¿Qué es Apache Flink® en Azure HDInsight en AKS? (versión preliminar)
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones en la Comunidad de Azure HDInsight.
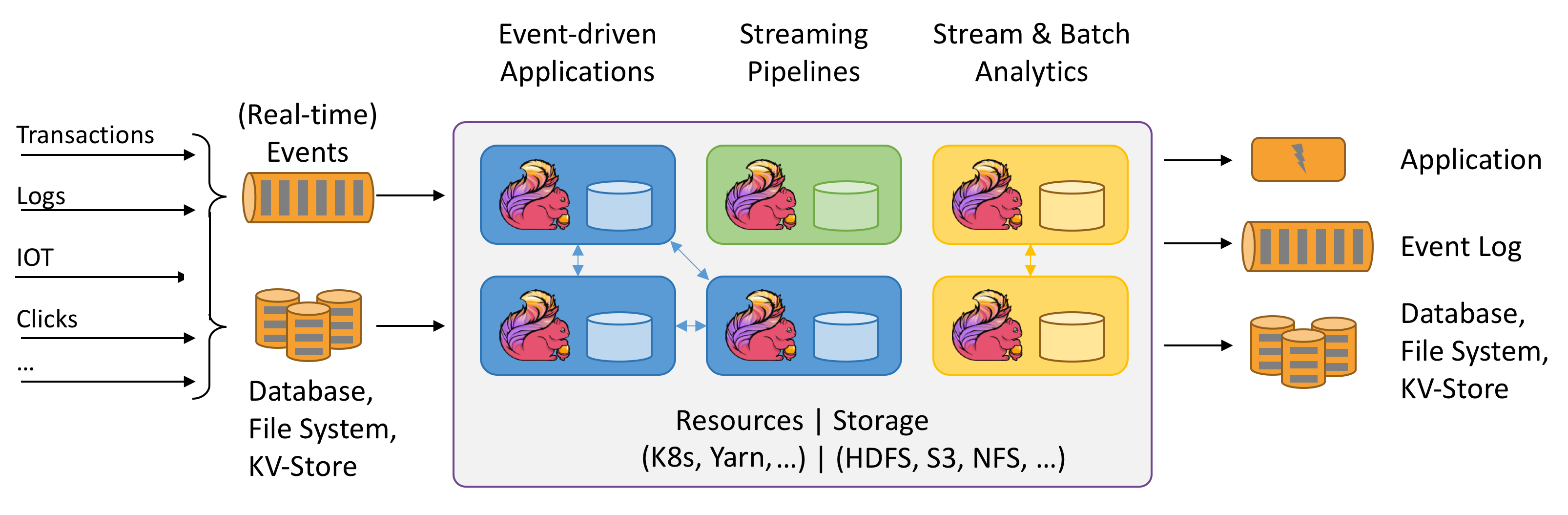
Apache Flink es un marco y un motor de procesamiento distribuido para cálculos con estado mediante flujos de datos enlazados y no enlazados. Flink se ha diseñado para ejecutarse en todos los entornos de clúster comunes, así como para ejecutar cálculos y aplicaciones de flujo con estado a velocidad en memoria y a cualquier escala. Las aplicaciones se paralelizan en, posiblemente, miles de tareas que se distribuyen y se ejecutan simultáneamente en un clúster. Por lo tanto, una aplicación puede usar cantidades ilimitadas de vCPU, memoria principal, disco y E/S de red. Además, Flink mantiene fácilmente el estado grande de la aplicación. Su algoritmo de punto de control asincrónico e incremental garantiza una influencia mínima en las latencias de procesamiento, al tiempo que garantiza la coherencia de estado exactamente una vez.
Apache Flink es un motor de análisis escalable de forma masiva para el procesamiento de flujos.
Entre las características clave que ofrece Flink se encuentran las siguientes:
- Operaciones en flujos enlazados y sin enlazar
- Rendimiento en memoria
- Capacidad de cálculos por lotes y de flujo
- Baja latencia, operaciones de alto rendimiento
- Procesamiento exactamente una vez
- Alta disponibilidad
- Estado y tolerancia a errores
- Totalmente compatible con el ecosistema de Hadoop
- API de SQL unificadas para flujos y lotes
¿Por qué utilizar Apache Flink?
