Definición de variables
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2019
Las variables proporcionan una manera cómoda de obtener los bits clave de los datos en varias partes de la canalización. El uso más común de las variables es definir un valor que se puede usar en la canalización. Todas las variables son cadenas y son mutables. El valor de una variable puede cambiar de una ejecución a otra o de un trabajo a otro de la canalización.
Al definir la misma variable en varios lugares con el mismo nombre, la variable con ámbito local más gana. Por lo tanto, una variable definida en el nivel de trabajo puede invalidar un conjunto de variables en el nivel de fase. Una variable definida en el nivel de fase invalida un conjunto de variables en el nivel raíz de la canalización. Un conjunto de variables en el nivel raíz de la canalización invalida un conjunto de variables en la interfaz de usuario de configuración de canalización. Para obtener más información sobre cómo trabajar con variables definidas en el nivel de trabajo, fase y raíz, consulte Ámbito de variable.
Puede usar variables con expresiones para asignar valores condicionalmente y personalizar aún más las canalizaciones.
Las variables son diferentes de los parámetros en tiempo de ejecución. Los parámetros en tiempo de ejecución tienen tipos y están disponibles durante el análisis de plantillas.
Variables definidas por el usuario
Al definir una variable, puede usar diferentes sintaxis (macro, expresión de plantilla o tiempo de ejecución) y qué sintaxis usa determina dónde se representa la variable en la canalización.
En las canalizaciones de YAML, puede establecer variables en el nivel raíz, fase y trabajo. También puede especificar variables fuera de una canalización de YAML en la interfaz de usuario. Al establecer una variable en la interfaz de usuario, esa variable se puede cifrar y establecer como secreto.
Las variables definidas por el usuario se pueden establecer como de solo lectura. Hay restricciones de nomenclatura para variables (por ejemplo: no se puede usar secret al principio de un nombre de variable).
Puede usar un grupo de variables para que las variables estén disponibles en varias canalizaciones.
Use plantillas para definir variables en un archivo que se use en varias canalizaciones.
Variables de varias líneas definidas por el usuario
Azure DevOps admite variables de varias líneas, pero hay algunas limitaciones.
Es posible que los componentes de nivel inferior, como las tareas de canalización, no controlen los valores de variable correctamente.
Azure DevOps no modificará los valores de variables definidos por el usuario. Los valores de variable deben tener el formato correcto antes de pasarse como variables de varias líneas. Al aplicar formato a la variable, evite caracteres especiales, no use nombres restringidos y asegúrese de usar un formato de finalización de línea que funcione para el sistema operativo del agente.
Las variables de varias líneas se comportan de forma diferente en función del sistema operativo. Para evitar esto, asegúrese de dar formato a variables de varias líneas correctamente para el sistema operativo de destino.
Azure DevOps nunca modifica los valores de variable, incluso si proporciona formato no admitido.
Variables del sistema
Además de las variables definidas por el usuario, Azure Pipelines tiene variables del sistema con valores predefinidos. Por ejemplo, la variable predefinida Build.BuildId proporciona el identificador de cada compilación y se puede usar para identificar distintas ejecuciones de canalización. Puede usar la variable Build.BuildId en scripts o tareas cuando necesite un valor único.
Si usa yaML o canalizaciones de compilación clásicas, consulte variables predefinidas para obtener una lista completa de variables del sistema.
Si usa canalizaciones de versión clásicas, consulte variables de versión.
Las variables del sistema se establecen con su valor actual al ejecutar la canalización. Algunas variables se establecen automáticamente. Como autor de canalización o usuario final, se cambia el valor de una variable del sistema antes de que se ejecute la canalización.
Las variables del sistema son de solo lectura.
Variables de entorno
Las variables de entorno son específicas del sistema operativo que está usando. Se insertan en una canalización de maneras específicas de la plataforma. El formato corresponde a cómo se da formato a las variables de entorno para la plataforma de scripting específica.
En sistemas UNIX (macOS y Linux), las variables de entorno tienen el formato $NAME. En Windows, el formato es %NAME% para lotes y $env:NAME en PowerShell.
