Volúmenes NFS v4.1 en Azure NetApp Files para SAP HANA
Azure NetApp Files proporciona recursos compartidos de NFS nativos que se pueden usar para los volúmenes /hana/shared, /hana/data y /hana/log. El uso de recursos compartidos de NFS basados en ANF para los volúmenes /hana/data y /hana/log requiere el uso del protocolo NFS v4.1. El protocolo NFS v3 no admite el uso de los volúmenes /hana/data y /hana/log al basar los recursos compartidos en ANF.
Importante
No se admite el protocolo NFS v3 implementado en Azure NetApp Files para su uso con /hana/data y /hana/log. El uso de NFS 4.1 es obligatorio para los volúmenes /hana/data y /hana/log desde un punto de vista funcional. Por su parte, para el volumen /hana/shared, se puede usar el protocolo NFS v3 o NFS v4.1 desde un punto de vista funcional.
Consideraciones importantes
A la hora de considerar Azure NetApp Files para SAP Netweaver y SAP HANA, tenga en cuenta los siguientes aspectos importantes:
Para conocer los límites de volumen y grupo de capacidad, consulte Límites de recursos de Azure NetApp Files.
Los recursos compartidos NFS basados en Azure NetApp Files y las máquinas virtuales que montan esos recursos compartidos deben estar en la misma red virtual de Azure o en redes virtuales emparejadas en la misma región.
La red virtual seleccionada debe tener una subred delegada en Azure NetApp Files. Para la carga de trabajo de SAP, se recomienda configurar un intervalo /25 para la subred delegada en Azure NetApp Files.
Es importante tener las máquinas virtuales implementadas con suficiente proximidad al almacenamiento de Azure NetApp para reducir la latencia, como, por ejemplo, demandada por SAP HANA para las escrituras de registro de puesta al día.
- Azure NetApp Files mientras tanto, tiene funcionalidad para implementar volúmenes NFS en zonas de Azure Availability Zones específicas. Esta proximidad zonal será suficiente en la mayoría de los casos para lograr una latencia de menos de 1 milisegundo. La funcionalidad está en versión preliminar pública y se describe en el artículo Administración de la Administración de la selección de ubicación del volumen de la zona de disponibilidad para Azure NetApp Files. Esta funcionalidad no requiere ningún proceso interactivo con Microsoft para lograr la proximidad entre la máquina virtual y los volúmenes NFS que asigne.
- Aunque para lograr la proximidad más óptima, la funcionalidad de los grupos de volúmenes de aplicación está disponible. Esta funcionalidad no solo busca la proximidad más óptima, sino la selección de ubicación más óptima de los volúmenes NFS, por lo que los distintos controladores manipulan los datos de HANA y los volúmenes de registro de puesta al día. La desventaja es que este método necesita algún proceso interactivo con Microsoft para anclar las máquinas virtuales.
Asegúrese de que la latencia del servidor de base de datos en el volumen de Azure NetApp Files se mide y está por debajo de 1 milisegundo
El rendimiento de un volumen de Azure NetApp es una función de la cuota del volumen y del nivel de servicio, como se documenta en Nivel de servicio para Azure NetApp Files. Al ajustar el tamaño de los volúmenes de Azure NetApp de HANA, asegúrese de que el rendimiento resultante cumple los requisitos del sistema HANA. De forma alternativa, considere el uso de un grupo de capacidad manual de QoS donde la capacidad de volumen y el rendimiento se pueden configurar y escalar de forma independiente (en este documento se pueden encontrar ejemplos específicos de SAP HANA).
Intente "consolidar" volúmenes para obtener más rendimiento en un volumen de mayor tamaño; por ejemplo, use un volumen para /sapmnt, /usr/sap/trans, etc., si es posible.
Azure NetApp Files ofrece la directiva de exportación: puede controlar los clientes permitidos, el tipo de acceso (lectura y escritura, solo lectura, etc.).
