Configuración de la replicación de datos internos de Azure Database for MySQL
SE APLICA A:  Azure Database for MySQL: servidor único
Azure Database for MySQL: servidor único
Importante
El servidor único de Azure Database for MySQL está en proceso de retirada. Es muy recomendable actualizar al servidor flexible de Azure Database for MySQL. Para obtener más información sobre la migración al servidor flexible de Azure Database for MySQL, consulte ¿Qué sucede con el servidor único de Azure Database for MySQL?
En este artículo se describe cómo configurar la Replicación de datos de entrada en Azure Database for MySQL mediante la configuración de los servidores de origen y de réplica. En este artículo se asume que tiene alguna experiencia previa con servidores y bases de datos MySQL.
Nota
Este artículo contiene referencias al término esclavo, un término que Microsoft ya no usa. Cuando se elimine el término del software, se eliminará también de este artículo.
Para crear una réplica en el servicio Azure Database for MySQL, la replicación de datos de entrada sincroniza los datos que proceden de un servidor MySQL de origen local con máquinas virtuales (VM) o servicios de base de datos en la nube. La replicación de datos de entrada se basa en la replicación según la posición del archivo de registro binario (binlog), que es nativa de MySQL. Para obtener más información acerca de la replicación de binlog, consulte la Introducción a la replicación de binlog de MySQL.
Revise las limitaciones y los requisitos de la replicación de datos de entrada antes de seguir los pasos de este artículo.
Creación de una instancia de servidor único de Azure Database for MySQL para usarla como réplica
Cree una nueva instancia de servidor único de Azure Database for MySQL (por ejemplo,
replica.mysql.database.azure.com). Consulte Creación de un servidor de Azure Database for MySQL mediante Azure Portal para la creación del servidor. Este servidor es el servidor de "réplica" para la replicación de datos de entrada.Importante
El servidor de Azure Database for MySQL debe crearse en los planes de tarifa De uso general u Optimizada para memoria, ya que la replicación de datos de entrada solo se admite en estos niveles. GTID se admite en las versiones 5.7 y 8.0, y solo en los servidores que admiten almacenamiento de hasta 16 TB (almacenamiento de uso general v2).
Cree las mismas cuentas de usuario y los privilegios correspondientes.
Las cuentas de usuario no se replican desde el servidor de origen al servidor de réplica. Si planea proporcionar a los usuarios acceso al servidor de réplica, debe crear manualmente todas las cuentas y privilegios correspondientes en este servidor recién creado de Azure Database for MySQL.
