Ejecución de las consultas de Apache Hive mediante las herramientas de Data Lake para Visual Studio
Aprenda a usar las herramientas de Data Lake para Visual Studio a fin de realizar consultas en Apache Hive. Las herramientas de Data Lake permiten crear, enviar y supervisar fácilmente consultas de Hive en Apache Hadoop en Azure HDInsight.
Requisitos previos
Un clúster de Apache Hadoop en HDInsight. Para más información sobre la creación de este elemento, consulte Creación de clústeres de Apache Hadoop en Azure HDInsight con plantillas de Resource Manager.
Visual Studio. En los pasos que se describen en este artículo, se utiliza Visual Studio 2019.
Herramientas de HDInsight para Visual Studio o Azure Data Lake Tools for Visual Studio. Para más información acerca de cómo instalar y configurar las herramientas, consulte Instalación de herramientas de Data Lake para Visual Studio.
Ejecución de consultas de Apache Hive con Visual Studio
Para crear y ejecutar consultas de Hive tiene dos opciones:
- Crear consultas ad hoc.
- Crear una aplicación de Hive.
Creación de una consulta ad hoc de Hive
Las consultas ad hoc se pueden ejecutar en el modo Lotes o Interactivo.
Inicie Visual Studio y seleccione Continuar sin código.
En el Explorador de servidores, haga clic con el botón derecho en Azure, seleccione Conectar a la suscripción de Microsoft Azure... y complete el proceso de inicio de sesión.
Expanda HDInsight, haga clic con el botón derecho en el clúster donde quiere ejecutar la consulta y seleccione Escribir una consulta de Hive.
Especifique esta consulta de Hive:
SELECT * FROM hivesampletable;Seleccione Ejecutar. El valor predeterminado del modo de ejecución es Interactivo.
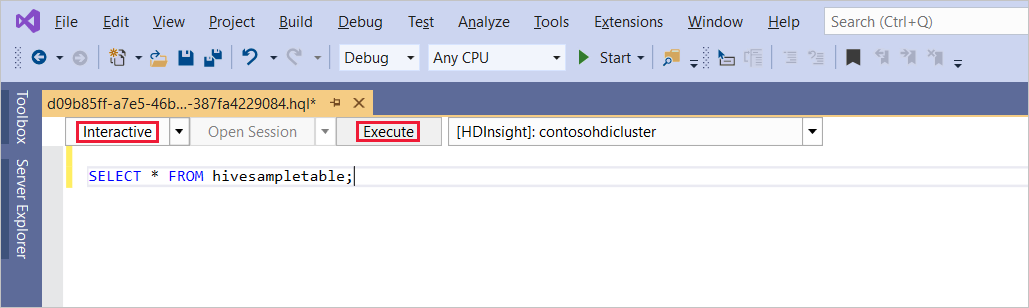
Para ejecutar la misma consulta en el modo Lotes, cambie la lista desplegable de Interactivo a Lotes. El botón de ejecución cambia de Ejecutar a Enviar.

El editor de Hive es compatible con IntelliSense. Data Lake Tools para Visual Studio es compatible con la carga de metadatos remotos cuando se edita un script de Hive. Por ejemplo, si escribe
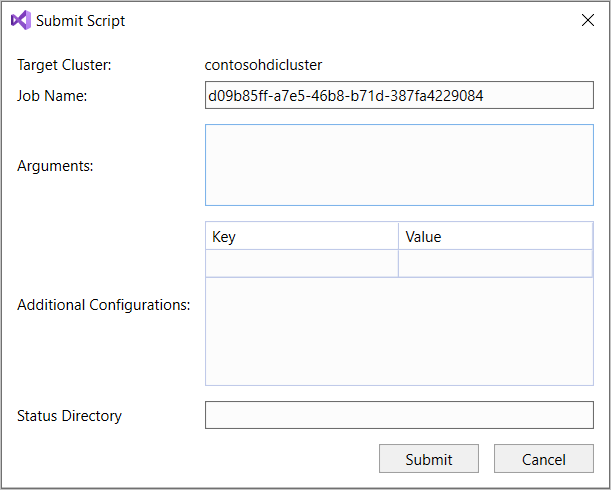
SELECT * FROM, IntelliSense enumera todos los nombres de tabla sugeridos. Cuando se especifica un nombre de tabla, IntelliSense enumera los nombres de columna. Las herramientas admiten casi todas las instrucciones DML de Hive, subconsultas y UDF integradas. IntelliSense solo sugiere los metadatos del clúster que se seleccionan en la barra de herramientas de HDInsight.En la barra de herramientas de consulta (el área situada debajo de la pestaña de consulta y encima del texto de la consulta), seleccione Enviar o haga clic en la flecha desplegable situada junto a Enviar y elija Opciones avanzadas. Si selecciona la última opción,
Si selecciona la opción de envío avanzado, configure las opciones Nombre del trabajo, Argumentos, Configuraciones adicionales y Estado de directorio en el cuadro de diálogo Enviar script. Después, seleccione Enviar.
Crear una aplicación de Hive
Para ejecutar una consulta de Hive creando una aplicación de Hive, siga estos pasos:
Abra Visual Studio.
