Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo crear puntos de conexión de servicio de modelos que atienden modelos personalizados mediante Databricks Model Serve.
El servicio de modelos proporciona las siguientes opciones para atender la creación de puntos de conexión:
- Interfaz de Usuario del Servicio
- REST API
- SDK de implementaciones de MLflow
Para crear puntos de conexión que sirvan modelos de base de IA generativa, consulte Creación de un modelo que atiende puntos de conexión.
Requisitos
- Su área de trabajo debe estar en una región admitida.
- Si usas bibliotecas personalizadas o bibliotecas desde un servidor espejo privado con su modelo, consulte "Uso de bibliotecas personalizadas de Python con Model Serving" antes de crear el punto de conexión del modelo.
- Para crear puntos de conexión mediante el SDK de implementaciones de MLflow, debe instalar el cliente de implementación de MLflow. Para instalarlo, ejecute:
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Control de acceso
Para comprender las opciones de control de acceso para los puntos de conexión de servicio de modelos para la administración de puntos de conexión, consulte Administración de permisos en un punto de conexión de servicio de modelos.
La identidad bajo la cual se ejecuta un punto de conexión de servicio del modelo está vinculada al creador original del punto de conexión. Después de la creación del punto de conexión, la identidad asociada no se puede cambiar ni actualizar en el punto de conexión. Esta identidad y sus permisos asociados se usan para acceder a los recursos del catálogo de Unity para las implementaciones. Si la identidad no tiene los permisos adecuados para acceder a los recursos necesarios del Unity Catalog, debe eliminar el punto de conexión y recrearlo bajo un usuario o principal de servicio que pueda acceder a esos recursos del Unity Catalog.
También puede agregar variables de entorno para almacenar las credenciales de servicio del modelo. Vea Configuración del acceso a los recursos desde los puntos de conexión de servicio del modelo
Crear un punto de conexión
Interfaz de usuario de servicio
Puede crear un punto de conexión para el servicio de modelos con la interfaz de usuario Serving.
Haga clic en Serving en la barra lateral para mostrar la interfaz de usuario de Serving.
Haga clic en Crear punto de conexión de servicio.

Para modelos registrados en el registro de modelos del Workspace o modelos en Unity Catalog:
En el campo Nombre , proporcione un nombre para el punto de conexión.
- Los nombres de punto de conexión no pueden usar el
databricks-prefijo. Este prefijo está reservado para los puntos de conexión preconfigurados de Databricks.
- Los nombres de punto de conexión no pueden usar el
En la sección Entidades atendidas
- Haga clic en el campo Entidad para abrir el formulario Seleccionar entidad atendida .
- Seleccione Mis modelos: Catálogo de Unity o Mis modelos: Registro de modelos en función de dónde se registre el modelo. El formulario se actualiza dinámicamente en función de la selección.
- No todos los modelos son modelos personalizados. Los modelos pueden ser modelos fundacionales o características para el servicio de funciones.
- Seleccione el modelo y la versión del modelo que desea utilizar.
- Seleccione el porcentaje de tráfico que se va a enrutar al modelo que se está utilizando.
- Seleccione el tamaño de recursos de cómputo que desee usar. Puede usar recursos de cálculo de CPU o GPU para cargas de trabajo. Consulte Tipos de carga de trabajo de GPU para obtener más información sobre los procesos de GPU disponibles.
- En Escalabilidad horizontal de procesos, seleccione el tamaño de la escalabilidad horizontal de procesos que se corresponda con el número de solicitudes que puede procesar este modelo servido al mismo tiempo. Este número debe ser aproximadamente igual al tiempo de ejecución del modelo QPS x. Para conocer la configuración de proceso definida por el cliente, consulte límites de servicio del modelo.
- Los tamaños disponibles son Pequeños para solicitudes de 0 a 4, 8-16 solicitudes medianas y Grandes para solicitudes de 16 a 64.
- Especifique si el punto de conexión debe escalar a cero cuando no esté en uso. No se recomienda escalar a cero para los puntos de conexión de producción, ya que no se garantiza la capacidad cuando se escala a cero. Cuando un punto de conexión se escala a cero, hay latencia adicional, también denominada arranque en frío, cuando el punto de conexión se escala verticalmente para atender solicitudes.
- En Configuración avanzada, puede:
- Cambie el nombre de la entidad atendida para personalizar cómo aparece en el punto de conexión.
- Agregue variables de entorno para conectarse a los recursos desde el punto de conexión o registrar la búsqueda de características dataFrame en la tabla de inferencia del punto de conexión. El registro del DataFrame de búsqueda de características requiere MLflow 2.14.0 o superior.
