Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Synapse Analytics ofrece varios motores de análisis que le ayudarán a ingerir, transformar, modelar, analizar y distribuir sus datos. Un grupo de Apache Spark proporciona funcionalidades de proceso de macrodatos de código abierto. Después de crear un grupo de Apache Spark en el área de trabajo de Synapse, los datos se pueden cargar, modelar, procesar y distribuir para tener información para los análisis más rápidamente.
En este inicio rápido, va a aprender a usar Azure Portal para crear un trabajo de Apache Spark en un área de trabajo de Synapse.
Importante
La facturación de las instancias de Spark se prorratea por minuto, tanto si se usan como si no. Asegúrese de cerrar la instancia de Spark después de que haya terminado de usarla, o configure un breve tiempo de espera. Para obtener más información, consulte la sección Limpieza de recursos de este artículo.
Si no tiene una suscripción a Azure, cree una cuenta gratuita antes de empezar.
Prerrequisitos
- Necesitará una suscripción a Azure. Si es necesario, crea una cuenta gratuita de Azure
- Usará el área de trabajo de Synapse.
Inicio de sesión en Azure Portal
Inicie sesión en el Portal de Azure
Vaya al área de trabajo de Synapse
Vaya al área de trabajo de Synapse en la que se va a crear el grupo de Apache Spark. Para ello, escriba el nombre del servicio (o el nombre del recurso directamente) en la barra de búsqueda.
