Solucione problemas de YARN de Apache Hadoop con Azure HDInsight.
Obtenga información sobre los principales problemas y sus soluciones al trabajar con cargas útiles de Apache Hadoop YARN en Apache Ambari.
¿Cómo se crea una nueva cola de YARN en un clúster?
Pasos de resolución
Para crear una nueva cola de YARN y equilibrar la asignación de capacidad en todas las colas, siga estos pasos en Ambari.
En este ejemplo, se cambia la capacidad de las dos colas existentes (default (predeterminado) y thriftsvr) del 50% al 25%, lo que proporciona una capacidad del 50% a la nueva cola (spark).
| Cola | Capacity | Capacidad máxima |
|---|---|---|
| default | 25 % | 50 % |
| thrftsvr | 25 % | 50 % |
| spark | 50 % | 50 % |
Seleccione el icono Ambari Views (Vistas de Ambari) y, a continuación, seleccione el patrón de cuadrícula. A continuación, seleccione YARN Queue Manager (Administrador de colas de YARN).

Seleccione la cola default.

Para la cola default, cambie la capacidad del 50% al 25%. Para la cola thriftsvr, cambie la capacidad al 25%.
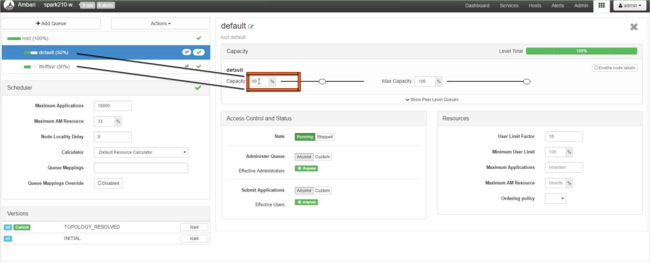
Seleccione Add Queue (Agregar cola) para crear una nueva cola.

Asigne un nombre a la cola nueva.

Deje los valores de Capacity (Capacidad) en el 50 % y seleccione el botón Actions (Acciones).

Seleccione Save and Refresh Queues (Guardar y actualizar colas).

Estos cambios están visibles inmediatamente en la interfaz de usuario de YARN Scheduler.
Información adicional
¿Cómo se descargan registros de YARN desde un clúster?
Pasos de resolución
Conéctese al clúster de HDInsight con un cliente Secure Shell (SSH). Para más información, consulte Otras lecturas.
Enumere todos los identificadores de aplicación de las aplicaciones Yarn que se están ejecutando con el siguiente comando:
yarn topLos identificadores aparecen en la columna APPLICATIONID. Puede descargar los registros desde la columna APPLICATIONID.
YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerDescargue los registros de contenedor de YARN para todos los maestros de aplicación con el siguiente comando:
yarn logs -applicationIdn logs -applicationId <application_id> -am ALL > amlogs.txtEste comando crea un archivo de registro denominado amlogs.txt.
Descargue los registros de contenedor de YARN solo para el maestro de aplicación más reciente con el siguiente comando:
yarn logs -applicationIdn logs -applicationId <application_id> -am -1 > latestamlogs.txtEste comando crea un archivo de registro denominado latestamlogs.txt.
Descargue los registros de contenedor de YARN para los dos primeros maestros de aplicación con el siguiente comando:
yarn logs -applicationIdn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtEste comando crea un archivo de registro denominado first2amlogs.txt.
Descargue todos los registros de contenedor de YARN con el siguiente comando:
yarn logs -applicationIdn logs -applicationId <application_id> > logs.txtEste comando crea un archivo de registro denominado logs.txt.
Descargue el registro de YARN de un contenedor determinado con el siguiente comando:
yarn logs -applicationIdn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txtEste comando crea un archivo de registro denominado containerlogs.txt.
Otras lecturas
- Conexión a HDInsight (Apache Hadoop) con SSH
- Apache Hadoop Yarn concepts and applications (Conceptos y aplicaciones de YARN en Apache Hadoop)
¿Cómo puedo comprobar la información de diagnóstico de aplicaciones de Yarn?
Diagnósticos en la interfaz de usuario de Yarn es una característica que permite ver el estado y los registros de las aplicaciones que se ejecutan en Yarn. Los diagnósticos pueden ayudarle a solucionar problemas y depurar las aplicaciones, así como a supervisar el rendimiento y el uso de recursos.
Para ver los diagnósticos de una aplicación específica, puede hacer clic en el id. de la aplicación en la lista de aplicaciones. En la página de detalles de la aplicación, también puede ver una lista de todos los intentos que se han realizado para ejecutar la aplicación. Puede hacer clic en cualquier intento para ver más detalles, como el id. de intento, el id. de contenedor, el id. de nodo, la hora de inicio, la hora de finalización y los diagnósticos

