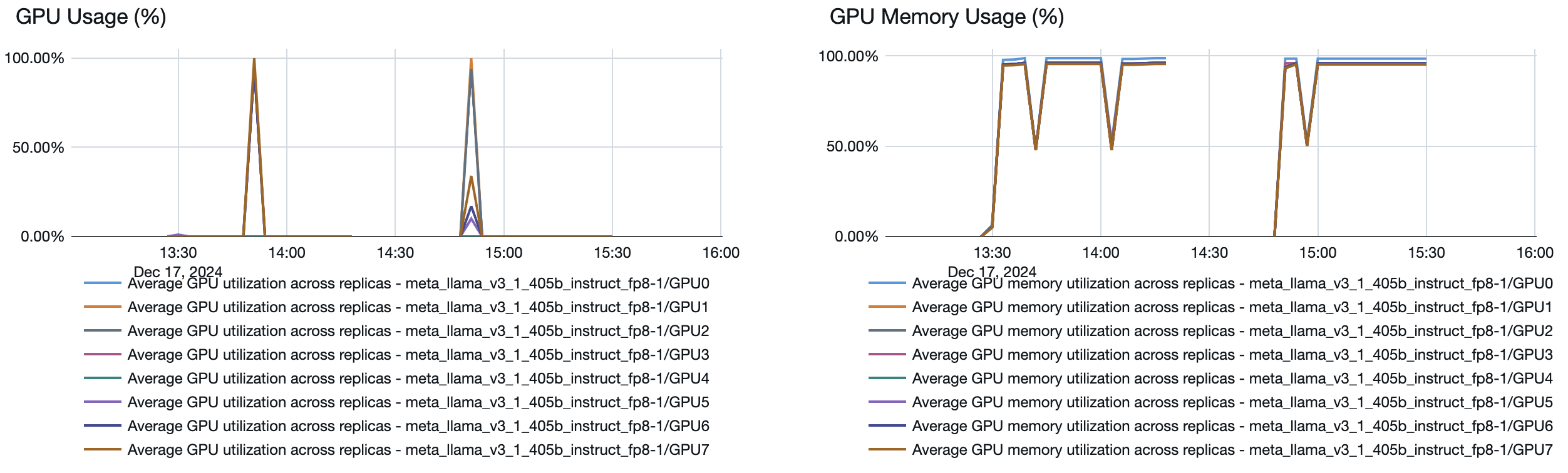
Solución de problemas
Si el punto de conexión de servicio con el rendimiento aprovisionado se ejecuta a una velocidad de menos tokens por segundo que el designado, compruebe en qué medida se ha escalado realmente el punto de conexión revisando lo siguiente:
- Las métricas del punto de conexión representan la simultaneidad aprovisionada.
- Tamaño mínimo de banda del punto de conexión de rendimiento aprovisionado.
- Vaya a los detalles de la entidad atendida para el punto de conexión y compruebe el valor mínimo de fichas por segundo en la lista desplegable Hasta.
A continuación, puede calcular cuánto se escaló realmente el punto de conexión utilizando la fórmula siguiente:
- Simultaneidad aprovisionada * tamaño mínimo de banda / 4
Por ejemplo, el gráfico de concurrencia aprovisionada para el modelo Llama 3.1 405B mencionado anteriormente tiene una concurrencia aprovisionada máxima de 8. Al configurar un punto de conexión para él, el tamaño mínimo de banda era de 850 tokens por segundo. En este ejemplo, el punto de conexión se escala a un máximo de:
- 8 (simultaneidad aprovisionada) * 850 (tamaño mínimo de banda) / 4 = 1700 tokens por segundo