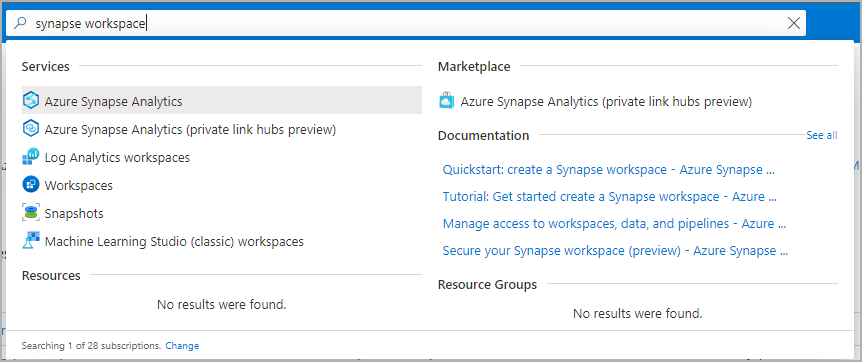
En la lista de áreas de trabajo, escriba el nombre (o una parte del nombre) del área que desea abrir. En este ejemplo, se usa un área de trabajo denominado contosoanalytics.
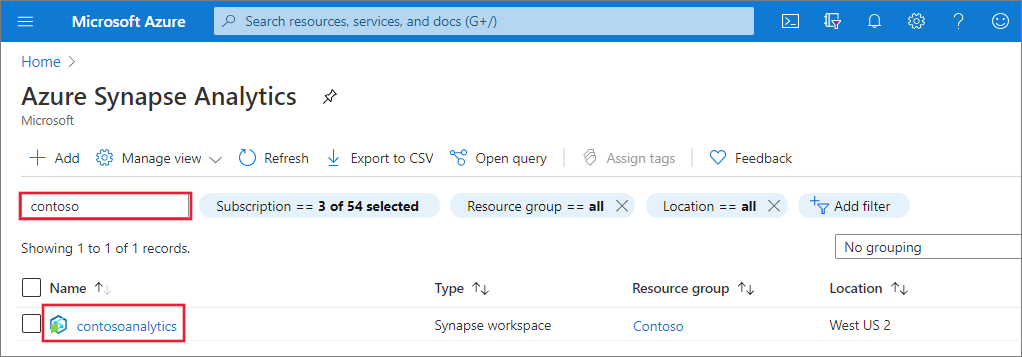


Creación de un grupo de Apache Spark
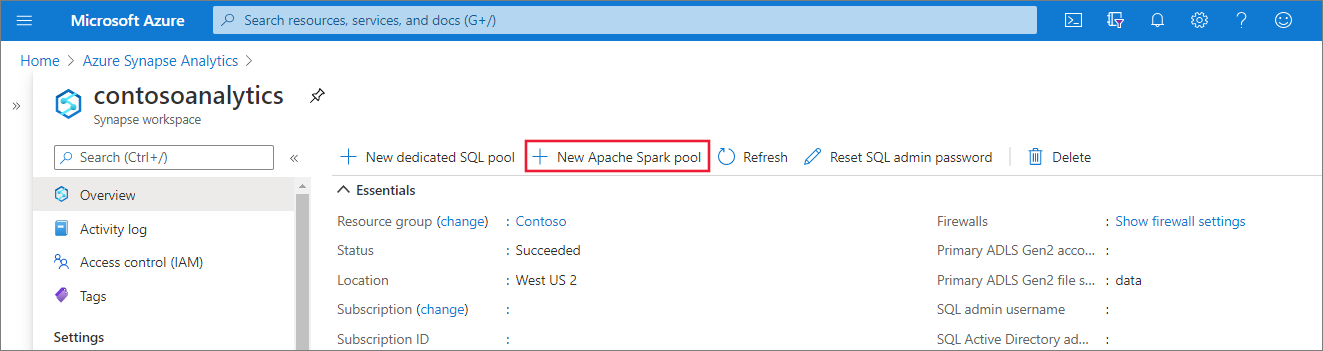
En el área de trabajo de Synapse en la que desee crear el grupo de Apache Spark, seleccione New Apache Spark pool (Nuevo grupo de Apache Spark) en la barra superior.
Escriba la siguiente información en la pestaña Datos básicos.
Configuración Valor sugerido Descripción Nombre del grupo de Apache Spark Un nombre de grupo válido, como contososparkEste es el nombre que tendrá el grupo de Apache Spark. Tamaño del nodo Pequeño (4 vCPU/32 GB) Establézcalo en el tamaño más pequeño para reducir los costos de este inicio rápido Autoscale Deshabilitado En este inicio rápido no se necesita la escalabilidad automática Número de nodos 5 Use un tamaño pequeño para limitar los costos en este inicio rápido 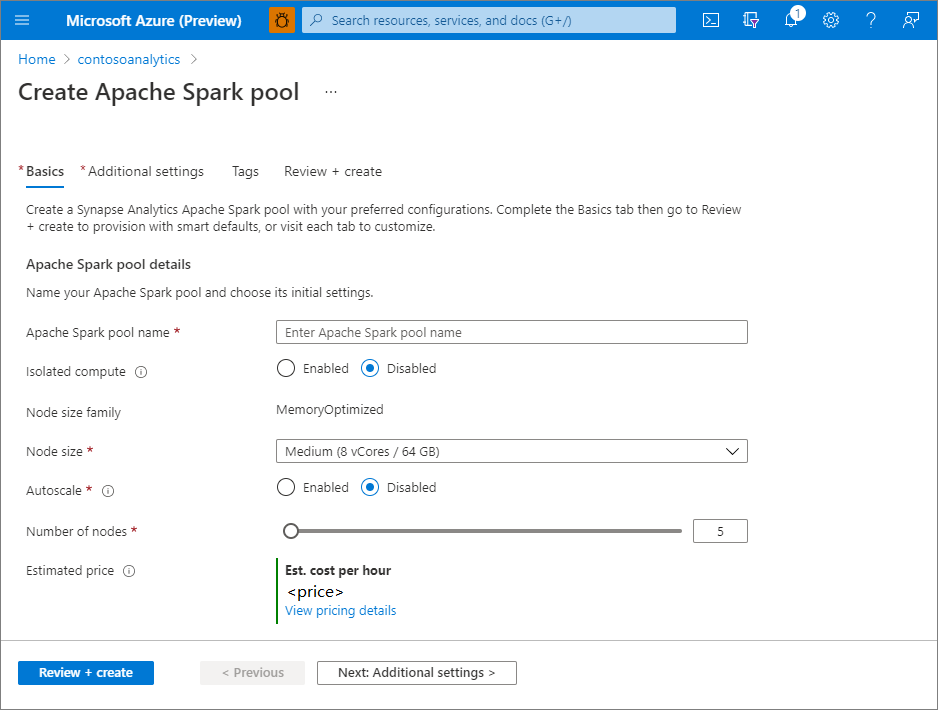
Importante
Existen limitaciones específicas para los nombres que pueden usar los grupos de Apache Spark. Los nombres solo deben contener letras o números, deben tener 15 caracteres o menos, deben comenzar con una letra, no contener palabras reservadas y ser únicos en el área de trabajo.
