Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Obtenga información sobre cómo usar un modelo ONNX previamente entrenado en ML.NET para detectar objetos en imágenes.
El entrenamiento de un modelo de detección de objetos desde cero requiere establecer millones de parámetros, una gran cantidad de datos de entrenamiento etiquetados y una gran cantidad de recursos de proceso (cientos de horas de GPU). Usar un modelo preentrenado permite acortar el proceso de entrenamiento.
En este tutorial, aprenderá a:
- Comprender el problema
- Obtenga información sobre qué es ONNX y cómo funciona con ML.NET
- Descripción del modelo
- Reutiliza el modelo entrenado previamente
- Detección de objetos con un modelo cargado
Prerrequisitos
- Visual Studio 2022 o posterior.
- paquete NuGet de Microsoft.ML
- Paquete NuGet Microsoft.ML.ImageAnalytics
- Paquete NuGet de Microsoft.ML.OnnxTransformer
- Modelo YOLOv2 Tiny entrenado previamente
- Netron (opcional)
Introducción al ejemplo de detección de objetos ONNX
En este ejemplo se crea una aplicación de consola de .NET Core que detecta objetos dentro de una imagen mediante un modelo ONNX de aprendizaje profundo previamente entrenado. El código de este ejemplo se puede encontrar en el repositorio dotnet/machinelearning-samples en GitHub.
¿Qué es la detección de objetos?
La detección de objetos es un problema de computer vision. Aunque está estrechamente relacionado con la clasificación de imágenes, la detección de objetos realiza la clasificación de imágenes a una escala más granular. La detección de objetos localiza y clasifica las entidades dentro de las imágenes. Los modelos de detección de objetos suelen entrenarse mediante redes neuronales y aprendizaje profundo. Consulte Aprendizaje profundo frente al aprendizaje automático para obtener más información.
Use la detección de objetos cuando las imágenes contengan varios objetos de tipos diferentes.

Algunos casos de uso para la detección de objetos incluyen:
- Coches Autónomos
- Robótica
- Detección de caras
- Seguridad en el lugar de trabajo
- Recuento de objetos
- Reconocimiento de actividad
Selección de un modelo de aprendizaje profundo
El aprendizaje profundo es un subconjunto del aprendizaje automático. Para entrenar modelos de aprendizaje profundo, se requieren grandes cantidades de datos. Los patrones de los datos se representan mediante una serie de capas. Las relaciones de los datos se codifican como conexiones entre las capas que contienen pesos. Cuanto mayor sea el peso, más fuerte será la relación. En conjunto, esta serie de capas y conexiones se conocen como redes neuronales artificiales. Cuantos más capas de una red, más profunda es, lo que lo convierte en una red neuronal profunda.
Hay diferentes tipos de redes neuronales, la más común es perceptrón multicapa (MLP), red neuronal convolucional (CNN) y red neuronal recurrente (RNN). El más básico es el MLP, que asigna un conjunto de entradas a un conjunto de salidas. Esta red neuronal es buena cuando los datos no tienen un componente espacial o de tiempo. La CNN usa capas convolucionales para procesar información espacial contenida en los datos. Un buen caso de uso para los CNN es el procesamiento de imágenes para detectar la presencia de una característica en una región de una imagen (por ejemplo, ¿hay una nariz en el centro de una imagen?). Por último, los RNN permiten que la persistencia del estado o la memoria puedan usarse como entrada. Los RNN se usan para el análisis de series temporales, donde es importante el orden secuencial y el contexto de los eventos.
