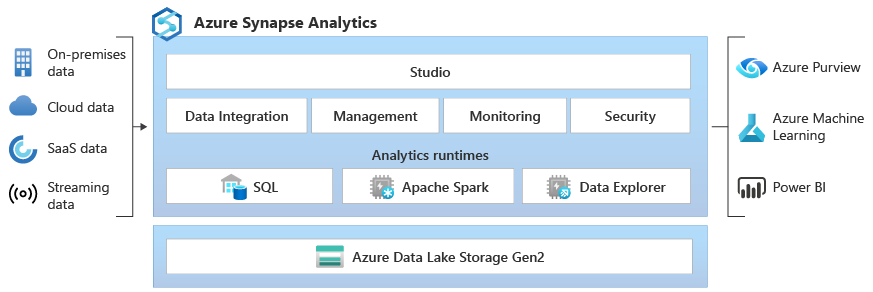
¿Qué es el Explorador de datos de Azure Synapse? (versión preliminar)
El Explorador de datos de Azure Synapse proporciona a los clientes una experiencia de consulta interactiva para desbloquear información de datos de registro y telemetría. Para complementar los motores de tiempo de ejecución de análisis de SQL y Apache Spark existentes, el tiempo de ejecución de análisis de Data Explorer está optimizado para realizar un análisis de registros eficaz gracias a una tecnología de indexación que se usa para indexar automáticamente los datos semiestructurados y de texto libre que se encuentran comúnmente en los datos de telemetría.
Para obtener más información, consulte el vídeo siguiente:
¿Qué hace único al Explorador de datos de Azure Synapse?
Ingesta sencilla: el Explorador de datos ofrece integraciones para la ingesta de datos sin código, de poco código, alto rendimiento y almacenamiento en caché de datos de orígenes en tiempo real. Los datos se pueden ingerir de orígenes como Azure Event Hubs, Kafka, Azure Data Lake, agentes de código abierto como Fluentd o Fluent Bit y una amplia variedad de orígenes de datos locales y en la nube.
Sin modelado de datos complejos: con el Explorador de datos no es necesario crear modelos de datos complejos ni crear scripts complejos para transformar los datos antes de consumirlos.
Sin mantenimiento de índices: no es necesario realizar tareas de mantenimiento a fin de optimizar los datos para el rendimiento de las consultas ni es necesario realizar el mantenimiento de los índices. Con el Explorador de datos, todos los datos sin procesar están disponibles inmediatamente, lo que le permite ejecutar consultas de alto rendimiento y alta simultaneidad en el streaming y los datos persistentes. Puede usar estas consultas para crear paneles y alertas casi en tiempo real y conectar los datos de análisis operativos con el resto de la plataforma de análisis de datos.
Democratización del análisis de datos: el Explorador de datos democratiza el análisis de datos de autoservicio con el lenguaje intuitivo de consulta Kusto (KQL) que proporciona la expresividad y la eficacia de SQL con la simplicidad de Excel. KQL está completamente optimizado para explorar telemetría sin procesar y datos de series temporales, ya que aprovecha la mejor tecnología de indexación de texto del Explorador de datos para realizar una búsqueda eficiente de texto libre y expresiones regulares, así como capacidades de análisis integrales para consultar seguimientos, datos de texto y datos semiestructurados JSON, incluidas matrices y estructuras anidadas. KQL le ofrece compatibilidad avanzada con series temporales para crear, manipular y analizar varias series temporales con compatibilidad de ejecución de Python en el motor para la puntuación de modelos.
Tecnología probada a escala de petabytes: el Explorador de datos es un sistema distribuido con recursos de proceso y almacenamiento que se puede escalar de forma independiente, lo que le permite realizar análisis en gigabytes o petabytes de datos.
Integrado: Azure Synapse Analytics proporciona interoperabilidad entre los datos de los motores del Explorador de datos, Apache Spark y SQL, lo que permite a los ingenieros, científicos y analistas de datos acceder y colaborar de forma fácil y segura en los mismos datos del lago de datos.
¿Cuándo usar el Explorador de datos de Azure Synapse?
Use el Explorador de datos como una plataforma de datos para crear soluciones de análisis de registros y análisis de IoT casi en tiempo real para:
Consolidar y correlacionar los datos de registros y eventos entre orígenes de datos locales, en la nube y de terceros.
Acelerar el recorrido de las operaciones de inteligencia artificial (reconocimiento de patrones, detección de anomalías, previsión, etc.).
Reemplazar las soluciones de búsqueda de registros basadas en infraestructuras para ahorrar costos y aumentar la productividad.
Compilar soluciones de análisis de IoT para los datos de IoT.
Compilar soluciones de SaaS de análisis para ofrecer servicios a los clientes internos y externos.