Seleccione Siguiente: Configuración adicional y examine la configuración predeterminada. No modifique ninguna configuración predeterminada.
Seleccione Siguiente: etiquetas. Considere la posibilidad de usar etiquetas de Azure. Por ejemplo, la etiqueta "Propietario" o "Creado por" para identificar quién creó el recurso, y la etiqueta "Entorno" para identificar si este recurso se encuentra en producción, desarrollo, etc. Para obtener más información, consulte Desarrolle su estrategia de nomenclatura y etiquetado para los recursos de Azure.
Selecciona Revisar + crear.
Asegúrese de que los detalles son correctos en función de lo que se especificó anteriormente y seleccione Create (Crear).
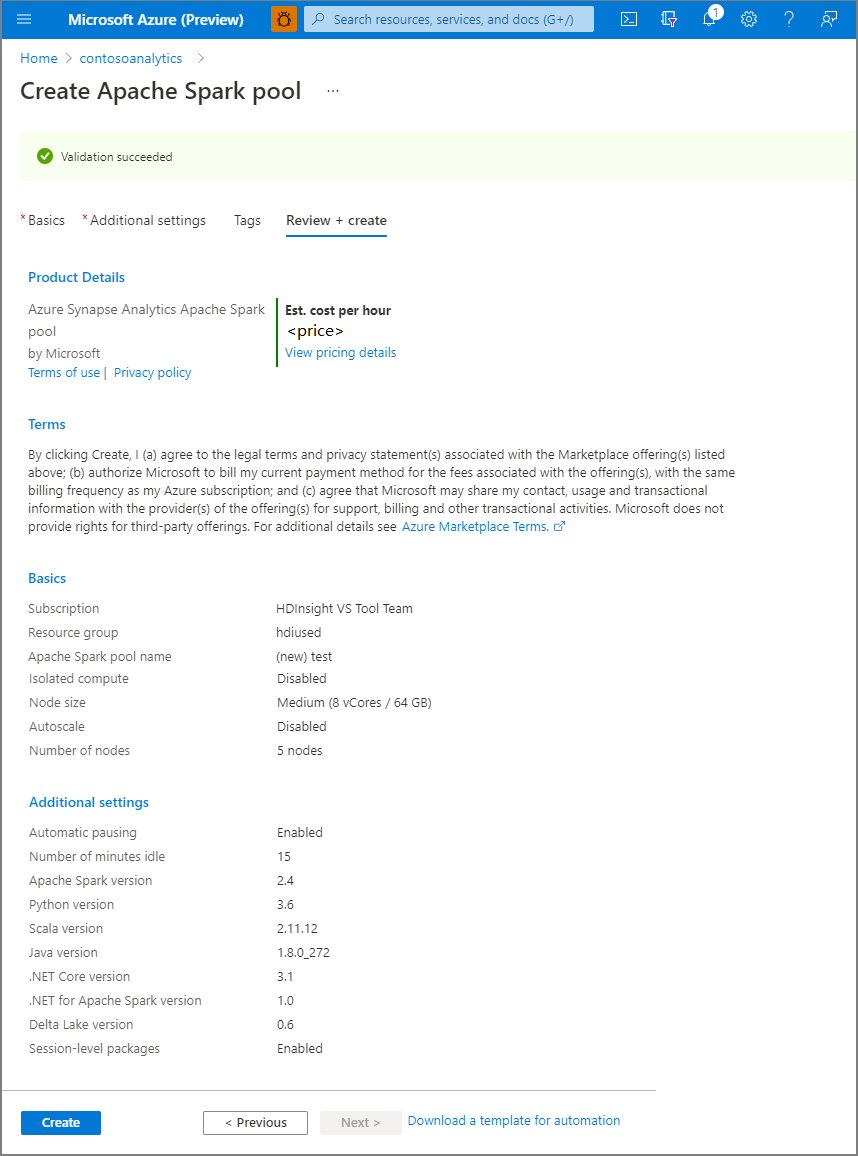
Llegados a este punto, se iniciará el flujo de aprovisionamiento de recursos, que mandará una indicación al finalizar.
