Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Tip
Microsoft Fabric Data Warehouse es un almacenamiento relacional de escala empresarial en una base de lago de datos, con una arquitectura lista para el futuro, inteligencia artificial integrada y nuevas características. Si no está familiarizado con el almacenamiento de datos, comience con Fabric Data Warehouse. Las cargas de trabajo del grupo de SQL dedicadas pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
Una tabla externa apunta a datos ubicados en Hadoop, Azure Storage Blob o Azure Data Lake Storage (ADLS).
Puede usar tablas externas para leer datos de archivos o escribir datos en archivos en Azure Storage. Con Azure Synapse SQL se pueden usar tablas externas para leer datos externos mediante un grupo de SQL dedicado o un grupo de SQL sin servidor.
En función del tipo de origen de datos externo, puede usar dos tipos de tablas externas:
- Tablas externas de Hadoop, que puede usar para leer y exportar datos en varios formatos de datos, como CSV, Parquet y ORC. Las tablas externas de Hadoop están disponibles en los grupos de SQL dedicados, pero no en los grupos de SQL sin servidor.
- Tablas externas nativas, que puede usar para leer y exportar datos en varios formatos de datos, como CSV y Parquet. Las tablas externas nativas están disponibles en los grupos de SQL sin servidor y en los grupos de SQL dedicados. La escritura y exportación de datos mediante CETAS y las tablas externas nativas solo está disponible en el grupo de SQL sin servidor, pero no en los grupos de SQL dedicados.
Principales diferencias entre Hadoop y las tablas externas nativas.
| Tipo de tabla externa | Hadoop | Nativa |
|---|---|---|
| Grupo de SQL dedicado | Disponible | Solo Parquet |
| Grupo de SQL sin servidor | No disponible | Disponible |
| Formatos compatibles | Delimited/CSV, Parquet, ORC, Hive RC y RC | Grupo de SQL sin servidor: delimitado/CSV, Parquet y Delta Lake Grupo de SQL dedicado: Parquet |
| Eliminación de particiones de carpetas | No | La eliminación de particiones solo está disponible en las tablas con particiones creadas en formatos Parquet y CSV que se sincronizan desde grupos de Apache Spark. Puede crear tablas externas en carpetas con particiones de Parquet, pero las columnas de creación de particiones son inaccesibles y se omitirán, y la eliminación de particiones no se aplicará. No cree tablas externas en carpetas de Delta Lake, ya que no se admiten. Use vistas con particiones Delta si tiene que consultar datos de Delta Lake con particiones. |
| Eliminación de archivos (pushdown de predicados) | No | Sí en pools SQL sin servidor. Para permitir la delegación de cadenas, debe usar la intercalación Latin1_General_100_BIN2_UTF8 en las columnas VARCHAR. Para obtener más información sobre las intercalaciones, consulte Compatibilidad con la intercalación de bases de datos para Synapse SQL en Azure Synapse Analytics. |
| Formato personalizado para la ubicación | No | Sí, con caracteres comodín como /year=*/month=*/day=* para los formatos Parquet y CSV. Las rutas de acceso a carpetas personalizadas no están disponibles en Delta Lake. En el grupo de SQL sin servidor, también es posible usar caracteres comodín /logs/** recursivos para hacer referencia a archivos Parquet y CSV en cualquier subcarpeta debajo de la carpeta a la que se haga referencia. |
| Examen recursivo de carpetas | Sí | Sí. En grupos de SQL sin servidor debe especificarse /** al final de la ruta de acceso de ubicación. En Grupo dedicado, las carpetas siempre se examinan de manera recursiva. |
| Autenticación del almacenamiento | Clave de acceso de almacenamiento (SAK), acceso directo de Microsoft Entra, identidad administrada, identidad de aplicación personalizada de Microsoft Entra | Firma de acceso compartido (SAS), tránsito de Microsoft Entra, identidad administrada, identidad de aplicación personalizada de Microsoft Entra. |
| Asignación de columnas | Ordinal: las columnas de la definición de tabla externa se asignan a las columnas de los archivos Parquet subyacentes por posición. | Grupo sin servidor: por nombre. Las columnas de la definición de tabla externa se asignan a las columnas de los archivos Parquet subyacentes por coincidencia de nombre de columna. Grupo dedicado: coincidencia ordinal. Las columnas de la definición de tabla externa se asignan a las columnas de los archivos Parquet subyacentes por posición. |
| CETAS (exportación/transformación) | Sí | CETAS con las tablas nativas como destino solo funciona en el grupo de SQL sin servidor. No se pueden usar los grupos de SQL dedicados para exportar datos mediante tablas nativas. |
Nota:
Las tablas externas nativas son la solución recomendada en los grupos en los que están disponibles con carácter general. Si necesita acceder a datos externos, use siempre las tablas nativas en grupos sin servidor o dedicados. Use las tablas de Hadoop solo si necesita acceder a algunos tipos que no se admitan en tablas externas nativas (por ejemplo: ORC, RC) o si la versión nativa no estuviera disponible.