El identificador de usuario para sidadm y el identificador de grupo para
sapsysen las máquinas virtuales debe coincidir con la configuración en Azure NetApp Files.Implementación de parámetros del sistema operativo Linux mencionados en la nota de SAP 3024346
Importante
Para las cargas de trabajo de SAP HANA, una baja latencia resulta fundamental. Trabaje con su representante de Microsoft para asegurarse de que las máquinas virtuales y los volúmenes de Azure NetApp Files se implementan en ubicaciones muy cercanas entre sí.
Importante
Si hubiera una discrepancia entre el id. de usuario para sidadm y el id. de grupo para sapsys entre la máquina virtual y la configuración de Azure NetApp, los permisos de archivos en volúmenes de Azure NetApp, montados en la máquina virtual, aparecerían como nobody. Asegúrese de especificar el identificador de usuario correcto para sidadm y el identificador de grupo para sapsys al incorporar un nuevo sistema a Azure NetApp Files.
Opción de montaje NCONNECT
Nconnect es una opción de montaje para volúmenes NFS hospedados en Azure NetApp Files que permite al cliente NFS abrir varias sesiones en un único volumen NFS. El uso de nconnect con un valor de más de 1 también desencadena el cliente NFS para usar más de una sesión RPC en el lado cliente (en el sistema operativo invitado) para controlar el tráfico entre el sistema operativo invitado y los volúmenes NFS montados. El uso de varias sesiones que controlan el tráfico de un volumen NFS, pero también el uso de varias sesiones RPC puede abordar escenarios de rendimiento como:
- Montaje de varios volúmenes NFS hospedados en Azure NetApp Files con distintos niveles de servicio en una máquina virtual
- El rendimiento de escritura máximo de un volumen y una única sesión de Linux está entre 1,2 y 1,4 GB/s. Tener varias sesiones en un volumen NFS hospedado en Azure NetApp Files puede aumentar el rendimiento
En el caso de las versiones del sistema operativo Linux que admiten nconnect como opción de montaje y algunas consideraciones de configuración importantes de nconnect, especialmente con diferentes puntos de conexión de servidor NFS, lea el documento Procedimientos recomendados de montaje NFS de Linux para Azure NetApp Files.
Ajuste del tamaño de la base de datos HANA en Azure NetApp Files
El rendimiento de un volumen de Azure NetApp es una función del tamaño del volumen y el nivel de servicio, como se documenta en Niveles de servicio para Azure NetApp Files.
Es importante comprender la relación entre rendimiento y tamaño, y que hay límites físicos en un punto de conexión de almacenamiento del servicio. Cada punto de conexión de almacenamiento se insertará dinámicamente en la subred delegada de Azure NetApp Files al crear el volumen y recibir una dirección IP. Los volúmenes de Azure NetApp Files pueden, en función de la capacidad disponible y la lógica de implementación, compartir un punto de conexión de almacenamiento.
En la tabla siguiente se demuestra que podría tener sentido crear un volumen "Estándar" de gran tamaño para almacenar las copias de seguridad, y que no tiene sentido crear un volumen "Ultra" mayor de 12 TB, porque se superaría la capacidad de ancho de banda física máxima de un solo volumen.