Las variables definidas por el sistema y el usuario también se insertan como variables de entorno para la plataforma. Cuando las variables se convierten en variables de entorno, los nombres de variable se convierten en mayúsculas y los puntos se convierten en caracteres de subrayado. Por ejemplo, la variable any.variable se convierte en la variable $ANY_VARIABLE.
Hay restricciones de nomenclatura para variables (por ejemplo: no se puede usar secret al principio de un nombre de variable).
Restricciones de nomenclatura de variables
Las variables de entorno y definidas por el usuario pueden constar de letras, números, . y _ caracteres. No use prefijos de variables reservados por el sistema. Son endpoint, input, secret, path y securefile. Cualquier variable que comience con una de estas cadenas (independientemente de la mayúscula) no estará disponible para las tareas y scripts.
Descripción de la sintaxis de variables:
Azure Pipelines admite tres formas diferentes de hacer referencia a variables: macro, expresión de plantilla y expresión en tiempo de ejecución. Puede usar cada sintaxis para un propósito diferente y cada una tiene algunas limitaciones.
En una canalización, las variables (${{ variables.var }}) de expresión de plantilla se procesan en tiempo de compilación, antes de que se inicie el tiempo de ejecución. Las variables ($(var)) de sintaxis de macro se procesan durante el tiempo de ejecución antes de que se ejecute una tarea. Las expresiones en tiempo de ejecución ($[variables.var]) también se procesan durante el tiempo de ejecución, pero están diseñadas para usarse con condiciones y expresiones. Cuando se usa una expresión en tiempo de ejecución, debe ocupar todo el lado derecho de una definición.
En este ejemplo, puede ver que la expresión de plantilla sigue teniendo el valor inicial de la variable después de actualizar la variable. El valor de la variable de sintaxis de macro se actualiza. El valor de la expresión de plantilla no cambia porque todas las variables de expresión de plantilla se procesan en tiempo de compilación antes de que se ejecuten las tareas. En cambio, las variables de sintaxis de macro se evalúan antes de que se ejecute cada tarea.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Variables de sintaxis de macro
La mayoría de los ejemplos de documentación usan la sintaxis de macro ($(var)). La sintaxis de macros está diseñada para interpolar valores de variable en entradas de tarea y en otras variables.
Las variables con sintaxis de macro se procesan antes de que una tarea se ejecute durante el tiempo de ejecución. El tiempo de ejecución se produce después de la expansión de plantillas. Cuando el sistema encuentra una expresión de macro, reemplaza la expresión por el contenido de la variable. Si no hay ninguna variable por ese nombre, la expresión de macro no cambia. Por ejemplo, si no se puede reemplazar $(var) , $(var) no se reemplazará por nada.
Las variables de sintaxis de macro permanecen sin cambios sin ningún valor porque un valor vacío como $() podría significar algo para la tarea que se está ejecutando y el agente no debe suponer que desea reemplazar ese valor. Por ejemplo, si usa $(foo) para hacer referencia a variables foo en una tarea de Bash, reemplazar todas las $() expresiones de la entrada a la tarea podría interrumpir los scripts de Bash.
Las variables de macro solo se expanden cuando se usan para un valor, no como palabra clave. Los valores aparecen en el lado derecho de una definición de canalización. El siguiente código es válido: key: $(value). Lo siguiente no es válido: $(key): value. Las variables de macro no se expanden cuando se usan para mostrar un nombre de trabajo insertado. En su lugar, debe usar la propiedad displayName.
Nota:
Las variables de sintaxis de macro solo se expanden para stages, jobs y steps.
Por ejemplo, no puede usar la sintaxis de macro dentro de resource o trigger.
En este ejemplo se usa la sintaxis de macros con Bash, PowerShell y una tarea de script. La sintaxis para llamar a una variable con sintaxis de macro es la misma para las tres.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Sintaxis de expresión de plantilla
Puede usar la sintaxis de la expresión de plantilla para expandir los parámetros de plantilla y las variables (${{ variables.var }}). Las variables de plantilla procesan en tiempo de compilación y se reemplazan antes de que se inicie el tiempo de ejecución. Las expresiones de plantilla están diseñadas para reutilizar partes de YAML como plantillas.
