Ajuste de hiperparámetros de un modelo (v2)
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Automatice el ajuste eficaz de hiperparámetros con el SDK v2 y la CLI v2 de Azure Machine Learning mediante el tipo SweepJob.
- Definir el espacio de búsqueda de parámetros para la versión de prueba
- Especificar el algoritmo de muestreo para el trabajo de barrido
- Especificar el objetivo que se va a optimizar
- Especificar la directiva de terminación anticipada para trabajos de bajo rendimiento
- Definir límites del trabajo de barrido
- Iniciar un experimento con la configuración definida
- Visualizar los trabajos de entrenamiento
- Seleccionar la mejor configuración para un modelo
¿Qué es el ajuste de hiperparámetros?
Los hiperparámetros son parámetros ajustables que permiten controlar el proceso de entrenamiento de un modelo. Por ejemplo, con redes neuronales, puede decidir el número de capas ocultas y el número de nodos de cada capa. El rendimiento de un modelo depende en gran medida de los hiperparámetros.
El ajuste de hiperparámetros, también denominado optimización de hiperparámetros es el proceso de encontrar la configuración de hiperparámetros que produzca el mejor rendimiento. Normalmente, el proceso es manual y costoso desde el punto de vista computacional.
Azure Machine Learning permite automatizar el ajuste de hiperparámetros y ejecutar experimentos en paralelo para optimizar los hiperparámetros de forma eficaz.
Definición del espacio de búsqueda
Ajuste automáticamente los hiperparámetros explorando el rango de valores definidos para cada hiperparámetro.
Los hiperparámetros pueden ser discretos o continuos, y tienen una distribución de valores que se describe mediante una expresión de parámetro.
Hiperparámetros discretos
Los hiperparámetros discretos se especifican con un objeto Choice entre valores discretos. Choice puede ser:
- uno o más valores separados por comas;
- un objeto
range; - cualquier objeto
listarbitrario.
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
En este caso, batch_size toma uno de los valores [16, 32, 64, 128] y number_of_hidden_layers, uno de los valores [1, 2, 3, 4].
También se pueden especificar los siguientes hiperparámetros discretos avanzados mediante una distribución:
QUniform(min_value, max_value, q): devuelve un valor como round(Uniform(min_value, max_value) / q) * qQLogUniform(min_value, max_value, q): devuelve un valor como round(exp(Uniform(min_value, max_value)) / q) * qQNormal(mu, sigma, q): devuelve un valor como round(Normal(mu, sigma) / q) * qQLogNormal(mu, sigma, q): devuelve un valor como round(exp(Normal(mu, sigma)) / q) * q
Hiperparámetros continuos
Los hiperparámetros continuos se especifican como una distribución a través de un rango continuo de valores:
Uniform(min_value, max_value): devuelve un valor distribuido uniformemente entre min_value y max_valueLogUniform(min_value, max_value): devuelve un valor que se extrae según exp(Uniform(min_value, max_value)) de forma que el logaritmo del valor devuelto se distribuya uniformementeNormal(mu, sigma): devuelve un valor real que se distribuye normalmente con media mu y desviación estándar sigma.LogNormal(mu, sigma): devuelve un valor extraído según exp(Normal(mu, sigma)) de forma que el logaritmo del valor devuelto se distribuya normalmente.
El siguiente es un ejemplo de definición de espacio de parámetros:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Este código define un espacio de búsqueda con dos parámetros: learning_rate y keep_probability. learning_rate tiene una distribución normal con un valor medio de 10 y una desviación estándar de 3. keep_probability tiene una distribución uniforme con un valor mínimo de 0,05 y un valor máximo de 0,1.
