Recopilación de datos de modelos en producción
SE APLICA A: Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
En este artículo se muestra cómo recopilar datos de un modelo de Azure Machine Learning implementado en un clúster de Azure Kubernetes Service (AKS). Los datos recopilados se almacenan luego en Azure Blob Storage.
Una vez que la colección está habilitada, los datos que recopile le ayudarán a:
Supervise los desfases de datos en los datos de producción que recopile.
Analice los datos recopilados mediante Power BI o Azure Databricks
Tomar mejores decisiones sobre cuándo volver a entrenar u optimizar el modelo.
Volver a entrenar el modelo con los datos recopilados.
Limitaciones
- La característica de recopilación de datos del modelo solo puede funcionar con la imagen de Ubuntu 18.04.
Importante
A partir del 10/03/2023, la imagen de Ubuntu 18.04 ha quedado en desuso. La compatibilidad con imágenes de Ubuntu 18.04 se quitará a partir de enero de 2023 cuando alcance su EOL el 30 de abril de 2023.
La característica MDC no es compatible con cualquier otra imagen que no sea Ubuntu 18.04, que no está disponible después de que la imagen de Ubuntu 18.04 quede en desuso.
Más información que puede consultar:
Nota:
La característica de recopilación de datos se encuentra actualmente en versión preliminar, no se recomienda ninguna característica en versión preliminar para cargas de trabajo de producción.
¿Qué información se recopila y a dónde va?
Se pueden recopilar los siguientes datos:
Datos de entrada de modelo de los servicios web implementados en un clúster de AKS. El audio de voz, las imágenes y el vídeo no se recopilan.
Predicciones de modelo con datos de entrada de producción.
Nota
La agregación y el cálculo previos en estos datos no forman parte actualmente del servicio de recopilación.
La salida se guarda en el almacenamiento de blobs. Dado que los datos se agregan al almacenamiento de blobs, puede elegir su herramienta favorita para ejecutar el análisis.
La ruta de acceso a los datos de salida en el blob sigue esta sintaxis:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Nota
En las versiones del SDK de Azure Machine Learning para Python anteriores a la versión 0.1.0 A16, el argumento designation se denomina identifier. Si desarrolló el código con una versión anterior, debe actualizarlo en consecuencia.
Prerrequisitos
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Un área de trabajo de Azure Machine Learning, un directorio local que contenga los scripts y tener instalado el SDK de Azure Machine Learning para Python. Para información sobre cómo instalarlos, consulte Configurar un entorno de desarrollo para Azure Machine Learning.
Necesita un modelo de aprendizaje automático entrenado para implementarlo en AKS. Si no tiene uno, consulte el tutorial sobre el entrenamiento de los modelos de clasificación de imágenes.
Necesita un clúster de AKS. Para obtener información sobre cómo crear una e implementarla, consulte Implementación de modelos de Machine Learning en Azure.
Configure el entorno e instale el SDK de supervisión de Azure Machine Learning.
Use una imagen de Docker basada en Ubuntu 18.04, que se incluye con
libssl 1.0.0, la dependencia esencial de modeldatacollector. Puede hacer referencia a imágenes precompiladas.
Habilitación de recolección de datos
Puede habilitar la recopilación de datos independientemente del modelo que implemente mediante Azure Machine Learning u otras herramientas.
Para habilitar la recopilación de datos, debe hacer lo siguiente:
Abrir el archivo de puntuación.
Agregue el código siguiente en la parte superior del archivo:
from azureml.monitoring import ModelDataCollectorDeclare las variables de recopilación de datos en su función
init:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId es un parámetro opcional. No es necesario usarlo si el modelo no lo necesita. El uso de CorrelationId le ayuda en la asignación con otros datos, como LoanNumber o CustomerId.
El parámetro Identifier se usa posteriormente para compilar la estructura de carpetas en el blob. Se puede usar para diferenciar los datos sin procesar de los datos procesados.
Agregue las líneas de código siguientes en la función
run(input_df):data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobLa recopilación de datos no se establece automáticamente en true cuando se implementa un servicio en AKS. Actualice el archivo de configuración, como en el ejemplo siguiente:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)También puede habilitar Application Insights para la supervisión de servicios si modifica esta configuración:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Para crear una nueva imagen e implementar el modelo de Machine Learning, consulte Implementación de modelos de Machine Learning en Azure.
Agregue el paquete PIP "Azure-Monitoring" a las dependencias de CONDA del entorno de servicio web:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Deshabilitar la recopilación de datos
Puede dejar de recopilar datos en cualquier momento. Use código Python para deshabilitar la recopilación de datos.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Validación y análisis de los datos
Puede elegir la herramienta que prefiera para analizar los datos recopilados en el almacenamiento de blobs.
Acceso rápido a los datos del blob
Inicie sesión en el portal de Azure.
Abra el área de trabajo.
Seleccione Storage.

Siga la ruta de acceso a los datos de salida del blob con esta sintaxis:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Análisis de los datos del modelo mediante Power BI
Descargue y abra Power BI Desktop.
Seleccione Obtener datos y, luego, Azure Blob Storage.