- (Opcional) Para agregar entidades de servicio adicionales al punto de conexión, haga clic en Agregar entidad atendida y repita los pasos de configuración anteriores. Puede servir varios modelos o versiones de modelo desde un único punto de conexión y controlar la división del tráfico entre ellos. Consulte Servir varios modelos para obtener más información.
En la sección Optimización de rutas, puede habilitar la optimización de rutas para el punto de conexión. Se recomienda la optimización de rutas para los puntos de conexión con requisitos elevados de QPS y rendimiento. Consulte Optimización de rutas en los puntos de conexión de servicio.
En la Sección de AI Gateway, puede seleccionar qué características de gobernanza habilitar en su punto de conexión. Consulte Unity AI Gateway.
Haga clic en Crear. La página Puntos de conexión de servicio aparece con el estado del punto de conexión de servicio mostrado como No listo.

REST API
Puede crear puntos de conexión mediante la API de REST. Consulte POST /api/2.0/serving-endpoints para ver los parámetros de configuración del punto de conexión.
En el ejemplo siguiente se crea un punto de conexión que proporciona la tercera versión del modelo my-ads-model, registrado en el registro de modelos del Catálogo de Unity. Para especificar un modelo del catálogo de Unity, proporcione el nombre completo del modelo, incluido el catálogo primario y el esquema, como, catalog.schema.example-model. En este ejemplo se utiliza la concurrencia definida por el usuario con min_provisioned_concurrency y max_provisioned_concurrency. Los valores de simultaneidad deben ser múltiplos de 4.
POST /api/2.0/serving-endpoints
{
"name": "uc-model-endpoint",
"config":
{
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false
}
]
}
}
Este es un ejemplo de respuesta: El estado del punto config_update es NOT_UPDATING y el modelo servido está en un estado READY.
{
"name": "uc-model-endpoint",
"creator": "user@email.com",
"creation_timestamp": 1700089637000,
"last_updated_timestamp": 1700089760000,
"state": {
"ready": "READY",
"config_update": "NOT_UPDATING"
},
"config": {
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": false,
"workload_type": "CPU",
"state": {
"deployment": "DEPLOYMENT_READY",
"deployment_state_message": ""
},
"creator": "user@email.com",
"creation_timestamp": 1700089760000
}
],
"config_version": 1
},
"tags": [
{
"key": "team",
"value": "data science"
}
],
"id": "e3bd3e471d6045d6b75f384279e4b6ab",
"permission_level": "CAN_MANAGE",
"route_optimized": false
}
SDK de implementaciones de MLflow
Las implementaciones de MLflow proporcionan una API para crear, actualizar y eliminar tareas. Las API de estas tareas aceptan los mismos parámetros que la API de REST para atender los puntos de conexión. Consulte POST /api/2.0/serving-endpoints para ver los parámetros de configuración del punto de conexión.
En el ejemplo siguiente se crea un punto de conexión que proporciona la tercera versión del modelo my-ads-model, registrado en el registro de modelos del Catálogo de Unity. Debe proporcionar el nombre completo del modelo, incluido el catálogo primario y el esquema, como , catalog.schema.example-model. En este ejemplo se utiliza la concurrencia definida por el usuario con min_provisioned_concurrency y max_provisioned_concurrency. Los valores de simultaneidad deben ser múltiplos de 4.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="unity-catalog-model-endpoint",
config={
"served_entities": [
{
"name": "ads-entity",
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "3",
"min_provisioned_concurrency": 4,
"max_provisioned_concurrency": 12,
"scale_to_zero_enabled": False
}
]
}
)
Cliente del espacio de trabajo
En el ejemplo siguiente se muestra cómo crear un punto de conexión mediante el SDK de cliente del área de trabajo de Databricks.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="uc-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
name="ads-entity",
entity_name="catalog.schema.my-ads-model",
entity_version="3",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
También puede:
- Habilite las tablas de inferencia para capturar automáticamente las solicitudes entrantes y las respuestas salientes a los puntos de conexión de servicio del modelo.
- Si tiene tablas de inferencia habilitadas en el punto de conexión, puede registrar la búsqueda de características de DataFrame en la tabla de inferencia.
Tipos de carga de trabajo de la GPU
La implementación de GPU es compatible con las siguientes versiones de paquete:
- PyTorch 1.13.0 - 2.0.1
- Tensorflow 2.5.0 - 2.13.0
- MLflow 2.4.0 y posterior
En los ejemplos siguientes se muestra cómo crear puntos de conexión de GPU mediante distintos métodos.