Para la CLI, puede usar el esquema YAML del trabajo de barrido para definir el espacio de búsqueda en YAML:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Muestreo del espacio de hiperparámetros
Especifique el método de muestreo de parámetros que se usará en el espacio de hiperparámetros. Azure Machine Learning es compatible con los siguientes métodos:
- Muestreo aleatorio
- Muestreo de cuadrícula
- Muestreo bayesiano
Muestreo aleatorio
El muestreo aleatorio admite hiperparámetros discretos y continuos. Admite la terminación anticipada de los trabajos de bajo rendimiento. Algunos usuarios realizan una búsqueda inicial con muestreo aleatorio y luego restringen el espacio de búsqueda para mejorar los resultados.
En el muestreo aleatorio, los valores de hiperparámetro se seleccionan aleatoriamente del espacio de búsqueda definido. Después de crear el trabajo de comando, puede usar el parámetro de barrido para definir el algoritmo de muestreo.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol es un tipo de muestreo aleatorio admitido por los tipos de trabajo de barrido. Puede usar Sobol para reproducir los resultados mediante inicialización y cubrir la distribución del espacio de búsqueda de forma más uniforme.
Para usar Sobol, use la clase RandomParameterSampling para agregar la inicialización y la regla, como se muestra en el ejemplo siguiente.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Muestreo de cuadrícula
El muestreo de cuadrícula admite hiperparámetros discretos. Use el muestreo de cuadrícula si su presupuesto le permite buscar en el espacio de búsqueda de manera exhaustiva. Admite la terminación anticipada de los trabajos de bajo rendimiento.
El muestreo de cuadrícula realiza una búsqueda de cuadrícula sencilla sobre todos los valores posibles. El muestreo de cuadrícula solo se puede usar con hiperparámetros de choice. Por ejemplo, el siguiente espacio tiene seis muestras:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Muestreo bayesiano
El muestreo bayesiano se basa en el algoritmo de optimización bayesiano. Escoge las muestras en función de cómo lo hicieron las anteriores, para que las nuevas muestras mejoren la métrica principal.
Se recomienda el muestreo bayesiano si tiene suficiente presupuesto para explorar el espacio de hiperparámetros. Para obtener los mejores resultados, se recomienda que el número máximo de trabajos sea mayor o igual que 20 veces el número de hiperparámetros que se está ajustando.
El número de trabajos simultáneos afecta a la eficacia del proceso de ajuste. Un menor número de trabajos simultáneos puede provocar una mejor convergencia de muestreo, dado que el menor grado de paralelismo aumenta el número de trabajos que se benefician de los trabajos completados previamente.
El muestreo bayesiano solo admite las distribuciones choice, uniform y quniform en el espacio de búsqueda.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Especificación del objetivo del barrido
Defina el objetivo del trabajo de barrido especificando la métrica principal y el objetivo que quiere que el ajuste de hiperparámetros optimice. En cada trabajo de entrenamiento se evalúa la métrica principal. La directiva de terminación anticipada usa la métrica principal para identificar los trabajos de bajo rendimiento.
primary_metric: el nombre de la métrica principal debe coincidir exactamente con el nombre de la métrica registrada por el script de entrenamiento.goal: puede serMaximizeoMinimizey determina si la métrica principal se maximizará o minimizará al evaluar los trabajos.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Esta muestra maximiza la "precisión".
Registrar métricas para el ajuste de hiperparámetros
El script de entrenamiento del modelo debe registrar la métrica principal durante el entrenamiento del modelo usando el mismo nombre de métrica correspondiente para que SweepJob pueda acceder a ella con el fin de realizar el ajuste de hiperparámetros.
Registre la métrica principal del script de entrenamiento mediante el siguiente fragmento de código de ejemplo:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
El script de entrenamiento calcula el parámetro val_accuracy y lo registra como la métrica principal de "precisión". Cada vez que se registra la métrica, el servicio de ajuste de hiperparámetros la recibe. Será usted quien tenga que determinar la frecuencia de los informes.
Para más información sobre cómo registrar valores en trabajos de entrenamiento, consulte Habilitación del registro en trabajos de entrenamiento de Azure Machine Learning.