Descripción del modelo
La detección de objetos es una tarea de procesamiento de imágenes. Por consiguiente, la mayoría de los modelos de aprendizaje profundo entrenados para resolver este problema son redes neuronales convolucionales (CNN). El modelo usado en este tutorial es el modelo Tiny YOLOv2, una versión más compacta del modelo YOLOv2 descrito en el documento: "YOLO9000: Better, Faster, Stronger" de Redmon y Farhadi. Tiny YOLOv2 se entrena en el conjunto de datos Pascal VOC y se compone de 15 capas que pueden predecir 20 clases diferentes de objetos. Dado que Tiny YOLOv2 es una versión condensada del modelo YOLOv2 original, se produce un equilibrio entre la velocidad y la precisión. Las distintas capas que componen el modelo se pueden visualizar mediante herramientas como Netron. La inspección del modelo produciría una asignación de las conexiones entre todas las capas que componen la red neuronal, donde cada capa contendrá el nombre de la capa junto con las dimensiones de la entrada y salida correspondientes. Las estructuras de datos usadas para describir las entradas y salidas del modelo se conocen como tensores. Los tensores se pueden considerar como contenedores que almacenan datos en N dimensiones. En el caso de Tiny YOLOv2, el nombre de la capa de entrada es image y espera un tensor de dimensiones 3 x 416 x 416. El nombre de la capa de salida es grid y genera un tensor de salida de dimensiones 125 x 13 x 13.
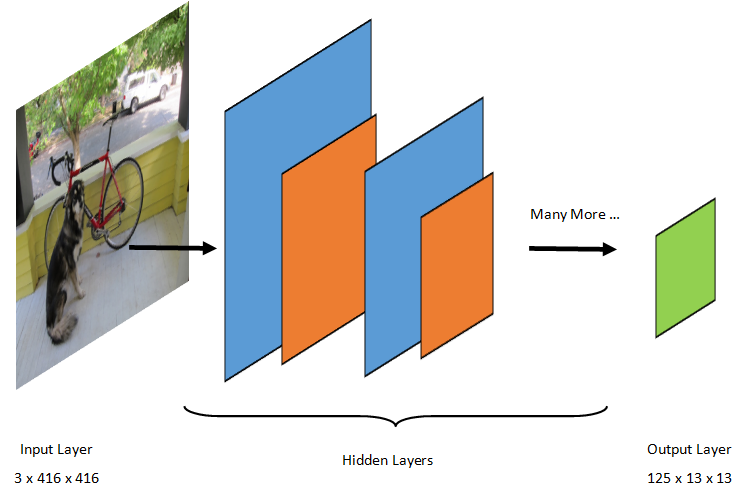
El modelo YOLO toma una imagen 3(RGB) x 416px x 416px. El modelo toma esta entrada y la pasa a través de las distintas capas para generar una salida. La salida divide la imagen de entrada en una 13 x 13 cuadrícula, con cada celda de la cuadrícula compuesta por 125 valores.
¿Qué es un modelo ONNX?
Open Neural Network Exchange (ONNX) es un formato de código abierto para los modelos de IA. ONNX admite la interoperabilidad entre marcos. Esto significa que puede entrenar un modelo en uno de los muchos marcos de aprendizaje automático populares, como PyTorch, convertirlo en formato ONNX y consumir el modelo ONNX en un marco diferente, como ML.NET. Para obtener más información, visite el sitio web de ONNX.

El modelo tiny YOLOv2 previamente entrenado se almacena en formato ONNX, una representación serializada de las capas y patrones aprendidos de esas capas. En ML.NET, la interoperabilidad con ONNX se logra con los paquetes ImageAnalytics NuGetOnnxTransformer. El ImageAnalytics paquete contiene una serie de transformaciones que toman una imagen y la codifican en valores numéricos que se pueden usar como entrada en una canalización de predicción o entrenamiento. El OnnxTransformer paquete aprovecha el entorno de ejecución de ONNX para cargar un modelo ONNX y usarlo para realizar predicciones basadas en la entrada proporcionada.
