El historial de datos de Azure Digital Twins (con Azure Data Explorer)
El historial de datos es una característica de integración de Azure Digital Twins. Permite conectar una instancia de Azure Digital Twins a un clúster de Azure Data Explorer para que las actualizaciones de grafos se historicen automáticamente a Azure Data Explorer . Estas actualizaciones historizadas incluyen actualizaciones de propiedades gemelas, eventos de ciclo de vida de gemelos y eventos de ciclo de vida de relaciones.
Una vez que se historizan las actualizaciones de grafos en Azure Data Explorer, puede ejecutar consultas conjuntas mediante el complemento Azure Digital Twins para Azure Data Explorer para razonar entre gemelos digitales, sus relaciones y datos de serie temporal. Esto se puede usar para examinar en el tiempo el estado del grafo que solía ser o para obtener información sobre el comportamiento de los entornos modelados. También puede usar estas consultas para reforzar los paneles operativos, enriquecer las aplicaciones web 2D y 3D e impulsar unas experiencias envolventes de realidad aumentada y mixta para transmitir el estado actual e histórico de recursos, procesos y personas que se modelan en Azure Digital Twins.
Para obtener más información sobre el historial de datos, incluida una demostración rápida, vea el siguiente vídeo de presentación de IoT:
Los mensajes emitidos por el historial de datos se miden en la dimensión de precios de los mensajes.
Requisitos previos: recursos y permisos
El historial de datos requiere los siguientes recursos:
- Instancia de Azure Digital Twins, con una identidad administrada asignada por el sistema habilitada.
- Espacio de nombres de Event Hubs que contiene un centro de eventos.
- Clúster de Azure Data Explorer que contiene una base de datos. El clúster debe tener habilitado el acceso a la red pública.
Estos recursos están conectados al flujo siguiente:
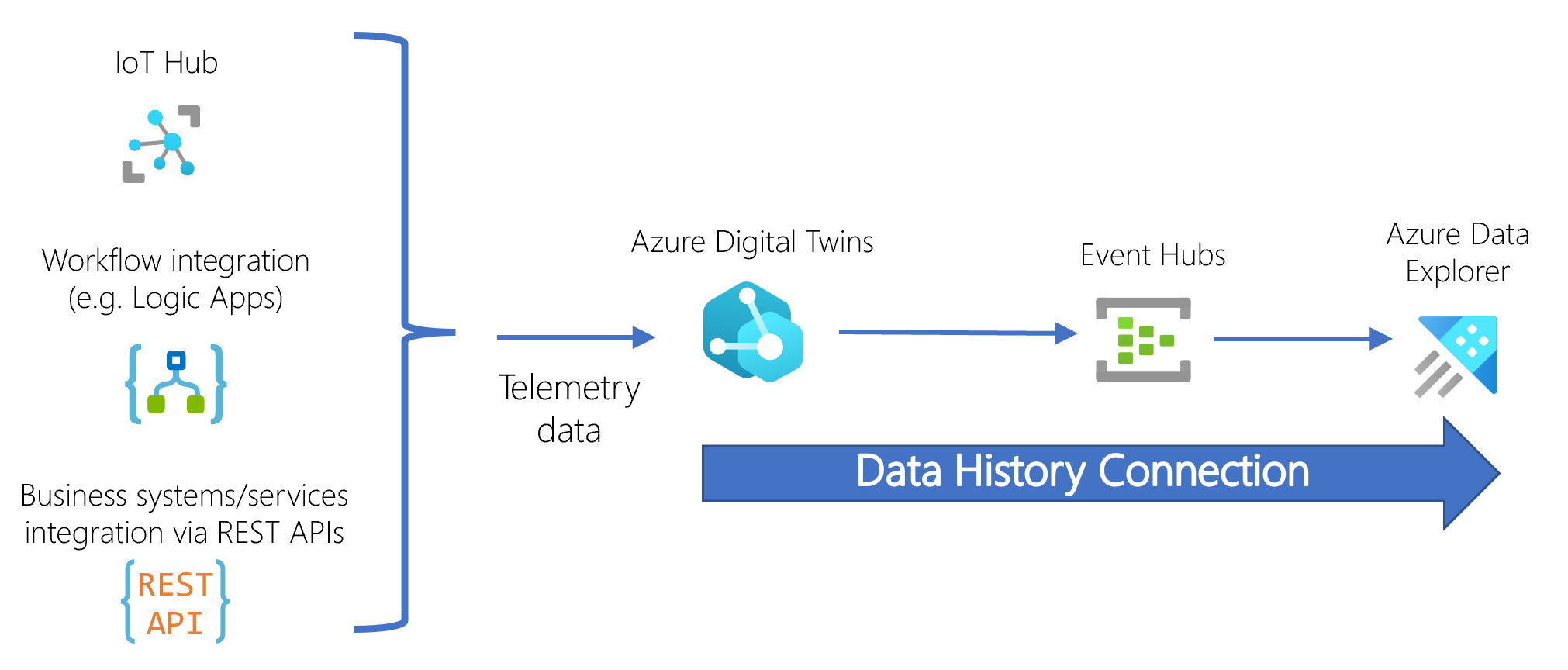
Cuando se actualiza el grafo de gemelos digitales, la información pasa a través del centro de eventos al clúster de Azure Data Explorer de destino, donde Azure Data Explorer almacena los datos como un registro con marca de tiempo en la tabla correspondiente.