Las variables de plantilla se unen silenciosamente a cadenas vacías cuando no se encuentra un valor de reemplazo. Las expresiones de plantilla, a diferencia de las expresiones macro y en tiempo de ejecución, pueden aparecer como claves (lado izquierdo) o valores (lado derecho). El siguiente código es válido: ${{ variables.key }} : ${{ variables.value }}.
Sintaxis de la expresión Runtime
Puede usar la sintaxis de expresión runtime para las variables que se expanden en tiempo de ejecución ($[variables.var]). Las variables de expresión en tiempo de ejecución se unen silenciosamente a cadenas vacías cuando no se encuentra un valor de reemplazo. Use expresiones en tiempo de ejecución en condiciones de trabajo para admitir la ejecución condicional de trabajos o fases completas.
Las variables de expresión runtime solo se expanden cuando se usan para un valor, no como palabra clave. Los valores aparecen en el lado derecho de una definición de canalización. El siguiente código es válido: key: $[variables.value]. Lo siguiente no es válido: $[variables.key]: value. La expresión runtime debe ocupar todo el lado derecho de un par clave-valor. Por ejemplo, key: $[variables.value] es válido, pero key: $[variables.value] foo no es válido.
| Sintaxis | Ejemplo | ¿Cuándo se procesa? | ¿Dónde se expande en una definición de canalización? | ¿Cómo se representa cuando no se encuentra? |
|---|---|---|---|---|
| macro | $(var) |
runtime antes de que se ejecute una tarea | Valor (plan derecho) | impresiones $(var) |
| expresión de plantilla | ${{ variables.var }} |
tiempo de compilación | clave o valor (lado izquierdo o derecho) | cadena vacía |
| expresión runtime | $[variables.var] |
motor en tiempo de ejecución | Valor (plan derecho) | cadena vacía |
¿Qué sintaxis debo usar?
Use la sintaxis de macros si va a proporcionar una entrada para una tarea.
Elija una expresión en tiempo de ejecución si está trabajando con condiciones y expresiones. Sin embargo, no use una expresión en tiempo de ejecución si no desea que la variable vacía se imprima (ejemplo: $[variables.var]). Por ejemplo, si tiene lógica condicional que se basa en una variable que tiene un valor específico o ningún valor. En ese caso, debe usar una expresión de macro.
Si va a definir una variable en una plantilla, use una expresión de plantilla.
Establecimiento de variables en la canalización
En el caso más común, establece las variables y las usa en el archivo YAML. Esto le permite realizar un seguimiento de los cambios en la variable del sistema de control de versiones. También puede definir variables en la interfaz de usuario de configuración de canalización (consulte la pestaña Clásico) y hacer referencia a ellas en el ARCHIVO YAML.
Este es un ejemplo que muestra cómo establecer dos variables, configuration y platform, y usarlas más adelante en los pasos. Para usar una variable en una instrucción YAML, encapsula en $(). Las variables no se pueden usar para definir un repository en una instrucción YAML.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Ámbitos de variables
En el archivo YAML, puede establecer una variable en varios ámbitos:
- En el nivel raíz, para que esté disponible para todos los trabajos de la canalización.
- En el nivel de fase, para que esté disponible solo para una fase específica.
- En el nivel de trabajo, para que esté disponible solo para un trabajo específico.
Al definir una variable en la parte superior de un YAML, la variable está disponible para todos los trabajos y fases de la canalización y es una variable global. Las variables globales definidas en un YAML no son visibles en la interfaz de usuario de configuración de la canalización.
Las variables en el nivel de trabajo invalidan las variables en el nivel raíz y de fase. Las variables en el nivel de fase invalidan las variables en el nivel raíz.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
La salida de ambos trabajos tiene este aspecto:
# job1
value
value1
value1
# job2
value
value2
value
Especificar variables
En los ejemplos anteriores, la palabra clave variables va seguida de una lista de pares clave-valor.
Las claves son los nombres de variable y los valores son los valores de las variables.
Hay otra sintaxis útil cuando desea usar plantillas para variables o grupos de variables.
Con las plantillas, las variables se pueden definir en un YAML e incluirse en otro archivo YAML.
Los grupos de variables son un conjunto de variables que puede usar en varias canalizaciones. Le permiten administrar y organizar variables que son comunes a varias fases en un solo lugar.
Use esta sintaxis para plantillas de variables y grupos de variables en el nivel raíz de una canalización.