¿Cómo soluciono los problemas comunes de YARN?
La interfaz de usuario de YARN no se carga
Si la interfaz de usuario de YARN no se carga o no está accesible y devuelve "Error HTTP 502.3: Puerta de enlace incorrecta", significa que, con bastante probabilidad, el servicio Resource Manager tiene un estado incorrecto. Para mitigar el problema, siga estos pasos:
- Vaya a la interfaz de usuario de Ambari>YARN>SUMMARY (Resumen) y compruebe si el servicio Resource Manager activo es el único que tiene el estado Started (Iniciado). Si no es así, intente mitigar el problema reiniciando el servicio Resource Manager incorrecto o detenido.
- Si el paso 1 no resuelve el problema, conéctese mediante SSH al nodo principal de Resource Manager activo y compruebe el estado de la recolección de elementos no utilizados en
jstat -gcutil <Resource Manager pid> 1000 100. Si ve que el valor de FGCT aumenta mucho en cuestión de segundos, significa que Resource Manager está ocupado con una GC completa y no puede procesar las otras solicitudes. - Vaya a la interfaz de usuario de Ambari>YARN>CONFIGS>Advanced (YARN > Configuraciones > Avanzado) y aumente el valor de
Resource Manager java heap size. - Reinicie los servicios necesarios en la interfaz de usuario de Ambari.
Ambos administradores de recursos están en espera
- Consulte el registro de Resource Manager para ver si hay algún error similar.
Service RMActiveServices failed in state STARTED; cause: org.apache.hadoop.service.ServiceStateException: com.google.protobuf.InvalidProtocolBufferException: Could not obtain block: BP-452067264-10.0.0.16-1608006815288:blk_1074235266_494491 file=/yarn/node-labels/nodelabel.mirror
Si el error existe, compruebe si hay algún archivo que esté en replicación o si faltan bloques en HDFS. Puede ejecutar
hdfs fsck hdfs://mycluster/.Ejecute
hdfs fsck hdfs://mycluster/ -deletepara limpiar concienzudamente HDFS y deshacerse del problema de RM en espera. Como alternativa, ejecute PatchYarnNodeLabel en uno de los nodos principales para aplicar revisiones al clúster.
Pasos siguientes
Si su problema no aparece o es incapaz de resolverlo, visite uno de nuestros canales para obtener ayuda adicional:
Obtenga respuestas de expertos de Azure mediante el soporte técnico de la comunidad de Azure.
Póngase en contacto con @AzureSupport, la cuenta oficial de Microsoft Azure para mejorar la experiencia del cliente. Esta cuenta pone en contacto a la comunidad de Azure con los recursos adecuados: respuestas, soporte técnico y expertos.
Si necesita más ayuda, puede enviar una solicitud de soporte técnico desde Azure Portal. Seleccione Soporte técnico en la barra de menús o abra la central Ayuda + soporte técnico. Para obtener información más detallada, revise Creación de una solicitud de soporte técnico de Azure. La suscripción a Microsoft Azure incluye acceso al soporte técnico para facturación y administración de suscripciones. El soporte técnico se proporciona a través de uno de los planes de soporte técnico de Azure.