Al trabajar con el historial de datos, se recomienda usar la versión 2023-01-31 o posterior de las API. Con la versión 2022-05-31 , solo se pueden historizar las propiedades gemelas (no el ciclo de vida del gemelo ni los eventos del ciclo de vida de las relaciones). Con versiones anteriores, el historial de datos no está disponible.
Permisos necesarios
Para configurar una conexión de historial de datos, la instancia de Azure Digital Twins debe tener los siguientes permisos para acceder a los recursos de Event Hubs y Azure Data Explorer. Estos roles permiten a Azure Digital Twins configurar el centro de eventos y la base de datos de Azure Data Explorer en su nombre (por ejemplo, crear una tabla en la base de datos). Opcionalmente, estos permisos se pueden eliminar después de configurar el historial de datos.
- Recurso de Event Hubs: Propietario de los datos de Azure Event Hubs
- Clúster de Azure Data Explorer: Colaborador (ámbito de todo el clúster o una base de datos específica)
- Asignación de entidad de seguridad de base de datos de Azure Data Explorer: Administrador (ámbito de la base de datos que se usa)
Posteriormente, la instancia de Azure Digital Twins debe tener el siguiente permiso en el recurso de Event Hubs mientras se usa el historial de datos: Emisor de datos de Azure Event Hubs (también puede optar por mantener Propietario de los datos de Azure Event Hubs en la configuración del historial de datos).
Estos permisos se pueden asignar mediante la CLI de Azure o Azure Portal.
Si desea restringir el acceso de red a los recursos implicados en el historial de datos (la instancia de Azure Digital Twins, el centro de eventos o el clúster de Azure Data Explorer), debe establecer esas restricciones después de configurar la conexión del historial de datos. Para obtener más información sobre este proceso, consulte Restricción del acceso de red a los recursos del historial de datos.
Creación y administración de la conexión del historial de datos
Esta sección contiene información para crear, actualizar y eliminar una conexión del historial de datos.
Creación de una conexión del historial de datos
Una vez configurados todos los recursos y permisos, puede usar la CLI de Azure, Azure Portal o el SDK de Azure Digital Twins para crear la conexión del historial de datos entre ellos. El conjunto de comandos de la CLI es az dt data-history.
El comando siempre creará una tabla para eventos de propiedad de gemelos historizados, que pueden usar el nombre predeterminado o un nombre personalizado que proporcione. Las eliminaciones de propiedades gemelas se pueden incluir opcionalmente en esta tabla. También puede proporcionar nombres de tabla para eventos de ciclo de vida de relaciones y eventos de ciclo de vida gemelos, y el comando creará tablas con esos nombres para historizar esos tipos de eventos.
Para obtener instrucciones paso a paso sobre cómo configurar una conexión de historial de datos, consulte Creación de una conexión de historial de datos.
Historial de varias instancias de Azure Digital Twins
Si lo desea, puede tener varias instancias de Azure Digital Twins historize actualizaciones en el mismo clúster de Azure Data Explorer.
Cada instancia de Azure Digital Twins tendrá su propia conexión de historial de datos destinada al mismo clúster de Azure Data Explorer. Dentro del clúster, las instancias pueden enviar sus datos gemelos a...