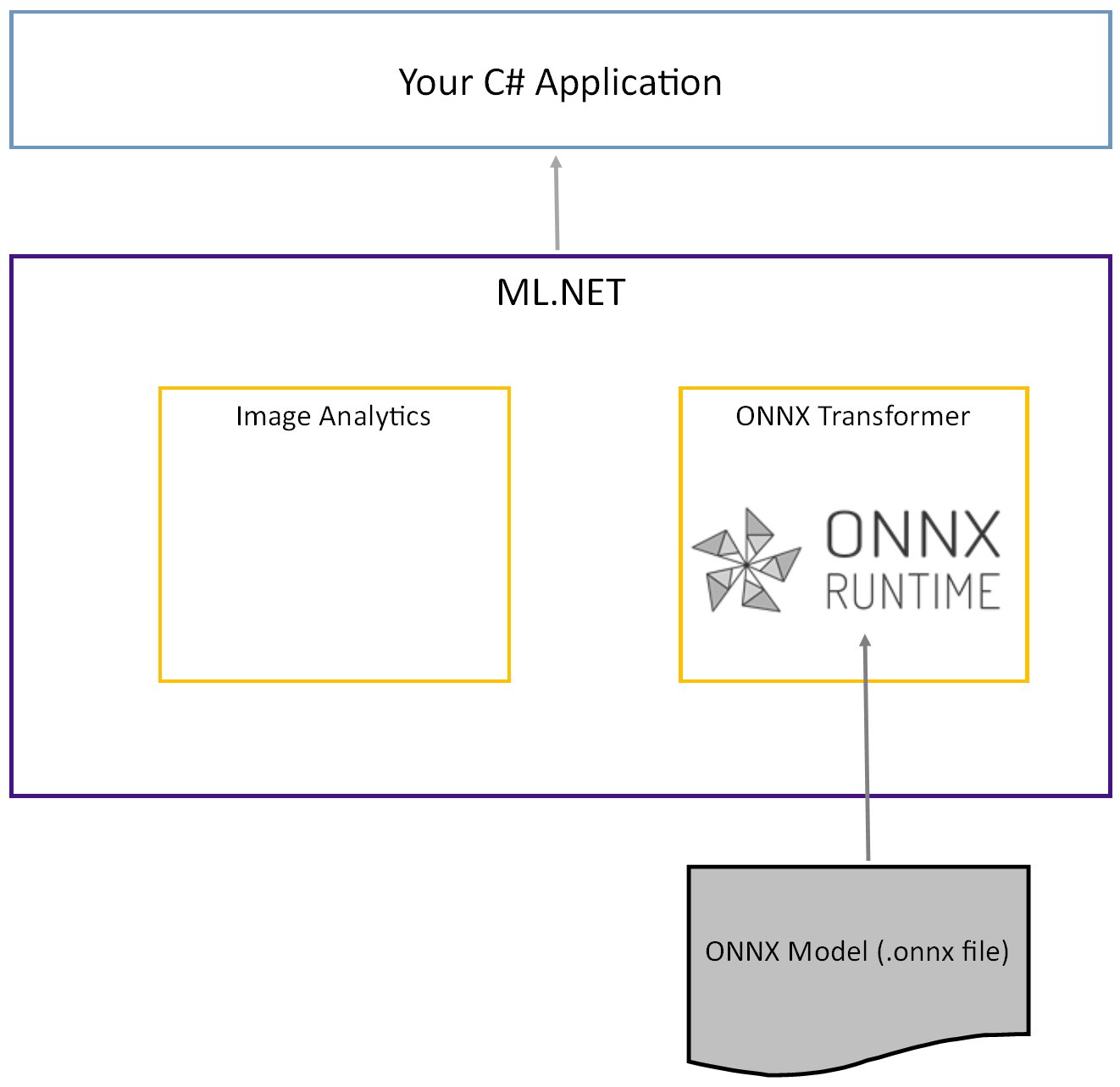
Configuración del proyecto de consola de .NET
Ahora que tiene un conocimiento general de lo que es ONNX y cómo funciona Tiny YOLOv2, es el momento de compilar la aplicación.
Creación de una aplicación de consola
Cree una aplicación de consola de C# denominada "ObjectDetection". Haga clic en el botón Siguiente .
Elija .NET 8 como marco de trabajo que se va a usar. Haga clic en el botón Crear.
Instale el paquete NuGet de Microsoft.ML:
Nota:
En este ejemplo se usa la versión estable más reciente de los paquetes NuGet mencionados a menos que se indique lo contrario.
- En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Administrar paquetes NuGet.
- Elija "nuget.org" como origen del paquete, seleccione la pestaña Examinar y busque Microsoft.ML.
- Seleccione el botón Instalar .
- Seleccione el botón Aceptar en el cuadro de diálogo Vista previa de cambios y, a continuación, seleccione el botón Acepto en el cuadro de diálogo Aceptación de licencia si está de acuerdo con los términos de licencia de los paquetes enumerados.
- Repita estos pasos para Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer y Microsoft.ML.OnnxRuntime.