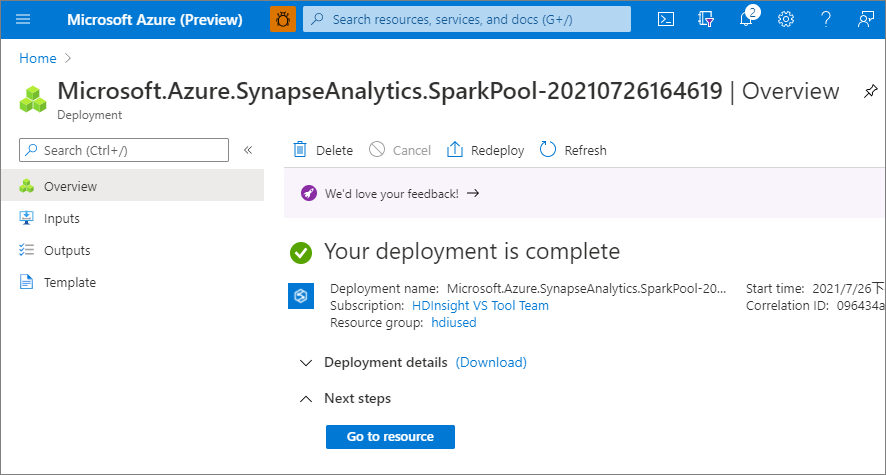
Una vez completado el aprovisionamiento, al desplazarse al área de trabajo se mostrará una nueva entrada para el grupo de Apache Spark recién creado.
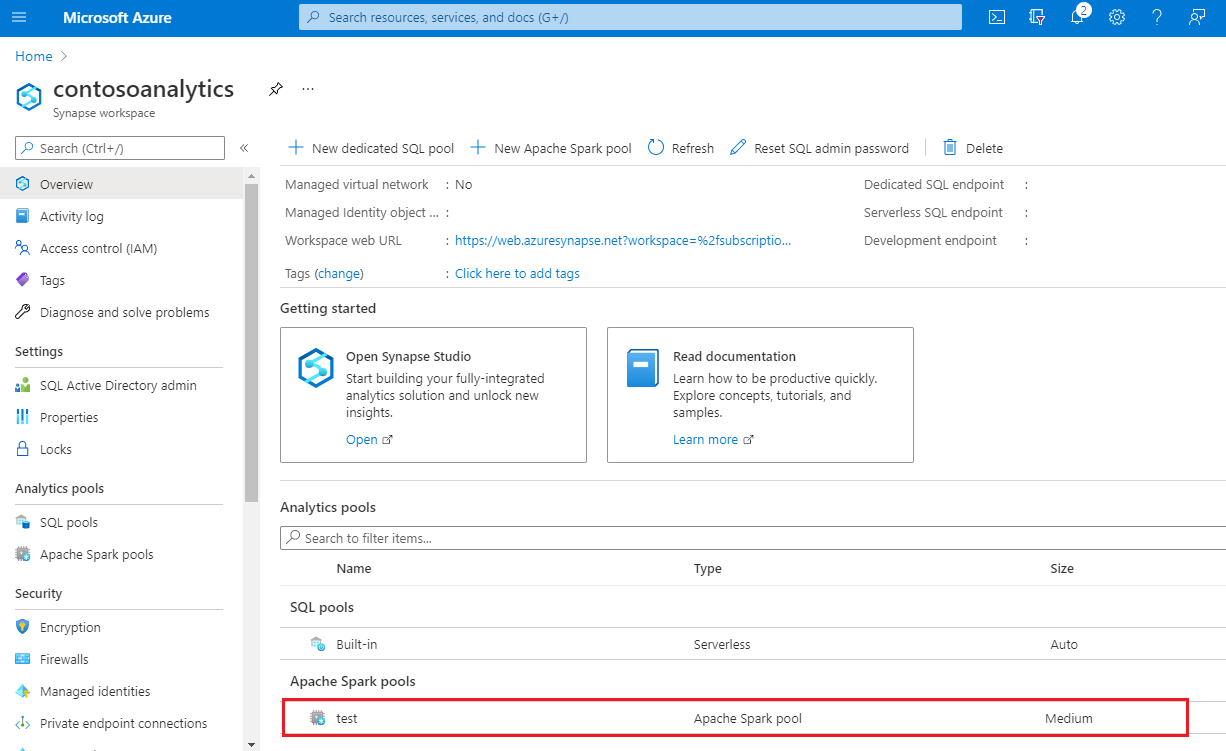
En este momento, no hay ningún recurso en ejecución, sin cargos por Spark, y ha creado metadatos sobre las instancias de Spark que desea crear.







Limpieza de recursos
En los siguientes pasos se elimina el grupo de Apache Spark del área de trabajo.
Advertencia
Al eliminar un grupo de Apache Spark, se quitará el motor de análisis del área de trabajo. Ya no será posible conectarse al grupo de SQL