- un conjunto independiente de tablas en el clúster de Azure Data Explorer.
- el mismo conjunto de tablas en el clúster de Azure Data Explorer. Para ello, especifique los mismos nombres de tabla de Azure Data Explorer al crear las conexiones del historial de datos. En los esquemas de la tabla de historial de datos, la
ServiceIdcolumna de cada tabla contendrá la dirección URL de la instancia de Azure Digital Twins de origen, por lo que puede usar este campo para resolver qué instancia de Azure Digital Twins emitió cada registro en tablas compartidas.
Actualización de una conexión de historial de datos de solo propiedades
Antes de febrero de 2023, la característica de historial de datos solo actualiza las propiedades de gemelos historizados. Si tiene una conexión de historial de datos de solo propiedades desde ese momento, puede actualizarla para historizar todas las actualizaciones de grafos a Azure Data Explorer (incluidas las propiedades del gemelo, los eventos de ciclo de vida de gemelos y los eventos del ciclo de vida de las relaciones).
Esto requerirá la creación de nuevas tablas en el clúster de Azure Data Explorer para los nuevos tipos de actualizaciones historizadas (eventos de ciclo de vida gemelos y eventos de ciclo de vida de relaciones). En el caso de los eventos de propiedad gemelos, puede decidir si desea que la nueva conexión siga usando la misma tabla de la conexión del historial de datos original para almacenar las actualizaciones de propiedades gemelas en el futuro o si desea que la nueva conexión use un conjunto completamente nuevo de tablas. A continuación, siga las instrucciones siguientes para sus preferencias.
Si desea seguir usando la tabla existente para las actualizaciones de propiedades gemelas: siga las instrucciones de Creación de una conexión de historial de datos para crear una nueva conexión de historial de datos con las nuevas funcionalidades. El nombre de la conexión del historial de datos puede ser el mismo que el original o un nombre diferente. Use las opciones de parámetro para proporcionar nuevos nombres para las dos nuevas tablas de tipo de evento y para pasar el nombre de tabla original para la tabla de actualizaciones de propiedades gemelas. La nueva conexión invalidará la antigua y seguirá usando la tabla original para futuras actualizaciones de propiedades gemelas historizadas.
Si desea usar todas las tablas nuevas: en primer lugar, elimine la conexión del historial de datos original. A continuación, siga las instrucciones de Creación de una conexión de historial de datos para crear una nueva conexión de historial de datos con las nuevas funcionalidades. El nombre de la conexión del historial de datos puede ser el mismo que el original o un nombre diferente. Use las opciones de parámetro para proporcionar nuevos nombres para las tres tablas de tipo de evento.
Eliminación de una conexión de historial de datos
Puede usar la CLI de Azure, Azure Portal o las API y sdk de Azure Digital Twins para eliminar una conexión de historial de datos. El comando de la CLI es az dt data-history connection delete.
La eliminación de una conexión también ofrece la opción de limpiar los recursos asociados a la conexión del historial de datos (para el comando de la CLI, el parámetro opcional que se va a agregar es --clean true). Si usa esta opción, el comando eliminará los recursos de Azure Data Explorer que se usan para vincular el clúster al centro de eventos, incluidas las conexiones de datos para la base de datos y las asignaciones de ingesta asociadas a la tabla. La opción "limpiar recursos" no eliminará el centro de eventos real y el clúster de Azure Data Explorer que se usa para la conexión del historial de datos.
La limpieza es un intento de mejor esfuerzo y requiere que la cuenta que ejecuta el comando tenga permiso de eliminación para estos recursos.
Nota:
Si tiene varias conexiones de historial de datos que comparten el mismo centro de eventos o clúster de Azure Data Explorer, con la opción "limpiar recursos", mientras que la eliminación de una de estas conexiones puede interrumpir las demás conexiones del historial de datos que dependen de estos recursos.
Tipos de datos y esquemas
El historial de datos historiza tres tipos de eventos de la instancia de Azure Digital Twins en Azure Data Explorer: eventos de ciclo de vida de las relaciones, eventos de ciclo de vida de gemelos y actualizaciones de propiedades de gemelos (que, opcionalmente, pueden incluir eliminaciones de propiedades gemelas). Cada uno de estos tipos de eventos se almacena en su propia tabla dentro de la base de datos de Azure Data Explorer, lo que significa que el historial de datos mantiene tres tablas en total. Puede especificar nombres personalizados para las tablas al configurar la conexión del historial de datos.
