Migración de Time Series Insights Gen2 a inteligencia en tiempo real en Microsoft Fabric
Nota:
El servicio Time Series Insights se retirará el 7 de julio de 2024. Considere la posibilidad de migrar los entornos existentes a otras soluciones lo antes posible. Para más información sobre la entrada en desuso y la migración, consulte nuestra documentación.
Información general
Eventhouse es la base de datos de series temporales en Inteligencia en tiempo real. Sirve como destino para migrar datos fuera de Time Series Insights.
Recomendaciones generales de migración.
| Característica | Migración recomendada |
|---|---|
| Ingesta de JSON desde el centro con aplanado y caracteres de escape | Obtener datos de Azure Event Hubs |
| Almacenamiento de acceso esporádico abierto | Disponibilidad de Eventhouse OneLake |
| Conector de Power BI | Use el Conector de Power BI de Eventhouse. Reescritura manual de TSQ en KQL. |
| Conector de Spark | Migre datos a Eventhouse. Uso de un cuaderno con Apache Spark para consultar una Eventhouse o Explorar los datos de su instancia de Lakehouse con un cuaderno |
| Carga masiva | Obtención de datos de Azure Storage |
| Modelo de Time Series | Se puede exportar como archivo JSON. Se puede importar a Eventhouse. Semántica de grafos de Kusto permiten la jerarquía de modelos, recorridos y análisis de modelos de serie temporal como gráfico |
| Explorador de series temporales | Panel en tiempo real, informe de Power BI o escribir un panel personalizado mediante KustoTrender |
| Lenguaje de consulta | Reescritura de consultas en KQL. |
Migración de telemetría
Para recuperar la copia de todos los datos del entorno, use PT=Time carpeta en la cuenta de almacenamiento. Para más información, consulte Almacenamiento de datos.
Paso 1 de la migración: Obtención de estadísticas sobre los datos de telemetría
Data
- Información general del entorno
- Registrar el identificador de entorno de la primera parte del FQDN de acceso a datos (por ejemplo, d390b0b0-1445-4c0c-8365-68d6382c1c2a desde .env.crystal-dev.windows-int.net)
- Información general del entorno -> Configuración del almacenamiento -> Cuenta de almacenamiento
- Uso del Explorador de Storage para obtener estadísticas de carpetas
- Tamaño de registro y número de blobs de la carpeta
PT=Time.
- Tamaño de registro y número de blobs de la carpeta
Paso 2 de migración: Migración de datos a Eventhouse
Creación de instancia de Eventhouse
Para configurar un centro de eventos para el proceso de migración, siga los pasos descritos en creación de un Eventhouse.
Ingesta de datos
Para recuperar datos de la cuenta de almacenamiento correspondiente a la instancia de Time Series Insights, siga los pasos descritos en Obtener datos de Azure Storage.
Asegúrese de todo esto:
Seleccione el contenedor adecuado y proporcione su URI, junto con el token de SAS o la clave de cuenta necesario.
Configure la ruta de acceso de carpeta de filtros de archivos como
V=1/PT=Timepara filtrar los blobs pertinentes.Compruebe el esquema inferido y quite las columnas consultadas con poca frecuencia, mientras conserva al menos la marca de tiempo, las columnas TSID y los valores. Para asegurarse de que todos los datos se copian en Eventhouse, agregue otra columna y use la transformación de asignación de DropMappedFields.
Complete el proceso de ingesta.
Consultas de datos
Ahora que ingerió correctamente los datos, puede empezar a explorarlos mediante un conjunto de consultas KQL. Si necesita acceder a los datos desde la aplicación cliente personalizada, Eventhouse proporciona SDK para lenguajes de programación principales, como C# (vínculo), Java (vínculo) y Node.js (vínculo).
Migración del modelo de serie temporal a Azure Data Explorer
El modelo se puede descargar en formato JSON desde el entorno de TSI mediante la experiencia de usuario del explorador de TSI o la API de Batch de TSM. A continuación, el modelo se puede importar a Eventhouse.
Descargue el TSM desde la experiencia de usuario de TSI.
Elimine las tres primeras líneas con Visual Studio Code u otro editor.
Con Visual Studio Code u otro editor, busque y reemplace como regex
\},\n \{con}{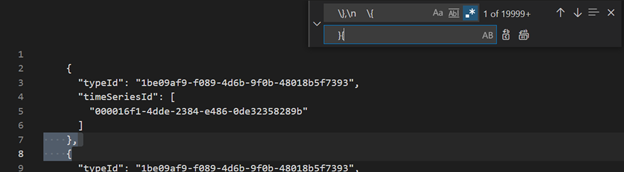
Ingiera como JSON en ADX como una tabla independiente mediante Obtener datos de un solo archivo.


