Administración de continuidad empresarial en Azure
Azure mantiene uno de los programas de administración de continuidad empresarial más maduros y respetados del sector. El objetivo de la continuidad empresarial en Azure es crear y avanzar en la capacidad de recuperación y resistencia de todos los servicios recuperables de forma independiente, ya sea un servicio orientado al cliente (parte de una oferta de Azure) o un servicio de plataforma de soporte interno.
Para comprender la continuidad empresarial, es importante tener en cuenta que muchas ofertas están formadas por varios servicios. En Azure, cada servicio se identifica de forma estática a través de herramientas y es la unidad de medida que se usa para la privacidad, la seguridad, el inventario, la administración de continuidad empresarial de riesgo y otras funciones. Para medir correctamente las funcionalidades de un servicio, se incluyen los tres elementos de personas, proceso y tecnología para cada servicio, sea del tipo que sea.
Por ejemplo:
- Si hay un proceso empresarial basado en personas, como un equipo o un servicio de soporte técnico, la entrega del servicio es lo que hacen. Las personas usan procesos y tecnología para ejecutar el servicio.
- Si hay tecnología como servicio, como Azure Virtual Machines, la entrega del servicio es la tecnología junto con las personas y los procesos que admiten su funcionamiento.
Modelo de responsabilidad compartida
Muchas de las ofertas que Proporciona Azure requieren que configure la recuperación ante desastres en varias regiones y no es responsabilidad de Microsoft. No todos los servicios de Azure replican automáticamente los datos ni se replican automáticamente desde una región con errores para la replicación cruzada en otra región habilitada. En estos casos, es responsable de configurar la recuperación y la replicación.
Microsoft garantiza que la infraestructura de línea de base y los servicios de plataforma estén disponibles. Pero en algunos escenarios, el uso exige duplicar las implementaciones y el almacenamiento en una capacidad de varias regiones, si decide hacerlo. En estos ejemplos se muestra el modelo de responsabilidad compartida. Es un pilar fundamental en la estrategia de continuidad empresarial y recuperación ante desastres.
División de responsabilidad
En un centro de datos local, usted es el propietario de toda la pila. A medida que traslada recursos a la nube, algunas responsabilidades se transfieren a Microsoft. En el diagrama siguiente se muestran las áreas y la división de responsabilidad entre usted y Microsoft, según el tipo de implementación.
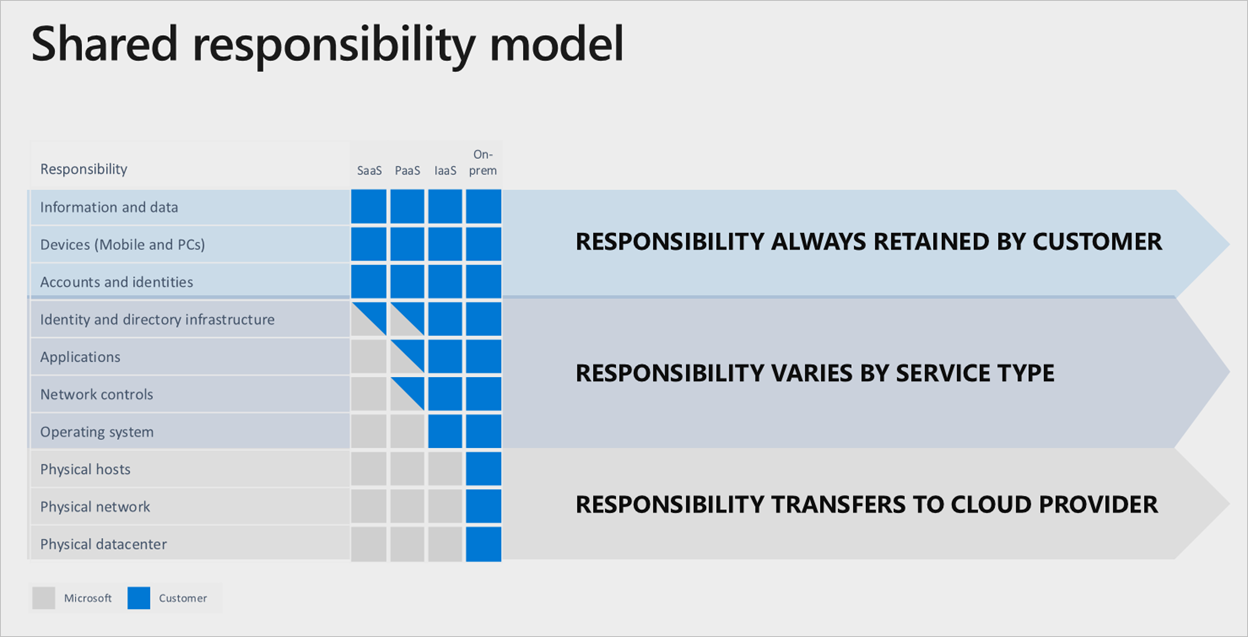
Un buen ejemplo del modelo de responsabilidad compartida es la implementación de máquinas virtuales. Si desea configurar la replicación entre regiones para lograr resistencia si se produce un error en la región, debe implementar un conjunto duplicado de máquinas virtuales en una región habilitada alternativa. Azure no replica automáticamente estos servicios en caso de error. Es su responsabilidad implementar los recursos necesarios. Debe tener un proceso para cambiar manualmente las regiones principales o debe usar un administrador de tráfico para detectar y conmutar por error automáticamente.
