Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Apache Hadoop era el entorno de trabajo de código abierto original para el procesamiento distribuido y análisis de macrodatos en clústeres. El ecosistema de Hadoop incluye utilidades y software relacionados, como Apache Hive, Apache HBase, Spark, Kafka, entre otros muchos.
Azure HDInsight es un servicio de análisis, de código abierto, espectro completo y totalmente administrado en la nube para empresas. El tipo de clúster de Apache Hadoop en Azure HDInsight permite usar el sistema de archivos distribuido Apache Hadoop (HDFS), la administración de recursos de Apache Hadoop YARN y un modelo de programación sencillo de MapReduce para procesar y analizar datos de por lotes en paralelo. Los clústeres de Hadoop en HDInsight son compatibles con Azure Data Lake Storage Gen2.
Para ver los componentes disponibles de la pila de tecnología de Hadoop en HDInsight, consulte ¿Cuáles son los componentes y versiones de Hadoop disponibles con HDInsight?. Para más información sobre Hadoop en HDInsight, consulte la página de características de Azure para HDInsight.
¿Qué es MapReduce?
MapReduce de Apache Hadoop es un marco de software para escribir trabajos que procesan enormes cantidades de datos. Los datos de entrada se dividen en fragmentos independientes. Cada fragmento se procesa en paralelo en todos los nodos del clúster. Un trabajo de MapReduce consta de dos funciones:
Asignador: consume datos de entrada, los analiza (normalmente con un filtro y operaciones de ordenación) y emite tuplas (pares de clave-valor)
Reductor: consume tuplas emitidas por el asignador y realiza una operación de resumen que crea un resultado combinado más pequeño de los datos del asignador
En el siguiente diagrama se muestra un ejemplo de trabajo de MapReduce de recuento de palabras básico:
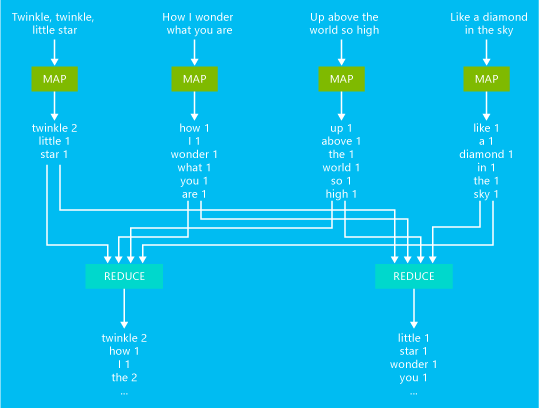
La salida de este trabajo es un recuento de las veces que aparece cada palabra en el texto.
- El asignador utiliza cada línea del texto de entrada como una entrada y la desglosa en palabras. Emite un par clave-valor cada vez que se detecta una palabra, seguida por un 1. La salida se ordena antes de enviarla al reductor.
- El reductor suma estos recuentos individuales de cada palabra y emite un solo par clave-valor que contiene la palabra seguido de la suma de sus apariciones.
MapReduce se puede implementar en varios lenguajes. Java es la implementación más común y se utiliza para fines de demostración en este documento.
Lenguajes de desarrollo
Tanto los lenguajes como los marcos de trabajo basados en Java y en la máquina virtual Java se pueden ejecutar directamente como un trabajo de MapReduce. El ejemplo usado en este documento es una aplicación de MapReduce de Java. Los lenguajes que no son Java, como C# o Python, o ejecutables independientes, deben usar streaming de Hadoop.
El streaming de Hadoop se comunica con el asignador y el reductor a través de STDIN y STDOUT. El asignador y reductor leen datos línea a línea desde STDIN y escriben el resultado en STDOUT. Cada línea leída o emitida por el asignador y el reductor debe estar en el formato de un par de clave-valor delimitado por un carácter de tabulación:
[key]\t[value]
Para obtener más información, consulte Streaming de Hadoop.
Para obtener ejemplos del uso del streaming de Hadoop con HDInsight, consulte el siguiente documento:
¿Por dónde empiezo?
- Inicio rápido: Creación de un clúster de Apache Hadoop en Azure HDInsight mediante Azure Portal
- Tutorial: Envío de trabajos de Apache Hadoop en HDInsight
- Desarrollo de programas MapReduce de Java para Apache Hadoop en HDInsight
- Uso de Apache Hive como una herramienta de extracción, transformación y carga de datos (ETL)
- Extracción, transformación y carga de datos (ETL) a escala
- Uso de una canalización de análisis de datos