En esta sintaxis alternativa, la palabra clave variables toma una lista de especificadores de variables.
Los especificadores de variables son name para una variable normal, group para un grupo de variables y template para incluir una plantilla de variable.
En el ejemplo siguiente se muestran los tres.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Obtenga más información sobre la reutilización de variables con plantillas.
Acceso a variables a través del entorno
Tenga en cuenta que las variables también están disponibles para los scripts a través de variables de entorno. La sintaxis para usar estas variables de entorno depende del lenguaje de scripting.
El nombre está en mayúsculas y el . se reemplaza por el _. Esto se inserta automáticamente en el entorno de proceso. Estos son algunos ejemplos:
- Script de Batch:
%VARIABLE_NAME% - Script de PowerShell:
$env:VARIABLE_NAME - Script de Bash:
$VARIABLE_NAME
Importante
Las variables predefinidas que contienen rutas de acceso de archivo se traducen al estilo adecuado (estilo de Windows C:\foo\ frente al estilo Unix /foo/) basado en el tipo de host del agente y el tipo de shell. Si ejecuta tareas de script de Bash en Windows, debe usar el método de variable de entorno para acceder a estas variables en lugar del método de variable de canalización para asegurarse de que tiene el estilo de ruta de acceso de archivo correcto.
Establecimiento de variables secretas
Sugerencia
Las variables secretas no se exportan automáticamente como variables de entorno. Para usar variables secretas en los scripts, asígnelas explícitamente a variables de entorno. Para más información, consulte Configurar variables de entorno.
No establezca variables secretas en el archivo YAML. Los sistemas operativos suelen registrar comandos para los procesos que ejecutan y no querrá que el registro incluya un secreto que haya pasado como entrada. Use el entorno del script o asigne la variable dentro del bloque variables para pasar secretos a la canalización.
Nota:
Azure Pipelines realiza un esfuerzo para enmascarar secretos al emitir datos a registros de canalización, por lo que es posible que vea variables adicionales y datos enmascarados en los registros y de salida que no están establecidos como secretos.
Debe establecer variables secretas en la interfaz de usuario de configuración de canalización para la canalización. Estas variables se limitan a la canalización donde se establecen. También puede establecer variables secretas en grupos de variables.
Para establecer secretos en la interfaz web, siga estos pasos:
- Vaya a la página Canalizaciones, seleccione la canalización adecuada y, después, seleccione Editar.
- Busque las Variables de esta canalización.
- Agregue la variable o actualícela.
- Seleccione la opción de Mantener el secreto de este valor para almacenar la variable de forma cifrada.
- Guarde la canalización.
Las variables de secreto se cifran en reposo con una clave RSA de 2048 bits. Los secretos están disponibles en el agente para que los usen las tareas y los scripts. Tenga cuidado con quién tiene acceso para modificar la canalización.
Importante
Hacemos un esfuerzo por enmascarar los secretos para que no aparezcan en la salida de Azure Pipelines, pero debe tomar precauciones. Nunca haga eco de secretos como salida. Algunos sistemas operativos registran los argumentos de la línea de comandos. Nunca pase secretos en la línea de comandos. En su lugar, se recomienda asignar los secretos a variables de entorno.
Nunca enmascaramos las subcadenas de los secretos. Si, por ejemplo, se establece "abc123" como secreto, "abc" no se enmascara en los registros. El objetivo de esto es no enmascarar los secretos de un modo demasiado pormenorizado, que haría los registros ilegibles. Por este motivo, los secretos no deben contener datos estructurados. Si, por ejemplo, se establece "{ "foo": "bar" }" como secreto, "bar" no se enmascara en los registros.
A diferencia de una variable normal, no se descifran automáticamente en variables de entorno para scripts. Debe asignar explícitamente variables secretas.
En el ejemplo siguiente se muestra cómo asignar y usar una variable secreta denominada mySecret en scripts de PowerShell y Bash. Se definen dos variables globales. A GLOBAL_MYSECRET se le asigna el valor de una variable mySecretsecreta y a GLOBAL_MY_MAPPED_ENV_VAR se le asigna el valor de una variable no secreta nonSecretVariable. A diferencia de una variable de canalización normal, no hay ninguna variable de entorno denominada MYSECRET.
