Alta disponibilidad de SAP HANA en máquinas virtuales de Azure en Red Hat Enterprise Linux
Para el desarrollo local, puede usar la replicación del sistema de HANA o el almacenamiento compartido para establecer alta disponibilidad para SAP HANA. En las máquinas virtuales Azure, la replicación del sistema HANA en Azure es actualmente la única función de HA compatible.
La replicación de SAP HANA se realiza con un nodo principal y al menos uno secundario. Los cambios en los datos del nodo principal se replican en los secundarios de forma sincrónica o asincrónica.
En este artículo se describe cómo implementar y configurar las máquinas virtuales, instalar la plataforma del clúster e instalar y configurar la replicación del sistema de SAP HANA.
En las configuraciones de ejemplo, se usan los comandos de instalación, el número de instancia 03 y el identificador del sistema de HANA HN1.
Requisitos previos
Lea primero las notas y los documentos de SAP siguientes:
- Nota de SAP 1928533, que incluye:
- La lista de tamaños de máquina virtual de Azure que se admiten para la implementación del software de SAP.
- Información importante sobre capacidad para los tamaños de máquina virtual de Azure.
- Las combinaciones admitidas de software y sistema operativo (SO) y base de datos de SAP.
- La versión del kernel de SAP necesaria para Windows y Linux en Microsoft Azure.
- La nota de SAP 2015553 enumera los requisitos previos para las implementaciones de software de SAP admitidas por SAP en Azure.
- La nota de SAP 2002167 recomienda la configuración del sistema operativo para Red Hat Enterprise Linux.
- La nota de SAP 2009879 contiene las instrucciones de SAP HANA para Red Hat Enterprise Linux.
- La nota de SAP 3108302 contiene las instrucciones de SAP HANA para Red Hat Enterprise Linux 9.x.
- La nota de SAP 2178632 contiene información detallada sobre todas las métricas de supervisión notificadas para SAP en Azure.
- La nota de SAP 2191498 incluye la versión de SAP Host Agent necesaria para Linux en Azure.
- La nota de SAP 2243692 incluye información acerca de las licencias de SAP en Linux en Azure.
- La nota de SAP 1999351 contiene más información de solución de problemas sobre la extensión de supervisión mejorada de Azure para SAP.
- La WIKI de la comunidad SAP contiene todas las notas de SAP que se necesitan para Linux.
- Planeación e implementación de Azure Virtual Machines para SAP en Linux
- Implementación de Azure Virtual Machines para SAP en Linux (este artículo)
- Implementación de DBMS de Azure Virtual Machines para SAP en Linux
- Replicación del sistema de SAP HANA en un clúster de Pacemaker
- Documentación general de RHEL:
- Documentación de RHEL específica para Azure:
- Directivas de compatibilidad para clústeres de alta disponibilidad RHEL: instancias de Microsoft Azure Virtual Machines como miembros del clúster
- Instalación y configuración de un clúster de alta disponibilidad de Red Hat Enterprise Linux 7.4 (y versiones posteriores) en Microsoft Azure
- Instalación de SAP HANA en Red Hat Enterprise Linux para su uso en Microsoft Azure
Información general
Para lograr alta disponibilidad, SAP HANA se instala en dos máquinas virtuales. Los datos se replican mediante la replicación del sistema de HANA.
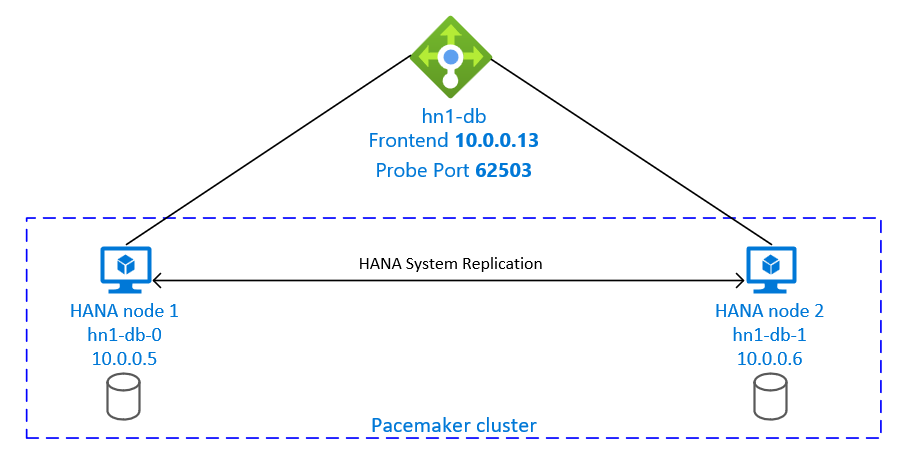
En la instalación de la replicación del sistema de SAP HANA se usa un nombre de host virtual dedicado y direcciones IP virtuales. En Azure, se requiere un equilibrador de carga para usar una dirección IP virtual. La configuración presentada muestra un equilibrador de carga con:
- Dirección IP de front-end: 10.0.0.13 para hn1-db
- Puerto de sondeo: 62503
Preparación de la infraestructura
Azure Marketplace contiene imágenes calificadas para SAP HANA con el complemento de alta disponibilidad, que puede usar para implementar nuevas máquinas virtuales mediante varias versiones de Red Hat.
Implementación manual de VM de Linux mediante Azure Portal
En este documento se supone que ya ha implementado un grupo de recursos, una red virtual de Azure y una subred.
Implemente máquinas virtuales para SAP HANA. Elija una imagen de RHEL adecuada que sea compatible con el sistema HANA. Puede implementar una máquina virtual en cualquiera de las opciones de disponibilidad: conjunto de escalado de máquinas virtuales, zona de disponibilidad o conjunto de disponibilidad.
Importante
Asegúrese de que el sistema operativo que selecciona está certificado por SAP para SAP HANA en los tipos específicos de máquinas virtuales que tiene previsto usar en su implementación. Puede buscar los tipos de máquina virtual certificados por SAP HANA y sus versiones del sistema operativo en Plataformas IaaS certificadas para SAP HANA. Asegúrese de consultar los detalles del tipo de máquina virtual para obtener la lista completa de versiones de SO compatibles con SAP HANA para el tipo de máquina virtual específico.
Configurar Azure Load Balancer
Durante la configuración de la máquina virtual, tiene una opción para crear o seleccionar salir del equilibrador de carga en la sección de redes. Siga estos pasos para configurar el equilibrador de carga estándar para la configuración de alta disponibilidad de la base de datos de HANA.
Siga los pasos descritos en Creación de un equilibrador de carga para configurar un equilibrador de carga estándar para un sistema SAP de alta disponibilidad mediante Azure Portal. Durante la configuración del equilibrador de carga, tenga en cuenta los siguientes puntos:
- Configuración de IP de front-end: cree una dirección IP de front-end. Seleccione el mismo nombre de red virtual y subred que las máquinas virtuales de la base de datos.
- Grupo de back-end: cree un grupo de back-end y agregue máquinas virtuales de base de datos.
- Reglas de entrada: cree una regla de equilibrio de carga. Siga los mismos pasos para ambas reglas de equilibrio de carga.
- Dirección IP de front-end: seleccione una dirección IP de front-end.
- Grupo de back-end: seleccione un grupo de back-end.
- Puertos de alta disponibilidad: seleccione esta opción.
- Protocolo: seleccione TCP.
- Sondeo de estado: cree un sondeo de estado con los detalles siguientes:
- Protocolo: seleccione TCP.
- Puerto: por ejemplo, 625<instance-no.>.
- Intervalo: escriba 5.
- Umbral de sondeo: escriba 2.
- Tiempo de espera de inactividad (minutos): Escriba 30.
- Habilitar IP flotante: seleccione esta opción.
Nota:
No se respeta la propiedad de configuración del sondeo de estado numberOfProbes, también conocida como Umbral incorrecto en el portal. Para controlar el número de sondeos consecutivos correctos o erróneos, establezca la propiedad probeThreshold en 2. Actualmente, no es posible establecer esta propiedad mediante Azure Portal, por lo que debe usar la CLI de Azure o el comando de PowerShell.
Para obtener más información sobre los puertos necesarios para SAP HANA, lea el capítulo Connections to Tenant Databases (Conexiones a las bases de datos de inquilino) de la guía SAP HANA Tenant Databases (Bases de datos de inquilino de SAP HANA) o la nota de SAP 2388694.
Nota:
Cuando las máquinas virtuales sin direcciones IP públicas se colocan en el grupo de back-end de una instancia interna (sin dirección IP pública) de Azure Standard Load Balancer, no hay conectividad saliente a Internet, a menos que se realice una configuración adicional para permitir el enrutamiento a puntos de conexión públicos. Para obtener más información sobre cómo conseguir la conectividad saliente, consulte Conectividad de punto de conexión público para máquinas virtuales con Azure Standard Load Balancer en escenarios de alta disponibilidad de SAP.
Importante
No habilite las marcas de tiempo TCP en VM de Azure que se encuentren detrás de Azure Load Balancer. La habilitación de las marcas de tiempo de TCP podría provocar un error en los sondeos de estado. Establezca el parámetro net.ipv4.tcp_timestamps en 0. Para obtener más información, consulte Sondeos de estado de Load Balancer y Nota de SAP 2382421.
Instalación de SAP HANA
En los pasos de esta sección se usan los siguientes prefijos:
- [A] : el paso se aplica a todos los nodos.
- [1] : el paso solo se aplica al nodo 1.
- [2] : el paso solo se aplica al nodo 2 del clúster de Pacemaker.
[A] Configuración del diseño de disco: Administrador de volúmenes lógicos (LVM) .
Se recomienda usar LVM para volúmenes que almacenen datos y archivos de registro. El siguiente ejemplo supone que las máquinas virtuales tienen cuatro discos de datos conectados que se utilizan para crear dos volúmenes.
Enumera todos los discos disponibles:
ls /dev/disk/azure/scsi1/lun*Ejemplo:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Cree volúmenes físicos para todos los discos que quiera usar:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Cree un grupo de volúmenes para los archivos de datos. Use un grupo de volúmenes para los archivos de registro y otro para el directorio compartido de SAP HANA:
sudo vgcreate vg_hana_data_HN1 /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_HN1 /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_HN1 /dev/disk/azure/scsi1/lun3Cree los volúmenes lógicos. Cuando se usa
lvcreatesin el modificador-i, se crea un volumen lineal. Se recomienda crear un volumen seccionado para mejorar el rendimiento de E/S. Alinee los tamaños de sección con los valores documentados en las configuraciones de almacenamiento de máquinas virtuales de SAP HANA. El argumento-idebe ser el número de volúmenes físicos subyacentes y-I, el tamaño de la sección.En este documento, se usan dos volúmenes físicos para el volumen de datos, por lo que el modificador
-ise establece en 2. El tamaño de sección para el volumen de datos es 256 KiB. Se usa un volumen físico para el volumen de registro, así que no se usa explícitamente ningún modificador-io-Ipara los comandos del volumen de registro.Importante
Use el modificador
-iy establézcalo en el número del volumen físico subyacente cuando se usa más de un volumen físico para cada volumen de datos, de registro o compartido. Use el modificador-Ipara especificar el tamaño de las secciones al crear un volumen seccionado. Consulte Configuraciones de almacenamiento de máquinas virtuales de Azure en SAP HANA para conocer las configuraciones de almacenamiento recomendadas, incluidos los tamaños de sección y el número de discos. Los siguientes ejemplos de diseño no cumplen necesariamente las directrices de rendimiento de un tamaño de sistema determinado. Sólo son para ilustración.sudo lvcreate -i 2 -I 256 -l 100%FREE -n hana_data vg_hana_data_HN1 sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_HN1 sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_HN1 sudo mkfs.xfs /dev/vg_hana_data_HN1/hana_data sudo mkfs.xfs /dev/vg_hana_log_HN1/hana_log sudo mkfs.xfs /dev/vg_hana_shared_HN1/hana_sharedNo monte los directorios mediante la emisión de comandos de montaje. En su lugar, escriba las configuraciones en
fstaby emita una finalmount -apara validar la sintaxis. Empiece por crear los directorios de montaje para cada volumen:sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/sharedA continuación, cree
fstabentradas para los tres volúmenes lógicos insertando las líneas siguientes en el/etc/fstabarchivo:/dev/mapper/vg_hana_data_HN1-hana_data /hana/data xfs defaults,nofail 0 2 /dev/mapper/vg_hana_log_HN1-hana_log /hana/log xfs defaults,nofail 0 2 /dev/mapper/vg_hana_shared_HN1-hana_shared /hana/shared xfs defaults,nofail 0 2
Por último, monte todos los volúmenes nuevos a la vez:
sudo mount -a[A] Configurar la resolución de nombres de host para todos los hosts.
Puede usar un servidor DNS o modificar el
/etc/hostsarchivo en todos los nodos mediante la creación de entradas para todos los nodos como este en/etc/hosts:10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Realice RHEL para la configuración de HANA.
Configure RHEL tal como se describe en las siguientes notas:
- 2447641: paquetes adicionales necesarios para instalar SAP HANA SPS 12 en RHEL 7.X
- 2292690 - SAP HANA DB: Recommended OS settings for RHEL 7 (2292690 - SAP HANA DB: configuraciones de sistema operativo recomendadas para RHEL 7)
- 2777782 - SAP HANA DB: Recommended OS settings for RHEL 8 (SAP HANA DB: configuración recomendada del sistema operativo para RHEL 8).
- 2455582 - Linux: Running SAP applications compiled with GCC 6.x (Nota de compatibilidad de SAP n.º 2455582 - Linux: Ejecución de aplicaciones SAP compiladas con GCC 6.x)
- 2593824 - Linux: Ejecución de aplicaciones SAP compiladas con GCC 7.x
- 2886607 - Linux: Ejecución de aplicaciones SAP compiladas con GCC 9.x
[A] Instale SAP HANA.
Para instalar la replicación del sistema de SAP HANA, consulte el artículo sobre cómo automatizar la replicación del sistema de escalado vertical de SAP HANA mediante el complemento de alta disponibilidad de RHEL.
Ejecute el programa hdblcm del DVD de HANA. Escriba los siguientes valores en el símbolo del sistema:
- Elija la instalación: Especifique 1.
- Seleccione los componentes adicionales para la instalación: Especifique 1.
- Escriba la ruta de instalación [/hana/shared]: Selecciones Entrar.
- Escribir el nombre de host local [..]: seleccione Entrar.
- ¿Desea agregar hosts adicionales al sistema? (y/n) [n]: Presione Entrar.
- Escribir el identificador del sistema de SAP HANA: escriba el SID de HANA, por ejemplo: HN1.
- Escribir el número de instancia [00]: escriba el número de instancia de HANA. Escribir 03 si usó la plantilla de Azure o ha seguido la sección de implementación manual de este artículo.
- Seleccione el modo de base de datos y escriba el índice [1]: Seleccione Entrar.
- Seleccionar uso del sistema/escribir el índice [4]: seleccione el valor de uso del sistema.
- Escribir ubicación de los volúmenes de datos [/hana/data/HN1]: seleccione Entrar.
- Escribir ubicación de los volúmenes de registro [/hana/log/HN1]: seleccione Entrar.
- ¿Restringir la asignación de memoria máxima? [n]: Presione Entrar.
- Escribir nombre de host del certificado para el host "..." [...]: seleccione Entrar.
- Escriba Contraseña de usuario del agente de host de SAP (sapadm): escriba la contraseña de usuario del agente de host.
- Confirme la Contraseña de usuario del agente de host de SAP (sapadm): vuelva a escribir la contraseña de usuario del agente de host para confirmar.
- Escribir contraseña de administrador del sistema (hdbadm): escriba la contraseña de administrador del sistema.
- Confirmar contraseña de administrador del sistema (hdbadm): escriba de nuevo la contraseña de administrador del sistema para confirmarla.
- Escribir directorio principal de administrador del sistema [/usr/sap/HN1/home]: seleccione Entrar.
- Escribir shell de inicio de sesión de administrador del sistema [/bin/sh]: seleccione Entrar.
- Escribir identificador de usuario de administrador del sistema [1001]: seleccione Entrar.
- Escribir identificador de grupo de usuarios (sapsys) [79]: seleccione Entrar.
- Escriba Contraseña de usuario de base de datos (SYSTEM): escriba la contraseña de usuario de la base de datos.
- Confirme la Contraseña de usuario de base de datos (SYSTEM): vuelva a escribir la contraseña de usuario de la base de datos para confirmar.
- ¿Reiniciar el sistema tras el reinicio de la máquina? [n]: Presione Entrar.
- ¿Desea continuar? (y/n): valide el resumen. Escriba s para continuar.
[A] Actualización del agente de host de SAP.
Descargue el archivo más reciente del agente de host de SAP desde SAP Software Center y ejecute el siguiente comando para actualizar el agente. Reemplace la ruta de acceso al archivo para que apunte al archivo que descargó:
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent>;[A] Configurar el firewall.
Cree la regla de firewall para el puerto de sondeo de Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp --permanent
Configuración de la Replicación del sistema de SAP HANA 2.0
En los pasos de esta sección se usan los siguientes prefijos:
- [A] : el paso se aplica a todos los nodos.
- [1] : el paso solo se aplica al nodo 1.
- [2] : el paso solo se aplica al nodo 2 del clúster de Pacemaker.
[A] Configurar el firewall.
Cree reglas de firewall para permitir la replicación del sistema de HANA y el tráfico del cliente. Los puertos necesarios se enumeran en TCP/IP Ports of All SAP Products (Puertos TCP/IP de todos los productos de SAP). Los siguientes comandos son simplemente un ejemplo para permitir la replicación del sistema de HANA 2.0 y el tráfico del cliente a las bases de datos SYSTEMDB, HN1 y NW1.
sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp --permanent sudo firewall-cmd --zone=public --add-port={40302,40301,40307,40303,40340,30340,30341,30342}/tcp[1] Creación de la base de datos de inquilino.
Si usa SAP HANA 2.0 o MDC, cree una base de datos de inquilino para el sistema SAP NetWeaver. Reemplace NW1 por el SID del sistema SAP.
Ejecute el siguiente comando como <hanasid>adm:
hdbsql -u SYSTEM -p "[passwd]" -i 03 -d SYSTEMDB 'CREATE DATABASE NW1 SYSTEM USER PASSWORD "<passwd>"'[1] Configuración de la replicación del sistema en el primer nodo.
Haga una copia de seguridad de las bases de datos como <hanasid>adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupSYS')" hdbsql -d HN1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupHN1')" hdbsql -d NW1 -u SYSTEM -p "<passwd>" -i 03 "BACKUP DATA USING FILE ('initialbackupNW1')"Copie los archivos PKI de sistema en el sitio secundario:
scp /usr/sap/HN1/SYS/global/security/rsecssfs/data/SSFS_HN1.DAT hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/data/ scp /usr/sap/HN1/SYS/global/security/rsecssfs/key/SSFS_HN1.KEY hn1-db-1:/usr/sap/HN1/SYS/global/security/rsecssfs/key/Cree el sitio principal:
hdbnsutil -sr_enable --name=SITE1[2] Configuración de la replicación del sistema en el segundo nodo.
Registre el segundo nodo para iniciar la replicación del sistema. Ejecute el siguiente comando como <hanasid>adm:
sapcontrol -nr 03 -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2[1] Comprobación del estado de replicación.
Compruebe el estado de replicación y espere hasta que todas las bases de datos estén sincronizadas. Si el estado sigue siendo DESCONOCIDO, compruebe la configuración del firewall.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py" # | Database | Host | Port | Service Name | Volume ID | Site ID | Site Name | Secondary | Secondary | Secondary | Secondary | Secondary | Replication | Replication | Replication | # | | | | | | | | Host | Port | Site ID | Site Name | Active Status | Mode | Status | Status Details | # | -------- | -------- | ----- | ------------ | --------- | ------- | --------- | --------- | --------- | --------- | --------- | ------------- | ----------- | ----------- | -------------- | # | SYSTEMDB | hn1-db-0 | 30301 | nameserver | 1 | 1 | SITE1 | hn1-db-1 | 30301 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30307 | xsengine | 2 | 1 | SITE1 | hn1-db-1 | 30307 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | NW1 | hn1-db-0 | 30340 | indexserver | 2 | 1 | SITE1 | hn1-db-1 | 30340 | 2 | SITE2 | YES | SYNC | ACTIVE | | # | HN1 | hn1-db-0 | 30303 | indexserver | 3 | 1 | SITE1 | hn1-db-1 | 30303 | 2 | SITE2 | YES | SYNC | ACTIVE | | # # status system replication site "2": ACTIVE # overall system replication status: ACTIVE # # Local System Replication State # ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ # # mode: PRIMARY # site id: 1 # site name: SITE1
Configuración de la Replicación del sistema de SAP HANA 1.0
En los pasos de esta sección se usan los siguientes prefijos:
- [A] : el paso se aplica a todos los nodos.
- [1] : el paso solo se aplica al nodo 1.
- [2] : el paso solo se aplica al nodo 2 del clúster de Pacemaker.
[A] Configurar el firewall.
Cree reglas de firewall para permitir la replicación del sistema de HANA y el tráfico del cliente. Los puertos necesarios se enumeran en TCP/IP Ports of All SAP Products (Puertos TCP/IP de todos los productos de SAP). Los siguientes comandos son simplemente un ejemplo para permitir la replicación del sistema de HANA 2.0. Adáptelo a su instalación de SAP HANA 1.0.
sudo firewall-cmd --zone=public --add-port=40302/tcp --permanent sudo firewall-cmd --zone=public --add-port=40302/tcp[1] Creación de los usuarios necesarios.
Ejecute el siguiente comando como raíz. Asegúrese de reemplazar los valores del identificador del sistema de HANA (por ejemplo, HN1), el número de instancia (03) y los nombres de usuario, por los valores de la instalación de SAP HANA:
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -u system -i 03 'CREATE USER hdbhasync PASSWORD "passwd"' hdbsql -u system -i 03 'GRANT DATA ADMIN TO hdbhasync' hdbsql -u system -i 03 'ALTER USER hdbhasync DISABLE PASSWORD LIFETIME'[A] Creación de la entrada del almacén de claves.
Ejecute el siguiente comando como raíz para crear una entrada del almacén de claves:
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbuserstore SET hdbhaloc localhost:30315 hdbhasync passwd[1] Realización de una copia de seguridad de la base de datos.
Haga una copia de seguridad de las bases de datos como raíz:
PATH="$PATH:/usr/sap/HN1/HDB03/exe" hdbsql -d SYSTEMDB -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"Si usa una instalación multiinquilino, haga también una copia de seguridad de la base de datos de inquilino:
hdbsql -d HN1 -u system -i 03 "BACKUP DATA USING FILE ('initialbackup')"[1] Configuración de la replicación del sistema en el primer nodo.
Cree el sitio principal como <hanasid>adm:
su - hdbadm hdbnsutil -sr_enable –-name=SITE1[2] Configuración de la replicación del sistema en el nodo secundario.
Registre el sitio secundario como <hanasid>adm:
HDB stop hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 HDB start
Creación de un clúster de Pacemaker
Siga los pasos de Configuración de Pacemaker en Red Hat Enterprise Linux en Azure para crear un clúster de Pacemaker básico para este servidor HANA.
Importante
Con el marco de inicio de SAP basado en sistema, las instancias de SAP HANA ahora se pueden administrar mediante systemd. La versión mínima necesaria de Red Hat Enterprise Linux (RHEL) es RHEL 8 para SAP. Como se describe en la Nota de SAP 3189534, las nuevas instalaciones de la revisión 70 o posteriores de SAP HANA SPS07, o las actualizaciones de los sistemas HANA a HANA 2.0 SPS07 revisión 70 o posterior, el marco de inicio de SAP se registrará automáticamente con systemd.
Al usar soluciones de alta disponibilidad para administrar la replicación del sistema de SAP HANA en combinación con las instancias de SAP HANA habilitadas para el sistema (consulte la Nota de SAP 3189534), se necesitan pasos adicionales para asegurarse de que el clúster de alta disponibilidad pueda administrar la instancia de SAP sin interferencias del sistema. Por lo tanto, para el sistema de SAP HANA integrado con systemd, deben seguirse pasos adicionales descritos en Red Hat KBA 7029705 en todos los nodos del clúster.
Implementación del enlace de replicación del sistema Python SAPHanaSR
Este importante paso optimiza la integración con el clúster y mejora la detección cuando es necesaria una conmutación por error del clúster. Se recomienda encarecidamente configurar el enlace de Python de SAPHanaSR.
[A] Instale los agentes de recursos de SAP HANA en todos los nodos. Asegúrese de habilitar un repositorio que contenga el paquete. No es necesario habilitar más repositorios si usa una imagen habilitada para alta disponibilidad de RHEL 8.x.
# Enable repository that contains SAP HANA resource agents sudo subscription-manager repos --enable="rhel-sap-hana-for-rhel-7-server-rpms" sudo yum install -y resource-agents-sap-hanaNota:
Para RHEL 8.x y RHEL 9.x, compruebe que el paquete resource-agents-sap-hana instalado es la versión 0.162.3-5 o posterior.
[A] Instale HANA
system replication hook. El enlace debe instalarse en ambos nodos de base de datos de HANA.Sugerencia
El enlace de Python solo puede se implementar para HANA 2.0.
Prepare el enlace como
root.mkdir -p /hana/shared/myHooks cp /usr/share/SAPHanaSR/srHook/SAPHanaSR.py /hana/shared/myHooks chown -R hn1adm:sapsys /hana/shared/myHooksDetenga HANA en ambos nodos. Ejecute como <sid>adm.
sapcontrol -nr 03 -function StopSystemAjuste
global.inien cada uno de los nodos del clúster.[ha_dr_provider_SAPHanaSR] provider = SAPHanaSR path = /hana/shared/myHooks execution_order = 1 [trace] ha_dr_saphanasr = info
[A] El cluster requiere configuración
sudoersen cada nodo del cluster para <sid>adm. En este ejemplo, esto se consigue mediante la creación de un archivo nuevo. Use elvisudocomando para editar el20-saphanaarchivo desplegable comoroot.sudo visudo -f /etc/sudoers.d/20-saphanaInserte las líneas siguientes y, a continuación, guarde:
Cmnd_Alias SITE1_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE1_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE1 -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SOK = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SITE2_SFAIL = /usr/sbin/crm_attribute -n hana_hn1_site_srHook_SITE2 -v SFAIL -t crm_config -s SAPHanaSR hn1adm ALL=(ALL) NOPASSWD: SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL Defaults!SITE1_SOK, SITE1_SFAIL, SITE2_SOK, SITE2_SFAIL !requiretty[A] Inicie SAP HANA en ambos nodos. Ejecute como <sid>adm.
sapcontrol -nr 03 -function StartSystem[1] Compruebe la instalación del enlace. Ejecute como <sid>adm en el sitio activo de replicación del sistema HANA.
cdtrace awk '/ha_dr_SAPHanaSR.*crm_attribute/ \ { printf "%s %s %s %s\n",$2,$3,$5,$16 }' nameserver_*# 2021-04-12 21:36:16.911343 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:36:29.147808 ha_dr_SAPHanaSR SFAIL # 2021-04-12 21:37:04.898680 ha_dr_SAPHanaSR SOK
Para obtener más detalles sobre la implementación del enlace de replicación del sistema SAP HANA, consulte la documentación sobre la configuración del enlace de proveedor de HA/DR de SAP.
Creación de recursos de clúster de SAP HANA
Cree la topología de HANA. Ejecute los comandos siguientes en uno de los nodos del clúster de Pacemaker. A lo largo de estas instrucciones, asegúrese de sustituir el número de instancia, el identificador del sistema de HANA, las direcciones IP y los nombres del sistema, si procede.
sudo pcs property set maintenance-mode=true
sudo pcs resource create SAPHanaTopology_HN1_03 SAPHanaTopology SID=HN1 InstanceNumber=03 \
op start timeout=600 op stop timeout=300 op monitor interval=10 timeout=600 \
clone clone-max=2 clone-node-max=1 interleave=true
A continuación, cree los recursos de HANA.
Nota:
Este artículo contiene referencias a un término que Microsoft ya no utiliza. Cuando se elimine el término del software, se eliminará también de este artículo.
Si va a compilar un clúster en RHEL 7.x, use los comandos siguientes:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
master notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-master symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-master 4000
sudo pcs resource defaults resource-stickiness=1000
sudo pcs resource defaults migration-threshold=5000
sudo pcs property set maintenance-mode=false
Si va a compilar un clúster en RHEL 8.x/9.x, use los comandos siguientes:
sudo pcs resource create SAPHana_HN1_03 SAPHana SID=HN1 InstanceNumber=03 PREFER_SITE_TAKEOVER=true DUPLICATE_PRIMARY_TIMEOUT=7200 AUTOMATED_REGISTER=false \
op start timeout=3600 op stop timeout=3600 \
op monitor interval=61 role="Slave" timeout=700 \
op monitor interval=59 role="Master" timeout=700 \
op promote timeout=3600 op demote timeout=3600 \
promotable notify=true clone-max=2 clone-node-max=1 interleave=true
sudo pcs resource create vip_HN1_03 IPaddr2 ip="10.0.0.13"
sudo pcs resource create nc_HN1_03 azure-lb port=62503
sudo pcs resource group add g_ip_HN1_03 nc_HN1_03 vip_HN1_03
sudo pcs constraint order SAPHanaTopology_HN1_03-clone then SAPHana_HN1_03-clone symmetrical=false
sudo pcs constraint colocation add g_ip_HN1_03 with master SAPHana_HN1_03-clone 4000
sudo pcs resource defaults update resource-stickiness=1000
sudo pcs resource defaults update migration-threshold=5000
sudo pcs property set maintenance-mode=false
Para configurar priority-fencing-delay para SAP HANA (aplicable solo a partir de pacemaker-2.0.4-6.el8 o superior), es necesario ejecutar los siguientes comandos.
Nota:
Si tiene un clúster de dos nodos, puede configurar la priority-fencing-delay propiedad del clúster. Esta propiedad introduce un retraso adicional en la limitación de un nodo que tiene una prioridad de recurso total mayor cuando se produce un escenario de cerebro dividido. Para más información, consulte ¿Puede Pacemaker cercar el nodo de clúster con los recursos en ejecución más pequeños?.
La propiedad priority-fencing-delay es aplicable a la versión pacemaker-2.0.4-6.el8 o posterior. Si está configurando priority-fencing-delay en un clúster existente, asegúrese de anular la pcmk_delay_max opción en el dispositivo de barrera.
sudo pcs property set maintenance-mode=true
sudo pcs resource defaults update priority=1
sudo pcs resource update SAPHana_HN1_03-clone meta priority=10
sudo pcs property set priority-fencing-delay=15s
sudo pcs property set maintenance-mode=false
Importante
Es una buena idea establecer AUTOMATED_REGISTER en false, mientras se realizan pruebas de conmutación por error, para evitar que una instancia principal con errores se registre automáticamente como secundaria. Después de las pruebas, como procedimiento recomendado, establezca AUTOMATED_REGISTER en true para que, después de la adquisición, la replicación del sistema pueda reanudarse automáticamente.
Asegúrese de que el estado del clúster sea correcto y que todos los recursos se hayan iniciado. El nodo en el que se ejecutan los recursos no es importante.
Nota:
Los tiempos de espera de la configuración anterior son solo ejemplos y puede ser necesario adaptarlos a la configuración específica de HANA. Por ejemplo, puede que necesite aumentar el tiempo de espera de inicio si la base de datos de SAP HANA tarda más en iniciarse.
Use el comando sudo pcs status para comprobar el estado de los recursos del clúster creados:
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# azure_fence (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Configuración de la replicación del sistema activa/habilitada para lectura de HANA en el clúster de Pacemaker
A partir de SAP HANA 2.0 SPS 01, SAP permite el uso de configuraciones activas/habilitadas para lectura para la replicación del sistema de SAP HANA, donde los sistemas secundarios de la replicación del sistema de SAP HANA se pueden usar activamente para cargas de trabajo de lectura intensiva.
Para admitir esta configuración en un clúster, se requiere una segunda dirección IP virtual, lo que permite a los clientes acceder a la base de datos de SAP HANA habilitada para lectura secundaria. Para garantizar que todavía se puede tener acceso al sitio de replicación secundario tras una adquisición, el clúster debe mover la dirección IP virtual con el sistema secundario del recurso SAPHana.
Esta sección describe los demás pasos necesarios para gestionar la replicación del sistema activo/de lectura de HANA en un clúster Red Hat HA con una segunda IP virtual.
Antes de continuar, asegúrese de que ha configurado completamente el clúster de alta disponibilidad de Red Hat que administra una base de datos de SAP HANA, como se describe en los segmentos anteriores de la documentación.
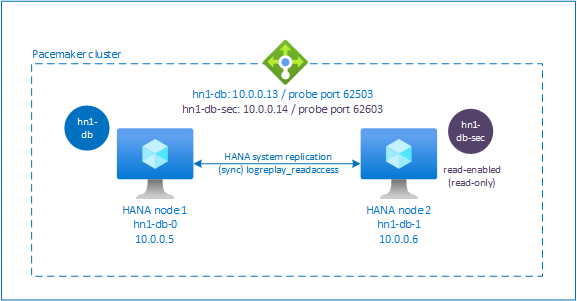
Configuración adicional en Azure Load Balancer para la configuración activa/habilitada para lectura
Para continuar con más pasos sobre el aprovisionamiento de una segunda dirección IP virtual, asegúrese de que ha configurado Azure Load Balancer como se describe en la sección Implementación manual de máquinas virtuales Linux mediante Azure Portal.
Para el equilibrador de carga estándar, siga los pasos adicionales que se indican a continuación en el mismo equilibrador de carga que creó en la sección anterior.
a. Crear un segundo grupo de direcciones IP de front-end:
- Abra el equilibrador de carga, seleccione frontend IP pool (Grupo de direcciones IP de front-end) y haga clic en Agregar.
- Escriba el nombre del segundo grupo de direcciones IP de front-end (por ejemplo, hana-secondaryIP).
- Establezca Asignación en Estática y escriba la dirección IP (por ejemplo, 10.0.0.14).
- Seleccione Aceptar.
- Una vez creado el nuevo grupo de direcciones IP de front-end, anote la dirección IP del grupo.
b. Cree un sondeo de estado:
- Abra el equilibrador de carga, seleccione Sondeos de estado y haga clic en Agregar.
- Escriba el nombre del sondeo de estado nuevo (por ejemplo hana-secondaryhp).
- Seleccione TCP como el protocolo y el puerto 62603. Mantenga el valor de Intervalo en 5 y el valor de Umbral incorrecto en 2.
- Seleccione Aceptar.
c. Cree las reglas de equilibrio de carga:
- Abra el equilibrador de carga, seleccione Reglas de equilibrio de carga y haga clic en Agregar.
- Escriba el nombre de la nueva regla del equilibrador de carga (por ejemplo, hana-secondarylb).
- Seleccione la dirección IP de front-end, el grupo de back-end y el sondeo de estado que creó anteriormente (por ejemplo, hana-secondaryIP, hana-backend y hana-secondaryhp).
- Seleccione Puertos HA.
- Asegúrese de habilitar la dirección IP flotante.
- Seleccione Aceptar.
Configuración de la replicación del sistema HANA activo/habilitado para lectura
Los pasos para configurar la replicación del sistema de HANA se describen en la sección Configuración de la replicación del sistema SAP HANA 2.0. Si va a implementar un escenario secundario habilitado para lectura, mientras configura la replicación del sistema en el segundo nodo, ejecute el siguiente comando como hanasidadm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2 --operationMode=logreplay_readaccess
Adición de un recurso de dirección IP virtual secundaria para una configuración activa/habilitada para lectura
La segunda dirección IP virtual y la restricción de coubicación adecuada se pueden configurar con los siguientes comandos:
pcs property set maintenance-mode=true
pcs resource create secvip_HN1_03 ocf:heartbeat:IPaddr2 ip="10.40.0.16"
pcs resource create secnc_HN1_03 ocf:heartbeat:azure-lb port=62603
pcs resource group add g_secip_HN1_03 secnc_HN1_03 secvip_HN1_03
pcs constraint location g_secip_HN1_03 rule score=INFINITY hana_hn1_sync_state eq SOK and hana_hn1_roles eq 4:S:master1:master:worker:master
pcs constraint location g_secip_HN1_03 rule score=4000 hana_hn1_sync_state eq PRIM and hana_hn1_roles eq 4:P:master1:master:worker:master
pcs property set maintenance-mode=false
Asegúrese de que el estado del clúster sea el correcto y que se iniciaron todos los recursos. La segunda dirección IP virtual se ejecutará en el sitio secundario junto con el recurso secundario SAPHana.
sudo pcs status
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full List of Resources:
# rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hn1-db-0
# Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]:
# Started: [ hn1-db-0 hn1-db-1 ]
# Clone Set: SAPHana_HN1_03-clone [SAPHana_HN1_03] (promotable):
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_03:
# nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# Resource Group: g_secip_HN1_03:
# secnc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
# secvip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
En la siguiente sección puede encontrar el conjunto típico de pruebas de conmutación por error que se va a ejecutar.
Tenga en cuenta el comportamiento de la segunda dirección IP virtual mientras prueba un clúster de HANA habilitado para lectura:
Al migrar el recurso de clúster SAPHana_HN1_03 al sitio secundario hn1-db-1, la segunda dirección IP virtual se seguirá ejecutando en el mismo sitio hn1-db-1. Si ha establecido
AUTOMATED_REGISTER="true"para el recurso y la replicación del sistema HANA se registra automáticamente en hn1-db-0, la segunda dirección IP virtual también se mueve a hn1-db-0.Al probar el bloqueo del servidor, los recursos de la segunda IP virtual (secvip_HN1_03) y el recurso de puerto de Azure Load Balancer (secnc_HN1_03) se ejecutarán en el servidor principal junto con los recursos de la IP virtual principal. Mientras el servidor secundario está inactivo, las aplicaciones que están conectadas a la base de datos de HANA habilitada para lectura se conectarán a la base de datos de HANA principal. El comportamiento es el esperado, ya que no desea que las aplicaciones que están conectadas a la base de datos de HANA habilitada para lectura sean inaccesibles mientras el servidor secundario de hora no esté disponible.
Durante la conmutación por error y la recuperación de la segunda dirección IP virtual, es posible que se interrumpan las conexiones existentes en las aplicaciones que utilizan la segunda IP virtual para conectarse a la base de datos HANA.
La configuración maximiza el tiempo durante el que se asignará el segundo recurso de IP virtual a un nodo en el que se ejecuta una instancia de SAP HANA correcta.
Prueba de la configuración del clúster
En esta sección se describe cómo se puede probar la configuración. Antes de iniciar una prueba, asegúrese de que Pacemaker no tiene ninguna acción con error (a través del estado de pcs), no hay restricciones de ubicación inesperadas (por ejemplo, restos de una prueba de migración) y que la replicación del sistema de HANA está en estado de sincronización, por ejemplo, con systemReplicationStatus.
sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"
Prueba de la migración
Estado del recurso antes de iniciar la prueba:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Puede migrar el nodo maestro de SAP HANA con el siguiente comando:
# On RHEL 7.x
pcs resource move SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource move SAPHana_HN1_03-clone --master
El clúster migraría el nodo maestro de SAP HANA y el grupo que contiene la dirección IP virtual a hn1-db-1.
Una vez finalizada la migración, la sudo pcs status salida es similar a la siguiente:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Con AUTOMATED_REGISTER="false", el clúster no reiniciaría la base de datos de HANA con errores ni la registraría en la nueva base de datos principal en hn1-db-0. En este caso, configure la instancia de HANA como secundaria mediante la ejecución de estos comandos, como hn1adm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
La migración crea restricciones de ubicación que deben eliminarse de nuevo. Ejecute el siguiente comando como raíz, o a través desudo:
pcs resource clear SAPHana_HN1_03-master
Supervise el estado del recurso de HANA mediante pcs status. Después de iniciar HANA en hn1-db-0, la salida debe ser similar a la siguiente:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Bloqueo de la comunicación de red
Estado del recurso antes de iniciar la prueba:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Ejecute la regla de firewall para bloquear la comunicación en uno de los nodos.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Cuando los nodos del clúster no se pueden comunicar entre sí, existe el riesgo de un escenario de cerebro dividido. En tales situaciones, los nodos de clúster intentan vallarse simultáneamente entre sí, lo que da lugar a una carrera de barreras. Para evitar esta situación, se recomienda establecer la propiedad priority-fencing-delay en la configuración del clúster (aplicable solo para pacemaker-2.0.4-6.el8 o superior).
Al habilitar la priority-fencing-delay propiedad , el clúster introduce un retraso en la acción de barrera específicamente en el nodo que hospeda el recurso maestro de HANA, lo que permite al nodo ganar la carrera de barreras.
Ejecute el siguiente comando para eliminar la regla de firewall:
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Prueba del agente de delimitación de Azure
Nota:
Este artículo contiene referencias a un término que Microsoft ya no utiliza. Cuando se elimine el término del software, se eliminará también de este artículo.
Estado del recurso antes de iniciar la prueba:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
Puede probar la configuración del agente de delimitación de Azure si deshabilita la interfaz de red en el nodo en el que SAP HANA está ejecutándose como maestro. Para obtener una descripción sobre cómo simular un fallo de red, consulte el artículo 79523 de la Base de conocimientos de Red Hat.
En este ejemplo, utilizamos el script net_breaker como root para bloquear todo acceso a la red:
sh ./net_breaker.sh BreakCommCmd 10.0.0.6
La máquina virtual debería ahora reiniciarse o detenerse dependiendo de la configuración de su cluster.
Si establece la stonith-action configuración offen , la máquina virtual se detiene y los recursos se migran a la máquina virtual en ejecución.
Después de volver a iniciar la máquina virtual, el recurso de SAP HANA no se podrá iniciar como secundario si estableció AUTOMATED_REGISTER="false". En este caso, configure la instancia de HANA como secundaria ejecutando este comando como usuario hn1adm :
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=03 --replicationMode=sync --name=SITE2
Vuelva a la raíz y limpie el estado con errores:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Estado del recurso después de la prueba:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Prueba de una conmutación por error manual
Estado del recurso antes de iniciar la prueba:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-0 ]
Slaves: [ hn1-db-1 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-0
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
Puede probar una conmutación por error manual deteniendo el cluster en el nodo hn1-db-0, como raíz:
pcs cluster stop
Después de la conmutación por error, puede reiniciar el clúster. Si establece AUTOMATED_REGISTER="false", el recurso de SAP HANA en el nodo hn1-db-0 no se podrá iniciar como secundario. En este caso, configure la instancia de HANA como secundaria mediante la ejecución de este comando:
pcs cluster start
Ejecute lo siguiente como hn1adm:
sapcontrol -nr 03 -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=03 --replicationMode=sync --name=SITE1
A continuación, como raíz:
# On RHEL 7.x
pcs resource cleanup SAPHana_HN1_03-master
# On RHEL 8.x
pcs resource cleanup SAPHana_HN1_03 node=<hostname on which the resource needs to be cleaned>
Estado del recurso después de la prueba:
Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_03
nc_HN1_03 (ocf::heartbeat:azure-lb): Started hn1-db-1
vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hn1-db-1