Especificación de una directiva de terminación anticipada
Termine de forma automática los trabajos con un bajo rendimiento con ayuda de una directiva de terminación anticipada. La terminación anticipada mejora la eficacia computacional.
Puede configurar los siguientes parámetros que controlan cuándo se aplica una directiva:
evaluation_interval: la frecuencia con que se aplica la directiva. Cada vez que el script de entrenamiento registra la métrica principal se considera un intervalo. Por lo tanto, un parámetroevaluation_intervalde 1 aplicará la directiva cada vez que el script de entrenamiento informe de la métrica principal. Un parámetroevaluation_intervalde 2 aplicará la directiva las demás veces. Si no se especifica,evaluation_intervalse establece en 0 de forma predeterminada.delay_evaluation: retrasa la primera evaluación de la directiva un número especificado de intervalos. Se trata de un parámetro opcional que permite que todas las configuraciones se ejecuten durante un número mínimo de intervalos, lo que evita la terminación anticipada de trabajos de entrenamiento. Si se especifica, la directiva aplica cada múltiplo de evaluation_interval que sea mayor o igual que delay_evaluation. Si no se especifica,delay_evaluationse establece en 0 de forma predeterminada.
Azure Machine Learning admite las siguientes directivas de terminación anticipada:
- Directiva de bandidos
- Directiva de mediana de detención
- Directiva de selección de truncamiento
- Sin directiva de terminación
Directiva de bandidos
La directiva de bandidos es una directiva de terminación basada en el factor de demora o la cantidad de demora y el intervalo de evaluación. La directiva de bandidos finaliza un trabajo cuando la métrica principal no se encuentra dentro del factor de demora o la cantidad de demora especificados del mejor trabajo.
Especifique los siguientes parámetros de configuración:
slack_factoroslack_amount: la demora permitida con respecto al trabajo de entrenamiento con el mejor rendimiento.slack_factorespecifica la demora permitida como una relación.slack_amountespecifica la demora permitida como una cantidad absoluta, en lugar de una relación.Por ejemplo, imagine que se aplica una directiva de bandidos en el intervalo 10. Suponga que el trabajo con el mejor rendimiento en el intervalo 10 informa de una métrica principal de 0,8 con el objetivo de maximizarla. Si la directiva se especifica con un elemento
slack_factorde 0,2, se finalizarán los trabajos de entrenamiento cuya mejor métrica en el intervalo 10 sea inferior a 0,66 (0,8/(1 +slack_factor)).evaluation_interval: la frecuencia con que se aplica la directiva (opcional)delay_evaluation: retrasa la primera evaluación de la directiva un número especificado de intervalos (opcional)
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
En este ejemplo, se aplica la directiva de terminación anticipada en cada intervalo cuando se notifican las métricas, comenzando en el intervalo de evaluación 5. Cualquier trabajo cuya mejor métrica sea inferior a (1/(1+0,1), o al 91 % de los trabajos con el mejor rendimiento, se finalizará.
Directiva de mediana de detención
La mediana de detención es una directiva de terminación anticipada basada en las medias móviles de las métricas principales notificadas por los trabajos. Esta directiva calcula las medias móviles en todos los trabajos de entrenamiento y detiene los trabajos cuyo valor de métrica principal sea peor que la mediana de los promedios.
Esta directiva toma los parámetros de configuración siguientes:
evaluation_interval: la frecuencia con que se aplica la directiva (parámetro opcional).delay_evaluation: retrasa la primera evaluación de directiva un número especificado de intervalos (parámetro opcional).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
En este ejemplo, se aplica la directiva de terminación anticipada en cada intervalo, comenzando en el intervalo de evaluación 5. Un trabajo se detiene en el intervalo 5 si su mejor métrica principal es peor que la mediana de las medias móviles durante los intervalos en una relación de 1 a 5 en todos los trabajos de entrenamiento.