Interfaz de usuario de servicio
Para configurar el punto de conexión para cargas de trabajo de GPU con la interfaz de usuario de servicio , seleccione el tipo de GPU deseado en la lista desplegable Tipo de proceso al crear el punto de conexión. Siga los mismos pasos de Creación de un punto de conexión, pero seleccione un tipo de carga de trabajo de GPU en lugar de CPU.
REST API
Para implementar los modelos mediante el uso de GPUs, incluya el campo workload_type en la configuración del punto de conexión.
POST /api/2.0/serving-endpoints
{
"name": "gpu-model-endpoint",
"config": {
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": false
}]
}
}
SDK de implementaciones de MLflow
En el ejemplo siguiente se muestra cómo crear un punto de conexión de GPU mediante el SDK de implementaciones de MLflow.
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="gpu-model-endpoint",
config={
"served_entities": [{
"entity_name": "catalog.schema.my-gpu-model",
"entity_version": "1",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
"scale_to_zero_enabled": False
}]
}
)
Cliente del espacio de trabajo
En el ejemplo siguiente se muestra cómo crear un punto de conexión de GPU mediante el SDK de cliente del área de trabajo de Databricks.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
w = WorkspaceClient()
w.serving_endpoints.create(
name="gpu-model-endpoint",
config=EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="catalog.schema.my-gpu-model",
entity_version="1",
workload_type="GPU_SMALL",
workload_size="Small",
scale_to_zero_enabled=False
)
]
)
)
En la tabla siguiente se resumen los tipos de carga de trabajo de GPU disponibles admitidos.
| Tipo de carga de trabajo de la GPU | Instancia de GPU | Memoria de GPU |
|---|---|---|
GPU_SMALL |
1xT4 | 16 GB |
GPU_LARGE |
1xA100 | 80 GB |
GPU_LARGE_2 |
2xA100 | 160 GB |
Modificar un punto de conexión de modelo personalizado
Después de habilitar un punto de conexión de modelo personalizado, puede actualizar la configuración de proceso según sea necesario. Esta configuración resulta especialmente útil si se necesita usar recursos adicionales en el modelo. El tamaño de la carga de trabajo y la configuración de proceso desempeñan un papel clave a la hora de decidir qué recursos se asignan para servir el modelo.
Nota:
Se pueden producir errores en las actualizaciones de la configuración del punto de conexión. Cuando se producen errores, la configuración activa existente permanece efectiva como si no se produjera la actualización.
Compruebe que la actualización se aplicó correctamente revisando el estado del punto de conexión.
Hasta que la nueva configuración esté lista, la configuración anterior sigue atendiendo el tráfico de predicción. Aunque hay una actualización en curso, no se puede realizar otra actualización. Sin embargo, puede cancelar una actualización en progreso desde la interfaz de usuario de Serving.