Agregue la dirección IP del servidor de origen a las reglas de firewall de la réplica.
Actualice las reglas de firewall mediante Azure Portal o la CLI de Azure.
Opcional: si desea usar la replicación basada en GTID desde el servidor de origen al servidor de réplica de Azure Database for MySQL, deberá habilitar los siguientes parámetros de servidor en el servidor de Azure Database for MySQL como se muestra en la imagen del portal siguiente:
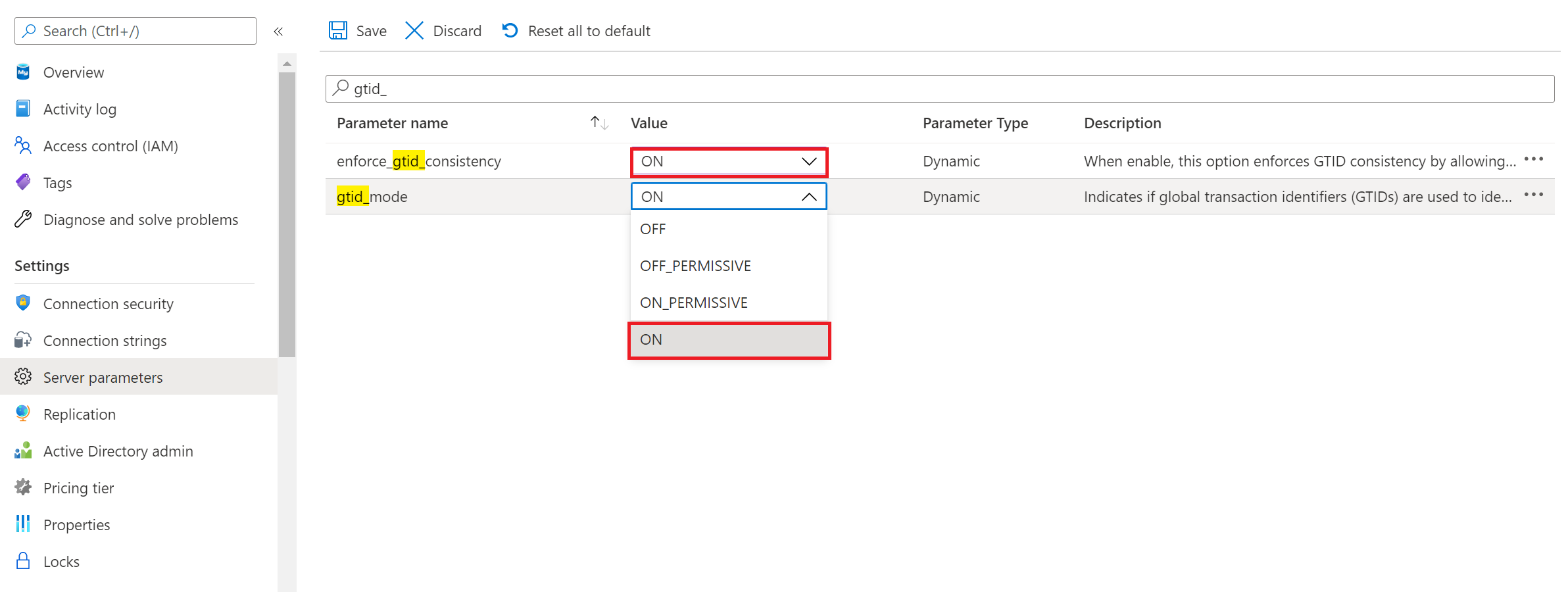
Configuración del servidor MySQL
En los siguientes pasos se prepara y configura el servidor MySQL en el entorno local, en una máquina virtual o en un servicio de base de datos hospedado por otros proveedores de nube para Data-in Replication. Este servidor es el "origen" de la replicación de datos de entrada.
Revise los requisitos del servidor de origen antes de continuar.
Asegúrese de que el servidor de origen permite el tráfico entrante y saliente en el puerto 3306 y de que tiene una dirección IP pública, el DNS es accesible públicamente o tiene un nombre de dominio completo (FQDN).
Pruebe la conectividad con el servidor de origen; para ello, pruebe a conectarse desde una herramienta como la línea de comandos de MySQL hospedada en otra máquina o desde la instancia de Azure Cloud Shell disponible en Azure Portal.
Si su organización tiene estrictas directivas de seguridad y no permite que todas las direcciones IP del servidor de origen permitan la comunicación desde Azure al servidor de origen, puede usar el siguiente comando para determinar la dirección IP de su servidor MySQL.
Inicie sesión en el servidor de Azure Database for MySQL mediante una herramienta como la línea de comandos de MySQL.
Ejecute la siguiente consulta.
mysql> SELECT @@global.redirect_server_host;A continuación se incluye una salida de ejemplo:
+-----------------------------------------------------------+ | @@global.redirect_server_host | +-----------------------------------------------------------+ | e299ae56f000.tr1830.westus1-a.worker.database.windows.net | +-----------------------------------------------------------+Salga de la línea de comandos de MySQL.
Para obtener la dirección IP, ejecute el siguiente comando en la utilidad ping:
ping <output of step 2b>Por ejemplo:
C:\Users\testuser> ping e299ae56f000.tr1830.westus1-a.worker.database.windows.net Pinging tr1830.westus1-a.worker.database.windows.net (**11.11.111.111**) 56(84) bytes of data.Configure las reglas de firewall del servidor de origen para incluir la dirección IP de salida del paso anterior en el puerto 3306.