Directiva de selección de truncamiento
La selección de truncamiento cancela un porcentaje de trabajos con el rendimiento más bajo en cada intervalo de evaluación. Los trabajos se comparan mediante la métrica principal.
Esta directiva toma los parámetros de configuración siguientes:
truncation_percentage: el porcentaje de trabajos con rendimiento más bajo que se terminarán en cada intervalo de evaluación. Un valor entero comprendido entre 1 y 99.evaluation_interval: la frecuencia con que se aplica la directiva (opcional)delay_evaluation: retrasa la primera evaluación de la directiva un número especificado de intervalos (opcional)exclude_finished_jobs: especifica si se excluirán los trabajos finalizados al aplicar la directiva
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
En este ejemplo, se aplica la directiva de terminación anticipada en cada intervalo, comenzando en el intervalo de evaluación 5. Un trabajo termina en el intervalo 5 si su rendimiento en este intervalo se encuentra en el 20 % del rendimiento más bajo de todos los trabajos del intervalo 5 y excluirá los trabajos finalizados al aplicar la directiva.
Sin directiva de terminación (predeterminado)
Si no se especifica ninguna directiva, el servicio de ajuste de hiperparámetros permite que todas las ejecuciones de entrenamiento se ejecuten hasta completarse.
sweep_job.early_termination = None
Selección de una directiva de terminación anticipada
- Si está buscando una directiva conservadora que proporcione ahorros sin finalizar trabajos prometedores, puede usar una directiva de mediana de detención con
evaluation_intervalen el valor 1 ydelay_evaluationen el valor 5. Se trata de una configuración conservadora que puede proporcionar unos ahorros de entre un 25 % y un 35 % sin pérdidas de la métrica principal (según nuestros datos de evaluación). - Si busca un ahorro más agresivo, use la directiva de bandidos con una directiva de selección de truncamiento o demora permisible más estricta con un porcentaje de truncamiento mayor.
Establecimiento de límites para el trabajo de barrido
Controle el presupuesto de recursos estableciendo límites para el trabajo de barrido.
max_total_trials: número máximo de trabajos de prueba. Debe ser un entero entre 1 y 1000.max_concurrent_trials: número máximo de trabajos que se pueden ejecutar simultáneamente (opcional). Si no se especifica, max_total_trials es el número de trabajos que se inician en paralelo. Si se especifica, el tiempo de espera debe ser un entero comprendido entre 1 y 1000.timeout: el tiempo máximo en segundos durante el que se puede ejecutar todo el trabajo de barrido. Una vez alcanzado este límite, el sistema cancela el trabajo de barrido, incluidas todas sus pruebas.trial_timeout: el tiempo máximo en segundos durante el que se puede ejecutar cada trabajo de prueba. Una vez alcanzado este límite, el sistema cancela la prueba.
Nota:
Si se especifican max_total_trials y timeout, el experimento de ajuste de hiperparámetros finaliza cuando se alcanza el primero de estos dos umbrales.
Nota:
El número de trabajos simultáneos viene determinado por los recursos disponibles en el destino de proceso especificado. Asegúrese de que el destino de proceso tenga los recursos disponibles para la simultaneidad deseada.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Este código configura el experimento de ajuste de hiperparámetros para usar un máximo total de 20 trabajos de prueba, con la ejecución de cuatro trabajos de prueba a la vez y un tiempo de espera de 1200 segundos para todo el trabajo de barrido.
Configuración del experimento de ajuste de hiperparámetros
Para configurar el experimento de ajuste de hiperparámetros, proporcione lo siguiente:
- El espacio de búsqueda de hiperparámetros definido
- Algoritmos de muestreo
- Una directiva de terminación anticipada
- Su objetivo
- Límites de recursos
- CommandJob o CommandComponent
- SweepJob
SweepJob puede ejecutar un barrido de hiperparámetros en el comando o el componente de comando.