Una vez que haya migrado los datos de serie temporal a Eventhouse en Fabric Real-Time Intelligence, puede usar la eficacia de Semántica de Kusto Graph para contextualizar y analizar los datos. La semántica de Kusto Graph permite modelar, recorrer y analizar la jerarquía del modelo de serie temporal como gráfico. Mediante la semántica de Kusto Graph, puede obtener información sobre las relaciones entre diferentes entidades de los datos de serie temporal, como activos, sitios y puntos de datos. Estas conclusiones le ayudan a comprender las dependencias e interacciones entre varios componentes del sistema.
Traducción de consultas de serie temporal (TSQ) a KQL
GetEvents
{
"getEvents": {
"timeSeriesId": [
"assest1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where assetId_string == "assest1" and siteId_string == "siteId1" and dataid_string == "dataId1"
| take 10000
GetEvents con filtro
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'status' AND $event.sensors.unit.String = 'ONLINE"
}
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| where ['sensors.sensor_string'] == "status" and ['sensors.unit_string'] == "ONLINE"
| take 10000
GetEvents con variable proyectada
{
"getEvents": {
"timeSeriesId": [
"deviceId1",
"siteId1",
"dataId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:0.0000000Z",
"to": "2021-11-05T00:00:00.000000Z"
},
"inlineVariables": {},
"projectedVariables": [],
"projectedProperties": [
{
"name": "sensors.value",
"type": "String"
},
{
"name": "sensors.value",
"type": "bool"
},
{
"name": "sensors.value",
"type": "Double"
}
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:0.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.000000Z)
| where deviceId_string== "deviceId1" and siteId_string == "siteId1" and dataId_string == "dataId1"
| take 10000
| project timestamp, sensorStringValue= ['sensors.value_string'], sensorBoolValue= ['sensors.value_bool'], sensorDoublelValue= ['sensors.value_double']
AggregateSeries
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
AggregateSeries con filtro
{
"aggregateSeries": {
"timeSeriesId": [
"deviceId1"
],
"searchSpan": {
"from": "2021-11-01T00:00:00.0000000Z",
"to": "2021-11-05T00:00:00.0000000Z"
},
"filter": {
"tsx": "$event.sensors.sensor.String = 'heater' AND $event.sensors.location.String = 'floor1room12'"
},
"interval": "PT1M",
"inlineVariables": {
"sensor": {
"kind": "numeric",
"value": {
"tsx": "coalesce($event.sensors.value.Double, todouble($event.sensors.value.Long))"
},
"aggregation": {
"tsx": "avg($value)"
}
}
},
"projectedVariables": [
"sensor"
]
}
}
events
| where timestamp >= datetime(2021-11-01T00:00:00.0000000Z) and timestamp < datetime(2021-11-05T00:00:00.0000000Z)
| where deviceId_string == "deviceId1"
| where ['sensors.sensor_string'] == "heater" and ['sensors.location_string'] == "floor1room12"
| summarize avgSensorValue= avg(coalesce(['sensors.value_double'], todouble(['sensors.value_long']))) by bin(IntervalTs = timestamp, 1m)
| project IntervalTs, avgSensorValue
Power BI
No hay ningún proceso automatizado para migrar informes de Power BI basados en Time Series Insights. Todas las consultas que dependen de los datos almacenados en Time Series Insights deben migrarse a Eventhouse.
Para crear informes de series temporales eficaces en Power BI, se recomienda hacer referencia a los siguientes artículos de blog informativos:
- Funcionalidades de series temporales de Eventhouse en Power BI
- Uso de parámetros dinámicos de M sin más limitaciones
- Valores de duración y intervalo de tiempo en KQL, Power Query y Power BI
- Configuración de consulta KQL en Power BI
- Filtrado y visualización de datos de Kusto en la hora local
- Informes casi en tiempo real en PBI + Kusto
- Modelado de Power BI con ADX: hoja de referencia rápida
Consulte estos recursos para obtener instrucciones sobre cómo crear informes de series temporales eficaces en Power BI.
Panel en tiempo real
Un panel en tiempo real de Fabric es una colección de iconos, organizados opcionalmente en páginas, donde cada icono tiene una consulta subyacente y una representación visual. Puede exportar de forma nativa consultas de Lenguaje de consulta Kusto (KQL) a un panel como objetos visuales y modificar posteriormente sus consultas subyacentes y formato visual según sea necesario. Además de facilitar la exploración de los datos, esta experiencia de panel totalmente integrada proporciona un mejor rendimiento de consulta y visualización.
Empiece por crear un nuevo panel en Fabric Real-Time Intelligence. Esta eficaz característica le permite explorar datos, personalizar objetos visuales, aplicar formato condicional y utilizar parámetros. Además, puede crear alertas directamente desde los paneles en tiempo real, lo que mejora las funcionalidades de supervisión. Para obtener instrucciones detalladas sobre cómo crear un panel, consulte la documentación oficial.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de