Nota
Esta dirección IP puede cambiar debido a operaciones de mantenimiento o implementación. Este método de conectividad es solo para los clientes que no pueden permitirse que permitan todas las direcciones IP en el puerto 3306.
Active el registro binario.
Compruebe si se ha habilitado el registro binario en el servidor de origen mediante la ejecución del comando siguiente:
SHOW VARIABLES LIKE 'log_bin';Si la variable
log_binse devuelve con el valor "ON", el registro binario está habilitado en el servidor.Si se devuelve
log_bincon el valor "OFF" y el servidor de origen se ejecuta de forma local o en máquinas virtuales en las que se puede tener acceso al archivo de configuración (my.cnf), puede seguir estos pasos:Busque el archivo de configuración de MySQL (my.cnf) en el servidor de origen. Por ejemplo: /etc/my.cnf.
Abra el archivo de configuración para editarlo y busque la sección mysqld.
En la sección mysqld, agregue la línea siguiente:
log-bin=mysql-bin.logReinicie el servidor de origen de MySQL para que los cambios surtan efecto.
Una vez que se haya reiniciado el servidor, compruebe que el registro binario está habilitado mediante la ejecución de la misma consulta que antes:
SHOW VARIABLES LIKE 'log_bin';
Establezca la configuración del servidor de origen.
Replicación de datos de entrada requiere el parámetro
lower_case_table_namespara ser coherente entre los servidores de origen y de réplica. Este parámetro es 1 de forma predeterminada en Azure Database for MySQL.SET GLOBAL lower_case_table_names = 1;Opcional: si desea usar la replicación basada en GTID,deberá comprobar si GTID está habilitado en el servidor de origen. Puede ejecutar el siguiente comando en el servidor MySQL de origen para ver si gtid_mode está activado.
show variables like 'gtid_mode';Importante
Todos los servidores tienen gtid_mode establecido en el valor predeterminado desactivado. No es necesario habilitar GTID en el servidor MySQL de origen específicamente para configurar la replicación de datos de entrada. Si GTID ya está habilitado en el servidor de origen, puede usar opcionalmente la replicación basada en GTID para configurar también la Replicación de datos de entrada con el servidor único de Azure Database for MySQL. Puede usar la replicación basada en archivos para configurar la replicación de datos de entrada para todos los servidores, independientemente de la configuración de gitd_mode en el servidor de origen.
Cree un nuevo rol de replicación y configure el permiso.
Cree una cuenta de usuario en el servidor de origen que está configurado con privilegios de replicación. Esto puede realizarse a través de los comandos SQL o una herramienta como MySQL Workbench. Tenga en cuenta si planea replicar con SSL, ya que necesitará especificarse al crear el usuario. Consulte la documentación de MySQL para entender cómo agregar cuentas de usuario en el servidor de origen.
En los comandos siguientes, el nuevo rol de replicación creado puede obtener acceso al origen desde cualquier máquina, no solo desde la máquina que hospeda al propio origen. Esto se hace especificando "syncuser@'%'" en el comando create user. Consulte la documentación de MySQL para más información acerca de la especificación de nombres de cuenta.
Comando SQL
Replicación con SSL
Para requerir SSL a todas las conexiones de usuario, use el comando siguiente para crear un usuario:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO 'syncuser'@'%' REQUIRE SSL;Replicación sin SSL
Si SSL no es necesario para todas las conexiones, use el comando siguiente para crear un usuario:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO 'syncuser'@'%';MySQL Workbench
Para crear el rol de replicación en MySQL Workbench, abra el panel Usuarios y privilegios desde el panel Administración y, a continuación, seleccione Agregar cuenta.