Todos los servicios de recuperación ante desastres habilitados por el cliente tienen documentación pública para guiarlo. Para obtener un ejemplo de documentación pública para la recuperación ante desastres habilitada por el cliente, consulte Azure Data Lake Analytics.
Para obtener más información sobre el modelo de responsabilidad compartida, consulte el Centro de confianza de Microsoft.
Cumplimiento de continuidad empresarial: responsabilidad de nivel de servicio
Cada servicio es necesario para completar los registros de recuperación ante desastres de continuidad empresarial en la herramienta Azure Business Continuity Manager. Los propietarios de servicios pueden usar la herramienta para trabajar en un modelo federado para completar e incorporar requisitos, que incluyen:
Propiedades del servicio: define el servicio y cómo se logran la recuperación ante desastres y la resistencia, e identifica la parte responsable de la recuperación ante desastres (para tecnología). Para más información sobre la propiedad de la recuperación, consulte la explicación sobre el modelo de responsabilidad compartida en la sección y el diagrama anteriores.
Análisis del impacto empresarial: este análisis ayuda al propietario del servicio a definir el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) en función de la importancia del servicio en una tabla de impactos. Los impactos operativos, legales, normativos, de imagen de marca y financieros se usan como objetivos para la recuperación.
Nota:
Microsoft no publica RTO ni RPO para los servicios porque estos datos son solo para medidas internas. Todas las promesas y medidas de los clientes se basan en el Acuerdo de Nivel de Servicio, porque cubre una gama más amplia frente a RTO o RPO, que solo se aplican en pérdidas catastróficas.
Dependencias: cada servicio asigna las dependencias (otros servicios) que requiere para funcionar, independientemente de la importancia, y se asigna al entorno de ejecución, necesario solo para la recuperación, o ambos. Si hay dependencias de almacenamiento, se asignan otros datos que definen lo que se almacena, y si requiere instantáneas a un momento dado, por ejemplo.
Personal: como se indica en la definición de un servicio, es importante conocer la ubicación y la cantidad de trabajadores que pueden admitir el servicio, lo que garantiza que no haya únicos puntos de error, y si los empleados críticos están dispersos para evitar errores mediante la cohabitación en una sola ubicación.
Proveedores externos: Microsoft mantiene una lista completa de proveedores externos y los proveedores que se consideran críticos se tienen en cuenta para las funcionalidades. Si un servicio lo identifica como una dependencia, las funcionalidades del proveedor se comparan con las necesidades del servicio para asegurarse de que una interrupción de terceros no interrumpa los servicios de Azure.