En el resto de esta sección se describen las tres tablas de Azure Data Explorer con detalle, incluido el esquema de datos de cada tabla.
Actualizaciones de propiedades gemelas
La tabla de Azure Data Explorer para las actualizaciones de propiedades gemelas tiene un nombre predeterminado de AdtPropertyEvents. Puede dejar el nombre predeterminado al crear la conexión o especificar un nombre de tabla personalizado.
Los datos de serie temporal para las actualizaciones de propiedades gemelas se almacenan con el esquema siguiente:
| Attribute | Tipo | Descripción |
|---|---|---|
TimeStamp |
DateTime | Fecha y hora en que Azure Digital Twins procesó el mensaje de actualización de la propiedad. El sistema establece este campo y los usuarios no pueden escribir en este campo. |
SourceTimeStamp |
DateTime | Propiedad opcional que se puede escribir que representa la marca de tiempo cuando se observó la actualización de la propiedad en un entorno real. Esta propiedad solo se puede escribir con la versión 31-05-2022 de los SDK o las API de Azure Digital Twins, y el valor debe cumplir el formato de fecha y hora de la normativa ISO 8601. Para obtener más información sobre cómo actualizar esta propiedad, vea Actualizar el valor sourceTime de una propiedad. |
ServiceId |
Cadena | Identificador de instancia de servicio del servicio de Azure IoT que guarda el registro |
Id |
Cadena | Identificador del gemelo |
ModelId |
Cadena | Identificador de modelo DTDL (DTMI) |
Key |
Cadena | Nombre de la propiedad actualizada |
Value |
Dinámica | Valor de la propiedad actualizada |
RelationshipId |
Cadena | Cuando se actualiza una propiedad definida en una relación (en lugar de gemelos o dispositivos), este campo se rellena con el identificador de la relación. Cuando se actualiza una propiedad de gemelo, este campo está vacío. |
RelationshipTarget |
Cadena | Cuando se actualiza una propiedad definida en una relación (en lugar de gemelos o dispositivos), este campo se rellena con el identificador de gemelo del gemelo de destino de la relación. Cuando se actualiza una propiedad de gemelo, este campo está vacío. |
Action |
Cadena | Esta columna solo existe si decide historizar eventos de eliminación de propiedades. Si es así, esta columna contiene el tipo de evento de propiedad gemelo (actualización o eliminación) |
A continuación se muestra una tabla de ejemplo de actualizaciones de propiedades gemelas almacenadas en Azure Data Explorer.
TimeStamp |
SourceTimeStamp |
ServiceId |
Id |
ModelId |
Key |
Value |
RelationshipTarget |
RelationshipID |
|---|---|---|---|---|---|---|---|---|
| 2022-12-15 20:23:29.8697482 | 2022-12-15 20:22:14.3854859 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 130 | ||
| 2022-12-15 20:23:39.3235925 | 2022-12-15 20:22:26.5837559 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 140 | ||
| 2022-12-15 20:23:47.078367 | 2022-12-15 20:22:34.9375957 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 130 | ||
| 2022-12-15 20:23:57.3794198 | 2022-12-15 20:22:50.1028562 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | dtmi:assetGen:PasteurizationMachine;1 |
Output | 123 |
Representación de propiedades con varios campos
Deberá almacenar una propiedad con varios campos. Estas propiedades se representan con un objeto JSON en el atributo Value del esquema.
Por ejemplo, si representa una propiedad con tres campos para los valores relativos a "roll" (alabeo), "pitch" (cabeceo) y"yaw" (guiñada), el historial de datos almacenará el siguiente objeto JSON como Value: {"roll": 20, "pitch": 15, "yaw": 45}.
Eventos del ciclo de vida de gemelos
La tabla de Azure Data Explorer para eventos de ciclo de vida de gemelos tiene un nombre personalizado que especificará al crear la conexión del historial de datos.
