Tutorial: Creación de una aplicación Apache Spark con IntelliJ mediante un área de trabajo de Synapse
En este tutorial se muestra cómo usar el complemento de Azure Toolkit for IntelliJ para desarrollar aplicaciones Apache Spark escritas en Scala y enviarlas a continuación a un grupo de Apache Spark sin servidor directamente desde el entorno de desarrollo integrado (IDE) de IntelliJ. Puede usar el complemento de varias maneras:
- Desarrollar y enviar una aplicación Spark en Scala a un grupo de Spark.
- Acceder a los recursos de los grupos de Spark.
- Desarrollar y ejecutar localmente una aplicación Spark en Scala.
En este tutorial, aprenderá a:
- Usar el complemento Azure Toolkit for IntelliJ
- Desarrollar aplicaciones de Apache Spark
- Envío de una aplicación a grupos de Spark
Requisitos previos
Complemento de Azure Toolkit 3.27.0-2019.2: instalación desde el Repositorio de complementos de IntelliJ
Complemento de Scala: instalación desde el Repositorio de complementos de IntelliJ.
El requisito previo siguiente es solo para los usuarios de Windows:
Mientras se ejecuta la aplicación Spark en Scala local en un equipo Windows, puede producirse una excepción, como se explica en SPARK-2356. Esta excepción se produce porque falta WinUtils.exe en Windows. Para solucionar este error, descargue el archivo ejecutable WinUtils y guárdelo en una ubicación como C:\WinUtils\bin. Después, agregue una variable de entorno HADOOP_HOME y establezca el valor de la variable en C:\WinUtils.
Creación de una aplicación Spark en Scala para un grupo de Spark
Inicie IntelliJ IDEA y seleccione Create New Project (Crear proyecto) para abrir la ventana New Project (Nuevo proyecto).
Seleccione Azure Spark/HDInsight en el panel izquierdo.
Seleccione Spark Project with Samples (Scala) (Proyecto de Spark con ejemplos [Scala]) en la ventana principal.
En la lista desplegable Build tool (Herramienta de compilación), seleccione uno de los siguientes tipos:
- Maven: para agregar compatibilidad con el asistente para la creación de proyectos de Scala.
- SBT para administrar las dependencias y compilar el proyecto de Scala.

Seleccione Next (Siguiente).
En la ventana New Project (Nuevo proyecto), proporcione la siguiente información:
Propiedad Descripción Nombre de proyecto Escriba un nombre. En este tutorial se usa myApp.Ubicación del proyecto Escriba la ubicación deseada para guardar el proyecto. Project SDK (SDK del proyecto) Podría quedarse en blanco la primera vez que se usa IDEA. Seleccione New... (Nuevo...) y vaya a su JDK. Versión de Spark El asistente de creación integra la versión adecuada de los SDK de Spark y Scala. Aquí puedes elegir la versión de Spark que necesites. 
Seleccione Finalizar. El proyecto puede tardar unos minutos en estar disponible.
El proyecto de Spark crea automáticamente un artefacto. Para ver el artefacto, haga lo siguiente:
a. En la barra de menús, vaya a Archivo>Estructura del proyecto... .
b. En la ventana Estructura del proyecto, seleccione Artefactos.
c. Seleccione Cancelar después de ver el artefacto.

Busque LogQuery en myApp>src>main>scala>sample>LogQuery. En este tutorial se usa LogQuery para la ejecución.

Conexión a los grupos de Spark
Inicie sesión en la suscripción de Azure para conectarse a los grupos de Spark.
Inicie sesión en la suscripción de Azure
En la barra de menús, vaya a Ver>Ventanas de herramientas>Azure Explorer.

En Azure Explorer, haga clic con el botón derecho en el nodo Azure y después seleccione Iniciar sesión.
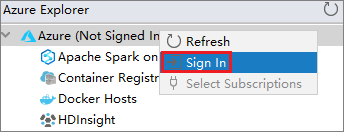
En el cuadro de diálogo de inicio de sesión en Azure, seleccione Inicio de sesión del dispositivo y, a continuación, Iniciar sesión.

En el cuadro de diálogo Inicio de sesión del dispositivo de Azure, seleccione Copiar y abrir.

En la interfaz del explorador, pegue el código y, a continuación, seleccione Siguiente.

Escriba sus credenciales de Azure y, a continuación, cierre el explorador.

Cuando haya iniciado sesión, en el cuadro de diálogo Select Subscriptions (Seleccionar suscripciones) se enumeran todas las suscripciones de Azure asociadas a las credenciales. Seleccione la suscripción y, a continuación, elija Seleccionar.

En Azure Explorer, expanda Apache Spark en Synapse para ver las áreas de trabajo de las suscripciones.

Para ver los grupos de Spark, puede expandir un área de trabajo.

Ejecución remota de una aplicación Spark en Scala en un grupo de Spark
Después de crear una aplicación en Scala, puede ejecutarla de forma remota.
Seleccione el icono para abrir la ventana Configuraciones de ejecución/depuración.

