¿Qué es el diseñador (v1) de Azure Machine Learning?
El diseñador de Azure Machine Learning es una interfaz de tipo arrastrar y colocar que se usa para entrenar e implementar modelos en el estudio de Azure Machine Learning. En este artículo, se describen las tareas que puede realizar en el diseñador.
Importante
El diseñador de Azure Machine Learning admite dos tipos de canalizaciones que usan componentes clásicos precompilados (v1) o personalizados (v2). Los dos tipos de componentes no son compatibles dentro de las canalizaciones y el diseñador v1 no es compatible con la CLI v2 y SDK v2. Este artículo se aplica a las canalizaciones que usan componentes precompilados clásicos (v1).
Los componentes clásicos precompilados (v1) incluyen las tareas típicas de procesamiento de datos y aprendizaje automático, como la regresión y la clasificación. Azure Machine Learning sigue admitiendo los componentes precompilados clásicos existentes, pero no se agregan nuevos componentes creados previamente. Además, la implementación de componentes precompilados clásicos (v1) no admite puntos de conexión en línea administrados (v2).
Los componentes personalizados (v2) permiten encapsular su propio código como componente, lo que permite compartir entre áreas de trabajo y crear sin problemas en las interfaces de Estudio de Azure Machine Learning y las interfaces de la CLI v2 y SDK v2. Es mejor usar componentes personalizados para nuevos proyectos, ya que son compatibles con Azure Machine Learning v2 y siguen recibiendo nuevas actualizaciones. Para saber sobre los componentes personalizados y el Diseñador (v2), consulte Diseñador de Azure Machine Learning (v2).
El siguiente GIF animado muestra cómo puede crear una canalización visualmente en el diseñador arrastrando y quitando recursos y conectándolos.

Para obtener información sobre los componentes disponibles en el diseñador, consulte Referencia de módulo y algoritmo para el diseñador de Azure Machine Learning. Para empezar a trabajar con el diseñador, consulte Tutorial: Diseñador (entrenamiento de un modelo de regresión sin código).
Entrenamiento e implementación de modelos
El diseñador usa el área de trabajo de Azure Machine Learning para organizar recursos compartidos, por ejemplo:
- Canalizaciones
- Datos
- Recursos de proceso
- Modelos registrados
- Trabajos de canalización publicados
- Puntos de conexión en tiempo real
En el diagrama siguiente se muestra cómo puede usar el diseñador para crear un flujo de trabajo de aprendizaje automático de un extremo a otro. Puede entrenar, probar e implementar modelos en la interfaz del diseñador.
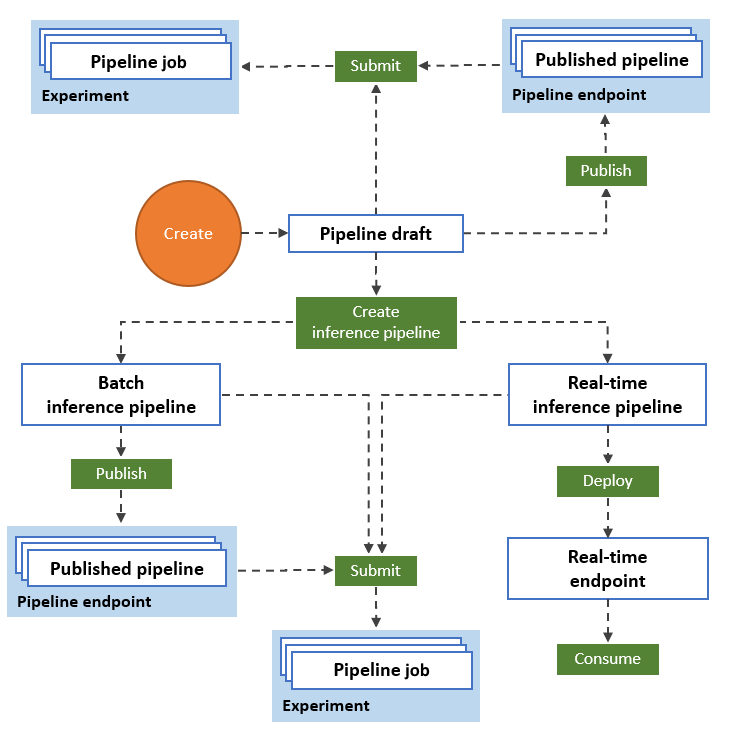
- Arrastre y coloque los recursos y componentes de datos en el lienzo visual del diseñador y conecte los componentes para crear un borrador de canalización.
- Enviar un trabajo de canalización mediante los recursos de proceso del área de trabajo de Azure Machine Learning.
- Convertir las canalizaciones de entrenamiento en canalizaciones de inferencia.
- Publique las canalizaciones en un punto de conexión de canalización de REST para enviar nuevas canalizaciones que se ejecuten con distintos parámetros y recursos de datos.
- Publique una canalización de entrenamiento para reutilizar una sola canalización para el entrenamiento de varios modelos y, al mismo tiempo, cambiar los parámetros y recursos de datos.
- Publique una canalización de inferencia por lotes para hacer predicciones sobre nuevos datos mediante un modelo entrenado previamente.