Nota
El destino de proceso usado en sweep_job debe tener suficientes recursos para satisfacer el nivel de simultaneidad. Para más información sobre los destinos de proceso, consulte Destinos de proceso.
Configure el experimento de ajuste de hiperparámetros:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
Se llama a command_job como una función para que podamos aplicar las expresiones de parámetro a las entradas de barrido. A continuación, la función sweep se configura con trial, sampling-algorithm, objective, limits y compute. El fragmento de código anterior se toma del cuaderno de ejemplo Ejecución del barrido de hiperparámetros en un comando o CommandComponent. En este ejemplo, se optimizan los parámetros learning_rate y boosting. La detención temprana de los trabajos se determina mediante MedianStoppingPolicy, que detiene un trabajo cuyo valor de métrica principal sea peor que la mediana de los promedios en todos los trabajos de entrenamiento (vea la Referencia de clase MedianStoppingPolicy).
Para ver cómo se reciben, analizan y pasan los valores de parámetros al script de entrenamiento para ajustarlos, consulte este ejemplo de código.
Importante
Cada trabajo de barrido de hiperparámetros reinicia el entrenamiento desde cero, lo que incluye volver a generar el modelo y todos los cargadores de datos. Puede minimizar este costo mediante el uso de una canalización de Azure Machine Learning o un proceso manual para preparar los datos lo máximo posible antes de los trabajos de entrenamiento.
Envío del experimento de ajuste de hiperparámetros