En la ventana Inicio, seleccione Crear un proyecto.
En la ventana Crear un nuevo proyecto, en el cuadro Buscar plantillas, escriba Hive. A continuación, elija Aplicación de Hive y seleccione Siguiente.
En la ventana Configure su nuevo proyecto, escriba el nombre del proyecto, seleccione o cree una ubicación para el nuevo proyecto y haga clic en Crear.
Abra el archivo Script.hql creado con este proyecto y péguelo en las siguientes instrucciones de HiveQL:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;Estas instrucciones realizan las acciones siguientes:
DROP TABLE: elimina la tabla, si existe.CREATE EXTERNAL TABLE: Crea una tabla 'externa' en Hive. Las tablas externas solo almacenan la definición de Tabla en Hive. (Los datos permanecen en la ubicación original).Nota
Las tablas externas deben utilizarse si espera que los datos subyacentes se actualicen mediante un origen externo, como un trabajo de MapReduce o un servicio de Azure.
La eliminación de una tabla externa no elimina los datos, solamente la definición de tabla.
ROW FORMAT: Indica cómo se da formato a los datos de Hive. En este caso, los campos de cada registro se separan mediante un espacio.STORED AS TEXTFILE LOCATION: indica a Hive que los datos deben almacenarse en el directorio example/data como texto.SELECT: selecciona todas las filas en las que la columnat4contiene el valor[ERROR]. Esta instrucción devuelve el valor3porque hay tres filas que contienen este valor.INPUT__FILE__NAME LIKE '%.log': indica a Hive que solo debe devolver datos de los archivos que terminan por .log. Esta cláusula limita la búsqueda al archivo sample.log que contiene los datos.
En la barra de herramientas del archivo de consulta (que tiene una apariencia similar a la de la barra de herramientas de consultas ad hoc), seleccione el clúster de HDInsight que desea usar para esta consulta. A continuación, cambie Interactivo a Lote (si es necesario) y seleccione Enviar para ejecutar las instrucciones como un trabajo de Hive.
El resumen del trabajo de Hive aparecerá y mostrará información sobre el trabajo en ejecución. Use el vínculo Actualizar para actualizar la información del trabajo, hasta que el estado del trabajo cambie a Completado.
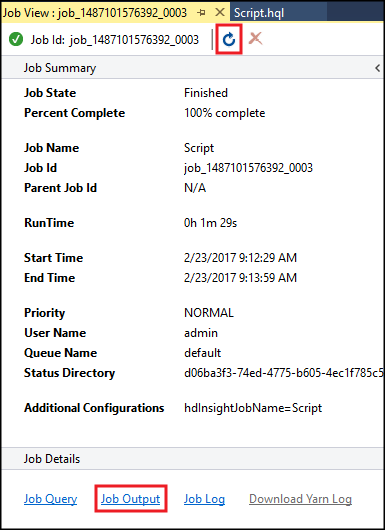
Seleccione Salida del trabajo para ver el resultado de este trabajo. Muestra
[ERROR] 3, que es el valor que devuelve esta consulta.
Ejemplo adicional
El ejemplo siguiente se basa en la tabla log4jLogs creada en el procedimiento anterior, Creación de una aplicación de Hive.
En el Explorador de servidores, haga clic con el botón derecho en el clúster y seleccione Escribir una consulta de Hive.
Especifique esta consulta de Hive:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';Estas instrucciones realizan las acciones siguientes:
CREATE TABLE IF NOT EXISTS: crea una tabla, en caso de que no exista todavía. Como no se utiliza la palabra claveEXTERNAL, esta instrucción crea una tabla interna. Las tablas internas se guardan en el almacenamiento de datos de Hive y Hive las administra.Nota
A diferencia de las tablas
EXTERNAL, la eliminación de una tabla interna también eliminará los datos subyacentes.STORED AS ORC: almacena los datos en formato de columnas de filas optimizadas (ORC). ORC es un formato altamente optimizado y eficiente para almacenar datos de Hive.INSERT OVERWRITE ... SELECT: Selecciona filas de la tablalog4jLogsque contienen[ERROR]y luego inserta los datos en la tablaerrorLogs.
Si es necesario, cambie Interactivo por Lote y seleccione Enviar.
Para comprobar si el trabajo creó la tabla, vaya al Explorador de servidores y expanda Azure>HDInsight. Expanda el clúster de HDInsight y después Bases de datos de Hive>predeterminado. Se muestran la tabla errorLogs y la tabla Log4jLogs.
Pasos siguientes
Como puede ver, las herramientas de HDInsight para Visual Studio proporcionan una manera sencilla de trabajar con consultas de Hive en HDInsight.
Para más información sobre Hive en HDInsight, consulte ¿Qué son Apache Hive y HiveQL en Azure HDInsight?.
Para más información sobre otras formas en que puede trabajar con Hadoop en HDInsight, consulte Uso de MapReduce con Apache Hadoop en HDInsight.
Para más información acerca de las herramientas de HDInsight para Visual Studio, consulte Uso de Herramientas de Data Lake para Visual Studio para conectarse a Azure HDInsight y ejecutar consultas de Apache Hive