- Implementar una canalización de inferencia en línea en un punto de conexión en tiempo real para realizar predicciones sobre nuevos datos en tiempo real.
Data
Un recurso de datos de aprendizaje automático permite acceder a los datos y trabajar con ellos fácilmente. En el diseñador se incluyen varios recursos de datos de ejemplo para experimentar con ellos. Puede registrar más recursos de datos a medida que los necesite.
Componentes
Un componente es un algoritmo que se puede ejecutar en los datos. El diseñador tiene varios componentes que van desde funciones de entrada de datos hasta procesos de entrenamiento, puntuación y validación.
Un componente puede tener parámetros que se usan para configurar los algoritmos internos del componente. Al seleccionar un componente en el lienzo, los parámetros y otras configuraciones de este se muestran en el panel Propiedades, a la derecha del lienzo. Puede modificar los parámetros y establecer los recursos de proceso para los componentes individuales de ese panel.
Para obtener más información sobre la biblioteca de algoritmos de aprendizaje automático disponibles, consulte la referencia de algoritmos y componentes. Para obtener ayuda en la elección de un algoritmo, consulte Hoja de características de los algoritmos de Machine Learning para el diseñador de Azure Machine Learning.
Pipelines
Una canalización consta de recursos de datos y componentes de análisis que se conectan. Las canalizaciones le ayudan a reutilizar el trabajo y organizar los proyectos.
Las canalizaciones tienen muchos usos. Puede crear canalizaciones que:
- Entrenen un único modelo.
- Entrenen varios modelos.
- Hagan predicciones en tiempo real o por lotes.
- Solo limpien datos.
Borradores de canalización
A medida que edita una canalización en el diseñador, el progreso se guarda como un borrador de canalización. Puede editar un borrador de canalización en cualquier momento si agrega o quita componentes, configura destinos de proceso, o establece parámetros.
Una canalización válida tiene las siguientes características:
- Los recursos de datos solo pueden conectarse a componentes.
- Los componentes solo pueden conectarse a recursos de datos o a otros componentes.
- Todos los puertos de entrada de los componentes deben tener alguna conexión al flujo de datos.
- Deben establecerse todos los parámetros obligatorios de cada componente.
Cuando esté listo para ejecutar el borrador de la canalización, guarde la canalización y envíe un trabajo de canalización.
Trabajos de canalización
Cada vez que se ejecuta una canalización, la configuración de esta y sus resultados se almacenan en el área de trabajo como un trabajo de canalización. Las ejecuciones de canalización se agrupan en experimentos para organizar el historial de trabajos.
Puede regresar a cualquier trabajo de canalización para inspeccionarlo con fines de solución de problemas o auditoría. Clone una ejecución de canalización para crear un borrador de canalización y editarlo.
Recursos de proceso
Los destinos de proceso están asociados al área de trabajo de Azure Machine Learning en el estudio de Azure Machine Learning. Use recursos de proceso del área de trabajo para ejecutar la canalización y hospedar los modelos implementados como puntos de conexión en línea o como puntos de conexión de canalización (para la inferencia por lotes). Los destinos de proceso admitidos son los siguientes:
| Destino de proceso | Cursos | Implementación |
|---|---|---|
| Proceso de Azure Machine Learning | ✓ | |
| Azure Kubernetes Service (AKS) | ✓ |
Implementar
Para hacer la inferencia en tiempo real, debe implementar una canalización como un punto de conexión en línea. El punto de conexión en línea crea una interfaz entre una aplicación externa y el modelo de puntuación. El punto de conexión se basa en REST, una arquitectura muy usada para proyectos de programación web. Una llamada a un punto de conexión en tiempo real devuelve resultados de predicción a la aplicación externa en línea.
Para realizar una llamada a un punto de conexión en línea, es necesario pasar la clave de API que se creó al implementar el punto de conexión. Los puntos de conexión en línea deben implementarse en un clúster de AKS. Para aprender a implementar el modelo, consulte Tutorial: Implemente un modelo de aprendizaje automático con el diseñador.
Publicar
También puede publicar una canalización en un punto de conexión de canalización. Igual que un punto de conexión en línea, un punto de conexión de canalización permite enviar nuevos trabajos de canalización desde aplicaciones externas mediante llamadas REST. Sin embargo, no se pueden enviar ni recibir datos en tiempo real con un punto de conexión de canalización.
Los puntos de conexión de canalización publicados son flexibles y se pueden usar para entrenar o volver a entrenar modelos, hacer inferencias por lotes o procesar nuevos datos. Puede publicar varias canalizaciones en un único punto de conexión de canalización y especificar la versión de canalización que se va a ejecutar.
Una canalización publicada se ejecuta en los recursos de proceso que se definen en el borrador de canalización de cada componente. El diseñador crea el mismo objeto PublishedPipeline como SDK.
Contenido relacionado
- Conozca los aspectos básicos del análisis predictivo y el aprendizaje automático con Tutorial: Predicción del precio de automóviles con el diseñador.
- Aprenda a modificar los ejemplos existentes del diseñador para adaptarlos a sus necesidades.