Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se incluyen dos ejemplos de modelos de recomendación basados en aprendizaje profundo en Azure Databricks. En comparación con los modelos de recomendación tradicionales, los modelos de aprendizaje profundo pueden lograr resultados de mayor calidad y escalar a grandes cantidades de datos. A medida que estos modelos siguen evolucionando, Databricks proporciona un marco para entrenar de forma eficaz modelos de recomendación a gran escala capaces de controlar cientos de millones de usuarios.
Un sistema de recomendaciones generales se puede ver como un embudo con las fases que se muestran en el diagrama.
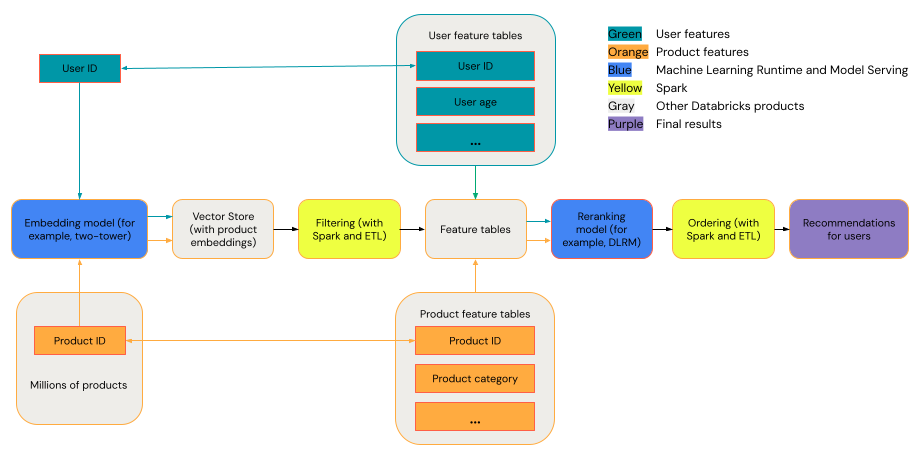
Algunos modelos, como el modelo de dos torres, funcionan mejor como modelos de recuperación. Estos modelos son más pequeños y pueden operar eficazmente en millones de puntos de datos. Otros modelos, como DLRM o DeepFM, funcionan mejor como modelos de reclasificación. Estos modelos pueden tomar más datos, son más grandes y pueden proporcionar recomendaciones específicas.
Requisitos
Databricks Runtime 14.3 LTS ML
Herramientas
En los ejemplos de este artículo se muestran las siguientes herramientas:
- TorchDistributor: TorchDistributor es un marco que permite ejecutar el entrenamiento de modelos PyTorch a gran escala en Databricks. Usa Spark para la orquestación y puede escalar a tantas GPU como estén disponibles en el clúster.
- Mosaic StreamingDataset: StreamingDataset mejora el rendimiento y la escalabilidad del entrenamiento en grandes conjuntos de datos en Databricks mediante características como la captura previa e intercalación.
- MLflow: MLflow permite realizar un seguimiento de los parámetros, las métricas y los puntos de control del modelo.
- TorchRec: los sistemas recomendados modernos usan tablas de búsqueda para insertar millones de usuarios y elementos para generar recomendaciones de alta calidad. Los tamaños de inserción más grandes mejoran el rendimiento del modelo, pero requieren una cantidad considerable de memoria en la GPU y configuraciones con varias GPU. TorchRec proporciona un marco para escalar modelos de recomendación y tablas de búsqueda en varias GPU, lo que lo convierte en ideal para incrustaciones de gran tamaño.
Ejemplo: Recomendaciones de películas con una arquitectura de modelo de dos torres
El modelo de dos torres está diseñado para controlar las tareas de personalización a gran escala mediante el procesamiento por separado de los datos de los usuarios y de los elementos antes de combinarlos. Es capaz de generar de forma eficaz cientos o miles de recomendaciones de calidad decentes. Por lo general, el modelo espera tres entradas: una característica user_id, una característica product_id y una etiqueta binaria que defina si la interacción <usuario, producto> fue positiva (el usuario compró el producto) o negativa (el usuario dio al producto una valoración de una estrella). Las salidas del modelo son incrustaciones para los usuarios y los elementos, que a continuación se combinan generalmente (a menudo con una similitud de punto o coseno) para predecir interacciones de elementos de usuario.