Agregue el nombre de la cuenta de almacenamiento y escriba la clave de almacenamiento. Para encontrar esta información, seleccione Configuración>Claves de acceso en el blob.
Seleccione el contenedor datos del modelo y elija Editar.
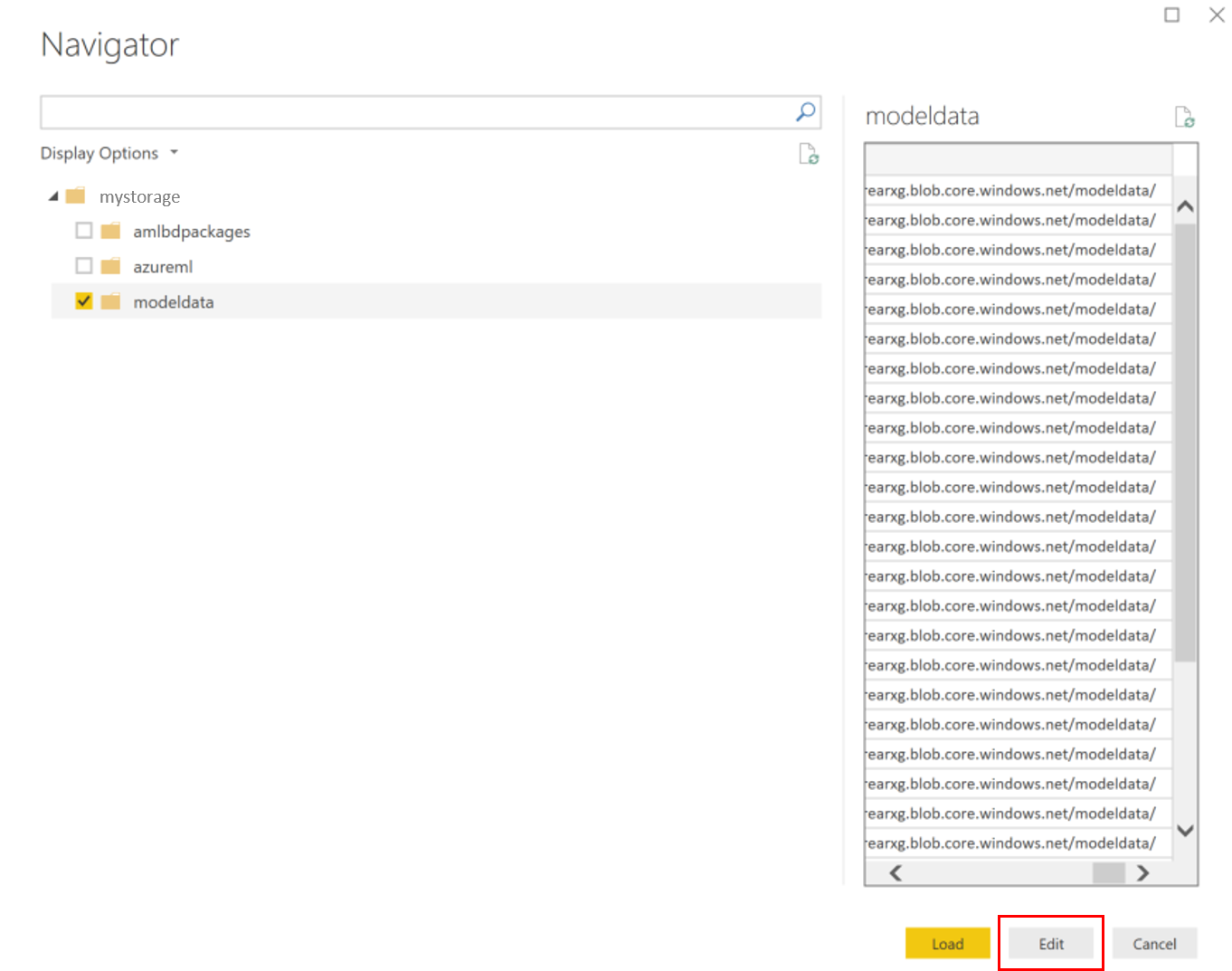
En el editor de consultas, haga clic en la columna Nombre y agregue su cuenta de almacenamiento.
Especifique la ruta de acceso del modelo en el filtro. Si quiere mirar únicamente en los archivos de un determinado año o mes, expanda la ruta de acceso de filtro. Por ejemplo, para mirar solo en los datos de marzo, use esta ruta de filtro:
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
Filtre los datos pertinentes por los valores de Nombre. Si almacenó predicciones y entradas, tendrá que crear una consulta para cada una.
Seleccione las flechas dobles hacia abajo junto al encabezado de columna Contenido para combinar los archivos.

Seleccione Aceptar. Los datos se cargan previamente.

Seleccione Close and Apply (Cerrar y aplicar).
Si ha agregado entradas y predicciones, las tablas se ordenan automáticamente por los valores RequestId.
Comience a crear los informes personalizados con los datos del modelo.




Análisis de datos del modelo mediante Azure Databricks
Cree un área de trabajo de Azure Databricks.
Acceda al área de trabajo de Databricks.
En ese área, seleccione Upload Data (Cargar datos).

Seleccione Create New Table (Crear nueva tabla) y seleccione Other Data Sources>Azure Blob Storage>Create Table in Notebook (Otros orígenes de datos > Azure Blob Storage > Crear tabla en Notebook).

Actualice la ubicación de los datos. Este es un ejemplo:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"
Siga los pasos de la plantilla para ver y analizar los datos.



Pasos siguientes
Detecte el desfase de datos en los datos que ha recopilado.