Tablas externas en un grupo de SQL dedicado y en un grupo de SQL sin servidor
Puede usar tablas externas para:
- Consultar Azure Blob Storage y ADLS Gen2 con consultas Transact-SQL.
- Almacenar los resultados de las consultas en archivos de Azure Blob Storage o Azure Data Lake Storage mediante CETAS con Synapse SQL.
- Importar datos de Azure Blob Storage y Azure Data Lake Storage y almacenarlos en un grupo de SQL dedicado (solo tablas de Hadoop en un grupo dedicado).
Nota:
Si se usa con la instrucción CREATE TABLE AS SELECT, al realizar la selección desde una tabla externa se importarán los datos en una tabla de un grupo de SQL dedicado.
Si el rendimiento de las tablas externas de Hadoop en los grupos dedicados no satisficiera los objetivos de rendimiento, considere la posibilidad de cargar datos externos en las tablas de almacenamiento de datos mediante la instrucción COPY.
Si desea ver un tutorial de carga, consulte el artículo en el que se explica el uso de PolyBase para cargar datos de Azure Blob Storage.
Para crear tablas externas en grupos de Synapse SQL, siga estos pasos:
- CREAR ORIGEN DE DATOS EXTERNO para hacer referencia a un almacenamiento externo de Azure y especificar la credencial que se debe usar para acceder al almacenamiento.
- CREATE EXTERNAL FILE FORMAT para describir el formato de archivos CSV o Parquet.
- CREATE EXTERNAL TABLE sobre los archivos colocados en la fuente de datos con el mismo formato de archivo.
Eliminación de particiones de carpetas
Las tablas externas nativas de los grupos de Synapse pueden omitir los archivos colocados en las carpetas que no sean pertinentes para las consultas. Si los archivos se almacenan en una jerarquía de carpetas (por ejemplo, /year=2020/month=03/day=16) y los valores para year, month y day se exponen como las columnas, las consultas que contienen filtros como year=2020 leerán los archivos solo desde las subcarpetas colocadas dentro de la carpeta year=2020. En esta consulta, se omitirán los archivos y las carpetas colocados en otras carpetas (year=2021 o year=2022). Esta eliminación se conoce como eliminación de particiones.
La eliminación de las particiones de una carpeta está disponible en las tablas externas nativas que se encuentran sincronizadas de los grupos de Spark de Synapse. Si tiene conjuntos de datos particionados y desea usar la eliminación de particiones con las tablas externas que cree, utilice las vistas particionadas en lugar de las tablas externas.
Eliminación de archivos
Algunos formatos de datos, como Parquet y Delta, contienen estadísticas de archivos para cada columna (por ejemplo, valores mínimos y máximos para cada columna). Las consultas que filtran datos no leerán los archivos en los que no existan los valores de columna necesarios. En primer lugar, la consulta explorará los valores mínimos y máximos de las columnas que se usen en el predicado de la consulta para buscar los archivos que no contengan los datos necesarios. Estos archivos se omitirán y se eliminarán del plan de consulta.
Esta técnica también se conoce como delegación de predicados de filtros y puede mejorar el rendimiento de las consultas. La delegación de filtros está disponible en los grupos de SQL sin servidor en formatos Parquet y Delta. Si quiere aplicar la delegación de filtros para los tipos de cadena, utilice el tipo VARCHAR con la intercalación Latin1_General_100_BIN2_UTF8. Para obtener más información sobre las intercalaciones, consulte Compatibilidad con la intercalación de bases de datos para Synapse SQL en Azure Synapse Analytics.
Seguridad
El usuario debe tener permiso SELECT en una tabla externa para leer los datos.
Las tablas externas acceden al almacenamiento de Azure subyacente mediante la credencial con ámbito de base de datos definida en el origen de datos mediante las siguientes reglas:
- El origen de datos sin credenciales permite que las tablas externas accedan a archivos disponibles públicamente en Azure Storage.
- El origen de datos puede tener una credencial que permita a las tablas externas acceder solo a los archivos de Azure Storage mediante el token de SAS o la identidad administrada del área de trabajo. Para consultar ejemplos, consulte el artículo sobre el desarrollo del control de acceso al almacenamiento de archivos.
Observaciones
Para garantizar la ejecución confiable de consultas, los archivos de origen y las carpetas a los que hacen referencia las tablas externas deben permanecer sin cambios durante la duración de la operación.