Preparación de los datos y el modelo entrenado previamente
Descargue el archivo ZIP del directorio de recursos del proyecto y descomprima.
Copie el directorio
assetsen su directorio del proyecto ObjectDetection. Este directorio y sus subdirectorios contienen los archivos de imagen (excepto el modelo Tiny YOLOv2, que descargará y agregará en el paso siguiente) necesario para este tutorial.Descarga el modelo Tiny YOLOv2 del ONNX Model Zoo.
Copie el archivo en el
model.onnxdirectorio del proyectoassets\Modely cámbielo porTinyYolo2_model.onnx. Este directorio contiene el modelo necesario para este tutorial.En el Explorador de soluciones, haga clic con el botón derecho en cada uno de los archivos del directorio de recursos y subdirectorios y seleccione Propiedades. En Avanzado, cambie el valor de Copiar al directorio de salida a Copiar si es más reciente.
Creación de clases y definición de rutas de acceso
Abra el archivo Program.cs y agregue las siguientes directivas adicionales using a la parte superior del archivo:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
A continuación, defina las rutas de acceso de los distintos recursos.
En primer lugar, cree el
GetAbsolutePathmétodo en la parte inferior del archivo Program.cs .string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }A continuación, debajo de las
usingdirectivas, cree campos para almacenar la ubicación de los recursos.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Agregue un nuevo directorio al proyecto para almacenar los datos de entrada y las clases de predicción.
En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Agregar>nueva carpeta. Cuando aparezca la nueva carpeta en el Explorador de soluciones, asígnela el nombre "DataStructures".
Cree la clase de datos de entrada en el directorio DataStructures recién creado.
En el Explorador de soluciones, haga clic con el botón derecho en el directorio DataStructures y seleccione Agregar>nuevo elemento.
En el cuadro de diálogo Agregar nuevo elemento , seleccione Clase y cambie el campo Nombre a ImageNetData.cs. A continuación, seleccione Agregar.
El archivo ImageNetData.cs se abre en el editor de código. Agregue la siguiente
usingdirectiva a la parte superior de ImageNetData.cs:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Quite la definición de clase existente y agregue el código siguiente para la
ImageNetDataclase al archivo ImageNetData.cs :public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDataes la clase de datos de imagen de entrada y tiene los siguientes String campos:-
ImagePathcontiene la ruta de acceso donde se almacena la imagen. -
Labelcontiene el nombre del archivo.
Además,
ImageNetDatacontiene un métodoReadFromFileque carga varios archivos de imagen almacenados en laimageFolderruta de acceso especificada y los devuelve como una colección deImageNetDataobjetos.-
Cree la clase de predicción en el directorio DataStructures .
En el Explorador de soluciones, haga clic con el botón derecho en el directorio DataStructures y seleccione Agregar>nuevo elemento.
En el cuadro de diálogo Agregar nuevo elemento , seleccione Clase y cambie el campo Nombre a ImageNetPrediction.cs. A continuación, seleccione Agregar.
El archivo ImageNetPrediction.cs se abre en el editor de código. Agregue la siguiente
usingdirectiva a la parte superior de ImageNetPrediction.cs:using Microsoft.ML.Data;Quite la definición de clase existente y agregue el código siguiente para la
ImageNetPredictionclase al archivo ImageNetPrediction.cs :public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictiones la clase de datos de predicción y tiene el siguientefloat[]campo:-
PredictedLabelscontiene las dimensiones, la puntuación de existencia del objeto y las probabilidades de las clases para cada una de las cajas delimitadoras detectadas en una imagen.
-
Inicializar variables
La clase MLContext es un punto de partida para todas las operaciones de ML.NET e inicializar mlContext crea un nuevo entorno de ML.NET que se puede compartir entre los objetos de flujo de trabajo de creación de modelos. Es similar, conceptualmente, a DBContext en Entity Framework.
Inicialice la mlContext variable con una nueva instancia de MLContext agregando la siguiente línea debajo del outputFolder campo.
MLContext mlContext = new MLContext();
Creación de un analizador para salidas del modelo posterior al proceso
El modelo segmenta una imagen en una 13 x 13 cuadrícula, donde cada celda de cuadrícula es 32px x 32px. Cada celda de cuadrícula contiene 5 posibles cajas delimitadoras de objetos. Una caja delimitadora tiene 25 elementos.