En el ventana de diálogo Configuraciones de ejecución/depuración, seleccione + y, a continuación, elija Apache Spark en Synapse.

En la ventana Configuraciones de ejecución/depuración, proporcione los valores siguientes y, a continuación, seleccione Aceptar:
Propiedad Value Grupos de Spark Seleccione los grupos de Spark en los que quiere ejecutar la aplicación. Seleccione un artefacto para enviarlo Deje la configuración predeterminada. Nombre de clase principal el valor predeterminado es la clase principal del archivo seleccionado. Puede cambiar la clase si selecciona los puntos suspensivos ( ... ) y elige otra clase. Configuraciones del trabajo Puede cambiar las claves y valores predeterminados. Para más información, consulte API de REST de Apache Livy. Argumentos de la línea de comandos Puede especificar los argumentos divididos por un espacio para la clase principal, si es necesario. Archivos jar a los que se hace referencia y archivos a los que se hace referencia puede escribir las rutas de acceso de los archivos y los Jar a los que se hace referencia, si los hubiera. También puede examinar archivos en el sistema de archivos virtual de Azure, que actualmente solo admite el clúster de ADLS Gen2. Para obtener más información: Configuración de Apache Spark y Cómo cargar recursos en el clúster. Almacenamiento de carga del trabajo Expanda para mostrar opciones adicionales. Tipo de almacenamiento Seleccione Use Azure Blob to upload (Usar Azure Blob para cargar) o Use cluster default storage account to upload (Usar la cuenta de almacenamiento predeterminada del clúster para cargar). Cuenta de almacenamiento Escriba su cuenta de Storage. Clave de almacenamiento Escriba su clave de almacenamiento. Contenedor de almacenamiento Seleccione su contenedor de almacenamiento en la lista desplegable una vez que se hayan escrito Cuenta de Storage y Clave de almacenamiento. 
Seleccione el icono SparkJobRun para enviar el proyecto al grupo de Spark seleccionado. La pestaña Remote Spark Job in Cluster (Trabajo de Spark remoto en clúster) muestra el progreso de la ejecución del trabajo en la parte inferior. Puede detener la aplicación si selecciona el botón rojo.


Ejecución/depuración local de aplicaciones Apache Spark
Puede seguir las instrucciones siguientes para configurar la ejecución local y la depuración local para el trabajo de Apache Spark.
Escenario 1: Ejecución local
Abra el cuadro de diálogo Configuraciones de ejecución/depuración y seleccione el signo más (+). A continuación, seleccione la opción Apache Spark en Synapse. Escriba la información de Nombre y Nombre de clase principal para guardar.

- Las variables de entorno y la ubicación de WinUtils.exe son solo para los usuarios de Windows.
- Variables de entorno: la variable de entorno del sistema se puede detectar automáticamente si se ha establecido antes y no es necesario agregarla manualmente.
- Ubicación de WinUtils.exe: para especificar la ubicación de WinUtils, seleccione el icono de carpeta de la derecha.
A continuación, seleccione el botón de reproducción local.

Una vez completada la ejecución local, si el script incluye una salida, puede comprobar el archivo de salida desde data>default.

Escenario 2: Depuración local
Abra el script LogQuery y establezca puntos de interrupción.
Seleccione el icono Depuración local para realizar la depuración local.

Acceso y administración del área de trabajo de Synapse
Puede realizar diferentes operaciones en Azure Explorer dentro de Azure Toolkit for IntelliJ. En la barra de menús, vaya a Ver>Ventanas de herramientas>Azure Explorer.
Inicio del área de trabajo
En Azure Explorer, vaya a Apache Spark en Synapse y, a continuación, expándalo.
Haga clic con el botón derecho en un área de trabajo y, a continuación, seleccione Iniciar área de trabajo, se abrirá el sitio web.