Como el modelo de dos torres proporciona inserciones para usuarios y productos, puede colocar estas inserciones en un índice vectorial, como Vector de búsqueda en IA de Mosaic, y realizar operaciones similares de búsqueda similar a las de los usuarios y elementos. Por ejemplo, podría colocar todos los elementos en un almacén de vectores y, para cada usuario, consultar el almacén de vectores para buscar los cien elementos principales cuyos incrustaciones son similares a los del usuario.
El siguiente cuaderno de ejemplo implementa el entrenamiento del modelo de dos torres usando el conjunto de datos "Aprendizaje a partir de conjuntos de elementos" para predecir la probabilidad de que un usuario valore positivamente una determinada película. Usa Mosaic StreamingDataset para la carga de datos distribuidos, TorchDistributor para el entrenamiento de modelos distribuidos y MLflow para el seguimiento y registro de modelos.
Cuaderno del modelo del recomendador de dos torres
Este cuaderno también está disponible en Databricks Marketplace: Cuaderno de modelo de dos torres
Nota:
- Las entradas del modelo de dos torres suelen ser las características categóricas user_id y product_id. El modelo se puede modificar para admitir varios vectores de características tanto para usuarios como para productos.
- Las salidas del modelo de dos torres suelen ser valores binarios que indican si el usuario tendrá una interacción positiva o negativa con el producto. El modelo se puede modificar para otras aplicaciones, como regresión, clasificación de varias clases y probabilidades para varias acciones de usuario (como descartar o comprar). Las salidas complejas deben implementarse con cuidado, ya que los objetivos contrapuestos pueden degradar la calidad de las inserciones generadas por el modelo.
Ejemplo: Entrenamiento de una arquitectura DLRM mediante un conjunto de datos sintético
DLRM es una arquitectura de red neuronal de última generación diseñada específicamente para sistemas de personalización y recomendación. Combina entradas numéricas y categóricas para modelar eficazmente las interacciones del elemento de usuario y predecir las preferencias del usuario. Por lo general, los DLRM esperan entradas que contengan tanto características dispersas (como el identificador de usuario, el identificador de ítem, la ubicación geográfica o la categoría del producto) como características densas (como la edad del usuario o el precio del artículo). El resultado de un DLRM suele ser una predicción de la implicación del usuario, como el porcentaje de clics o la probabilidad de compra.
Los DLRM ofrecen un marco altamente personalizable que puede controlar datos a gran escala, por lo que es adecuado para tareas complejas de recomendación en varios dominios. Al tratarse de un modelo más grande que la arquitectura de dos torres, este modelo se usa a menudo en la fase de reclasificación.
En el siguiente cuaderno de ejemplo se compila un modelo DLRM para predecir etiquetas binarias mediante características densas (numéricas) y características dispersas (categóricas). Usa un conjunto de datos sintético para entrenar el modelo, Mosaic StreamingDataset para la carga de datos distribuida, TorchDistributor para el entrenamiento distribuido del modelo y MLflow para el seguimiento y registro del modelo.
Cuaderno DLRM
Este cuaderno también está disponible en el marketplace de Databricks: Cuaderno DLRM.
Comparación de modelos de dos torres y DLRM
La tabla muestra algunas pautas para seleccionar qué modelo de recomendación usar.
| Tipo de modelo | Tamaño del conjunto de datos necesario para el entrenamiento | Tamaño del modelo | Tipos de entrada admitidos | Tipos de salida compatibles | Casos de uso |
|---|---|---|---|---|---|
| Dos torres | Pequeño | Pequeño | Normalmente dos características (user_id, product_id) | Clasificación binaria y generación de incrustaciones principalmente | Generación de cientos o miles de posibles recomendaciones |
| DLRM | Grande | Grande | Varias características categóricas y densas (user_id, género, geographic_location, product_id, product_category, …) | Clasificación de varias clases, regresión, otros | Recuperación específica (recomendando decenas de elementos altamente relevantes) |
En resumen, el modelo de dos torres es más útil para generar miles de recomendaciones de buena calidad de forma muy eficaz. Un ejemplo podría ser recomendaciones de películas de un proveedor de cable. El modelo DLRM es más útil para generar recomendaciones muy específicas basadas en más datos. Un ejemplo podría ser un minorista que quiere presentar a un cliente un número menor de artículos que es muy probable que compren.