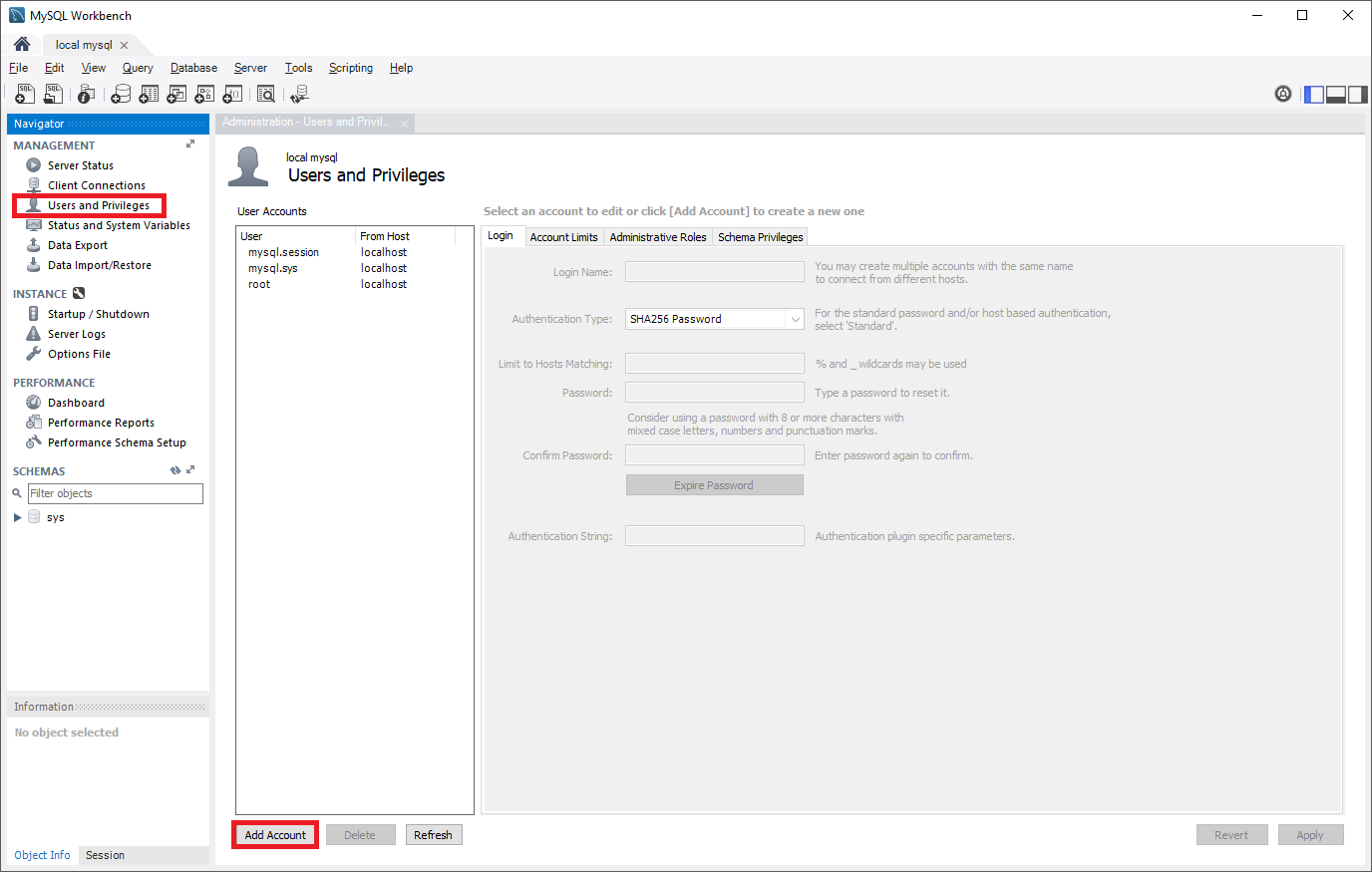
Escriba el nombre de usuario en el campo Login Name (Nombre de inicio de sesión).