Apache Flink es un excelente recurso para desarrollar y ejecutar muchos tipos diferentes de aplicaciones, debido a su amplio conjunto de características. Entre las características de Flink se encuentran la compatibilidad con el procesamiento por lotes y flujos, la sofisticada administración de estado, la semántica de procesamiento en tiempo de eventos y las garantías de consistencia de estado exactamente una vez. Flink no tiene un único punto de error. Flink ha demostrado su eficacia de escalación a miles de núcleos y a terabytes de estado de aplicación, ofrece un alto rendimiento y una baja latencia, y potencia algunas de las aplicaciones de procesamiento de flujos más exigentes del mundo.
- Detección de fraude: Flink se puede utilizar para detectar transacciones fraudulentas o actividades en tiempo real mediante la aplicación de reglas complejas y modelos de aprendizaje automático en flujos de datos.
- Detección de anomalías: Flink se puede utilizar para identificar valores atípicos o patrones anómalos en flujos de datos, como lecturas de sensores, tráfico de red o comportamientos de usuarios.
- Alertas basadas en reglas: Flink se puede utilizar para desencadenar alertas o notificaciones basadas en condiciones o umbrales predefinidos en los flujos de datos, como la temperatura, la presión o los precios de acciones.
- Supervisión de procesos empresariales: Flink se puede utilizar para efectuar un seguimiento y analizar el estado y el rendimiento de procesos empresariales o flujos de trabajo en tiempo real, como el suministro de pedidos, las entregas o el servicio al cliente.
- Aplicación web (red social): Flink se puede utilizar para impulsar aplicaciones web que requieren el procesamiento en tiempo real de datos generados por el usuario, como mensajes, menciones de «me gusta», comentarios o recomendaciones.
Obtenga más información sobre los casos de uso comunes descritos en los casos de uso de Apache Flink.
Los clústeres de Apache Flink en HDInsight en AKS son un servicio completamente administrado. Aquí se enumeran las ventajas de crear un clúster de Flink en HDInsight en AKS.
| Característica | Descripción |
|---|---|
| Creación sencilla | Puede crear un nuevo clúster de Flink en HDInsight en cuestión de minutos mediante Azure Portal, Azure PowerShell o el SDK. Consulte Introducción al clúster de Apache Flink en HDInsight en AKS. |
| Facilidad de uso | Los clústeres de Flink en HDInsight en AKS incluyen la administración de configuración basada en el portal, y el escalado. Además, con la API de administración de trabajos, se usa la API de REST o Azure Portal para la administración de trabajos. |
| API de REST | Los clústeres de Flink en HDInsight en AKS incluyen la API de administración de trabajos, un método de envío de trabajos de Flink basado en la API de REST para enviar y supervisar trabajos de forma remota en Azure Portal. |
| Tipo de implementación | Flink puede ejecutar aplicaciones en modo de sesión o modo de aplicación. Por ahora, HDInsight en AKS solo admite clústeres de sesión. Puede ejecutar varios trabajos de Flink en un clúster de sesión. El modo de aplicación está en la hoja de ruta de los clústeres de HDInsight en AKS |
| Compatibilidad con Metastore | Los clústeres de Flink en HDInsight en AKS pueden admitir catálogos con metastore de Hive en diferentes formatos de archivo abiertos con puntos de control remotos en Azure Data Lake Storage Gen2. |