Consola de Spark
Puede ejecutar la consola local de Spark (Scala) o la consola de sesión interactiva de Spark Livy (Scala).
Consola local de Spark (Scala)
Asegúrese de que cumple el requisito previo de WINUTILS.EXE.
En la barra de menús, vaya a Ejecutar>Editar configuraciones...
En la ventana Configuraciones de ejecución/depuración, en el panel izquierdo, vaya a Apache Spark en Synapse>[Spark en Synapse] myApp.
En la ventana principal, seleccione la pestaña Ejecutar de forma local.
Proporcione los valores siguientes y seleccione Aceptar:
Propiedad Value Variables de entorno Asegúrese de que el valor de HADOOP_HOME sea correcto. Ubicación de WINUTILS.exe Asegúrese de que la ruta de acceso sea correcta. 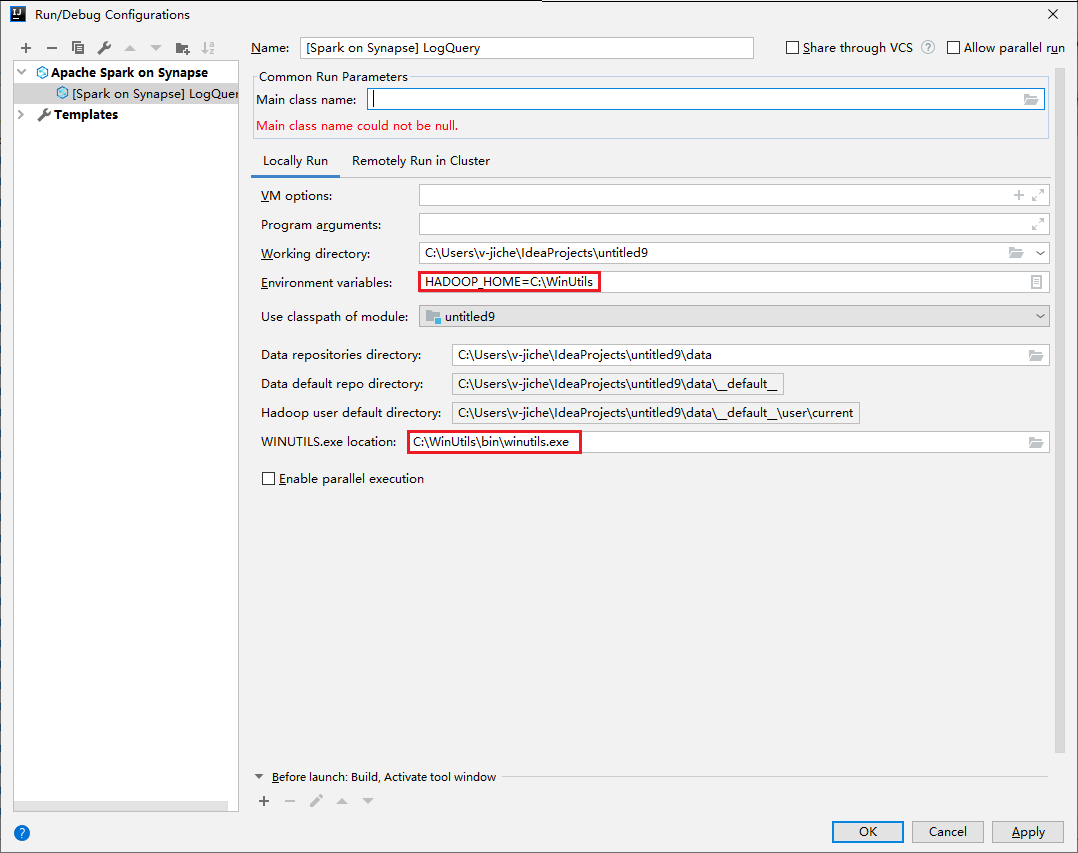
En el proyecto, vaya a myApp>src>main>scala>myApp.
En la barra de menús, vaya a Herramientas>Consola de Spark>Ejecutar consola local de Spark (Scala) .
Pueden aparecer dos cuadros de diálogo para preguntarle si quiere corregir automáticamente las dependencias. Si es así, seleccione Autocorrección.


El aspecto de la consola debería ser similar al de la siguiente imagen. En la ventana de la consola, escriba
sc.appNamey presione CTRL + Entrar. Se muestra el resultado. Para detener la consola local, seleccione el botón rojo.
Consola de sesión interactiva de Spark Livy (Scala)
Solo se admite en IntelliJ 2018.2 y 2018.3.
En la barra de menús, vaya a Ejecutar>Editar configuraciones...
En la ventana Configuraciones de ejecución/depuración, en el panel izquierdo, vaya a Apache Spark en Synapse>[Spark en Synapse] myApp.
En la ventana principal, seleccione la pestaña Remotely Run in Cluster (Ejecutar en clúster de forma remota).
Proporcione los valores siguientes y seleccione Aceptar:
Propiedad Value Nombre de clase principal Seleccione el nombre de clase Main. Grupos de Spark Seleccione los grupos de Spark en los que quiere ejecutar la aplicación. 
En el proyecto, vaya a myApp>src>main>scala>myApp.
En la barra de menús, vaya a Herramientas>Consola de Spark>Ejecutar consola de sesión interactiva de Spark Livy (Scala) .
El aspecto de la consola debería ser similar al de la siguiente imagen. En la ventana de la consola, escriba
sc.appNamey presione CTRL + Entrar. Se muestra el resultado. Para detener la consola local, seleccione el botón rojo.
Envío de la selección a la consola de Spark
Puede ver el resultado del script si envía algún código a la consola local o la consola de sesión interactiva de Livy (Scala). Para hacerlo, puede resaltar parte del código en el archivo de Scala y hacer clic con el botón derecho en Enviar selección a consola de Spark. El código seleccionado se envía a la consola y se ejecuta. El resultado se muestra después del código en la consola. La consola comprobará si hay errores.