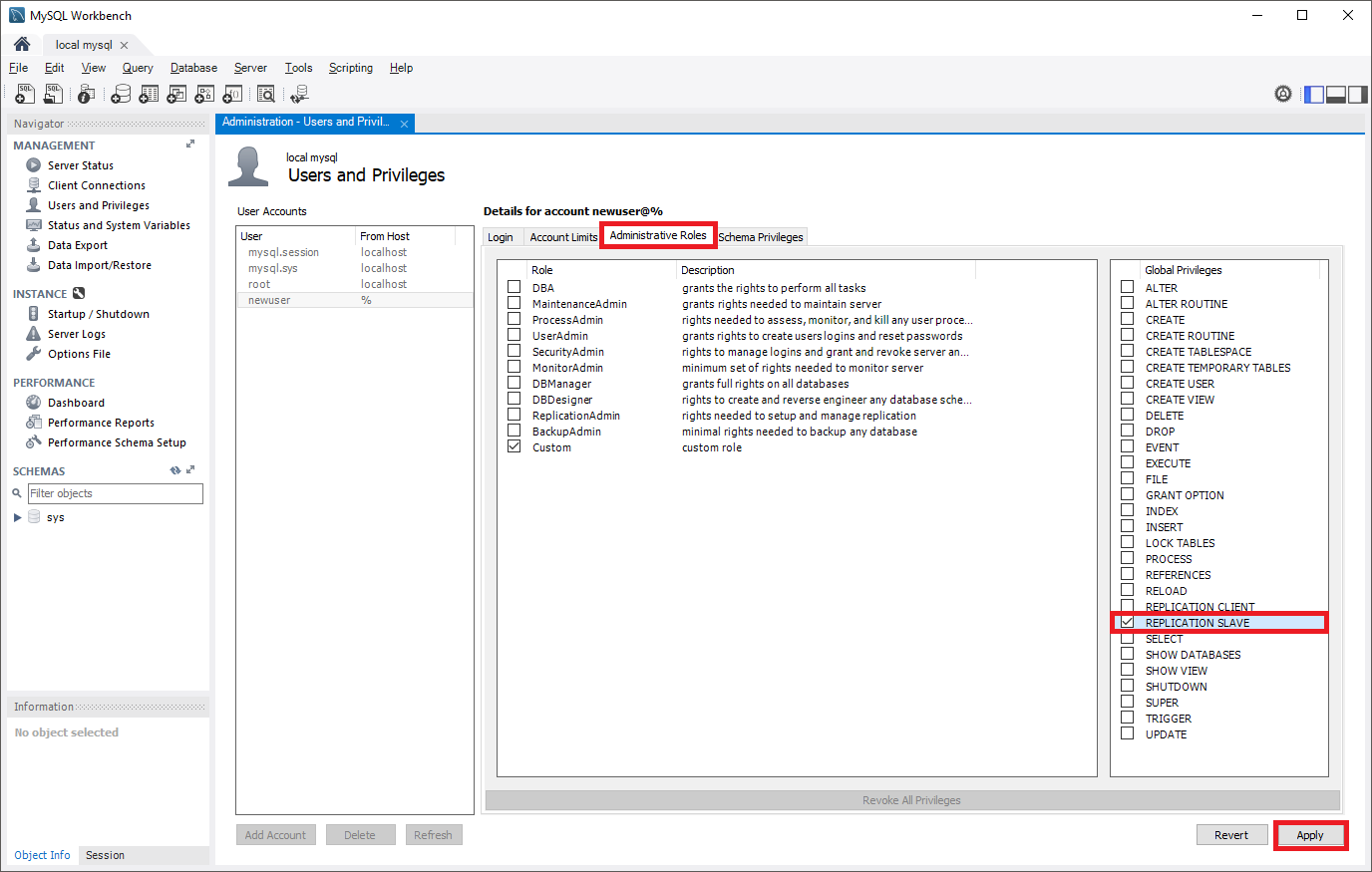
Seleccione el panel Roles administrativos y, a continuación, seleccione Servidor subordinado de replicación en la lista de Privilegios globales. A continuación, seleccione Aplicar para crear el rol de replicación.
Establezca el servidor de origen en el modo de solo lectura.