Si necesita más del rendimiento de escritura máximo para el volumen /hana/data que puede proporcionar una sola sesión de Linux, también puede usar la creación de particiones de volúmenes de datos de SAP HANA como alternativa. La creación de particiones del volumen de datos de SAP HANA fragmenta la actividad de E/S durante la recarga de datos o los puntos de retorno de HANA en varios archivos de datos de HANA ubicados en varios recursos compartidos de NFS. Para obtener más detalles sobre la fragmentación del volumen de datos de HANA, lea estos artículos:
- Guía para administradores de HANA
- Blog sobre SAP HANA: creación de particiones de volúmenes de datos
- Nota de SAP n.º 2400005
- Nota de SAP #2700123
| Size | Rendimiento Estándar | Rendimiento Premium | Rendimiento Ultra |
|---|---|---|---|
| 1 TB | 16 MB/s | 64 MB/s | 128 MB/s |
| 2 TB | 32 MB/s | 128 MB/s | 256 MB/s |
| 4 TB | 64 MB/s | 256 MB/s | 512 MB/s |
| 10 TB | 160 MB/s | 640 MB/s | 1280 MB/s |
| 15 TB | 240 MB/s | 960 MB/s | 1400 MB/s1 |
| 20 TB | 320 MB/s | 1280 MB/s | 1400 MB/s1 |
| 40 TB | 640 MB/s | 1400 MB/s1 | 1400 MB/s1 |
1: límites de rendimiento de lectura de sesión única o de escritura (en caso de que no se use la opción de montaje de NFS nconnect)
Es importante comprender que los datos se escriben en los mismos discos SSD en el back-end de almacenamiento. Se ha creado la cuota de rendimiento del grupo de capacidad para poder administrar el entorno. Los KPI de almacenamiento son iguales para todos los tamaños de base de datos de HANA. En casi todos los casos, esta hipótesis no refleja la realidad y la expectativa del cliente. El tamaño de los sistemas de HANA no implica necesariamente que un sistema pequeño requiera un rendimiento de almacenamiento reducido, ni que un sistema de gran tamaño requiera un rendimiento alto de almacenamiento. No obstante, por lo general se pueden esperar mayores requisitos de rendimiento para las instancias de base de datos de HANA de mayor tamaño. Como resultado de las reglas de dimensionamiento de SAP para el hardware subyacente, estas instancias de HANA de mayor tamaño también proporcionan más recursos de CPU y un paralelismo superior en tareas como la carga de datos después del reinicio de una instancia. En consecuencia, se deben adoptar los tamaños de volumen para las expectativas y los requisitos del cliente, y no solo controlados por requisitos de capacidad puros.
Al diseñar la infraestructura de SAP en Azure, debe tener en cuenta los requisitos mínimos de rendimiento del almacenamiento (para sistemas de producción) de SAP. Estos requisitos se traducen en las siguientes características de rendimiento mínimas:
| Tipo de volumen y tipo de E/S | KPI mínimo solicitado por SAP | Nivel de servicio Premium | Nivel de servicio Ultra |
|---|---|---|---|
| Escritura de volumen de registro | 250 MB/s | 4 TB | 2 TB |
| Escritura de volumen de datos | 250 MB/s | 4 TB | 2 TB |
| Lectura de volumen de datos | 400 MB/s | 6,3 TB | 3,2 TB |
Dado que se exigen los tres KPI, el volumen de /hana/data debe dimensionarse a la capacidad de mayor tamaño para cumplir los requisitos mínimos de lectura. Cuando se usan grupos de capacidad de QoS manual, el tamaño y el rendimiento de los volúmenes se pueden definir de forma independiente. Dado que tanto la capacidad como el rendimiento se toman del mismo grupo de capacidad, el nivel de servicio y el tamaño del grupo deben ser lo suficientemente grandes como para ofrecer el rendimiento total (vea el ejemplo aquí).
En el caso de los sistemas HANA, que no requieren un ancho de banda alto, el rendimiento del volumen de Azure NetApp Files se puede reducir con un tamaño de volumen menor o, si usa QoS manual, ajustar el rendimiento directamente. Y, en caso de que un sistema HANA requiera más rendimiento, el volumen podría adaptarse mediante el cambio de tamaño de la capacidad en línea. No se ha definido ningún KPI para los volúmenes de copia de seguridad. Sin embargo, el rendimiento del volumen de copia de seguridad es fundamental para un entorno que funcione correctamente. El rendimiento del volumen de registros y datos debe estar diseñado para cumplir con las expectativas de los clientes.
