¿Qué es Apache Spark™ en HDInsight en AKS? (versión preliminar)
Nota:
Retiraremos Azure HDInsight en AKS el 31 de enero de 2025. Antes del 31 de enero de 2025, deberá migrar las cargas de trabajo a Microsoft Fabric o un producto equivalente de Azure para evitar la terminación repentina de las cargas de trabajo. Los clústeres restantes de la suscripción se detendrán y quitarán del host.
Solo el soporte técnico básico estará disponible hasta la fecha de retirada.
Importante
Esta funcionalidad actualmente está en su versión preliminar. En Términos de uso complementarios para las versiones preliminares de Microsoft Azure encontrará más términos legales que se aplican a las características de Azure que están en versión beta, en versión preliminar, o que todavía no se han lanzado con disponibilidad general. Para más información sobre esta versión preliminar específica, consulte la Información de Azure HDInsight sobre la versión preliminar de AKS. Para plantear preguntas o sugerencias sobre la característica, envíe una solicitud en AskHDInsight con los detalles y síganos para obtener más actualizaciones sobre Comunidad de Azure HDInsight.
Apache Spark™ es una plataforma de procesamiento paralelo que admite el procesamiento en memoria para mejorar el rendimiento de aplicaciones de análisis de macrodatos.
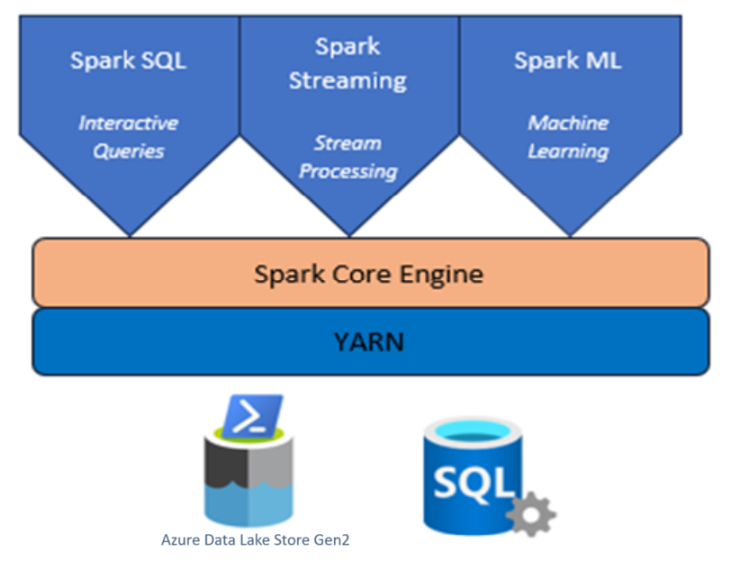
Apache Spark™ proporciona primitivas para la computación de clústeres en memoria. Un trabajo de Spark puede cargar y almacenar en la memoria caché datos, y repetir consultas sobre ellos. La informática en memoria es más rápida que las aplicaciones basadas en disco, como Hadoop, que comparte datos mediante el sistema de archivos distribuidos Hadoop (HDFS). Apache Spark permite la integración con los lenguajes de programación Scala y Python para permitirle manipular conjuntos de datos distribuidos como colecciones locales. No se necesita estructurar todo como operaciones de asignación y reducción.
Clúster de Apache Spark con HDInsight en AKS
Azure HDInsight es un servicio administrado, de espectro completo y de análisis de código abierto para empresas.
Apache Spark™ en Azure HDInsight en AKS es el servicio de Spark administrado en Microsoft Azure. Con Apache Spark en Azure HDInsight en AKS, puede almacenar y procesar los datos dentro de Azure. Los clústeres de Spark en HDInsight son compatibles con o Azure Data Lake Storage Gen2, lo que le permite aplicar el procesamiento de Spark en los almacenes de datos existentes.
El marco Apache Spark para HDInsight en AKS permite el análisis de datos rápido y la computación en clúster utilizando el procesamiento en memoria. Jupyter Notebook permite interactuar con los datos, combinar código con texto Markdown y realizar visualizaciones simples.
Apache Spark en AKS en HDInsight se compone por varios componentes como pods.
Controladores de clúster
Los controladores de clúster son responsables de instalar y administrar el servicio respectivo. Varios controladores se instalan y administran en un clúster de Spark.
Componentes del servicio Apache Spark
Servicio Zookeeper: un clúster de Zookeeper de tres nodos, actúa como coordinador distribuido o almacenamiento de alta disponibilidad para otros servicios.
Servicio Yarn: clúster de Yarn de Hadoop, los trabajos de Spark se programarían en el clúster como aplicaciones de Yarn.
Interfaces de cliente: los clústeres de Apache Spark en HDInsight en AKS proporcionan varias interfaces de cliente. Livy Server, Jupyter Notebook, Spark History Server, proporciona servicios de Spark a HDInsight en usuarios de AKS.
Referencia
- Apache, Apache Spark, Spark y los nombres de proyecto de código abierto asociados son marcas comerciales de Apache Software Foundation (ASF).