Antes de comenzar a volcar la base de datos, el servidor debe colocarse en modo de solo lectura. En modo de solo lectura, el servidor de origen no podrá procesar ninguna transacción de escritura. Evalúe el impacto para su negocio y la programación de la ventana de solo lectura en un momento de poco tráfico, si es necesario.
FLUSH TABLES WITH READ LOCK; SET GLOBAL read_only = ON;Obtenga el nombre del archivo de registro binario y el desplazamiento.
Ejecute el comando
show master statuspara determinar el nombre de archivo de registro binario actual y el desplazamiento.show master status;Los resultados deberían parecerse a los siguientes. Asegúrese de anotar el nombre del archivo binario, pues se utilizará en pasos posteriores.

Volcado y restauración del servidor de origen
Determine qué bases de datos y tablas quiere replicar en Azure Database for MySQL y realice el volcado desde el servidor de origen.
Puede utilizar mysqldump para volcar bases de datos desde el servidor principal. Para más información, consulte Volcado y restauración. No es necesario volcar la biblioteca de MySQL y la biblioteca de prueba.
Opcional: si desea usar la replicación basada en gtid, deberá identificar el GTID de la última transacción ejecutada en el servidor principal. Puede utilizar el siguiente comando para anotar el GTID de la última transacción ejecutada en el servidor maestro.
show global variables like 'gtid_executed';Establezca el servidor de origen en modo de lectura/escritura.
Cuando se haya volcado la base de datos, cambie el servidor MySQL de origen de nuevo al modo de lectura/escritura.
SET GLOBAL read_only = OFF; UNLOCK TABLES;Restaure el archivo de volcado en el nuevo servidor.
Restaure el archivo de volcado en el servidor creado en el servicio Azure Database for MySQL. Consulte Volcado y restauración para saber cómo restaurar un archivo de volcado en un servidor MySQL. Si el archivo de volcado es grande, cárguelo a una máquina virtual en Azure dentro de la misma región que el servidor de réplica. Restáurelo en el servidor de Azure Database for MySQL desde la máquina virtual.
Opcional: observe el GTID del servidor restaurado en Azure Database for MySQL para asegurarse de que es el mismo que el del servidor principal. Puede utilizar el siguiente comando para anotar el GTID del valor purgado de GTID en el servidor de réplica de Azure Database for MySQL. El valor de gtid_purged debe ser el mismo que gtid_executed en el servidor maestro anotado en el paso 2 para que la replicación basada en GTID funcione.
show global variables like 'gtid_purged';
Vinculación de los servidores de origen y de réplica para iniciar la Replicación de datos de entrada
Establezca el servidor de origen.
Todas las funciones de la replicación de datos internos se realizan mediante los procedimientos almacenados. Puede encontrar todos los procedimientos en Procedimientos almacenados de replicación de datos internos. Los procedimientos almacenados se pueden ejecutar en el shell de MySQL o en MySQL Workbench.
Para vincular dos servidores e iniciar la replicación, inicie sesión en el servidor de réplica de destino en el servicio Azure Database for MySQL y establezca la instancia externa como servidor de origen. Esto se realiza mediante el procedimiento almacenado
mysql.az_replication_change_masteren el servidor Azure Database for MySQL.CALL mysql.az_replication_change_master('<master_host>', '<master_user>', '<master_password>', <master_port>, '<master_log_file>', <master_log_pos>, '<master_ssl_ca>');Opcional: si desea usar la replicación basada en gtid, deberá usar el siguiente comando para vincular los dos servidores.
call mysql.az_replication_change_master_with_gtid('<master_host>', '<master_user>', '<master_password>', <master_port>, '<master_ssl_ca>');master_host: nombre de host del servidor de origen
master_user: nombre de usuario para el servidor de origen
master_password: contraseña para el servidor de origen
master_port: número de puerto en el que el servidor de origen escucha las conexiones (3306 es el puerto predeterminado en el que escucha MySQL).
master_log_file: nombre del archivo de registro binario procedente de la ejecución de
show master statusmaster_log_pos: posición del registro binario procedente de la ejecución de
show master statusmaster_ssl_ca: contexto del certificado de entidad de certificación. Si no usa SSL, pase una cadena vacía.