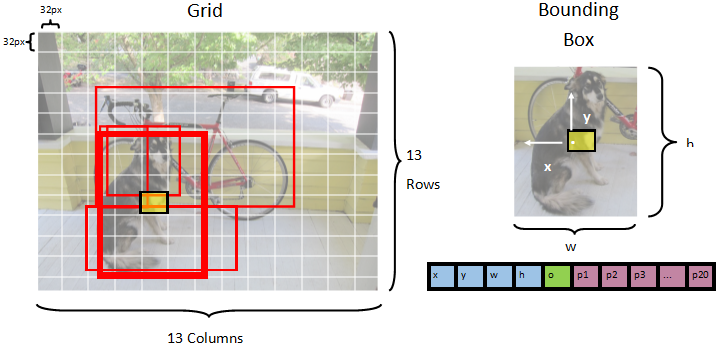
-
xla posición x del centro del rectángulo delimitador en relación con la celda de cuadrícula a la que está asociada. -
yla posición y del centro del cuadro delimitador con respecto a la celda de cuadrícula con la que está asociada. -
wancho de la caja delimitadora. -
hla altura de la caja delimitadora. -
oel valor de confianza de que un objeto existe dentro del cuadro delimitador, también conocido como puntuación de objetividad. -
p1-p20probabilidades de clase para cada una de las 20 clases previstas por el modelo.
En total, los 25 elementos que describen cada una de las 5 cajas delimitadoras componen los 125 elementos contenidos en cada celda de la cuadrícula.
La salida generada por el modelo ONNX previamente entrenado es una matriz flotante de longitud 21125, que representa los elementos de un tensor con dimensiones 125 x 13 x 13. Para transformar las predicciones generadas por el modelo en un tensor, se requiere un trabajo posterior al procesamiento. Para ello, cree un conjunto de clases para ayudar a analizar la salida.
Agregue un nuevo directorio al proyecto para organizar el conjunto de clases del analizador.
- En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Agregar>nueva carpeta. Cuando aparezca la nueva carpeta en el Explorador de soluciones, asígnelo el nombre "YoloParser".
Crear cuadros delimitadores y dimensiones
La salida de datos del modelo contiene coordenadas y dimensiones de las cajas delimitadoras de los objetos dentro de la imagen. Cree una clase base para dimensiones.
En el Explorador de soluciones, haga clic con el botón derecho en el directorio YoloParser y seleccione Agregar>nuevo elemento.
En el cuadro de diálogo Agregar nuevo elemento , seleccione Clase y cambie el campo Nombre a DimensionsBase.cs. A continuación, seleccione Agregar.
El archivo DimensionsBase.cs se abre en el editor de código. Quite todas las
usingdirectivas y la definición de clase existente.Agregue el código siguiente para la
DimensionsBaseclase al archivo DimensionsBase.cs :public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBasetiene las siguientesfloatpropiedades:-
Xcontiene la posición del objeto a lo largo del eje X. -
Ycontiene la posición del objeto a lo largo del eje Y. -
Heightcontiene el alto del objeto . -
Widthcontiene el ancho del objeto .
-
A continuación, cree una clase para las cajas delimitadoras.
En el Explorador de soluciones, haga clic con el botón derecho en el directorio YoloParser y seleccione Agregar>nuevo elemento.
En el cuadro de diálogo Agregar nuevo elemento , seleccione Clase y cambie el campo Nombre a YoloBoundingBox.cs. A continuación, seleccione Agregar.
El archivo YoloBoundingBox.cs se abre en el editor de código. Agregue la siguiente
usingdirectiva a la parte superior de YoloBoundingBox.cs:using System.Drawing;Justo encima de la definición de clase existente, agregue una nueva definición de clase denominada
BoundingBoxDimensionsque herede de laDimensionsBaseclase para contener las dimensiones del cuadro de límite correspondiente.public class BoundingBoxDimensions : DimensionsBase { }Quite la definición de clase existente
YoloBoundingBoxy agregue el código siguiente para laYoloBoundingBoxclase al archivo YoloBoundingBox.cs :public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxtiene las siguientes propiedades:-
Dimensionscontiene dimensiones de la caja delimitadora. -
Labelcontiene la clase de objeto detectado dentro del cuadro de límite. -
Confidencecontiene la confianza de la clase . -
Rectcontiene la representación del rectángulo de las dimensiones del cuadro delimitador. -
BoxColorcontiene el color asociado a la clase correspondiente que se usa para dibujar en la imagen.