Importante
Independientemente de la capacidad que implemente en un volumen NFS individual, se espera que el rendimiento se nivele en el rango de 1,2-1,4 GB/s de ancho de banda usado por un consumidor en una sola sesión. Esto tiene que ver con la arquitectura subyacente de la oferta de Azure NetApp Files y los límites de sesiones de Linux relacionadas alrededor de NFS. Las cifras relativas al rendimiento y a la capacidad de proceso que se indican en el artículo Banco de pruebas de rendimiento de resultados de pruebas para Azure NetApp Files se obtuvieron en un volumen NFS compartido con varias máquinas virtuales cliente y como resultado con varias sesiones. Ese escenario es diferente al escenario que se mide en SAP, donde se mide el rendimiento de una sola máquina virtual frente a un volumen NFS hospedado en Azure NetApp Files.
Para cumplir los requisitos de rendimiento mínimo de SAP para los datos y el registro, y de acuerdo con las directrices para /hana/shared, los tamaños recomendados serían los siguientes:
| Volumen | Size Capa Premium Storage |
Size Capa de almacenamiento Ultra |
Protocolo NFS admitido |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6,3 TiB | 3,2 TiB | v4.1 |
| /hana/shared scale-up | Mín. (1 TB, 1 x RAM) | Mín. (1 TB, 1 x RAM) | v3 o v4.1 |
| /hana/shared scale-out | 1 x RAM del nodo de trabajo por cuatro nodos de trabajo |
1 x RAM del nodo de trabajo por cuatro nodos de trabajo |
v3 o v4.1 |
| /hana/logbackup | 3 x RAM | 3 x RAM | v3 o v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 o v4.1 |
Se recomienda encarecidamente usar NFS v4.1 para todos los volúmenes.
Revise cuidadosamente las consideraciones para ajustar el tamaño /hana/shared, porque el volumen adecuado de /hana/shared contribuye a la estabilidad del sistema.
Los tamaños de los volúmenes de copia de seguridad son estimaciones. Los requisitos exactos deben definirse en función de la carga de trabajo y los procesos de funcionamiento. En el caso de las copias de seguridad, podría consolidar muchos volúmenes para diferentes instancias de SAP HANA en uno o dos volúmenes de mayor tamaño, lo que podría tener un nivel de servicio de Azure NetApp Files inferior.
Nota:
Las recomendaciones de dimensionamiento de Azure NetApp Files que se han indicado en este documento tienen como objetivo satisfacer los requisitos mínimos que SAP expresa a sus proveedores de infraestructura. En escenarios reales de implementaciones de clientes y de cargas de trabajo, es posible que no sea suficiente. Utilice estas recomendaciones como punto de partida y adáptelas en función de los requisitos de la carga de trabajo específica.
Por tanto, podría considerar la posibilidad de implementar un rendimiento similar para los volúmenes de Azure NetApp Files, tal como se indicó anteriormente en el almacenamiento de disco Ultra. Tenga en cuenta también los tamaños enumerados para los volúmenes de las diferentes SKU de máquina virtual como ya se ha hecho en las tablas de disco Ultra.
Sugerencia
Puede cambiar el tamaño de los volúmenes de Azure NetApp Files de manera dinámica, sin necesidad de unmount los volúmenes, detener las máquinas virtuales o detener SAP HANA. Esto permite que la aplicación se adapte a las demandas de rendimiento esperadas e imprevistas.
La documentación sobre cómo implementar una configuración de escalabilidad horizontal de SAP HANA con un nodo de espera mediante Azure NetApp Files basado en los volúmenes de NFS v4.1 se publica en Escalabilidad horizontal de SAP HANA con nodo en espera en máquinas virtuales de Azure con Azure NetApp Files en SUSE Linux Enterprise Server.
Configuración del kernel de Linux
Para implementar correctamente SAP HANA en Azure NetApp Files, se debe implementar correctamente la configuración del kernel de Linux según la nota de SAP 3024346.