Se recomienda pasar este parámetro como una variable. Para más información, vea los ejemplos siguientes.
Nota
Si el servidor de origen se hospeda en una máquina virtual de Azure, establezca la opción "Permitir el acceso a servicios de Azure" en "Activado" para permitir que los servidores de origen y de réplica se comuniquen entre sí. Esta configuración se puede cambiar desde las opciones de seguridad de conexión. Para obtener más información, consulte el artículo sobre cómo administrar reglas de firewall mediante el portal.
Ejemplos
Replicación con SSL
La variable
@certse crea mediante la ejecución de los siguientes comandos de MySQL:SET @cert = '-----BEGIN CERTIFICATE----- PLACE YOUR PUBLIC KEY CERTIFICATE'`S CONTEXT HERE -----END CERTIFICATE-----'La replicación con SSL se configura entre un servidor de origen hospedado en el dominio "companya.com" y un servidor de réplica hospedado en Azure Database for MySQL. Este procedimiento almacenado se ejecuta en la réplica.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, @cert);Replicación sin SSL
La replicación sin SSL se configura entre un servidor de origen hospedado en el dominio "companya.com" y un servidor de réplica hospedado en Azure Database for MySQL. Este procedimiento almacenado se ejecuta en la réplica.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, '');Configure el filtrado.
Si desea omitir la replicación de algunas tablas del maestro, actualice el parámetro de servidor
replicate_wild_ignore_tableen el servidor de réplica. Puede proporcionar más de un patrón de tabla mediante una lista separada por comas.Consulte la documentación de MySQL para más información acerca de este parámetro.
Para actualizar el parámetro, use Azure Portal o la CLI de Azure.
Inicie la replicación.
Llame al procedimiento almacenado
mysql.az_replication_startpara iniciar la replicación.CALL mysql.az_replication_start;Compruebe el estado de replicación.
Llame al comando
show slave statusen el servidor de réplica para ver el estado de replicación.show slave status;Si el estado de
Slave_IO_RunningySlave_SQL_Runninges "yes" y el valor deSeconds_Behind_Masteres "0", la replicación funciona correctamente.Seconds_Behind_Masterindica el tiempo de retraso de la réplica. Si el valor no es "0", significa que la réplica procesa actualizaciones.
Otros procedimientos almacenados útiles para las operaciones de la replicación de datos de entrada
Detención replicación
Para detener la replicación entre el servidor de origen y de réplica, use el siguiente procedimiento almacenado:
CALL mysql.az_replication_stop;
Eliminación de la relación de replicación
Para eliminar la relación entre el servidor de origen y de réplica, use el siguiente procedimiento almacenado:
CALL mysql.az_replication_remove_master;
Omisión de error de replicación
Para omitir un error de replicación y permitir que continúe la replicación, use el siguiente procedimiento almacenado:
CALL mysql.az_replication_skip_counter;
Opcional: si desea usar la replicación basada en gtid, use el siguiente procedimiento almacenado para omitir una transacción.
call mysql. az_replication_skip_gtid_transaction(‘<transaction_gtid>’)
El procedimiento puede omitir la transacción para el GTID dado. Si el formato de GTID no es correcto o la transacción de GTID ya se ha ejecutado, el procedimiento no se ejecutará. El GTID de una transacción se puede determinar analizando el registro binario para comprobar los eventos de transacción. MySQL proporciona un valor mysqlbinlog de utilidad para analizar los registros binarios y mostrar su contenido en formato de texto, que se puede usar para identificar el GTID de la transacción.
Importante
Este procedimiento solo se puede usar para omitir una transacción y no se puede usar para omitir el conjunto de gtid ni establecer gtid_purged.
Para omitir la siguiente transacción después de la posición de replicación actual, use el siguiente comando para identificar el GTID de la transacción siguiente, como se muestra a continuación.
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos][LIMIT [offset,] row_count]

Pasos siguientes
- Aprenda más sobre Data-in Replication para Azure Database for MySQL.