Interfaz de usuario de servicio
Después de habilitar un punto de conexión de modelo, seleccione Editar punto de conexión para modificar la configuración de proceso del punto de conexión.
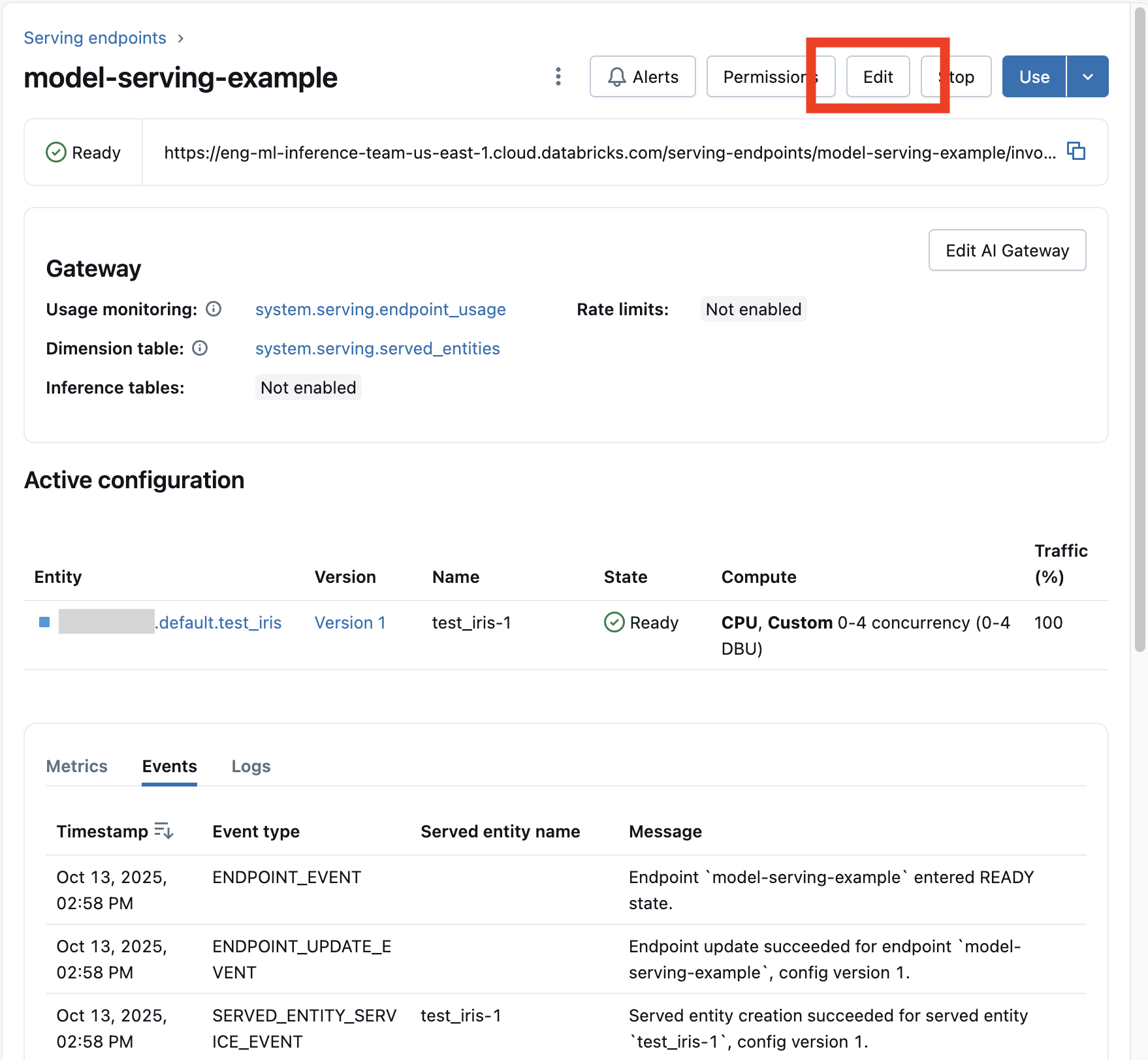
Puede cambiar la mayoría de los aspectos de la configuración del punto de conexión, excepto el nombre del punto de conexión y determinadas propiedades inmutables.
Para cancelar una actualización de configuración en curso, seleccione Cancelar actualización en la página de detalles del punto de conexión.
REST API
A continuación se muestra un ejemplo de actualización de configuración de punto de conexión mediante la API de REST. Consulte PUT /api/2.0/serving-endpoints/{name}/config.
PUT /api/2.0/serving-endpoints/{name}/config
{
"name": "unity-catalog-model-endpoint",
"config":
{
"served_entities": [
{
"entity_name": "catalog.schema.my-ads-model",
"entity_version": "5",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
],
"traffic_config":
{
"routes": [
{
"served_model_name": "my-ads-model-5",
"traffic_percentage": 100
}
]
}
}
}
SDK de implementaciones de MLflow
El SDK de implementaciones de MLflow usa los mismos parámetros que la API REST, consulte PUT /api/2.0/serving-endpoints/{name}/config para obtener detalles del esquema de solicitud y respuesta.
En el ejemplo de código siguiente se usa un modelo del registro de modelos del catálogo de Unity:
import mlflow
from mlflow.deployments import get_deploy_client
mlflow.set_registry_uri("databricks-uc")
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{endpointname}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.{model_name}",
"entity_version": "1",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
],
"traffic_config": {
"routes": [
{
"served_model_name": f"{model_name}-1",
"traffic_percentage": 100
}
]
}
}
)
Evaluación de un extremo de modelo
Para evaluar su modelo, envíe solicitudes al extremo de servicio del modelo.
- Vea Puntos de conexión de servicio de consulta para modelos personalizados.
- Consulte Uso de modelos de base.
Recursos adicionales
- Administración de puntos de conexión de servicio de modelos.
- Modelos externos en Mosaic AI Model Serving.
- Si prefiere usar Python, puede usar el SDK de Python en tiempo real de Databricks.
Ejemplos de notebooks
Los siguientes cuadernos incluyen diferentes modelos registrados de Databricks que puede usar para comenzar a trabajar con los puntos finales de servicio de modelos. Para obtener ejemplos adicionales, consulte Tutorial: Implementación y consulta de un modelo personalizado.
Los ejemplos de modelos se pueden importar en el área de trabajo siguiendo las instrucciones de Importación de un cuaderno. Después de elegir y crear un modelo a partir de uno de los ejemplos, regístrelo en el catálogo de Unity y, a continuación, siga los pasos de flujo de trabajo de la interfaz de usuario para el servicio de modelos.