En el caso de los sistemas que usan alta disponibilidad (HA) que emplean Pacemaker y Azure Load Balancer, es necesario implementar la siguiente configuración en el archivo /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Los sistemas que se ejecutan sin Pacemaker ni Azure Load Balancer deben implementar esta configuración en /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Implementación con proximidad zonal
Para obtener una proximidad zonal de los volúmenes y máquinas virtuales NFS, puede seguir las instrucciones que se describen en Administración de la Administración de la selección de ubicación del volumen de la zona de disponibilidad para Azure NetApp Files. Con este método, las máquinas virtuales y los volúmenes NFS estarán en la misma zona de disponibilidad de Azure. En la mayoría de las regiones de Azure, este tipo de proximidad debe ser suficiente para lograr una latencia inferior a 1 milisegundo para las escrituras de registro de puesta al día más pequeñas para SAP HANA. Este método no requiere ningún trabajo interactivo con Microsoft para colocar y anclar máquinas virtuales en un centro de datos específico. Como resultado, es flexible con el cambio de tamaños y familias de máquinas virtuales dentro de todos los tipos y familias de máquinas virtuales que se ofrecen en la zona de disponibilidad que implementó. Por lo tanto, puede reaccionar de manera flexible ante posibles cambios o pasar con mayor rapidez a tamaños o familias de máquinas virtuales más rentables. Se recomienda este método para sistemas que no son de producción y sistemas de producción que pueden trabajar con latencias de registro de puesta al día que están más cerca de 1 milisegundo. Actualmente, la versión de esta funcionalidad es una versión preliminar pública.
Implementación por el grupo de volúmenes de aplicación de Azure NetApp Files para SAP HANA (AVG)
Para implementar volúmenes Azure NetApp Files con proximidad a la máquina virtual, se ha desarrollado una nueva funcionalidad denominada grupo de volúmenes de aplicación de Azure NetApp Files para SAP HANA (AVG). Hay una serie de artículos que documentan la funcionalidad. Lo mejor es comenzar con el artículo Descripción del grupo de volúmenes de aplicación de Azure NetApp Files para SAP HANA. A medida que lea los artículos, queda claro que el uso de los AVG también implica el uso de grupos con ubicación por proximidad de Azure. La nueva funcionalidad usa los grupos con ubicación por proximidad para vincularse a los volúmenes que se crean. Para asegurarse de que durante la vigencia del sistema HANA las máquinas virtuales no se van a mover fuera de los volúmenes de Azure NetApp Files, se recomienda usar una combinación de Avset/PPG para cada una de las zonas en las que se implementa. El orden de implementación sería como el siguiente:
- Con el formulario, debe solicitar un anclaje del AvSet vacío a un hardware de proceso para asegurarse de que las máquinas virtuales no se van a mover.
- Asigne un PPG al conjunto de disponibilidad e inicie una máquina virtual asignada a este conjunto de disponibilidad.
- Use el grupo de volúmenes de aplicación de Azure NetApp Files para la funcionalidad SAP HANA para implementar los volúmenes de HANA.
La configuración del grupo con ubicación por proximidad para usar los AVG de una manera óptima tendría el siguiente aspecto:
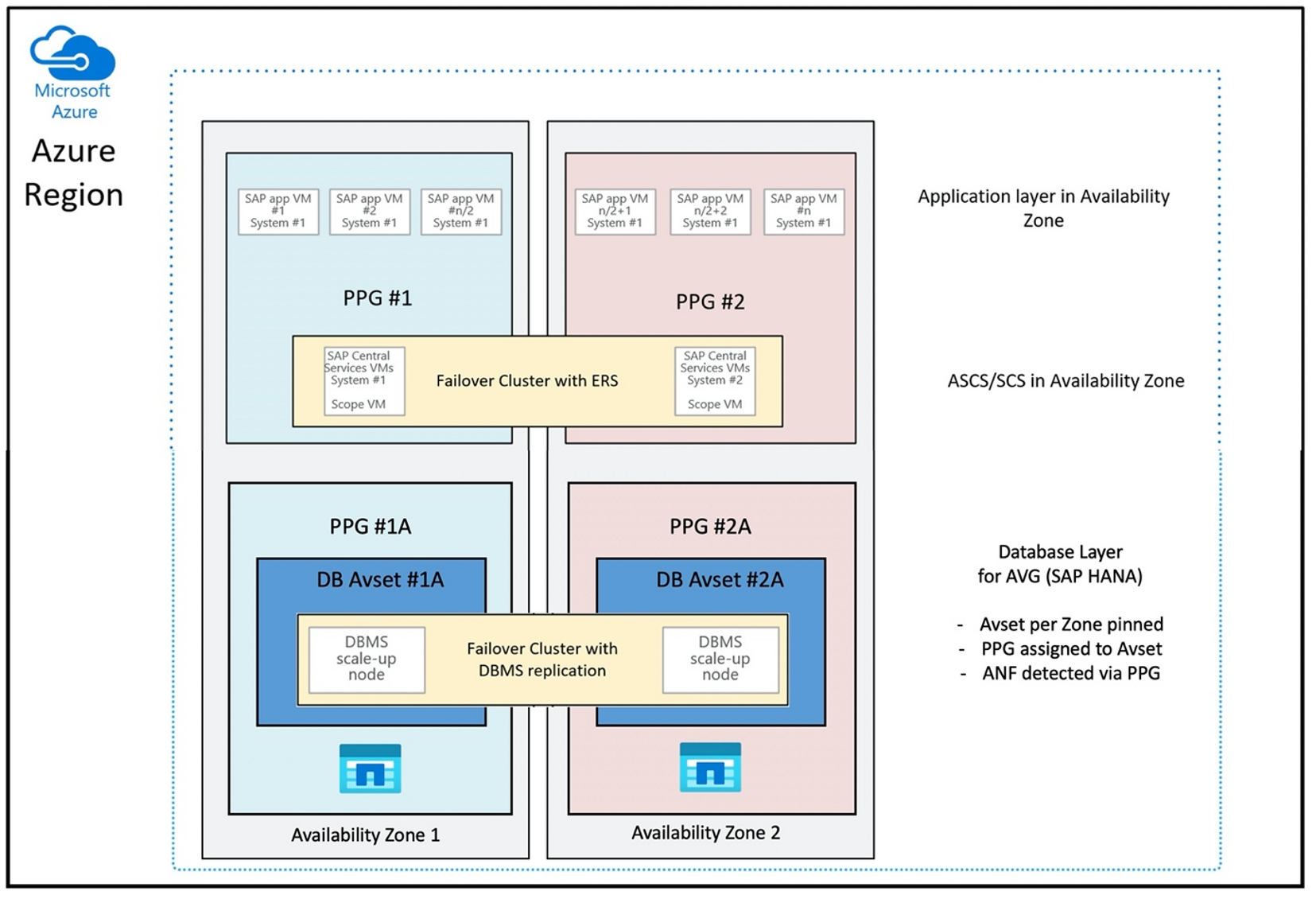
El diagrama muestra que va a usar un grupo con ubicación por proximidad de Azure para la capa de DBMS. Por lo tanto, se puede usar junto con los AVG. Es mejor incluir solo las máquinas virtuales que ejecutan las instancias de HANA en el grupo con ubicación por proximidad. El grupo con ubicación por proximidad es necesario, incluso si solo se usa una máquina virtual con una única instancia de HANA, para que el AVG identifique la proximidad más cercana del hardware de Azure NetApp Files. Y para asignar el volumen NFS en Azure NetApp Files lo más cerca posible de las máquinas virtuales que usan los volúmenes NFS.
Este método genera los resultados más óptimos en relación con la baja latencia, no solo al tener los volúmenes NFS y las máquinas virtuales lo más cerca posible, sino también al tener en cuenta las consideraciones sobre la colocación de los volúmenes de datos y registro de puesta al día en distintos controladores del back-end de NetApp. Sin embargo, la desventaja es que la implementación de la máquina virtual está anclada a un centro de datos. Con eso, está perdiendo flexibilidades en el cambio de tipos y familias de máquinas virtuales. Como resultado, debe limitar este método a los sistemas que requieren absolutamente una latencia de almacenamiento baja. Para todos los demás sistemas, debe intentar la implementación con una implementación zonal tradicional de la máquina virtual y Azure NetApp Files. En la mayoría de los casos, esto es suficiente en términos de baja latencia. Esto también garantiza un fácil mantenimiento y administración de la máquina virtual y Azure NetApp Files.