Tras definir la configuración de ajuste de hiperparámetros, envíe el trabajo:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Visualización de los trabajos de ajuste de hiperparámetros
Puede visualizar todos los trabajos de ajuste de hiperparámetros en Estudio de Azure Machine Learning. Para más información sobre cómo ver un experimento en el portal, consulte Visualización de registros de trabajo en el estudio.
Gráfico de métricas: esta visualización realiza un seguimiento de las métricas registradas para cada trabajo secundario de Hyperdrive durante el ajuste de hiperparámetros. Cada línea representa un trabajo secundario y cada punto mide el valor de la métrica principal en esa iteración del tiempo de ejecución.
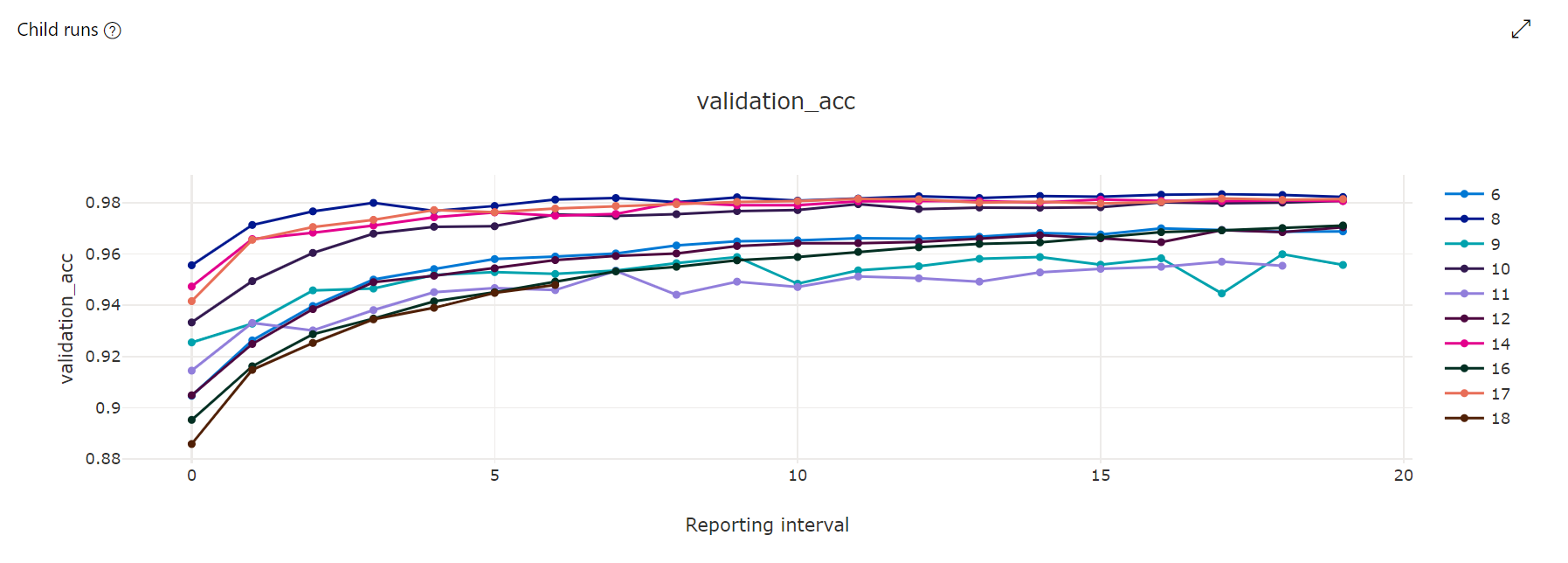
Gráfico de coordenadas paralelas: esta visualización muestra la correlación entre el rendimiento de la métrica principal y los valores de los hiperparámetros individuales. El gráfico es interactivo mediante el movimiento de ejes (seleccionar y arrastrar por la etiqueta del eje) y resaltando los valores en un solo eje (seleccione y arrastre verticalmente a lo largo de un solo eje para resaltar un intervalo de valores deseados). El gráfico de coordenadas paralelas incluye un eje en la parte superior derecha del gráfico que traza el mejor valor de métrica correspondiente a los hiperparámetros establecidos para esa instancia de trabajo. Este eje se proporciona para proyectar la leyenda de degradado del gráfico en los datos de forma más legible.
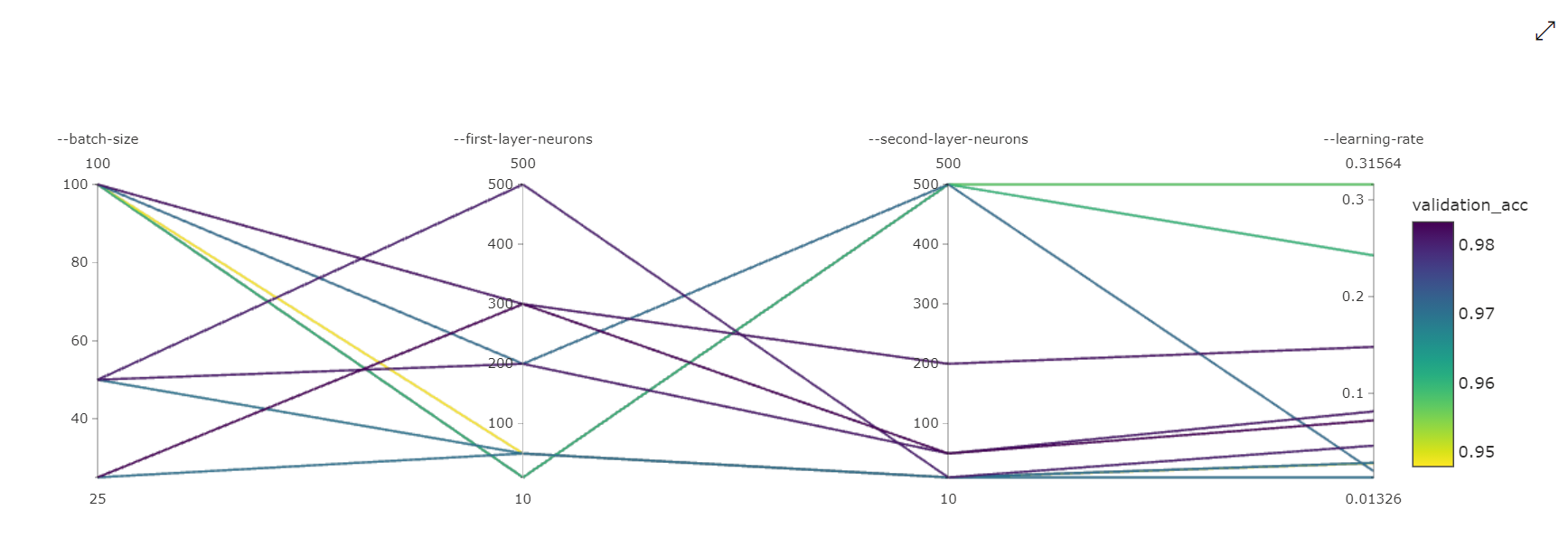
Gráfico de dispersión bidimensional: esta visualización muestra la correlación entre dos hiperparámetros individuales, junto con el valor de la métrica principal asociada.