Arquitectura de los grupos del Explorador de datos
Los grupos del Explorador de datos implementan una arquitectura de escalabilidad horizontal con la separación de los recursos de procesos y de almacenamiento. Esto le permite escalar cada recurso de forma independiente y, por ejemplo, ejecutar varios procesos de solo lectura en los mismos datos. Los grupos del Explorador de datos consisten en un conjunto de recursos de procesos que ejecutan el motor responsable de indexar, comprimir, almacenar en caché y atender consultas distribuidas de forma automática. También tienen un segundo conjunto de recursos de procesos que ejecutan el servicio de administración de datos responsable de los trabajos del sistema en segundo plano y la ingesta de datos administrados y en cola. Todos los datos se conservan en cuentas de almacenamiento de blobs administradas mediante un formato de columnas comprimido.
Los grupos del Explorador de datos admiten un ecosistema rico para la ingesta de datos mediante conectores, SDK, API de REST y otras capacidades administradas. Ofrece varias maneras de consumir datos para consultas ad hoc, informes, paneles, alertas, API de REST y SDK.
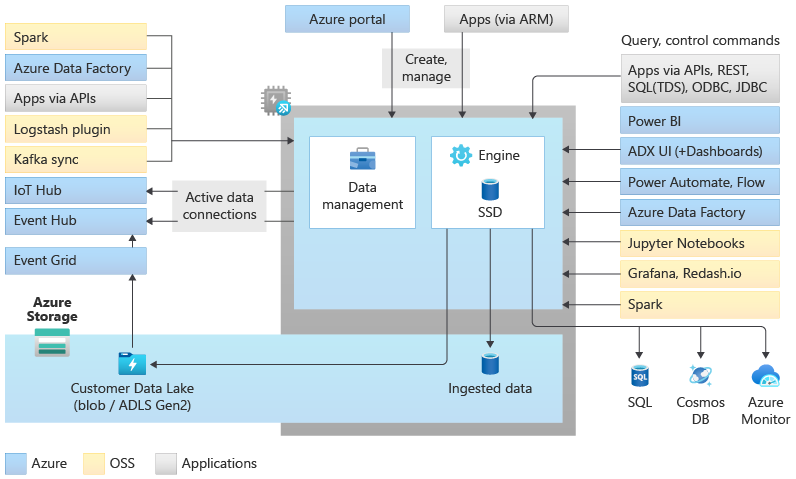
Hay muchas funcionalidades únicas que hacen que el Explorador de datos sea el mejor motor analítico para el análisis de registros y series temporales en Azure.
En las secciones siguientes se resaltan las diferencias clave.
La indexación de datos semiestructurados y de texto libre permite un alto rendimiento casi en tiempo real y la realización de un gran número de consultas simultáneas
El Explorador de datos indexa datos semiestructurados (JSON) y datos no estructurados (texto libre) que hacen que las consultas en ejecución sean muy eficaces en este tipo de datos. De forma predeterminada, cada campo se indexa durante la ingesta de datos con la opción de usar una directiva de codificación de bajo nivel a fin de ajustar o deshabilitar el índice para campos específicos. El ámbito del índice es una sola partición de datos.
La implementación del índice depende del tipo del campo, tal como se muestra a continuación:
| Tipo de campo | Implementación de la indexación |
|---|---|
| String | El motor genera un índice de término invertido para los valores de columna de la cadena. Cada valor de cadena se analiza y divide en términos normalizados y se registra una lista ordenada de posiciones lógicas, que contienen elementos ordinales de registro para cada término. La lista ordenada resultante de términos y sus posiciones asociadas se almacena como un árbol B inmutable. |
|
Numérico DateTime TimeSpan |
El motor compila un índice de avance simple basado en intervalos. El índice registra los valores mínimo y máximo de cada bloque, de un grupo de bloques y de toda la columna de la partición de datos. |
| Dinámica | El proceso de ingesta enumera todos los elementos "atómicos" dentro del valor dinámico, como nombres de propiedad, valores y elementos de matriz, y los reenvía al generador de índices. Los campos dinámicos tienen el mismo índice de término invertido que los campos de cadena. |
Estas funcionalidades de indexación eficaces permiten al Explorador de datos hacer que los datos estén disponibles casi en tiempo real para realizar consultas de alto rendimiento y alta simultaneidad. El sistema optimiza automáticamente las particiones de datos para aumentar aún más el rendimiento.
Lenguaje de consulta Kusto
KQL tiene una comunidad grande y creciente gracias a la rápida adopción de Log Analytics de Azure Monitor, Application Insights, Microsoft Sentinel, Azure Data Explorer y otras ofertas de Microsoft. El lenguaje está bien diseñado con una sintaxis fácil de leer y proporciona una transición sin problemas desde consultas simples de una línea, a consultas complejas de procesamiento de datos. Esto permite al Explorador de datos proporcionar una gran compatibilidad con IntelliSense y un amplio conjunto de funciones integradas y de construcciones de lenguaje para agregaciones, series temporales y análisis de usuarios que no están disponibles en SQL para la exploración rápida de los datos de telemetría.