La tarea de PowerShell ejecuta un script para imprimir las variables.
$(mySecret): se trata de una referencia directa a la variable secreta y funciona.$env:MYSECRET: intenta acceder a la variable secreta como una variable de entorno, que no funciona porque las variables secretas no se asignan automáticamente a las variables de entorno.$env:GLOBAL_MYSECRET: intenta acceder a la variable secreta a través de una variable global, que tampoco funciona porque las variables secretas no se pueden asignar de esta manera.$env:GLOBAL_MY_MAPPED_ENV_VAR: accede a la variable no secreta a través de una variable global, que funciona.$env:MY_MAPPED_ENV_VAR: accede a la variable secreta a través de una variable de entorno específica de la tarea, que es la manera recomendada de asignar variables secretas a variables de entorno.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
La salida de ambas tareas en el script anterior tendría este aspecto:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
También puede usar variables secretas fuera de scripts. Por ejemplo, puede asignar variables secretas a tareas mediante la definición variables. En este ejemplo se muestra cómo usar variables secretas $(vmsUser) y $(vmsAdminPass) en una tarea de copia de archivos de Azure.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@4
inputs:
SourcePath: 'my/path'
azureSubscription: 'my-subscription'
Destination: 'AzureVMs'
storage: 'my-storage'
resourceGroup: 'my-rg'
vmsAdminUserName: $(VMS_USER)
vmsAdminPassword: $(VMS_PASS)
Referencia de variables secretas en grupos de variables
En este ejemplo se muestra cómo hacer referencia a un grupo de variables en el archivo YAML y también cómo agregar variables dentro de YAML. Hay dos variables usadas del grupo de variables: user y token. La variable token es secreta y se asigna a la variable de entorno $env:MY_MAPPED_TOKEN para que se pueda hacer referencia a ella en YAML.
Este YAML realiza una llamada DE REST para recuperar una lista de versiones y genera el resultado.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Importante
De forma predeterminada, con los repositorios de GitHub, las variables secretas asociadas a la canalización no están disponibles para las compilaciones de bifurcaciones de solicitudes de incorporación de cambios. Para obtener más información, consulte Contribuciones de bifurcaciones.
Uso compartido de variables entre canalizaciones
Para compartir variables en varias canalizaciones del proyecto, use la interfaz web. En Biblioteca, use grupos de variables.
Uso de variables de salida de tareas
Algunas tareas definen variables de salida, que puede consumir en pasos, trabajos y fases de bajada. En YAML, puede acceder a variables entre trabajos y fases mediante dependencias.
Al hacer referencia a trabajos de matriz en tareas de bajada, deberá usar una sintaxis diferente. Consulte Establecimiento de una variable de salida de varios trabajos. También debe usar una sintaxis diferente para las variables en los trabajos de implementación. Consulte Compatibilidad con variables de salida en trabajos de implementación.
Algunas tareas definen variables de salida, que puede consumir en pasos, trabajos y fases de bajada. En YAML, puede acceder a variables entre trabajos y fases mediante dependencias.
- Para hacer referencia a una variable de una tarea diferente dentro del mismo trabajo, use
TASK.VARIABLE. - Para hacer referencia a una variable de una tarea de un trabajo diferente, use
dependencies.JOB.outputs['TASK.VARIABLE'].
Nota:
De forma predeterminada, cada fase de una canalización depende de la anterior en el archivo de YAML. Si necesita hacer referencia a una fase que no es inmediatamente anterior a la actual, puede invalidar este valor predeterminado automático agregando una sección dependsOn de a la fase.
Nota:
En los ejemplos siguientes se usa la sintaxis de canalización estándar. Si utiliza canalizaciones de implementación, la sintaxis de variables y variables condicionales será distinta. Para obtener información sobre la sintaxis específica que se va a usar, consulte Trabajos de implementación.
En estos ejemplos, supongamos que tenemos una tarea denominada MyTask, que establece una variable de salida denominada MyVar.
Obtenga más información sobre la sintaxis en Expresiones: dependencias.