Disponibilidad
Las actualizaciones del sistema y las actualizaciones de ANF se aplican sin afectar al entorno del cliente. Se define un Acuerdo de nivel de servicio del 99,99 %.
Volúmenes, direcciones IP y grupos de capacidades
Con ANF, es importante comprender cómo se compila la infraestructura subyacente. Un grupo de capacidad es solo una construcción que proporciona un presupuesto de capacidad y rendimiento, y una unidad de facturación, en función del nivel de servicio del grupo de capacidad. Un grupo de capacidad no tiene ninguna relación física con la infraestructura subyacente. Al crear un volumen en el servicio, se crea un punto de conexión de almacenamiento. A este punto de conexión de almacenamiento se le asigna una única dirección IP para proporcionar acceso a los datos al volumen. Si crea varios volúmenes, todos ellos se distribuyen entre el conjunto subyacente de equipos sin sistema operativo, asociados a este punto de conexión de almacenamiento. ANF tiene una lógica que distribuye de forma automática las cargas de trabajo de los clientes cuando los volúmenes o la capacidad del almacenamiento configurado alcanzan un nivel interno predefinido. Es posible que observe estos casos al crearse automáticamente un nuevo punto de conexión de almacenamiento con una nueva dirección IP para acceder a los volúmenes. El servicio ANF no proporciona control al cliente sobre esta lógica de distribución.
Volumen de registro y volumen de copia de seguridad de registros
El "volumen de registro" ( /hana/log) se usa para escribir el registro de la fase de puesta al día en línea. Por lo tanto, hay archivos abiertos ubicados en este volumen y no tiene sentido crear una instantánea del mismo. Los archivos de registro en línea de la fase de puesta al día se archivan, o se hace una copia de seguridad de estos, en el volumen de copia de seguridad de registros cuando el archivo de registro en línea de la fase de puesta al día está completo o se ejecuta una copia de seguridad de registros de la fase de puesta al día. Para proporcionar un rendimiento de copia de seguridad razonable, el volumen de copia de seguridad de registros requiere un buen rendimiento. Para optimizar los costos de almacenamiento, puede tener sentido consolidar el volumen de copia de seguridad de registros de varias instancias de HANA. Así, varias instancias de HANA usan el mismo volumen y escriben sus copias de seguridad en directorios diferentes. Con este tipo de consolidación, se puede obtener más rendimiento, ya que es necesario aumentar ligeramente el tamaño del volumen.
Esto mismo se aplica al volumen que se usa para escribir copias de seguridad completas de bases de datos de HANA.
Copia de seguridad
Además de las copias de seguridad de streaming y el servicio Azure Backup, que realiza copias de seguridad de bases de datos de SAP HANA, tal como se describe en el artículo Guía de copia de seguridad de SAP HANA en Azure Virtual Machines, Azure NetApp Files permite realizar copias de seguridad de instantáneas basadas en almacenamiento.
SAP HANA admite lo siguiente:
- Compatibilidad de la copia de seguridad de instantáneas basadas en almacenamiento con sistemas de contenedor único con SAP HANA 1.0 SPS7 y versiones superiores
- Compatibilidad de la copia de seguridad de instantáneas basada en almacenamiento con entornos HANA de varios contenedores de bases de datos (MDC) con un único inquilino con SAP HANA 2.0 SPS1 y versiones posteriores.
- Compatibilidad de la copia de seguridad de instantáneas basada en almacenamiento con entornos HANA de varios contenedores de bases de datos (MDC) con varios inquilinos con SAP HANA 2.0 SPS4 y versiones posteriores.
La creación de copias de seguridad de instantáneas basadas en almacenamiento es un procedimiento sencillo que consta de cuatro pasos:
- Creación de una instantánea de base de datos de HANA (interna): una actividad que debe realizar por su cuenta o mediante herramientas.