Clasificación de recuperación: esta clasificación es única para el programa de administración de continuidad empresarial de Azure. Esta clasificación mide varios elementos clave para crear una puntuación de resistencia:
- Voluntad de conmutación por error: aunque puede haber un proceso, puede que no sea la primera opción para interrupciones a corto plazo.
- Automatización de la conmutación por error.
- Automatización de la decisión de conmutación por error.
El tiempo más confiable y más corto para la conmutación por error es un servicio automatizado y no requiere ninguna decisión humana. Un servicio automatizado usa la supervisión de latidos o las transacciones sintéticas para determinar si un servicio está inactivo e iniciar una corrección inmediata.
Plan de recuperación y prueba: Azure requiere que todos los servicios tengan un plan de recuperación detallado y que prueben ese plan como si se hubiera producido un error en el servicio debido a una interrupción catastrófica. Los planes de recuperación deben escribirse para que alguien con aptitudes y acceso similares pueda completar las tareas. Un plan escrito evita depender de la disponibilidad de expertos en la materia.
Las pruebas se realizan de varias maneras, incluida la prueba automática en un entorno de producción o de casi producción, y como parte de la exploración en profundidad de regiones completas de Azure en conjuntos de regiones de valor controlado. Estas regiones habilitadas son idénticas a las regiones de producción, pero se pueden deshabilitar sin afectar a los servicios. Las pruebas se consideran integradas porque todos los servicios se ven afectados simultáneamente.
Habilitación del cliente: cuando es responsable de configurar la recuperación ante desastres, Azure debe tener instrucciones de documentación orientadas al público. Para todos estos servicios, se proporcionan vínculos a documentación y detalles sobre el proceso.
Comprobación del cumplimiento de la continuidad empresarial
Cuando un servicio ha completado su registro de administración de continuidad empresarial, debe enviarlo para su aprobación. Se asigna a un profesional experimentado en administración de continuidad empresarial que revisa todo el registro para comprobar su integridad y calidad. Si el registro cumple todos los requisitos, se aprueba. Si no es así, se rechaza con una solicitud de reprocesamiento. Este proceso garantiza que ambas partes acepten que se ha logrado el cumplimiento de la continuidad empresarial y que solo el propietario del servicio certifica el trabajo. Los equipos de auditoría y cumplimiento internos de Azure también hacen un muestreo aleatorio periódico para asegurarse de que se envían los mejores datos.
Pruebas de servicios
Microsoft y Azure hacen pruebas exhaustivas para la recuperación ante desastres y para la preparación de la zona de disponibilidad. Los servicios se prueban automáticamente en un entorno de producción o de preproducción para demostrar la capacidad de recuperación independiente de los servicios que no dependen de las conmutaciones por error de la plataforma principal.
Para asegurarse de que los servicios se pueden recuperar de forma similar en un escenario de inactividad de una región real, las pruebas de tipo de "desconexión" se realizan en entornos de valor controlado que son regiones totalmente implementadas que coinciden con producción. Por ejemplo, los clústeres, bastidores y unidades de alimentación están literalmente desactivados para simular un error de región total.
Durante estas pruebas, Azure usa el mismo proceso de producción para las tareas de detección, notificación, respuesta y recuperación. Ninguna persona espera una exploración y los ingenieros encargados de la recuperación son los recursos normales de rotación de turno. Esta coordinación evita depender de los expertos en la materia, que podrían no estar disponibles durante un evento real.
En estas pruebas se incluyen servicios en los que es responsable de configurar la recuperación ante desastres después de la documentación pública de Microsoft. Los equipos de servicio crean instancias de tipo cliente para mostrar que la recuperación ante desastres habilitada por el cliente funciona según lo previsto y que las instrucciones proporcionadas son precisas.
Para obtener más información sobre las certificaciones, consulte el Centro de confianza de Microsoft y la sección sobre cumplimiento.