Los datos de serie temporal para eventos de ciclo de vida de gemelos se almacenan con el esquema siguiente:
| Attribute | Tipo | Description |
|---|---|---|
TwinId |
Cadena | Identificador del gemelo |
Action |
Cadena | El tipo de evento de ciclo de vida del gemelo (crear o eliminar) |
TimeStamp |
DateTime | La fecha y hora en que Azure Digital Twins procesó el evento de ciclo de vida del gemelo. El sistema establece este campo y los usuarios no pueden escribir en este campo. |
ServiceId |
Cadena | Identificador de instancia de servicio del servicio de Azure IoT que guarda el registro |
ModelId |
Cadena | Identificador de modelo DTDL (DTMI) |
A continuación se muestra una tabla de ejemplo de actualizaciones del ciclo de vida de gemelo almacenadas en Azure Data Explorer.
TwinId |
Action |
TimeStamp |
ServiceId |
ModelId |
|---|---|---|---|---|
| PasteurizationMachine_A01 | Create | 2022-12-15 07:14:12.4160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| PasteurizationMachine_A02 | Create | 2022-12-15 07:14:12.4210 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
| SaltMachine_C0 | Create | 2022-12-15 07:14:12.5480 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:SaltMachine;1 |
| PasteurizationMachine_A02 | Eliminar | 2022-12-15 07:15:49.6050 | dairyadtinstance.api.wcus.digitaltwins.azure.net | dtmi:assetGen:PasteurizationMachine;1 |
Eventos del ciclo de vida de las relaciones
La tabla de Azure Data Explorer para los eventos del ciclo de vida de las relaciones tiene un nombre personalizado que especificará al crear la conexión del historial de datos.
Los datos de serie temporal para los eventos del ciclo de vida de las relaciones se almacenan con el esquema siguiente:
| Attribute | Tipo | Description |
|---|---|---|
RelationshipId |
Cadena | Identificador de relación. El sistema establece este campo y los usuarios no pueden escribir en este campo. |
Name |
Cadena | El nombre de la relación |
Action |
El tipo de evento de ciclo de vida de la relación (crear o eliminar) | |
TimeStamp |
DateTime | La fecha y hora en que Azure Digital Twins procesó el evento de ciclo de vida de la relación. El sistema establece este campo y los usuarios no pueden escribir en este campo. |
ServiceId |
Identificador de instancia de servicio del servicio de Azure IoT que guarda el registro | |
Source |
Identificador del gemelo de origen. Este es el identificador del gemelo donde se origina la relación. | |
Target |
Identificador del gemelo de destino. Este es el identificador del gemelo donde llega la relación. |
A continuación se muestra una tabla de ejemplo de actualizaciones del ciclo de vida de las relaciones almacenadas en Azure Data Explorer.
RelationshipId |
Name |
Action |
TimeStamp |
ServiceId |
Source |
Target |
|---|---|---|---|---|---|---|
| PasteurizationMachine_A01_feeds_Relationship0 | feeds | Create | 2022-12-15 07:16:12.7120 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A01 | SaltMachine_C0 |
| PasteurizationMachine_A02_feeds_Relationship0 | feeds | Create | 2022-12-15 07:16:12.7160 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A02 | SaltMachine_C0 |
| PasteurizationMachine_A03_feeds_Relationship0 | feeds | Create | 2022-12-15 07:16:12.7250 | dairyadtinstance.api.wcus.digitaltwins.azure.net | PasteurizationMachine_A03 | SaltMachine_C1 |
| OsloFactory_contains_Relationship0 | contains | Eliminar | 2022-12-15 07:16:13.1780 | dairyadtinstance.api.wcus.digitaltwins.azure.net | OsloFactory | SaltMachine_C0 |
Latencia de ingesta completa
El historial de datos de Azure Digital Twins se basa en el mecanismo de ingesta existente proporcionado por Azure Data Explorer. Azure Digital Twins garantizará que los eventos de actualización de grafos estén disponibles para Azure Data Explorer en menos de dos segundos. Azure puede introducir latencia adicional para la ingesta de datos de Data Explorer.
Hay dos métodos en Azure Data Explorer para la ingesta de datos: la ingesta por lotes y la ingesta de streaming. Puede configurar estos métodos de ingesta para tablas individuales según sus necesidades y el escenario de ingesta de datos específico.