- Modificar, eliminar o reemplazar los archivos o carpetas a los que se hace referencia mientras se ejecuta la consulta puede provocar errores o provocar resultados incoherentes.
- Antes de consultar tablas externas en un grupo de SQL dedicado, compruebe que todos los datos de origen son estables y no se modificarán durante la ejecución.
Ejemplo de CREATE EXTERNAL DATA SOURCE
En el ejemplo siguiente se crea un origen de datos externo de Hadoop en un grupo de SQL dedicado para ADLS Gen2 que apunta al conjunto de datos de Nueva York:
CREATE DATABASE SCOPED CREDENTIAL [ADLS_credential]
WITH IDENTITY='SHARED ACCESS SIGNATURE',
SECRET = 'sv=2022-11-02&ss=b&srt=co&sp=rl&se=2042-11-26T17:40:55Z&st=2024-11-24T09:40:55Z&spr=https&sig=DKZDuSeZhuCWP9IytWLQwu9shcI5pTJ%2Fw5Crw6fD%2BC8%3D'
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH
-- Please note the abfss endpoint when your account has secure transfer enabled
( LOCATION = 'abfss://data@newyorktaxidataset.dfs.core.windows.net' ,
CREDENTIAL = ADLS_credential ,
TYPE = HADOOP
) ;
En el ejemplo siguiente se crea un origen de datos externo para Azure Data Lake Storage Gen2 que apunta al conjunto de datos de Nueva York disponible públicamente:
CREATE EXTERNAL DATA SOURCE YellowTaxi
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/',
TYPE = HADOOP)
Ejemplo de CREATE EXTERNAL FILE FORMAT
En el ejemplo siguiente se crea un formato de archivo externo para los archivos del censo:
CREATE EXTERNAL FILE FORMAT census_file_format
WITH
(
FORMAT_TYPE = PARQUET,
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
Ejemplo de CREATE EXTERNAL TABLE
En el ejemplo siguiente se crea una tabla externa. Devuelve la primera fila:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
)
GO
SELECT TOP 1 * FROM census_external_table
Creación y consulta de tablas externas a partir de un archivo en Azure Data Lake
Mediante las funcionalidades de exploración de Data Lake de Synapse Studio ya es posible crear y consultar tablas externas mediante un grupo de Synapse SQL haciendo clic con el botón derecho en el archivo. El gesto de un solo clic para crear tablas externas desde la cuenta de almacenamiento de ADLS Gen2 solo se admite para los archivos con formato Parquet.
Requisitos previos
Debe tener acceso al área de trabajo con al menos el rol de acceso
Storage Blob Data Contributora la cuenta de ADLS Gen2 o a las listas de control de acceso (ACL) que le permiten consultar los archivos.Debe tener al menos permisos para crear una tabla externa y consultar tablas externas en el grupo de Synapse SQL (dedicado o sin servidor).
En el panel Data (Datos), seleccione el archivo desde el que desea crear la tabla externa:

Se abrirá una ventana de diálogo. Seleccione un grupo de SQL dedicado o sin servidor, asígnele un nombre a la tabla y seleccione Abrir script:
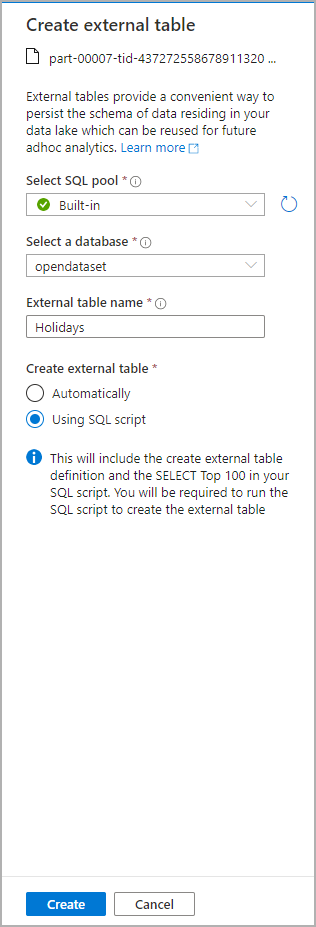
El script de SQL se genera automáticamente e infiere el esquema del archivo:

Ejecute el script. El script ejecutará automáticamente un SELECT TOP 100 *:

Ahora se crea la tabla externa. Ahora puede consultar la tabla externa directamente desde el panel de datos.
Contenido relacionado
Consulte el artículo CETAS para obtener información sobre cómo guardar los resultados de una consulta en una tabla externa en Azure Storage. O bien puede empezar a consultar Tablas externas de Apache Spark para Azure Synapse.