Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Managed Instance for Apache Cassandra proporciona operaciones de implementación y escalado automatizadas para los centros de datos administrados de código abierto de Apache Cassandra. Esta característica acelera los escenarios híbridos y ayuda a reducir el mantenimiento continuo.
En este inicio rápido se muestra cómo usar Azure Portal para crear un clúster de Apache Spark totalmente administrado dentro de la red virtual de Azure del clúster de Azure Managed Instance para Apache Cassandra. Crea el clúster de Spark en Azure Databricks. Posteriormente, puede crear o adjuntar cuadernos al clúster, leer datos de diferentes orígenes de datos y analizar la información.
También puede obtener más información con instrucciones detalladas sobre implementación de Azure Databricks en la red virtual de Azure (inyección de red virtual).
Requisitos previos
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Crear un clúster de Azure Databricks
Siga estos pasos para crear un clúster de Azure Databricks en una red virtual que tenga La instancia administrada de Azure para Apache Cassandra:
Inicie sesión en Azure Portal.
En el panel izquierdo, busque Grupos de recursos. Vaya al grupo de recursos que contiene la red virtual donde se implementa la instancia administrada.
Abra el recurso de red virtual y anote el espacio de direcciones.
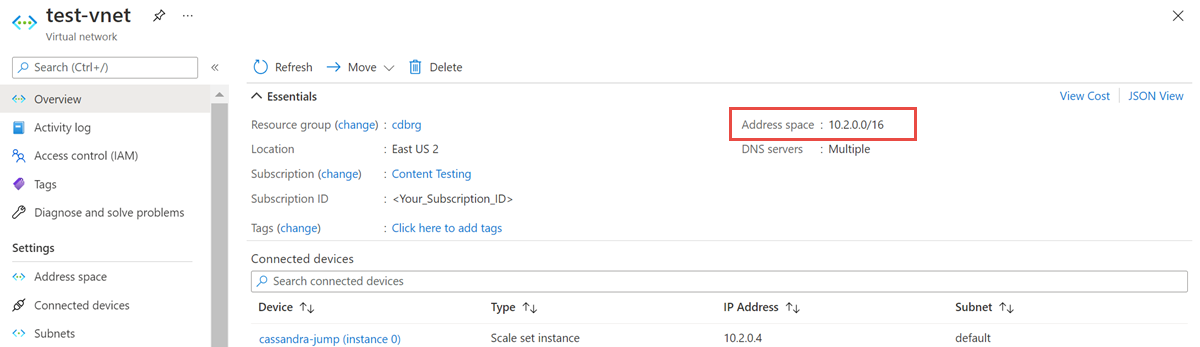
En el grupo de recursos, seleccione Agregar y busque Azure Databricks en el campo de búsqueda.
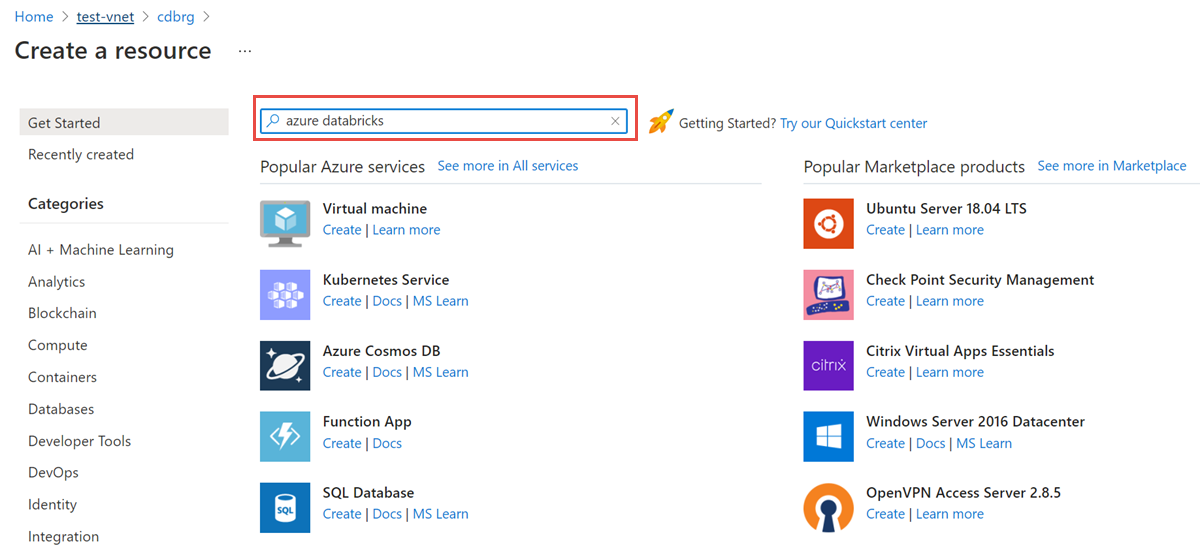
Seleccione Crear para crear una cuenta de Azure Databricks.