La ingesta de streaming tiene la latencia más baja. Sin embargo, debido a la sobrecarga de procesamiento, este modo solo se debe usar si se ingieren menos de 4 GB de datos cada hora. La ingesta por lotes funciona mejor si se esperan altas tasas de datos de ingesta. Azure Data Explorer utiliza la ingesta por lotes de forma predeterminada. En la tabla siguiente se resume la latencia completa para el peor escenario previsto:
| Configuración de Data Explorer Azure | Latencia completa prevista | Velocidad de datos recomendada |
|---|---|---|
| Ingesta de streaming | <12 s (<3 s típico) | <4 GB/h |
| Ingesta por lotes | Varía (de 12 s a 15 min, según la configuración) | >4 GB/h |
El resto de esta sección contiene detalles para habilitar cada tipo de ingesta.
Ingesta por lotes (valor predeterminado)
Si no se configura de otro modo, Azure Data Explorer utilizará la ingesta por lotes. La configuración predeterminada puede suponer que los datos estén disponibles para la consulta solo entre 5 y 10 minutos tras realizarse una actualización de un gemelo digital. La directiva de ingesta se puede modificar, de modo que el procesamiento por lotes se produzca como máximo cada 10 segundos (como mínimo, o 15 minutos como máximo). Para modificar la directiva de ingesta, se debe emitir el siguiente comando en la vista de consulta de Azure Data Explorer:
.alter table <table_name> policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:10", "MaximumNumberOfItems": 500, "MaximumRawDataSizeMB": 1024}'
Asegúrese de que <table_name> se reemplaza por el nombre de la tabla que se ha configurado. MaximumBatchingTimeSpan debe establecerse en el intervalo de procesamiento por lotes preferido. La directiva puede tardar entre 5 y 10 minutos en entrar en vigor. Puede obtener más información sobre la ingesta por lotes en el siguiente vínculo: Comando de administración de directivas IngestionBatching de Kusto.
Ingesta de streaming
La habilitación de la ingesta de streaming es un proceso de dos pasos:
- Habilitar la ingesta de streaming para su clúster. Esta acción solo debe llevarse a cabo un vez. (Advertencia: su ejecución tendrá un efecto en la cantidad de almacenamiento disponible para la caché en caliente y puede suponer limitaciones adicionales). Para obtener instrucciones, consulte Configuración de la ingesta de streaming en el clúster de Azure Data Explorer.
- Agregue una directiva de ingesta de streaming para la tabla deseada. Puede obtener más información sobre cómo habilitar la ingesta de streaming para el clúster en la documentación de Azure Data Explorer: Comando de administración de directivas IngestionBatching de Kusto.
Para habilitar la ingesta de streaming para el historial de datos de Azure Digital Twins, se debe emitir el siguiente comando en el panel de consulta de Data Explorer:
.alter table <table_name> policy streamingingestion enable
Asegúrese de que <table_name> se reemplaza por el nombre de la tabla que se ha configurado. La directiva puede tardar entre 5 y 10 minutos en entrar en vigor.
Visualización de propiedades historizadas
Azure Digital Twins Explorer, una herramienta para desarrolladores para visualizar e interactuar con los datos de Azure Digital Twins, ofrece una característica explorador de historial de datos para ver las propiedades historizadas a lo largo del tiempo en un gráfico o una tabla. Esta característica también está disponible en 3D Scenes Studio, un entorno 3D inmersivo para proporcionar a Azure Digital Twins el contexto visual de los recursos 3D.

Para obtener información más detallada sobre el uso del explorador de historial de datos, consulte Validación y exploración de propiedades historizadas.
Nota:
Si tiene problemas al seleccionar una propiedad en la experiencia del Explorador de historial de datos visuales, esto puede significar que hay un error en algún modelo de la instancia. Por ejemplo, tener valores de enumeración no únicos en los atributos de un modelo interrumpirá esta característica de visualización. Si esto sucede, revise las definiciones del modelo y asegúrese de que todas las propiedades son válidas.
Pasos siguientes
Una vez que los datos gemelos se han pasado a Azure Data Explorer, puede usar el complemento de consulta de Azure Digital Twins para Azure Data Explorer para ejecutar consultas en los datos. Obtenga más información sobre el complemento aquí: Consulta con el complemento de Data Explorer Azure.
O bien, profundice en el historial de datos con instrucciones de creación y un escenario de ejemplo: Creación de una conexión de historial de datos.