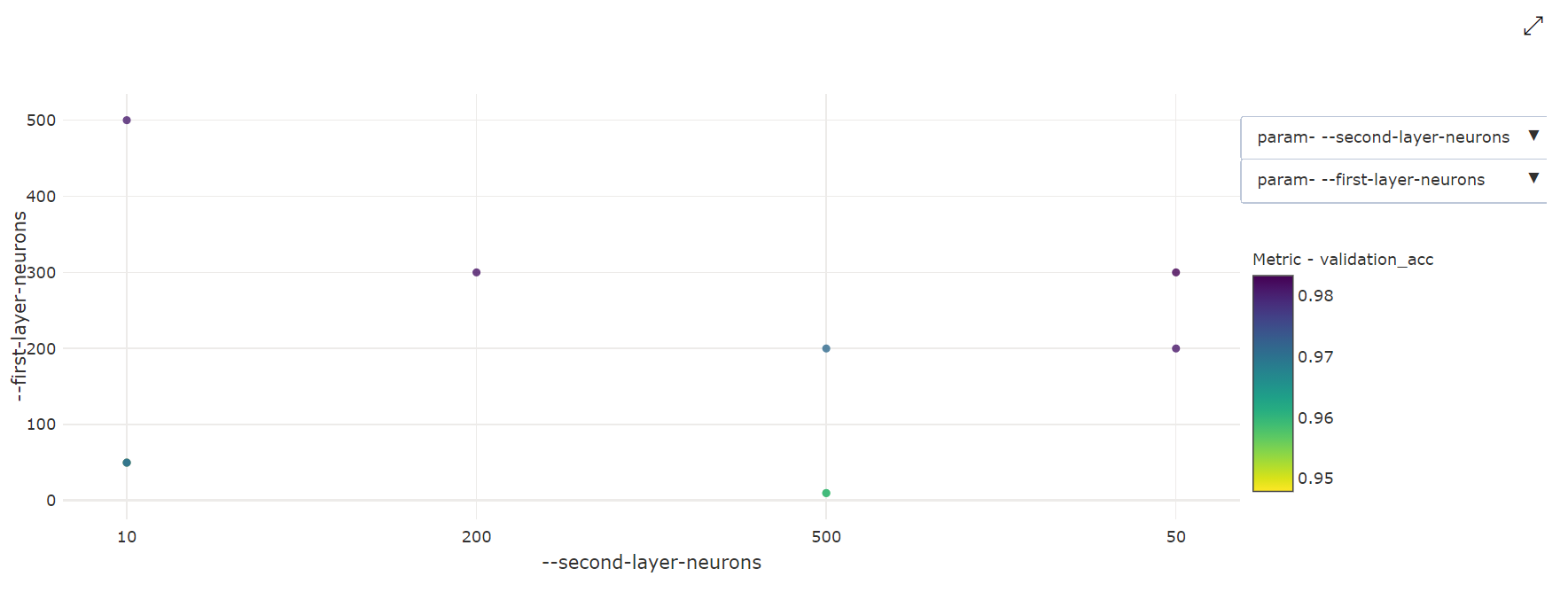
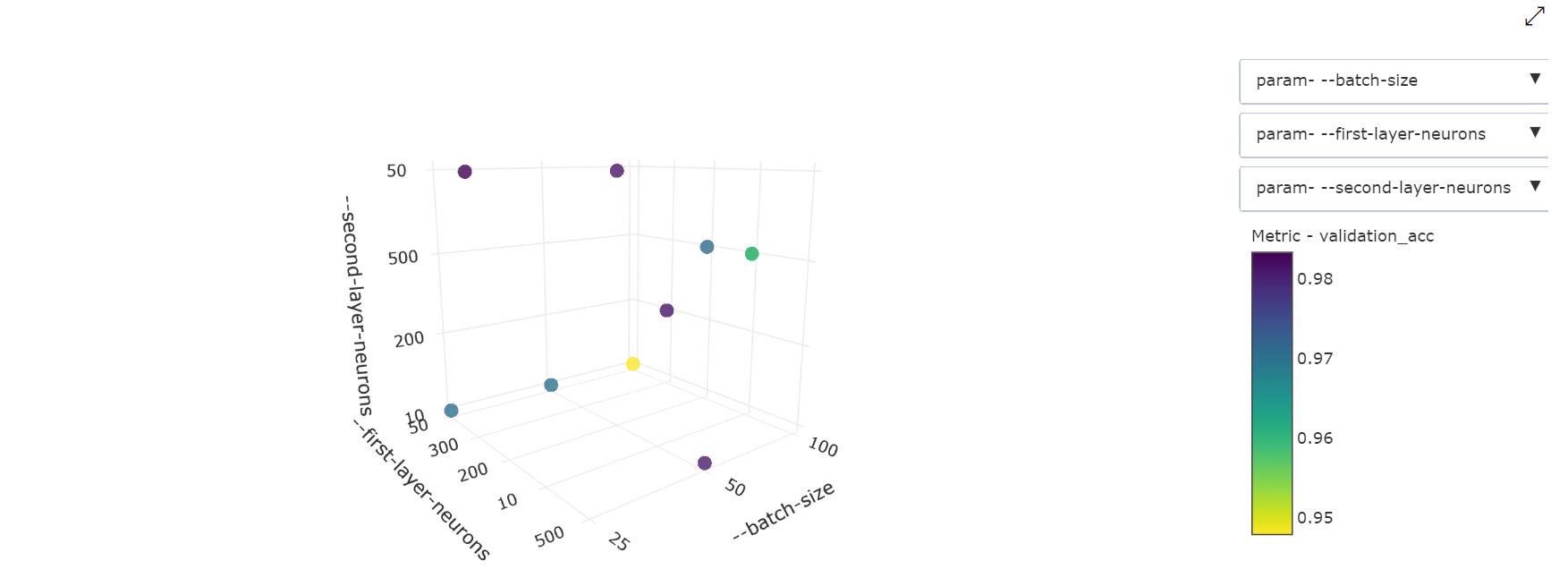
Gráfico de dispersión tridimensional: esta visualización es la misma que en la de dos dimensiones, pero permite tres dimensiones de hiperparámetros de correlación con el valor de la métrica principal. También puede seleccionar y arrastrar para volver a orientar el gráfico para ver diferentes correlaciones en el espacio 3D.
Búsqueda del mejor trabajo de prueba
Una vez completados todos los trabajos de ajuste de hiperparámetros, recupere las mejores salidas de prueba:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
Puede usar la CLI para descargar todas las salidas predeterminadas y con nombre del mejor trabajo de prueba y los registros del trabajo de barrido.
az ml job download --name <sweep-job> --all
Opcionalmente, solo para descargar la mejor salida de prueba
az ml job download --name <sweep-job> --output-name model
Referencias
Pasos siguientes
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de