Uso de salidas en el mismo trabajo
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Uso de salidas en otro trabajo
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Uso de salidas en otra fase
Para utilizar la salida de una etapa diferente, el formato para hacer referencia a variables es stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE']. En el nivel de fase, pero no en el nivel de trabajo, puede usar estas variables en condiciones.
Las variables de salida solo están disponibles en la siguiente fase de bajada. Si varias fases consumen la misma variable de salida, use la condición dependsOn.
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
También puede pasar variables entre fases con una entrada de archivo. Para ello, deberá definir variables en la segunda fase en el nivel de trabajo y, a continuación, pasar las variables como entradas env:.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
La salida de las fases de la canalización anterior tiene este aspecto:
Hello inline version
true
crushed tomatoes
Enumerar variables
Puede enumerar todas las variables de la canalización con el comando az pipelines variable list. Para empezar, consulte Introducción a la CLI de Azure DevOps.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Parámetros
- org: la URL de la organización de Azure DevOps. Puede configurar la organización predeterminada mediante
az devops configure -d organization=ORG_URL. Obligatorio si no está configurado como predeterminado o seleccionado mediantegit config. Ejemplo:--org https://dev.azure.com/MyOrganizationName/. - pipeline-id: obligatorio si no se proporciona pipeline-name. Identificador de la canalización.
- pipeline-name: obligatorio si no se proporciona pipeline-id, pero se omite si se proporciona pipeline-id. Nombre de la canalización.
- project: el nombre o id. del proyecto. El proyecto predeterminado se puede configurar mediante
az devops configure -d project=NAME_OR_ID. Es obligatorio si no está configurado como predeterminado o seleccionado mediantegit config.
Ejemplo
El siguiente comando enumera todas las variables del grupo de variables con el identificador 12 y muestra el resultado en formato de tabla.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Establecer variables en scripts
Los scripts pueden definir variables que se consumen posteriormente en los pasos posteriores de la canalización. Todas las variables establecidas por este método se tratan como cadenas. Para establecer una variable a partir de un script, use una sintaxis de comando e imprima en stdout.
Establecimiento de una variable con ámbito de trabajo a partir de un script
Para establecer una variable a partir de un script, use el comando de registro task.setvariable. Esto actualiza las variables de entorno para los trabajos posteriores. Los trabajos posteriores tienen acceso a la nueva variable con sintaxis de macro y en tareas como variables de entorno.
Cuando issecret se establece en true, el valor de la variable se guardará como secreto y se enmascarará en el registro. Para obtener más información sobre las variables secretas, consulte Comandos de registro.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
Los pasos posteriores también tendrán la variable de canalización agregada a su entorno. No se puede usar la variable en el paso que se define.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
Salida de la canalización anterior.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Establecimiento de una variable de salida de varios trabajos
Si desea que una variable esté disponible para trabajos futuros, debe marcarla como una variable de salida mediante isOutput=true. A continuación, puede asignarlo a trabajos futuros mediante la sintaxis $[] e incluir el nombre del paso que establece la variable. Las variables de salida de varios trabajos solo funcionan para trabajos en la misma fase.
Para pasar variables a trabajos en distintas fases, use la sintaxis de dependencias de fase.
Nota:
De forma predeterminada, cada fase de una canalización depende de la anterior en el archivo YAML. Por lo tanto, cada fase puede usar variables de salida de la fase anterior. Para acceder a más fases, deberá modificar el gráfico de dependencias, por ejemplo, si la fase 3 requiere una variable de la fase 1, deberá declarar una dependencia explícita en la fase 1.
Al crear una variable de salida de varios trabajos, debe asignar la expresión a una variable. En este YAML, $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] se asigna a la variable $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
Salida de la canalización anterior.
this is the value
this is the value
Si va a establecer una variable de una fase a otra, use stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
Si va a establecer una variable desde una matriz o sector, para hacer referencia a la variable al acceder a ella desde un trabajo de bajada, debe incluir:
- Nombre del trabajo.
