Detección de anomalías en Azure Stream Analytics
Disponible tanto en la nube como en Azure IoT Edge, Azure Stream Analytics ofrece funcionalidades de detección de anomalías integradas basadas en aprendizaje automático, que se pueden usar para supervisar las dos anomalías que se producen con más frecuencia: temporales y persistentes. Con las funciones AnomalyDetection_SpikeAndDip y AnomalyDetection_ChangePoint, puede realizar la detección de anomalías directamente en el trabajo de Stream Analytics.
Los modelos de aprendizaje automático asumen una serie temporal muestreada uniformemente. Si la serie temporal no es uniforme, puede insertar un paso de agregación con una ventana de saltos de tamaño constante antes de llamar a la detección de anomalías.
En este momento, las operaciones de aprendizaje automático no admiten las tendencias de estacionalidad ni las correlaciones múltiples variadas.
Detección de anomalías con aprendizaje automático en Azure Stream Analytics
En el siguiente vídeo se demuestra cómo detectar una anomalía en tiempo real mediante funciones con aprendizaje automático en Azure Stream Analytics.
Comportamiento del modelo
Por lo general, la precisión del modelo mejora con más datos en la ventana deslizante. Los datos de la ventana deslizante especificada se tratan como parte de su rango normal de valores para ese período. El modelo solo tiene en cuenta el historial de eventos a través de la ventana deslizante para comprobar si el evento actual es anómalo. Cuando se mueve la ventana deslizante, los valores antiguos se expulsan del entrenamiento del modelo.
Las funciones operan estableciendo un valor normal determinado en función de lo han observado hasta ahora. Los valores atípicos se identifican mediante la comparación con el valor normal establecido, en el nivel de confianza. El tamaño de ventana debe basarse en los eventos mínimos necesarios para entrenar el modelo para el comportamiento normal, con el fin de que cuando se produzca alguna anomalía, pueda reconocerlos.
El tiempo de respuesta del modelo aumenta con el tamaño del historial porque se debe comparar con un mayor número de eventos anteriores. Se recomienda incluir solo el número necesario de eventos para mejorar el rendimiento.
Las brechas en la serie temporal pueden producirse porque el modelo no recibe los eventos en determinados puntos en el tiempo. Stream Analytics controla esta situación mediante lógica de imputación. El tamaño del historial, así como una duración, en la misma ventana deslizante se usa para calcular la velocidad media a la que se esperan que lleguen los eventos.
Puede usarse el generador de anomalías que está disponible aquí para alimentar una instancia de IoT Hub con datos con distintos patrones de anomalías. Un trabajo de Azure Stream Analytics se puede configurar con estas funciones de detección de anomalías para leer de este centro de IoT y detectar anomalías.
Picos e interrupciones
A las anomalías temporales de un flujo de eventos de serie temporal se les conocen como picos e interrupciones. Los picos y las interrupciones pueden supervisarse mediante el operador basado en Machine Learning, AnomalyDetection_SpikeAndDip.
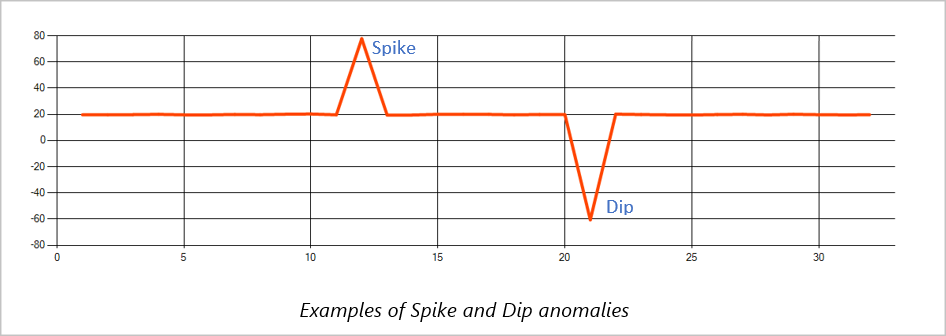
En la misma ventana deslizante, si un pico de segundo es menor que el primero, la puntuación calculada del pico más pequeño probablemente no es lo suficientemente significativo en comparación con la puntuación del primer pico en el nivel de confianza especificado. Puede intentar reducir la confianza del modelo para capturar estas anomalías. Sin embargo, si empieza a recibir demasiadas alertas, puede usar un intervalo de confianza superior.
En la siguiente consulta de ejemplo se da por supuesto una velocidad uniforme de entrada de un evento por segundo en una ventana deslizante de 2 minutos con un historial de 120 eventos. La instrucción SELECT final extrae y produce la puntuación y el estado de anomalía con un nivel de confianza del 95 %.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Cambio de puntos
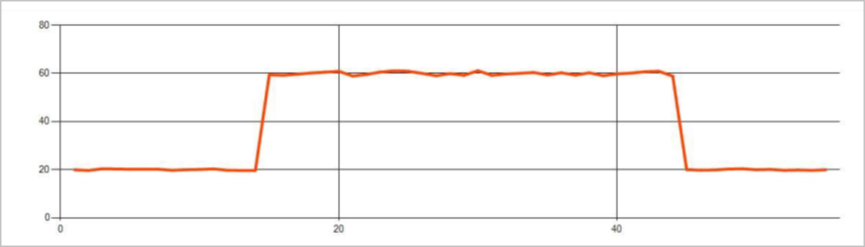
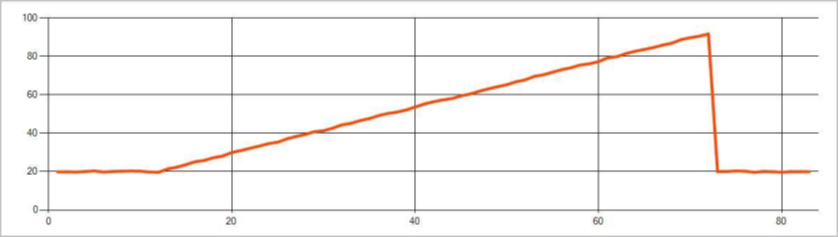
Las anomalías persistentes en un flujo de eventos de serie temporal son los cambios en la distribución de valores del flujo de eventos, como los cambios de nivel y tendencias. En Stream Analytics, estas anomalías se detectan mediante el operador AnomalyDetection_ChangePoint basado en Machine Learning.