| Compatibilidad con Azure Storage | Los clústeres de Flink en HDInsight pueden usar Azure Data Lake Storage Gen2 como receptor de archivos. Para más información sobre Data Lake Storage Gen2, consulte Azure Data Lake Storage Gen2. |
| Integración con servicios de Azure | El clúster de Flink en HDInsight en AKS incluye una integración de Kafka junto con Azure Event Hubs y Azure HDInsight. Puede compilar aplicaciones de streaming mediante Event Hubs o HDInsight. |
| Adaptabilidad | HDInsight en AKS le permite escalar los nodos del clúster de Flink según la programación con la característica escalabilidad automática. Consulte Escalado automático de clústeres de Azure HDInsight en AKS. |
| Back-end de estado | HDInsight en AKS usa RocksDB como StateBackend predeterminado. RocksDB es un almacén persistente de valor-clave insertable para un almacenamiento rápido. |
| Puntos de control | El establecimiento de punto de control está habilitado de manera predeterminada en clústeres de HDInsight en AKS. La configuración predeterminada en HDInsight en AKS mantiene los cinco últimos puntos de control en el almacenamiento persistente. En caso de que se produzca un error en el trabajo, este se puede reiniciar desde el punto de control más reciente. |
| Puntos de control incrementales | RocksDB admite puntos de control incrementales. Si bien recomendamos el uso de puntos de control incrementales para un estado grande, esta característica se debe habilitar manualmente. El establecimiento de un valor predeterminado en flink-conf.yaml: state.backend.incremental: true habilita los puntos de control incrementales, a menos que la aplicación invalide esta configuración en el código. Esta instrucción tiene el valor «true» de manera predeterminada. Alternativamente, puede configurar este valor directamente en el código (lo que invalida el valor predeterminado de configuración) EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true);. De manera predeterminada, se conservan los cinco últimos puntos de control en el directorio configurado para almacenar estos puntos. Este valor se puede cambiar en la sección de administración de configuración state.checkpoints.num-retained: 5. |
Los clústeres de Apache Flink en HDInsight en AKS incluyen los siguientes componentes que están disponibles en los clústeres de manera predeterminada.
Consulte la hoja de ruta para saber qué estará disponible próximamente.
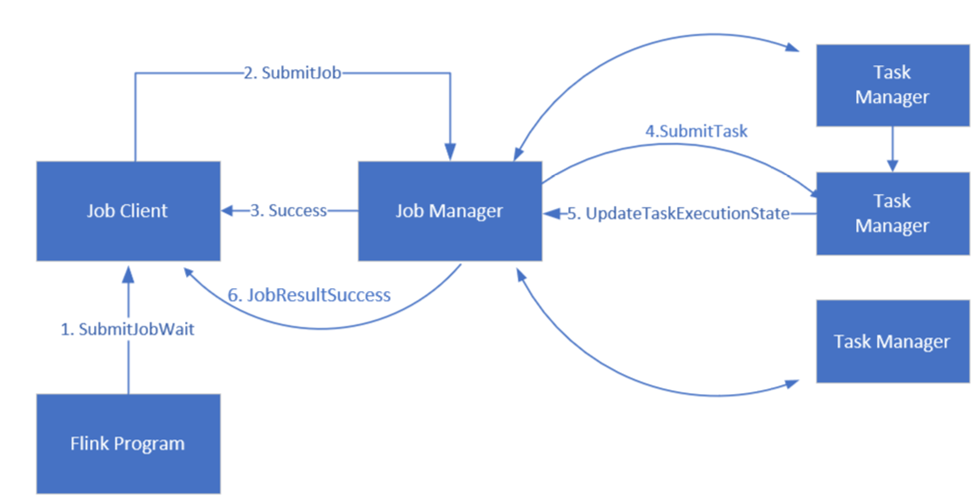
Administración de trabajos de Apache Flink
Flink programa trabajos con tres componentes distribuidos: administrador de trabajos, administrador de tareas y cliente de trabajos, configurados con arreglo a un modelo líder-seguidor.
Trabajo de Flink: un trabajo o programa de Flink consta de varias tareas. Las tareas son la unidad básica de ejecución en Flink. Cada tarea de Flink tiene varias instancias en función del nivel de paralelismo, y cada una de ellas se ejecuta en un TaskManager.
Administrador de trabajos: el administrador de trabajos actúa como programador y programa tareas en administradores de tareas.
Administrador de tareas: los administradores de tareas incluyen una o varias ranuras para ejecutar tareas en paralelo.
Cliente de trabajos: el cliente de trabajos se comunica con el administrador de trabajos para enviar trabajos de Flink.
Interfaz de usuario web de Flink: Flink incluye una interfaz de usuario web para inspeccionar, supervisar y depurar las aplicaciones en ejecución.
Referencia
- Sitio web de Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink y los nombres de proyecto de código abierto asociados son marcas comerciales de Apache Software Foundation (ASF).