Previsión a gran escala: muchos modelos y entrenamiento distribuido
Este artículo trata sobre el entrenamiento de modelos de previsión en grandes cantidades de datos históricos. Puede encontrar instrucciones y ejemplos para entrenar modelos de previsión en AutoML en nuestro artículo Configuración de AutoML para la previsión de series temporales.
Los datos de serie temporal pueden ser grandes debido al número de series en los datos, el número de observaciones históricas o ambos. Muchos modelos y series temporales jerárquicas, o HTS, son soluciones de escalado para el escenario anterior, donde los datos constan de un gran número de series temporales. En estos casos, puede ser beneficioso para la precisión del modelo y la escalabilidad dividir los datos en grupos y entrenar un gran número de modelos independientes en paralelo en los grupos. Por el contrario, hay escenarios en los que uno o un pequeño número de modelos de alta capacidad son mejores. El entrenamiento de DNN distribuido tiene como destino este caso. Revisamos los conceptos sobre estos escenarios en el resto del artículo.
Many Models
Los componentes de muchos modelos de AutoML permiten entrenar y administrar millones de modelos en paralelo. Por ejemplo, supongamos que tiene datos históricos de ventas para un gran número de tiendas. Puede usar muchos modelos para iniciar trabajos de entrenamiento de AutoML en paralelo para cada almacén, como en el diagrama siguiente:

El componente de entrenamiento de muchos modelos aplica el barrido y la selección de modelos de AutoML de forma independiente a cada almacén de este ejemplo. Esta independencia del modelo ayuda a la escalabilidad y puede beneficiar la precisión del modelo, especialmente cuando las tiendas tienen dinámicas de ventas divergentes. Sin embargo, un enfoque de modelo único puede producir previsiones más precisas cuando hay dinámicas de ventas comunes. Consulte la sección de entrenamiento de DNN distribuido para obtener más información sobre ese caso.
Puede configurar la creación de particiones de datos, la configuración de AutoML para los modelos y el grado de paralelismo para los trabajos de entrenamiento de muchos modelos. Para obtener ejemplos, consulte nuestra sección de guía sobre componentes de muchos modelos.
Previsión de series temporales jerárquicas
Es habitual que las series temporales de las aplicaciones empresariales tengan atributos anidados que forman una jerarquía. Los atributos de catálogo de productos y geografía a menudo se anidan, por ejemplo. Considere un ejemplo en el que la jerarquía tiene dos atributos geográficos, el estado y el identificador de almacén, y dos atributos de producto, categoría y SKU:

Esta jerarquía se muestra en el diagrama siguiente:

De manera importante, las cantidades de ventas en el nivel de hoja (SKU) se suman a las cantidades de ventas agregadas en los niveles de estado y ventas totales. Los métodos de previsión jerárquicos conservan estas propiedades de agregación al prever la cantidad vendida en cualquier nivel de la jerarquía. Las previsiones con esta propiedad son coherentes con respecto a la jerarquía.
AutoML admite las siguientes características para series temporales jerárquicas (HTS):
- Entrenamiento en cualquier nivel de la jerarquía. En algunos casos, los datos de nivel de hoja pueden ser ruidosos, pero los agregados pueden ser más accesibles para la previsión.
- Recuperación de las previsiones de punto en cualquier nivel de la jerarquía. Si el nivel de previsión es "inferior" al nivel de entrenamiento, las previsiones del nivel de entrenamiento se desagregan a través de proporciones históricas medias o proporciones de promedios históricos. Las previsiones de nivel de entrenamiento se suman según la estructura de agregación cuando el nivel de previsión está "por encima" del nivel de entrenamiento.
- Recuperación de previsiones cuantiles/probabilísticas para los niveles en el nivel de entrenamiento o "inferiores". Las funcionalidades actuales de modelado admiten la desagregación de las previsiones probabilísticas.
Los componentes HTS de AutoML se basan en muchos modelos, por lo que HTS comparte las propiedades escalables de muchos modelos. Para obtener ejemplos, consulte nuestra sección de guía sobre componentes de HTS.
Entrenamiento de DNN distribuido (versión preliminar)
Importante
Esta característica actualmente está en su versión preliminar pública. Esta versión preliminar se ofrece sin un Acuerdo de Nivel de Servicio y no se recomienda para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas.
Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Los escenarios de datos que presentan grandes cantidades de observaciones históricas o un gran número de series temporales relacionadas pueden beneficiarse de un enfoque de modelo único escalable. En consecuencia, AutoML admite la búsqueda de modelos y el entrenamiento distribuido en modelos de red convolucional temporal (TCN), que son un tipo de red neuronal profunda (DNN) para los datos de serie temporal. Para obtener más información sobre la clase de modelo TCN de AutoML, consulte nuestro artículo sobre DNN.
El entrenamiento de DNN distribuido logra escalabilidad mediante un algoritmo de creación de particiones de datos que respeta los límites de la serie temporal. En el diagrama siguiente se muestra un ejemplo sencillo con dos particiones:
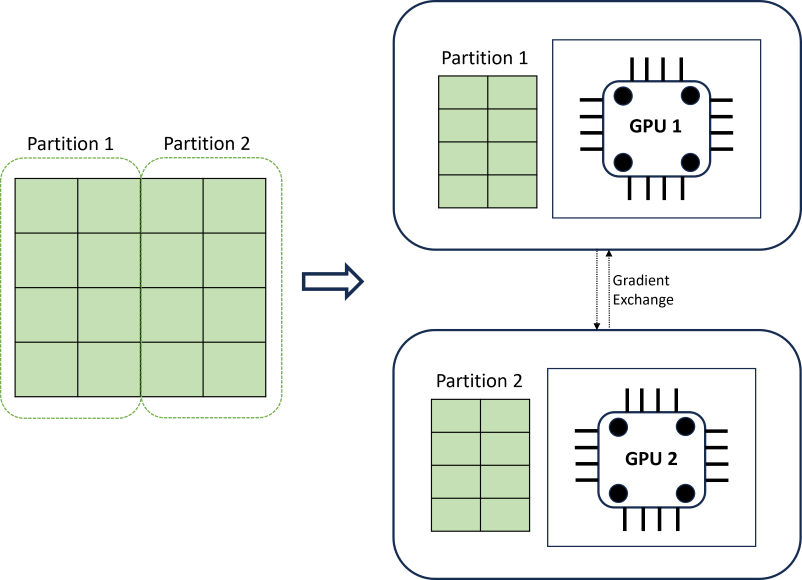
Durante el entrenamiento, los datos DNN cargan en cada carga de proceso solo lo que necesitan para completar una iteración de propagación inversa; el conjunto de datos completo nunca se lee en la memoria. Las particiones se distribuyen aún más entre varios núcleos de proceso (normalmente GPU) posiblemente en varios nodos para acelerar el entrenamiento. El marco Horovod proporciona coordinación entre procesos.
Pasos siguientes
- Más información sobre cómo configurar AutoML para entrenar un modelo de previsión de series temporales.
- Obtenga información sobre cómo AutoML usa el aprendizaje automático para crear modelos de previsión.
- Más información sobre los modelos de aprendizaje profundo para la previsión en AutoML