- SAP HANA escribe datos en los archivos de datos para crear un estado coherente en el almacenamiento: HANA realiza este paso como resultado de la creación de una instantánea de HANA.
- Creación de una instantánea en el volumen /hana/data volumen en el almacenamiento: un paso que debe realizar por su cuenta o mediante herramientas. No es necesario realizar una instantánea en el volumen /hana/log.
- Eliminación de la instantánea de base de datos de HANA (interna) y reanudación del funcionamiento normal: un paso que debe realizar por su cuenta o mediante herramientas.
Advertencia
En caso de que falte el último paso o este no se pueda realizar, se producirá un impacto grave en la demanda de memoria de SAP HANA y podrá provocar una detención de SAP HANA.
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Este procedimiento de copia de seguridad de instantáneas se puede administrar de varias maneras y con distintas herramientas. Un ejemplo es el script de Python "ntaphana_azure.py" disponible en GitHub https://github.com/netapp/ntaphana. Este es un código de ejemplo proporcionado "tal cual" sin necesidad de mantenimiento ni soporte técnico.
Precaución
Una instantánea en sí misma no es una copia de seguridad protegida, ya que se encuentra en el mismo almacenamiento físico que el volumen del que se ha tomado una instantánea. Es obligatorio "proteger" al menos una instantánea por día en otra ubicación. Esto puede hacerse en el mismo entorno, en una región de Azure remota o en almacenamiento de blobs de Azure.
Soluciones disponibles para la copia de seguridad coherente con la aplicación basada en instantáneas de almacenamiento:
- ¿Qué es la herramienta Azure Application Consistent Snapshot? de Microsoft es una herramienta de línea de comandos que habilita la protección de datos para bases de datos de terceros. Controla toda la orquestación necesaria para colocar las bases de datos en un estado coherente con la aplicación antes de tomar una instantánea de almacenamiento. Una vez realizada la instantánea de almacenamiento, la herramienta devuelve las bases de datos a un estado operativo. AzAcSnap admite copias de seguridad basadas en instantáneas para HANA (instancias grandes), así como Azure NetApp Files. Consulte el artículo ¿Qué es la herramienta Azure Application Consistent Snapshot? para obtener más información
- En el caso de los usuarios de productos de copia de seguridad de Commvault, otra opción es Commvault IntelliSnap V.11.21 y versiones posteriores. Esta versión de Commvault y las posteriores ofrecen compatibilidad con instantáneas de Azure NetApp Files. En el artículo CommVault IntelliSnap 11.21 se proporciona más información.
Copia de seguridad de la instantánea mediante almacenamiento de blobs de Azure
La realización de una copia de seguridad en el almacenamiento de blobs de Azure es un método rápido y rentable para guardar copias de seguridad de instantáneas de almacenamiento de base de datos de HANA basadas en ANF. Para guardar las instantáneas en el almacenamiento de blobs de Azure, es preferible usar la herramienta AzCopy. Descargue la versión más reciente de esta herramienta e instálela. Por ejemplo, en el directorio bin donde esté instalado el script de Python de GitHub. Descargue la versión más reciente de la herramienta AzCopy:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
La característica más avanzada es la opción SYNC. Si se usa la opción SYNC, azcopy mantiene sincronizado el directorio de origen y el de destino. El uso del parámetro --delete-destination es importante. Sin este parámetro, azcopy no elimina los archivos del sitio de destino y el uso de espacio en el lado de destino aumentaría. Cree un contenedor de Blob en bloques en una cuenta de almacenamiento de Azure. Después, cree la clave SAS para el contenedor de blobs y sincronice la carpeta de instantáneas con el contenedor de blobs de Azure.
Por ejemplo, si se debe sincronizar una instantánea diaria con el contenedor de blobs de Azure para proteger los datos y solo se debe conservar una instantánea, se puede usar el comando siguiente.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Pasos siguientes
Lea el artículo: