Alta disponibilidad de IBM Db2 LUW en máquinas virtuales de Azure en Red Hat Enterprise Linux Server
IBM Db2 para Linux, UNIX y Windows (LUW) en la configuración de alta disponibilidad y recuperación ante desastres (HADR) consta de un nodo que ejecuta una instancia de base de datos principal y al menos un nodo que ejecuta una instancia de base de datos secundaria. Los cambios realizados en la instancia de base de datos principal se replican en una instancia de base de datos secundaria de manera sincrónica o asincrónica, según la configuración.
Nota:
Este artículo contiene referencias a términos que Microsoft ya no utiliza. Cuando se eliminen estos términos del software, se eliminarán de este artículo.
En este artículo se describe cómo implementar y configurar las máquinas virtuales (VM) de Azure, instalar el marco del clúster e instalar IBM Db2 LUW con configuración de HADR.
En el artículo no se describe cómo instalar y configurar IBM Db2 LUW con HADR o la instalación de software SAP. Para ayudarle a hacer estas tareas, proporcionamos referencias a los manuales de instalación de SAP e IBM. En este artículo nos centramos en los elementos que son específicos para el entorno de Azure.
Las versiones de IBM Db2 admitidas son 10.5 y posteriores, tal como se documenta en la nota de SAP 1928533.
Antes de comenzar una instalación, consulte la documentación y notas SAP siguientes:
| Nota de SAP | Descripción |
|---|---|
| 1928533 | SAP applications on Azure: Supported Products and Azure VM types (Nota de SAP 1928533: Aplicaciones SAP en Azure: productos admitidos y tipos de máquina virtual de Azure) |
| 2015553 | SAP en Azure: Support Prerequisites (Nota de soporte técnico 2015553 de SAP en Microsoft Azure: requisitos previos de soporte técnico) |
| 2178632 | Key monitoring metrics for SAP on Azure (Métricas de supervisión clave para SAP en Azure) |
| 2191498 | SAP on Linux with Azure: Enhanced Monitoring (SAP en Linux con Azure: supervisión mejorada) |
| 2243692 | Linux on Azure (IaaS) VM: SAP license issues (Linux y máquinas virtuales de Microsoft Azure (IaaS): problemas de licencia de SAP) |
| 2002167 | Red Hat Enterprise Linux 7.x: Instalación y actualización |
| 2694118 | Complemento de alta disponibilidad de Red Hat Enterprise Linux en Azure |
| 1999351 | Troubleshooting Enhanced Azure Monitoring for SAP (Solución de problemas de la supervisión mejorada de Azure para SAP) |
| 2233094 | DB6: SAP applications on Azure that use IBM Db2 for Linux, UNIX, and Windows - additional information (DB6: aplicaciones de SAP en Azure con IBM Db2 para Linux, UNIX y Windows: información adicional) |
| 1612105 | DB6: FAQ on Db2 with HADR (Preguntas más frecuentes sobre Db2 con HADR) |
Información general
Para lograr alta disponibilidad, IBM Db2 LUW con HADR se instala en al menos dos máquinas virtuales de Azure, que se implementan en un conjunto de escalado de máquinas virtuales con orquestación flexible entre zonas de disponibilidad o en un conjunto de disponibilidad.
En los gráficos siguientes se muestra una configuración de dos VM de Azure de servidor de base de datos. Ambas máquinas virtuales de Azure de servidor de base de datos tienen su propio almacenamiento conectado y están en funcionamiento. En HADR, una instancia de base de datos en una de las máquinas virtuales de Azure tiene el rol de la instancia principal. Todos los clientes están conectados a la instancia principal. Todos los cambios en las transacciones de base de datos se almacenan localmente en el registro de transacciones de Db2. Dado que las entradas del registro de transacciones se almacenan localmente, los registros se transfieren a través de TCP/IP a la instancia de base de datos en el segundo servidor de base de datos, el servidor en espera o la instancia en espera. La instancia en espera actualiza la base de datos local al poner al día las entradas del registro de transacciones. De este modo, el servidor en espera se mantiene sincronizado con el servidor principal.
HADR es solo una funcionalidad de replicación. No tiene detección de errores ni capacidades de toma de control o conmutación por error. Una toma de control o transferencia al servidor en espera lo debe iniciar manualmente un administrador de base de datos. Para lograr una toma de control y detección de errores automáticas, puede usar la característica de agrupación en clústeres de Linux Pacemaker. Pacemaker supervisa las dos instancias de servidor de bases de datos. Cuando se bloquea la instancia del servidor de base de datos principal, Pacemaker inicia una toma de control de HADR automática por el servidor en espera. Pacemaker también garantiza que la dirección IP virtual se asigna al nuevo servidor principal.
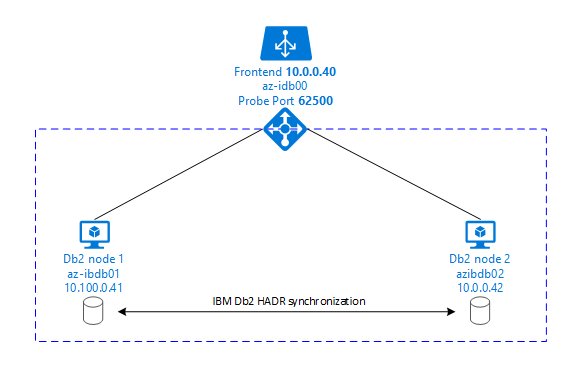
Para que los servidores de aplicaciones de SAP se conecten a la base de datos principal, se necesita un nombre de host virtual y una dirección IP virtual. Después de una conmutación por error, los servidores de aplicaciones SAP se conectarán a la nueva instancia de base de datos principal. En un entorno de Azure, se necesita Azure Load Balancer para usar una dirección IP virtual de la manera en que se necesita para HADR de IBM Db2.
Para ayudarle a comprender por completo cómo IBM Db2 LUW con HADR y Pacemaker se incorporan a una configuración de sistema SAP de alta disponibilidad, en la imagen siguiente se presenta una visión general de una configuración de alta disponibilidad de un sistema SAP basado en la base de datos IBM Db2. En este artículo solo se cubre IBM Db2, pero se proporcionan referencias a otros artículos sobre cómo configurar otros componentes de un sistema SAP.
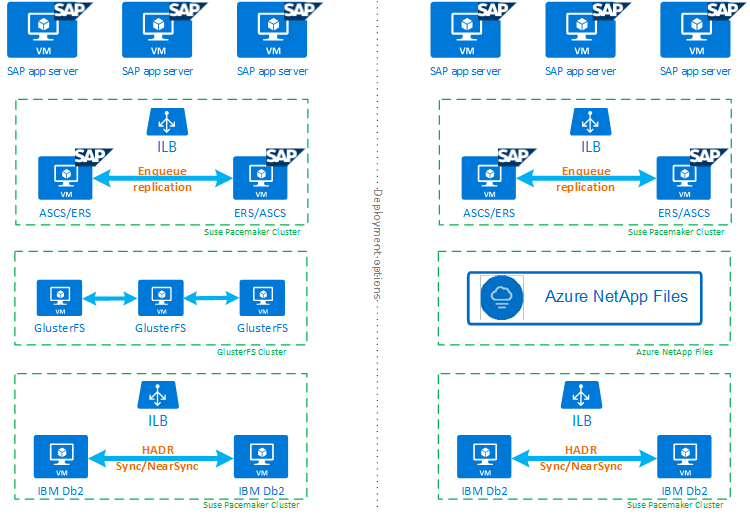
Introducción de alto nivel de los pasos necesarios
Para implementar una configuración de IBM Db2, deberá seguir estos pasos:
- Planificar el entorno.
- Implemente las VM.
- Actualizar RHEL Linux y configurar los sistemas de archivos.
- Instalar y configurar Pacemaker.
- Configurar el clúster de GlusterFS o Azure NetApp Files.
- Instalar ASCS/ERS en un clúster independiente.
- Instalar la base de datos de IBM Db2 con la opción Distributed/High Availability (Distribuida/alta disponibilidad) (SWPM).
- Instalar y crear un nodo y una instancia de base de datos secundarios y configurar HADR.
- Confirmar que HADR funciona.
- Aplicar la configuración de Pacemaker para controlar IBM Db2.
- Configurar Azure Load Balancer.
- Instalar los servidores de aplicaciones principal y de diálogo.
- Comprobar y adaptar la configuración de los servidores de aplicaciones SAP.
- Realizar pruebas de toma de control y conmutación por error.
Planificar la infraestructura de Azure para hospedar IBM Db2 LUW con HADR
Complete el proceso de planificación antes de ejecutar la implementación. La planificación crea la base para la implementación de una configuración de Db2 con HADR en Azure. En la tabla siguiente se indican los elementos clave que deben formar parte de la planificación de IBM Db2 LUW (parte de la base de datos del entorno SAP):
| Tema | Descripción breve |
|---|---|
| Definir los grupos de recursos de Azure | Los grupos de recursos donde se implementa la máquina virtual, la red virtual, Azure Load Balancer y otros recursos. Puede ser nuevo o existente. |
| Definición de red virtual o subred | Donde se implementan las VM para IBM Db2 y Azure Load Balancer. Puede ser existente o recién creado. |
| Máquinas virtuales que hospedan IBM Db2 LUW | Tamaño de VM, almacenamiento, redes, dirección IP. |
| Nombre de host virtual y dirección IP virtual de la base de datos IBM Db2 | La dirección IP virtual o nombre de host que se usa para la conexión de servidores de aplicaciones SAP. db-virt-hostname, db-virt-ip. |
| Barreras de Azure | Método para evitar situaciones de cerebro dividido. |
| Azure Load Balancer | Uso de la versión Estándar (recomendada), puerto de sondeo para la base de datos Db2 (nuestra recomendación 62500) probe-port. |
| Resolución de nombres | Funcionamiento de la resolución de nombres en el entorno. Se recomienda el servicio DNS. Se puede usar el archivo de host local. |
Para más información sobre Linux Pacemaker en Azure, consulte Configuración de Pacemaker en Red Hat Enterprise Linux en Azure.
Importante
Para la versión 11.5.6 u otras posteriores de Db2, se recomienda encarecidamente la solución integrada mediante Pacemaker de IBM.
Implementación en Red Hat Enterprise Linux
El agente de recursos de IBM Db2 LUW se incluye en el complemento de alta disponibilidad de Red Hat Enterprise Linux Server. Para realizar la configuración que se describe en este documento, debe usar Red Hat Enterprise Linux para SAP. Azure Marketplace contiene una imagen de Red Hat Enterprise Linux 7.4 para SAP o versiones superiores que puede usar para implementar nuevas máquinas virtuales de Azure. Tenga en cuenta los distintos modelos de soporte técnico o servicio que ofrece Red Hat mediante Azure Marketplace al elegir una imagen de máquina virtual en el catálogo de máquinas virtuales de Azure.
Hosts: Actualizaciones del servicio de nombres de dominio
Haga una lista de todos los nombres de host, incluidos los nombres de host virtual, y actualice los servidores DNS para habilitar la resolución correcta de dirección IP y nombres de host. Si un servidor DNS no existe o no se pueden actualizar y crear entradas DNS, deberá usar los archivos de host local de las VM individuales que forman parte de este escenario. Si usa entradas de archivos de host, asegúrese de que las entradas se apliquen a todas las VM del entorno de sistema SAP. Sin embargo, recomendamos que use el DNS que, idealmente, se extiende a Azure.
Implementación manual
Asegúrese de que el SO seleccionado sea compatible con IBM/SAP para IBM Db2 LUW. La lista de versiones de SO admitidas para máquinas virtuales de Azure y las versiones de Db2 está disponible en la nota de SAP 1928533. La lista de las versiones de SO por versión de Db2 individual está disponible en la matriz de disponibilidad de productos de SAP. Se recomienda como mínimo Red Hat Enterprise Linux 7.4 para SAP por las mejoras de rendimiento relacionadas con Azure que se incluyen en esta versión y en las siguientes.
- Cree o seleccione un grupo de recursos.
- Cree o seleccione una red virtual y subred.
- Elija un tipo de implementación adecuado para las máquinas virtuales de SAP. Por lo general, un conjunto de escalado de máquinas virtuales con orquestación flexible.
- Cree la máquina Virtual 1.
- Use la imagen de Red Hat Enterprise Linux para SAP de Azure Marketplace.
- Seleccione el conjunto de escalado, la zona de disponibilidad o el conjunto de disponibilidad creados en el paso 3.
- Cree la máquina Virtual 2.
- Use la imagen de Red Hat Enterprise Linux para SAP de Azure Marketplace.
- Seleccione el conjunto de escalado, la zona de disponibilidad o el conjunto de disponibilidad creados en el paso 3 (no la misma zona que seleccionó en el paso 4).
- Agregue discos de datos a las VM y luego compruebe la recomendación de una configuración de sistema de archivos disponible en el artículo Implementación de DBMS de Azure Virtual Machines de IBM Db2 para carga de trabajo de SAP.
Instalar el entorno de SAP y IBM Db2 LUW
Antes de comenzar la instalación de un entorno SAP basado en IBM Db2 LUW, consulte la siguiente documentación:
- Documentación de Azure.
- Documentación de SAP.
- Documentación de IBM.
En la sección de introducción de este artículo se proporcionan vínculos a esta documentación.
Consulte los manuales de instalación de SAP sobre la instalación de aplicaciones basadas en NetWeaver en IBM Db2 LUW. Encontrará las guías en el portal de ayuda de SAP mediante el buscador de guías de instalación de SAP.
Puede reducir el número de guías que se muestran en el portal al establecer los siguientes filtros:
- Deseo: Instalar un nuevo sistema.
- Mi base de datos: IBM Db2 para Linux, Unix y Windows.
- Filtros adicionales para las versiones de SAP NetWeaver, configuración de la pila o sistema operativo.
Reglas de firewall de Red Hat
Red Hat Enterprise Linux tiene un firewall habilitado de forma predeterminada.
#Allow access to SWPM tool. Rule is not permanent.
sudo firewall-cmd --add-port=4237/tcp
Sugerencias de instalación para la configuración de IBM Db2 LUW con HADR
Para configurar la instancia de base de datos de IBM Db2 LUW principal:
- Use la opción distribuida o de alta disponibilidad.
- Instale la instancia de SAP ASCS/ERS y base de datos.
- Realice una copia de seguridad de la base de datos recién instalada.
Importante
Anote el "puerto de comunicación de la base de datos" que se establece durante la instalación. El número de puerto debe ser el mismo para ambas instancias de base de datos.
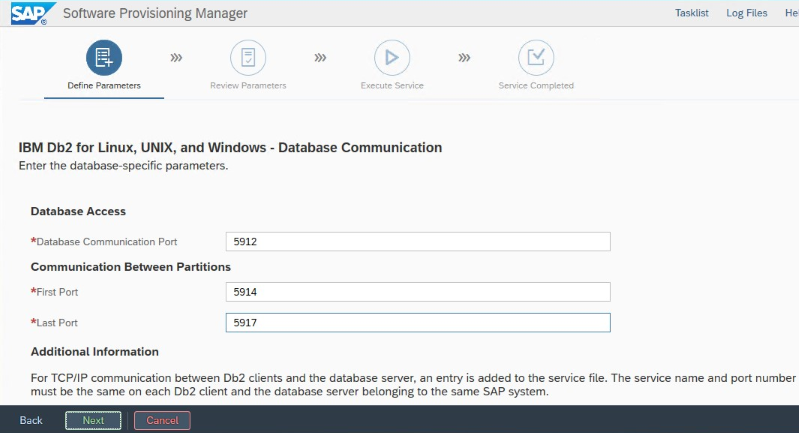
Configuración de HADR de IBM Db2 para Azure
Cuando usa un agente de barrera de Azure Pacemaker, establezca los parámetros siguientes:
- Duración de la ventana del mismo nivel de HADR (segundos) (HADR_PEER_WINDOW) = 240
- Valor de tiempo de espera de HADR (HADR_TIMEOUT) = 45
Recomendamos los parámetros anteriores según las pruebas iniciales de conmutación por error o toma de control. Es obligatorio hacer pruebas del correcto funcionamiento de la conmutación por error y toma de control con estos valores de parámetro. Dado que las configuraciones individuales pueden variar, es posible que los parámetros necesiten ajuste.
Nota
Específico de IBM Db2 con la configuración de HADR con inicio normal: antes de poder iniciar la instancia de base de datos principal, debe estar en marcha la instancia de base de datos secundario o en espera.
Nota
Para la instalación y configuración específicas de Azure y Pacemaker: Durante el procedimiento de instalación a través de SAP Software Provisioning Manager, hay una pregunta sobre la alta disponibilidad para IBM Db2 LUW:
- No seleccione IBM Db2 pureScale.
- No seleccione Install IBM Tivoli System Automation for Multiplatforms (Instalar IBM Tivoli System Automation para multiplataformas).
- No seleccione Generate cluster configuration files (Generar archivos de configuración de clúster).
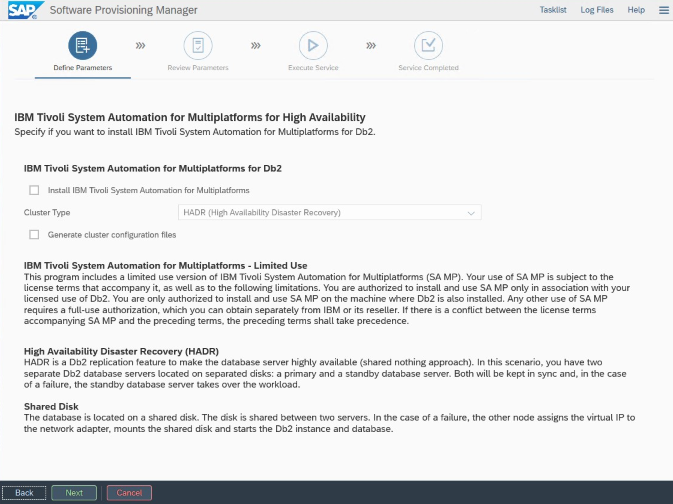
Para configurar el servidor de base de datos en espera mediante el procedimiento de copia del sistema homogéneo de SAP, ejecute estos pasos:
- Seleccione la opción Copia del sistema>Sistemas de destino>Distribuida>Instancia de base de datos.
- Como método de copia, seleccione Homogeneous System (Sistema homogéneo) para que pueda usar la copia de seguridad para restaurar una copia de seguridad en la instancia de servidor en espera.
- Cuando llegue al paso de salida para restaurar la base de datos para la copia del sistema homogéneo, cierre el instalador. Restaure la base de datos a partir de una copia de seguridad del host principal. Todas las fases de instalación posteriores se han ejecutado en el servidor de base de datos principal.
Reglas de firewall de Red Hat para DB2 HADR
Agregue reglas de firewall para permitir que funcione el tráfico a DB2 y entre DB2 para HADR:
- Puerto de comunicación de base de datos. Si usa particiones, agregue también esos puertos.
- Puerto HADR (valor del parámetro HADR_LOCAL_SVC de DB2).
- Puerto de sondeo de Azure.
sudo firewall-cmd --add-port=<port>/tcp --permanent
sudo firewall-cmd --reload
Comprobación de HADR de IBM Db2
Con fines de demostración y para los procedimientos que se describen en este artículo, la base de datos SID es ID2.
Tras haber configurado HADR y el estado es PEER y CONNECTED en los nodos principal y en espera, realice la comprobación siguiente:
Execute command as db2<sid> db2pd -hadr -db <SID>
#Primary output:
Database Member 0 -- Database ID2 -- Active -- Up 1 days 15:45:23 -- Date 2019-06-25-10.55.25.349375
HADR_ROLE = PRIMARY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 1
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.076494 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 5
HEARTBEAT_EXPECTED = 52
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 5
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 369280
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 132242668
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 300
PEER_WINDOW_END = 06/25/2019 11:12:03.000000 (1561461123)
READS_ON_STANDBY_ENABLED = N
#Secondary output:
Database Member 0 -- Database ID2 -- Standby -- Up 1 days 15:45:18 -- Date 2019-06-25-10.56.19.820474
HADR_ROLE = STANDBY
REPLAY_TYPE = PHYSICAL
HADR_SYNCMODE = NEARSYNC
STANDBY_ID = 0
LOG_STREAM_ID = 0
HADR_STATE = PEER
HADR_FLAGS =
PRIMARY_MEMBER_HOST = az-idb01
PRIMARY_INSTANCE = db2id2
PRIMARY_MEMBER = 0
STANDBY_MEMBER_HOST = az-idb02
STANDBY_INSTANCE = db2id2
STANDBY_MEMBER = 0
HADR_CONNECT_STATUS = CONNECTED
HADR_CONNECT_STATUS_TIME = 06/25/2019 10:55:05.078116 (1561460105)
HEARTBEAT_INTERVAL(seconds) = 7
HEARTBEAT_MISSED = 0
HEARTBEAT_EXPECTED = 10
HADR_TIMEOUT(seconds) = 30
TIME_SINCE_LAST_RECV(seconds) = 1
PEER_WAIT_LIMIT(seconds) = 0
LOG_HADR_WAIT_CUR(seconds) = 0.000
LOG_HADR_WAIT_RECENT_AVG(seconds) = 598.000027
LOG_HADR_WAIT_ACCUMULATED(seconds) = 598.000
LOG_HADR_WAIT_COUNT = 1
SOCK_SEND_BUF_REQUESTED,ACTUAL(bytes) = 0, 46080
SOCK_RECV_BUF_REQUESTED,ACTUAL(bytes) = 0, 367360
PRIMARY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
HADR_LOG_GAP(bytes) = 0
STANDBY_REPLAY_LOG_FILE,PAGE,POS = S0000012.LOG, 14151, 3685322855
STANDBY_RECV_REPLAY_GAP(bytes) = 0
PRIMARY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_REPLAY_LOG_TIME = 06/25/2019 10:45:42.000000 (1561459542)
STANDBY_RECV_BUF_SIZE(pages) = 2048
STANDBY_RECV_BUF_PERCENT = 0
STANDBY_SPOOL_LIMIT(pages) = 1000
STANDBY_SPOOL_PERCENT = 0
STANDBY_ERROR_TIME = NULL
PEER_WINDOW(seconds) = 1000
PEER_WINDOW_END = 06/25/2019 11:12:59.000000 (1561461179)
READS_ON_STANDBY_ENABLED = N
Configuración de Azure Load Balancer
Durante la configuración de la máquina virtual, tiene una opción para crear o seleccionar salir del equilibrador de carga en la sección de redes. Siga estos pasos para configurar el equilibrador de carga estándar para la configuración de alta disponibilidad de la base de datos DB2.
Siga los pasos descritos en Creación de un equilibrador de carga para configurar un equilibrador de carga estándar para un sistema SAP de alta disponibilidad mediante Azure Portal. Durante la configuración del equilibrador de carga, tenga en cuenta los siguientes puntos:
- Configuración de IP de front-end: cree una dirección IP de front-end. Seleccione el mismo nombre de red virtual y subred que las máquinas virtuales de la base de datos.
- Grupo de back-end: cree un grupo de back-end y agregue máquinas virtuales de base de datos.
- Reglas de entrada: cree una regla de equilibrio de carga. Siga los mismos pasos para ambas reglas de equilibrio de carga.
- Dirección IP de front-end: seleccione una dirección IP de front-end.
- Grupo de back-end: seleccione un grupo de back-end.
- Puertos de alta disponibilidad: seleccione esta opción.
- Protocolo: seleccione TCP.
- Sondeo de estado: cree un sondeo de estado con los detalles siguientes:
- Protocolo: seleccione TCP.
- Puerto: por ejemplo, 625<instance-no.>.
- Intervalo: escriba 5.
- Umbral de sondeo: escriba 2.
- Tiempo de espera de inactividad (minutos): Escriba 30.
- Habilitar IP flotante: seleccione esta opción.
Nota:
No se respeta la propiedad de configuración del sondeo de estado numberOfProbes, también conocida como Umbral incorrecto en el portal. Para controlar el número de sondeos consecutivos correctos o erróneos, establezca la propiedad probeThreshold en 2. Actualmente, no es posible establecer esta propiedad mediante Azure Portal, por lo que debe usar la CLI de Azure o el comando de PowerShell.
Nota:
Cuando las máquinas virtuales sin direcciones IP públicas se colocan en el grupo de back-end de una instancia interna (sin dirección IP pública) de Azure Standard Load Balancer, no hay conectividad saliente a Internet, a menos que se realice una configuración adicional para permitir el enrutamiento a puntos de conexión públicos. Para obtener más información sobre cómo conseguir la conectividad saliente, consulte Conectividad de punto de conexión público para máquinas virtuales con Azure Standard Load Balancer en escenarios de alta disponibilidad de SAP.
Importante
No habilite las marcas de tiempo TCP en VM de Azure que se encuentren detrás de Azure Load Balancer. La habilitación de las marcas de tiempo de TCP podría provocar un error en los sondeos de estado. Establezca el parámetro net.ipv4.tcp_timestamps en 0. Para más información, consulte Sondeos de estado de Load Balancer.
[A] Agregue la regla de firewall para el puerto de sondeo:
sudo firewall-cmd --add-port=<probe-port>/tcp --permanent
sudo firewall-cmd --reload
Implementar un clúster de Pacemaker
Para crear un clúster básico de Pacemaker para este servidor IBM Db2, consulte Configuración de Pacemaker en Red Hat Enterprise Linux en Azure.
Configuración de Db2 Pacemaker
Cuando usa Pacemaker la conmutación por error automática en el caso de que haya un error en el nodo, deberá configurar las instancias de Db2 y Pacemaker, según corresponda. En esta sección se describe este tipo de configuración.
Los siguientes elementos tienen los siguiente prefijos:
- [A] : Aplicable a todos los nodos
- [1] : Aplicable solo al nodo 1
- [2] : Aplicable solo al nodo 2
[A] Requisito previo para la configuración de Pacemaker:
Apague ambos servidores de base de datos con user db2<sid> con db2stop.
Cambie el entorno de shell para el usuario db2<sid> por /bin/ksh:
# Install korn shell: sudo yum install ksh # Change users shell: sudo usermod -s /bin/ksh db2<sid>
Configuración de pacemaker
[1] Configuración de Pacemaker específico de HADR para IBM Db2:
# Put Pacemaker into maintenance mode sudo pcs property set maintenance-mode=true[1] Crear los recursos de IBM Db2:
Si crea un clúster en RHEL 7.x, asegúrese de actualizar los agentes de recursos del paquete a la versión
resource-agents-4.1.1-61.el7_9.15o posterior. Use los siguientes comandos para crear los recursos del clúster:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' master meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-master meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-master #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-master then g_ipnc_db2id2_ID2Si crea un clúster en RHEL 8.x, asegúrese de actualizar los agentes de recursos del paquete a la versión
resource-agents-4.1.1-93.el8o posterior. Para obtener más información, consulte la KBA de Red Hat Un recursodb2con HADR genera un error en la promoción con el estadoPRIMARY/REMOTE_CATCHUP_PENDING/CONNECTED. Use los siguientes comandos para crear los recursos del clúster:# Replace bold strings with your instance name db2sid, database SID, and virtual IP address/Azure Load Balancer. sudo pcs resource create Db2_HADR_ID2 db2 instance='db2id2' dblist='ID2' promotable meta notify=true resource-stickiness=5000 #Configure resource stickiness and correct cluster notifications for master resoruce sudo pcs resource update Db2_HADR_ID2-clone meta notify=true resource-stickiness=5000 # Configure virtual IP - same as Azure Load Balancer IP sudo pcs resource create vip_db2id2_ID2 IPaddr2 ip='10.100.0.40' # Configure probe port for Azure load Balancer sudo pcs resource create nc_db2id2_ID2 azure-lb port=62500 #Create a group for ip and Azure loadbalancer probe port sudo pcs resource group add g_ipnc_db2id2_ID2 vip_db2id2_ID2 nc_db2id2_ID2 #Create colocation constrain - keep Db2 HADR Master and Group on same node sudo pcs constraint colocation add g_ipnc_db2id2_ID2 with master Db2_HADR_ID2-clone #Create start order constrain sudo pcs constraint order promote Db2_HADR_ID2-clone then g_ipnc_db2id2_ID2[1] Iniciar los recursos de IBM Db2:
Saque Pacemaker del modo de mantenimiento.
# Put Pacemaker out of maintenance-mode - that start IBM Db2 sudo pcs property set maintenance-mode=false[1] Asegúrese de que el estado del clúster sea correcto y que todos los recursos se hayan iniciado. No importa en qué nodo se ejecutan en los recursos.
sudo pcs status 2 nodes configured 5 resources configured Online: [ az-idb01 az-idb02 ] Full list of resources: rsc_st_azure (stonith:fence_azure_arm): Started az-idb01 Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2] Masters: [ az-idb01 ] Slaves: [ az-idb02 ] Resource Group: g_ipnc_db2id2_ID2 vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01 nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Importante
Debe administrar la instancia de DB2 en clústeres de Pacemaker mediante las herramientas de Pacemaker. Si usa comandos de db2, como db2stop, Pacemaker detecta la acción como un error de recurso. Si va a realizar mantenimiento, puede colocar los nodos en modo de mantenimiento. Pacemaker suspende la supervisión de recursos y luego se pueden usar los comandos de administración normal de db2.
Hacer cambios en los perfiles de SAP para usar la dirección IP virtual para la conexión
Para conectarse a la instancia principal de la configuración de HADR, el nivel de aplicación de SAP debe usar la dirección IP virtual que definió y configuró para Azure Load Balancer. Se requieren los siguientes cambios:
/sapmnt/<SID>/profile/DEFAULT.PFL
SAPDBHOST = db-virt-hostname
j2ee/dbhost = db-virt-hostname
/sapmnt/<SID>/global/db6/db2cli.ini
Hostname=db-virt-hostname
Instalar los servidores de aplicaciones principal y de diálogo
Al instalar servidores de aplicaciones principal y de diálogo con una configuración de HADR de Db2, use el nombre de host virtual que eligió para la configuración.
Si realizó la instalación antes de haber creado la configuración de HADR de Db2, realice los cambios según se describe en la sección anterior y del modo siguiente para pilas de Java de SAP.
Comprobación URL de JDBC para sistemas de pila de ABAP+Java o Java
Use la herramienta de configuración de J2EE para comprobar o actualizar la dirección URL de JDBC. Dado que la herramienta de configuración de J2EE es una herramienta gráfica, deberá tener X server instalado:
Inicie sesión en el servidor de aplicaciones principal de la instancia de J2EE y ejecute lo siguiente:
sudo /usr/sap/*SID*/*Instance*/j2ee/configtool/configtool.shEn el marco de la izquierda, seleccione security store.
En el marco de la derecha, elija la clave
jdbc/pool/\<SAPSID>/url.Cambie el nombre de host de la dirección URL de JDBC al nombre de host virtual.
jdbc:db2://db-virt-hostname:5912/TSP:deferPrepares=0Seleccione Agregar.
Para guardar los cambios, seleccione el icono de disco de la parte superior izquierda.
Cierre la herramienta de configuración.
Reinicie la instancia de Java.
Configurar el archivado de registros para la configuración de HADR
Para configurar el archivado de registros de Db2 para la configuración de HADR, recomendamos que configure tanto la base de datos principal como la base de datos en espera de modo que tengan capacidad de recuperación automático de registros de todas las ubicaciones de archivo de registro. Tanto la base de datos principal y como la base de datos en espera deben poder recuperar los archivos de registro de todas las ubicaciones de archivos de registro en las que cualquiera de las instancias de base de datos podría archivar este tipo de archivo.
El archivado de registros solo lo realiza la base de datos principal. Si cambia los roles de HADR de los servidores de base de datos o si se produce un error, la nueva base de datos principal es responsable del archivado de registros. Si ha configurado varias ubicaciones de archivo de registro, es posible que los registros se archiven dos veces. Si se produce una actualización local o remota, también es posible que tenga que copiar manualmente los registros archivados desde el servidor principal anterior a la ubicación de registros activa del nuevo servidor principal.
Se recomienda configurar un recurso compartido de NFS común o GlusterFS, donde se escriben registros de ambos nodos. El recurso compartido de NFS o GlusterFS debe tener una alta disponibilidad.
Puede usar recursos compartidos de NFS de alta disponibilidad ya existentes o GlusterFS para los transportes o un directorio de perfiles. Para más información, consulte:
- GlusterFS en máquinas virtuales de Azure de Red Hat Enterprise Linux para SAP NetWeaver.
- Alta disponibilidad para SAP NetWeaver en máquinas virtuales de Azure en Red Hat Enterprise Linux con Azure NetApp Files para aplicaciones SAP.
- Azure NetApp Files (para crear recursos compartidos de NFS).
Prueba de la configuración del clúster
En esta sección se describe cómo se puede probar la configuración de HADR de Db2. En cada prueba se supone que el servidor principal de IBM DB2 se ejecuta en la máquina virtual az-idb01. Se debe usar el usuario con privilegios sudo o raíz (no recomendado).
El estado inicial de todos los casos de prueba se explica aquí: (crm_mon -r o pcs status)
- pcs status es una instantánea del estado de Pacemaker en tiempo de ejecución.
- crm_mon -r es la salida continua del estado de Pacemaker.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
El estado original en un sistema SAP se documenta en Transacción DBACOCKPIT > Configuración > Introducción, tal como se muestra en la siguiente imagen:
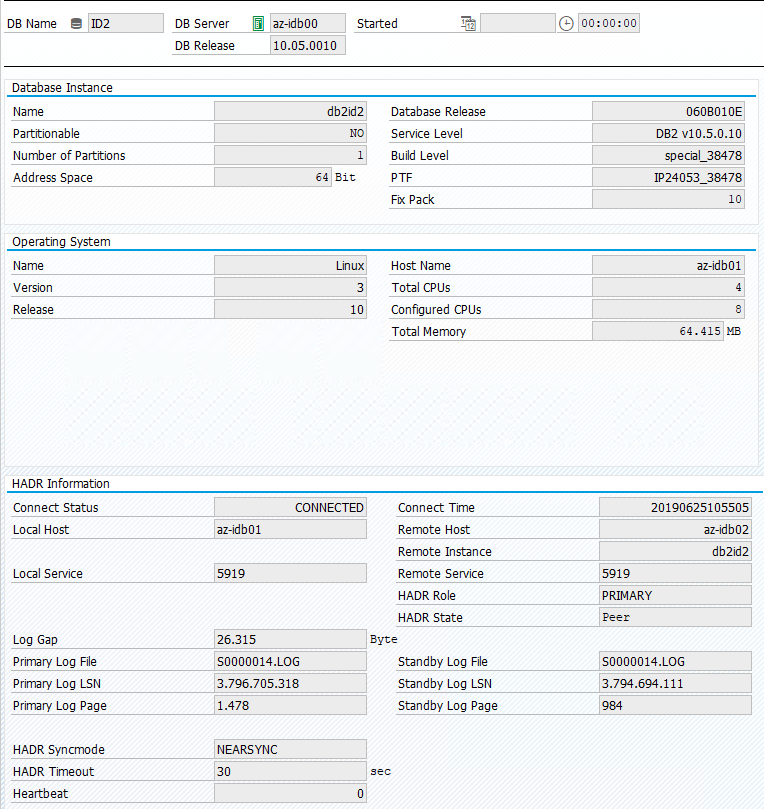
Probar la toma de control de IBM Db2
Importante
Antes de iniciar la prueba, asegúrese de lo siguiente:
Pacemaker no tiene acciones con error (pcs status).
No hay restricciones de ubicación (restos de la prueba de migración).
La sincronización de HADR de IBM Db2 funciona. Compruébelo con el usuario db2<sid>.
db2pd -hadr -db <DBSID>
Migre el nodo que ejecuta la base de datos principal de Db2. Para ello, ejecute el comando siguiente:
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
Una vez finalizada la migración, la salida del estado de crm tendrá este aspecto:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
El estado original en un sistema SAP se documenta en Transacción DBACOCKPIT > Configuración > Introducción, tal como se muestra en la siguiente imagen:
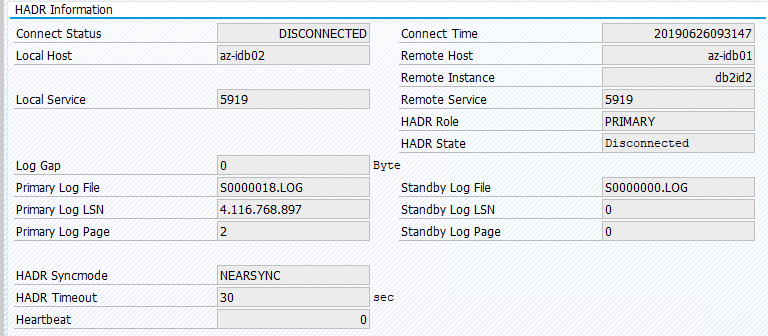
La migración de recursos con "pcs resource move" crea restricciones de ubicación. En este caso, las restricciones de ubicación impiden la ejecución de la instancia de IBM DB2 en az-idb01. Si no se eliminan las restricciones de ubicación, el recurso no puede conmutar por recuperación.
Quite la restricción de ubicación y se iniciará el nodo en espera en az-idb01.
# On RHEL 7.x
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource clear Db2_HADR_ID2-clone
El estado del clúster cambia a:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb01
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
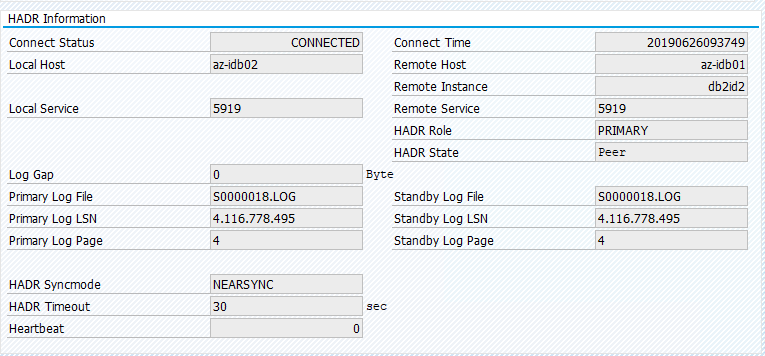
Vuelva a migrar el recurso a idb01 y elimine las restricciones de ubicación.
# On RHEL 7.x
sudo pcs resource move Db2_HADR_ID2-master az-idb01
sudo pcs resource clear Db2_HADR_ID2-master
# On RHEL 8.x
sudo pcs resource move Db2_HADR_ID2-clone --master
sudo pcs resource clear Db2_HADR_ID2-clone
- En RHEL 7.x -
pcs resource move <resource_name> <host>: crea restricciones de ubicación y puede causar problemas con la toma de control - En RHEL 8.x -
pcs resource move <resource_name> --master: crea restricciones de ubicación y puede causar problemas con la toma de control pcs resource clear <resource_name>: elimina las restricciones de ubicaciónpcs resource cleanup <resource_name>: elimina todos los errores del recurso
Probar una toma de control manual
Puede probar una toma de control manual mediante la detención del servicio de Pacemaker en el nodo az-idb01:
systemctl stop pacemaker
estado en az-ibdb02
2 nodes configured
5 resources configured
Node az-idb01: pending
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
Después de la conmutación por error, puede reiniciar el servicio en az-idb01.
systemctl start pacemaker
Detener el proceso de Db2 en el nodo que ejecuta la base de datos principal de HADR
#Kill main db2 process - db2sysc
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2ptr 34598 34596 8 14:21 ? 00:00:07 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 34598
Se producirá un error en la instancia de Db2 y Pacemaker moverá el nodo maestro y notificará el siguiente estado:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=49, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 09:57:35 2019', queued=0ms, exec=362ms
Pacemaker reinicia la instancia de base de datos principal de Db2 en el mismo nodo o se hace la conmutación por error al nodo que ejecuta la instancia de base de datos secundaria y se notifica un error.
Detener el proceso de Db2 en el nodo que ejecuta la instancia de base de datos secundaria
[sapadmin@az-idb02 ~]$ sudo ps -ef|grep db2sysc
db2id2 23144 23142 2 09:53 ? 00:00:13 db2sysc 0
[sapadmin@az-idb02 ~]$ sudo kill -9 23144
El nodo entra en un estado de error y el error se notifica.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
Failed Actions:
* Db2_HADR_ID2_monitor_20000 on az-idb02 'not running' (7): call=144, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 10:02:09 2019', queued=0ms, exec=0ms
La instancia de Db2 se reinicia en el rol secundario que tenía asignado anteriormente.
Detener la base de datos a través de db2stop force en el nodo que ejecuta la instancia de base de datos principal de HADR
Como user db2<sid>, ejecute el comando db2stop force:
az-idb01:db2ptr> db2stop force
Se detectó un error:
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Slaves: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Stopped
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Stopped
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
La instancia de base de datos secundaria de HADR de Db2 se promovió al rol principal.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
Failed Actions:
* Db2_HADR_ID2_demote_0 on az-idb01 'unknown error' (1): call=110, status=complete, exitreason='none',
last-rc-change='Wed Jun 26 14:03:12 2019', queued=0ms, exec=355ms
Bloquear la VM que ejecuta la instancia de base de datos principal de HADR mediante "halt"
#Linux kernel panic.
sudo echo b > /proc/sysrq-trigger
En tal caso, Pacemaker detecta que el nodo que ejecuta la instancia de base de datos principal no responde.
2 nodes configured
5 resources configured
Node az-idb01: UNCLEAN (online)
Online: [ az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb01 ]
Slaves: [ az-idb02 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb01
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb01
El paso siguiente es comprobar para ver si existe una situación tipo cerebro dividido. Cuando el nodo superviviente haya determinado que el nodo que ejecutó por última vez la instancia de base de datos principal está inactivo, se ejecuta una conmutación por error de los recursos.
2 nodes configured
5 resources configured
Online: [ az-idb02 ]
OFFLINE: [ az-idb01 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Stopped: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02
En caso de un pánico del kernel, el agente de barrera reiniciará el nodo con error. Una vez que el nodo con error vuelve a estar en línea, debe iniciar el clúster de Pacemaker mediante:
sudo pcs cluster start
la instancia de Db2 se inicia en el rol secundario.
2 nodes configured
5 resources configured
Online: [ az-idb01 az-idb02 ]
Full list of resources:
rsc_st_azure (stonith:fence_azure_arm): Started az-idb02
Master/Slave Set: Db2_HADR_ID2-master [Db2_HADR_ID2]
Masters: [ az-idb02 ]
Slaves: [ az-idb01 ]
Resource Group: g_ipnc_db2id2_ID2
vip_db2id2_ID2 (ocf::heartbeat:IPaddr2): Started az-idb02
nc_db2id2_ID2 (ocf::heartbeat:azure-lb): Started az-idb02