Escriba los siguientes valores:
- Nombre del área de trabajo: proporcione un nombre para el área de trabajo de Azure Databricks.
- Región: asegúrese de seleccionar la misma región que la red virtual.
- Plan de tarifa: seleccione Estándar, Premium o Evaluación. Para más información sobre estos niveles, consulte la página de precios de Azure Databricks.
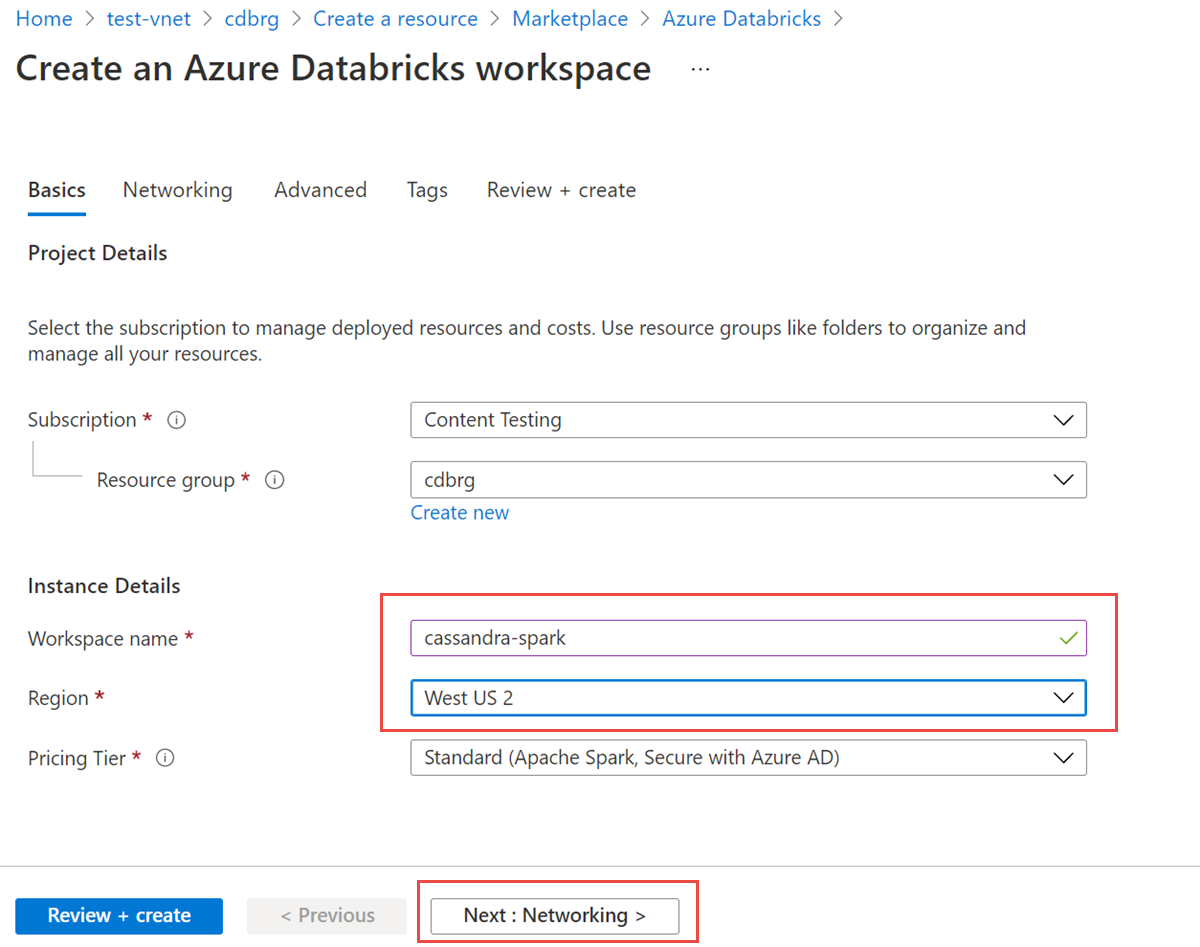
Seleccione la pestaña Redes y escriba los detalles siguientes:
- Implementación del área de trabajo de Azure Databricks en la red virtual (VNet): seleccione Sí.