Los cambios persistentes duran mucho más que picos y caídas y podrían indicar eventos catastróficos. Los cambios persistentes normalmente no se perciben a simple vista, pero se pueden detectar con el operador AnomalyDetection_ChangePoint.
La imagen siguiente es un ejemplo de un cambio de nivel:
La imagen siguiente es un ejemplo de un cambio de tendencia:
En la consulta de ejemplo siguiente se supone una velocidad de entrada uniforme de un evento por segundo en una ventana deslizante de 20 minutos con un tamaño de historial de 1200 eventos. La instrucción SELECT final extrae y produce la puntuación y el estado de anomalía con un nivel de confianza del 80 %.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Características de rendimiento
El rendimiento de estos modelos depende del tamaño del historial, la duración de la ventana, la carga de eventos y de si se utiliza la partición del nivel de función. En esta sección se describen estas configuraciones y se proporcionan ejemplos sobre cómo mantener las tasas de ingesta de 1 K, 5 K y 10 000 eventos por segundo.
- Tamaño del historial: estos modelos se ejecutan linealmente con el tamaño historial. Cuanto mayor sea, más tiempo tardarán los modelos en puntuar un nuevo evento. Se debe a que los modelos comparan el nuevo evento con cada uno de los eventos anteriores del búfer del historial.
- Duración de la ventana: la duración de la ventana debe reflejar cuánto tarda en recibir todos los eventos según lo especificado por el tamaño del historial. Si no hay muchos eventos en la ventana, Azure Stream Analytics imputará los valores que falten. Por lo tanto, el consumo de CPU es una función del tamaño del historial.
- Carga de eventos: cuanto mayor sea la carga de eventos, más trabajo realizarán los modelos, lo cual afecta al consumo de CPU. El trabajo se puede escalar horizontalmente de manera vergonzosamente paralela, dando por hecho que tiene sentido según la lógica de negocios usar más particiones de entrada.
- Partición del nivel de función - la partición del nivel de función se realiza mediante
PARTITION BYdentro de la llamada de la función de detección de anomalías. Este tipo de partición agrega una sobrecarga, ya que el estado debe mantenerse para varios modelos al mismo tiempo. La partición del nivel de función se usa en escenarios como la partición del nivel de dispositivo.
Relación
El tamaño del historial, la duración de ventana y la carga total de eventos están relacionados de la siguiente manera:
DuraciónDeLaVentana (en ms) = 1000 * tamañoDeHistorial/(total de eventos de entrada por segundo/número de particiones de entrada)
Al realizar la partición de la función por identificador de dispositivo, agregue "PARTITION BY deviceId" a la llamada de la función de detección de anomalías.
Observaciones
En la tabla siguiente se incluyen las observaciones de rendimiento de un solo nodo (seis SU) para el caso no particionado:
| Tamaño del historial (eventos) | Duración de la ventana (ms) | Total de eventos de entrada por segundo |
|---|---|---|
| 60 | 55 | 2200 |
| 600 | 728 | 1650 |
| 6,000 | 10 910 | 1 100 |
En la tabla siguiente se incluyen las observaciones de rendimiento de un solo nodo (seis SU) para el caso con particiones:
| Tamaño del historial (eventos) | Duración de la ventana (ms) | Total de eventos de entrada por segundo | Recuento de dispositivos |
|---|---|---|---|
| 60 | 1091 | 1 100 | 10 |
| 600 | 10 910 | 1 100 | 10 |
| 6,000 | 218 182 | <550 | 10 |
| 60 | 21 819 | 550 | 100 |
| 600 | 218 182 | 550 | 100 |
| 6,000 | 2 181 819 | <550 | 100 |
El código de ejemplo para ejecutar las configuraciones no particionadas anteriores se encuentra en el repositorio Streaming a escala de ejemplos de Azure. El código crea un trabajo de Stream Analytics sin particiones del nivel de función que usa Event Hubs como entrada y salida. La carga de entrada se genera con clientes de prueba. Cada evento de entrada es un documento JSON de 1 KB. Los eventos simulan un dispositivo IoT que envía datos JSON (hasta 1 K dispositivos). El tamaño del historial, la duración de la ventana y la carga total de eventos varían en dos particiones de entrada.
Nota:
Para lograr una estimación más precisa, personalice los ejemplos de forma que se ajusten a su escenario.
Identificación de los cuellos de botella
Para identificar cuellos de botella en la canalización, uUse el panel Métricas del trabajo de Azure Stream Analytics. Revise Eventos de entrada/salida para ver el rendimiento y Retraso de la marca de agua o Eventos de trabajos pendientes para ver si el trabajo está al día con respecto a la tasa de entrada. Para métricas de Event Hubs, busque Solicitudes limitadas y ajuste las unidades de umbral como corresponda. En lo relativo a las métricas de Azure Cosmos DB, consulte Máximo de RU/s consumidas por cada intervalo de claves de partición en Rendimiento para garantizar que los intervalos de claves de partición se consumen uniformemente. Para Azure SQL DB, supervise las E/S de registro y la CPU.