y todas las consultas, canalizaciones y cuadernos que usen este grupo de Apache Spark dejarán de funcionar.
Si está seguro de que quiere eliminar el grupo de Apache Spark, siga estos pasos:
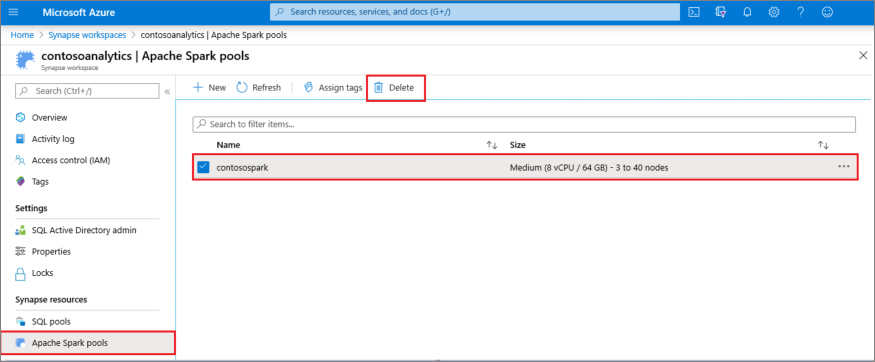
- Vaya al panel Grupos de Apache Spark en el área de trabajo.
- Seleccione el grupo de Apache Spark que se va a eliminar (en este caso, contosospark).
- Seleccione Eliminar.
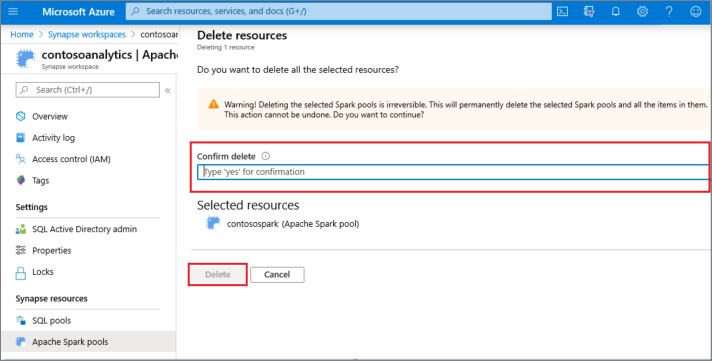
- Confirme la eliminación y seleccione el botón Eliminar.
- Cuando el proceso se complete correctamente, el grupo de Apache Spark dejará de aparecer en los recursos del área de trabajo.