- Red virtual: en la lista desplegable, elija la red virtual donde existe la instancia administrada.
- Nombre de subred pública: escriba un nombre para la subred pública.
- Rango CIDR de subred pública: escriba un intervalo IP para la subred pública.
- Nombre de subred privada: escriba un nombre para la subred privada.
- Intervalo CIDR de subred privada: escriba un intervalo IP para la subred privada.
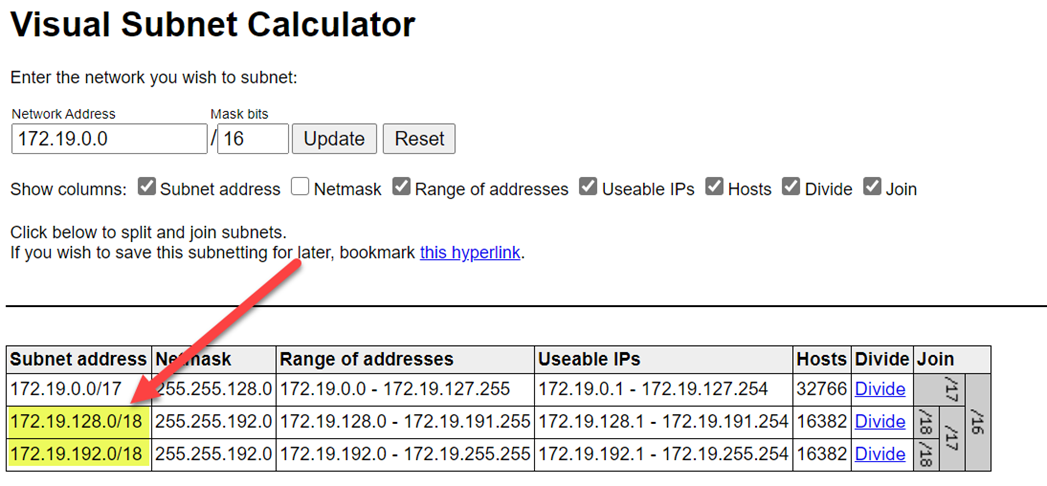
Para evitar conflictos de intervalos, asegúrese de seleccionar intervalos superiores. Si es necesario, use una calculadora de subred visual para dividir los intervalos.
En la captura de pantalla siguiente se muestran detalles de ejemplo en el panel de redes.
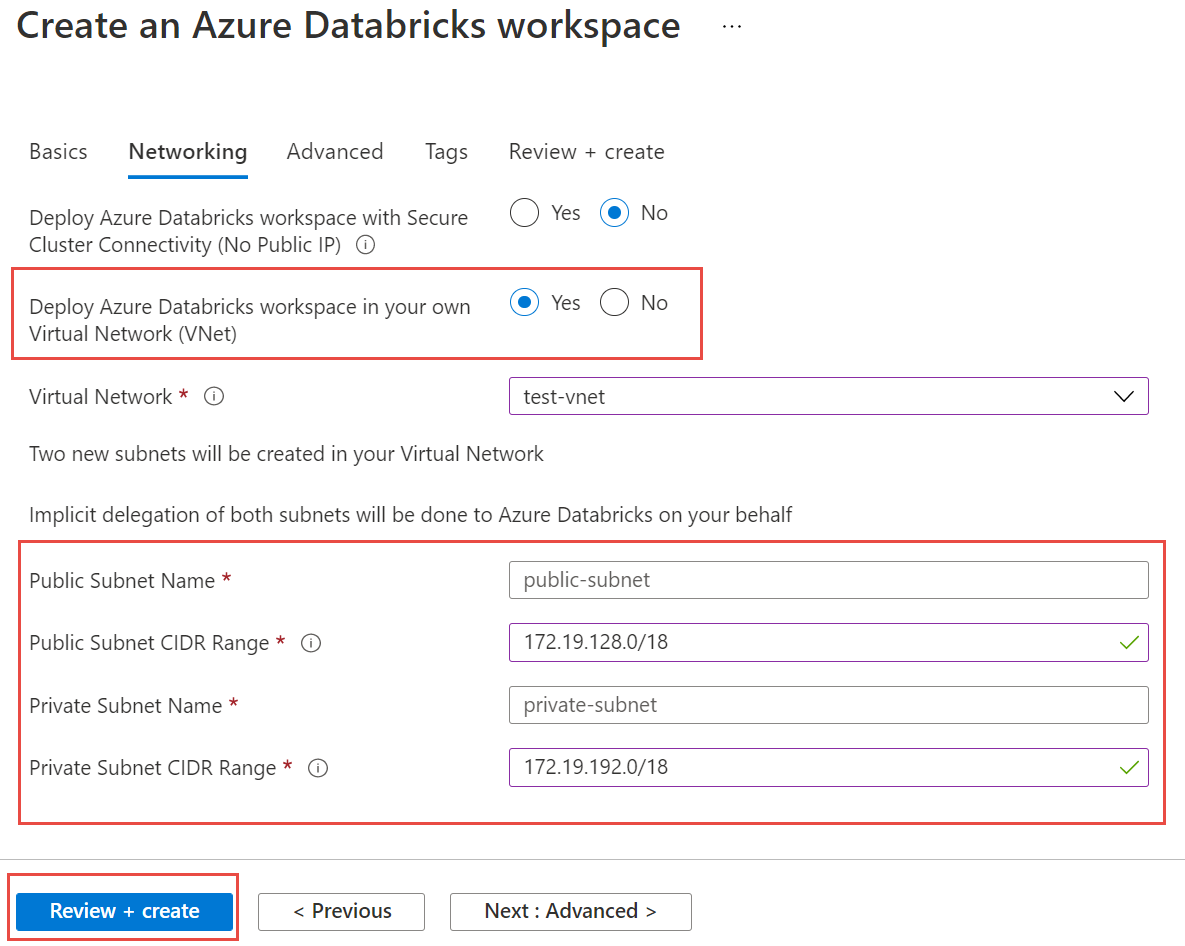
Seleccione Revisar y crear y, a continuación, seleccione Crear para implementar el área de trabajo.
Abre el área de trabajo una vez que se haya creado el área de trabajo.
Se le redirigirá al portal de Azure Databricks. En el portal, seleccione Nuevo clúster.
En el panel Nuevo clúster , acepte valores predeterminados para todos los campos distintos de los campos siguientes:
- Nombre del clúster: escriba un nombre para el clúster.
- Versión de Databricks Runtime: se recomienda seleccionar la versión 7.5 o posterior del entorno de ejecución de Azure Databricks para la compatibilidad con Spark 3.x.

Expanda Opciones avanzadas y agregue la siguiente configuración. Asegúrese de reemplazar las direcciones IP y las credenciales del nodo.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueAgregue la biblioteca de conectores de Cassandra de Apache Spark a su clúster para conectarse a los puntos de conexión nativos y de Cassandra de Azure Cosmos DB. En el clúster, seleccione Bibliotecas>instalar nueva>maven y, a continuación, agregue
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0en el campo Coordenadas de Maven.
Seleccione Instalar.
Limpieza de recursos
Si no va a seguir usando este clúster de instancia administrada, siga estos pasos para eliminarlo:
- En el menú de la izquierda de Azure Portal, seleccione Grupos de recursos.
- En la lista, seleccione el grupo de recursos que creó para este inicio rápido.
- En el panel Información general del grupo de recursos, seleccione Eliminar grupo de recursos.
- En el panel siguiente, escriba el nombre del grupo de recursos que desea eliminar y, a continuación, seleccione Eliminar.
Paso siguiente
En este inicio rápido, ha aprendido a crear un clúster de Apache Spark totalmente administrado dentro de la red virtual del clúster de Azure Managed Instance para Apache Cassandra. A continuación, aprenda a administrar los recursos del clúster y del centro de datos.