- El paso.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA1)"
name: echovar
Asegúrese de prefijar el nombre del trabajo a las variables de salida de un trabajo de implementación . En este caso, el nombre del trabajo es A:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 Establecer las variables
Establecer las variables  Establecer las variables
Establecer las variables  Establecer las variables
Establecer las variables Establecimiento de variables mediante expresiones
Puede establecer una variable mediante una expresión . Ya hemos encontrado un caso de esto para establecer una variable en la salida de otra de un trabajo anterior.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
Puede usar cualquiera de las expresiones admitidas para establecer una variable. Este es un ejemplo de cómo establecer una variable para que actúe como un contador que comienza en 100, se incrementa en 1 para cada ejecución y se restablece a 100 todos los días.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
Para obtener más información sobre contadores, dependencias y otras expresiones, vea expresiones.
Configuración de variables que se pueden establecer para los pasos
Puede definir settableVariables dentro de un paso o especificar que no se puede establecer ninguna variable.
En este ejemplo, el script no puede establecer una variable.
steps:
- script: echo This is a step
target:
settableVariables: none
En este ejemplo, el script permite la variable sauce pero no la variable secretSauce. Verá una advertencia en la página de ejecución de canalización.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Permitir durante el tiempo en cola
Si una variable aparece en el bloque variables de un archivo YAML, su valor es fijo y no se puede invalidar en tiempo de cola. El procedimiento recomendado es definir las variables en un archivo YAML, pero hay ocasiones en las que esto no tiene sentido. Por ejemplo, es posible que quiera definir una variable secreta y no tener la variable expuesta en YAML. O bien, es posible que tenga que establecer manualmente un valor de variable durante la ejecución de la canalización.
Tiene dos opciones para definir valores en tiempo de cola Puede definir una variable en la interfaz de usuario y seleccionar la opción Permitir que los usuarios invaliden este valor al ejecutar esta canalización o puede usar parámetros en tiempo de ejecución en su lugar. Si la variable no es un secreto, el procedimiento recomendado es usar parámetros en tiempo de ejecución.
Para establecer una variable en tiempo de cola, agregue una nueva variable dentro de la canalización y seleccione la opción invalidar.
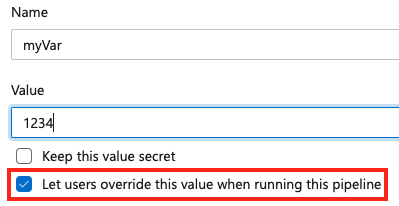
Para permitir que una variable se establezca en tiempo de cola, asegúrese de que la variable no aparezca también en el bloque variables de una canalización o trabajo. Si define una variable en el bloque de variables de un YAML y en la interfaz de usuario, el valor de YAML tiene prioridad.

Expansión de variables
Cuando se establece una variable con el mismo nombre en varios ámbitos, se aplica la prioridad siguiente (prioridad más alta primero).
- Variable de nivel de trabajo establecida en el archivo YAML
- Variable de nivel de trabajo establecida en el archivo YAML
- Variable de nivel de canalización establecida en el archivo YAML
- Variable establecida en tiempo de cola
- Variable de canalización establecida en la interfaz de usuario de configuración de canalización
En el ejemplo siguiente, la misma variable a se establece en el nivel de canalización y el nivel de trabajo en el archivo YAML. También se establece en un grupo de variables Gy como una variable en la interfaz de usuario de configuración de canalización.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
Al establecer una variable con el mismo nombre en el mismo ámbito, el último valor establecido tiene prioridad.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Nota:
Al establecer una variable en el archivo YAML, no la defina en el editor web como configurable en tiempo de cola. Actualmente no se pueden cambiar las variables que se establecen en el archivo YAML en tiempo de cola. Si necesita establecer una variable en tiempo de cola, no la establezca en el archivo YAML.
Las variables se expanden una vez cuando se inicia la ejecución y, de nuevo, al principio de cada paso. Por ejemplo:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
Hay dos pasos en el ejemplo anterior. La expansión de $(a) se produce una vez al principio del trabajo y una vez al principio de cada uno de los dos pasos.
Dado que las variables se expanden al principio de un trabajo, no se pueden usar en una estrategia. En el ejemplo siguiente, no se puede usar la variable a para expandir la matriz de trabajos, ya que la variable solo está disponible al principio de cada trabajo expandido.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
Si la variable a es una variable de salida de un trabajo anterior, puede usarla en un trabajo futuro.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Expansión recursiva
En el agente, las variables a las que se hace referencia mediante sintaxis $( ) se expanden recursivamente.
Por ejemplo:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"