-
Creación del analizador
Ahora que se crean las clases para dimensiones y cuadros de límite, es el momento de crear el analizador.
En el Explorador de soluciones, haga clic con el botón derecho en el directorio YoloParser y seleccione Agregar>nuevo elemento.
En el cuadro de diálogo Agregar nuevo elemento , seleccione Clase y cambie el campo Nombre a YoloOutputParser.cs. A continuación, seleccione Agregar.
El archivo YoloOutputParser.cs se abre en el editor de código. Agregue las siguientes
usingdirectivas a la parte superior de YoloOutputParser.cs:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;Dentro de la definición de clase existente
YoloOutputParser, agregue una clase anidada que contenga las dimensiones de cada una de las celdas de la imagen. Agregue el siguiente código para la claseCellDimensionsque hereda de la claseDimensionsBaseen la parte superior de la definición de la claseYoloOutputParser.class CellDimensions : DimensionsBase { }Dentro de la definición de clase
YoloOutputParser, agregue las siguientes constantes y campos.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNTes el número de filas de la cuadrícula en la que se divide la imagen. -
COL_COUNTes el número de columnas de la cuadrícula en la que se divide la imagen. -
CHANNEL_COUNTes el número total de valores contenidos en una celda de la cuadrícula. -
BOXES_PER_CELLes el número de cajas delimitadoras en una celda, -
BOX_INFO_FEATURE_COUNTes la cantidad de características contenidas en un cuadro (x,y,altura,anchura,confianza). -
CLASS_COUNTes el número de predicciones de clase contenidas en cada cuadro delimitador. -
CELL_WIDTHes el ancho de una celda de la cuadrícula de imágenes. -
CELL_HEIGHTes la altura de una celda en la cuadrícula de imágenes. -
channelStridees la posición inicial de la celda actual de la cuadrícula.
Cuando el modelo realiza una predicción, también conocida como puntuación, divide la
416px x 416pximagen de entrada en una cuadrícula de celdas el tamaño de13 x 13. Cada celda contiene es32px x 32px. Dentro de cada celda, hay 5 cajas delimitadoras, cada una contiene 5 características (x, y, ancho, alto, confianza). Además, cada cuadro de límite contiene la probabilidad asociada a cada una de las clases, que en este caso son 20. Por lo tanto, cada celda contiene 125 fragmentos de información (5 características + 20 probabilidades de clase).-
Cree una lista de delimitadores a continuación channelStride para los 5 cuadros de límite:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Las anclas son proporciones predefinidas de alto y ancho de cajas delimitadoras. La mayoría de los objetos o clases detectados por un modelo tienen proporciones similares. Esto es valioso cuando se trata de crear cajas delimitadoras. En lugar de predecir los cuadros de límite, se calcula el desplazamiento de las dimensiones predefinidas, lo que reduce el cálculo necesario para predecir el cuadro de límite. Normalmente, estas relaciones de anclaje se calculan en función del conjunto de datos usado. En este caso, dado que el conjunto de datos se conoce y los valores se han precomputizado, los delimitadores se pueden codificar de forma rígida.
A continuación, defina las etiquetas o clases que predecirá el modelo. Este modelo predice 20 clases, que es un subconjunto del número total de clases previstas por el modelo YOLOv2 original.
Agregue la lista de etiquetas debajo de .anchors
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Hay colores asociados a cada una de las clases. Asigne los colores de clase debajo de labels:
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Creación de funciones auxiliares
Hay una serie de pasos implicados en la fase posterior al procesamiento. Para ayudar con eso, se pueden emplear varios métodos auxiliares.
Los métodos auxiliares utilizados en por el analizador son:
-
Sigmoidaplica la función sigmoid que genera un número entre 0 y 1. -
Softmaxnormaliza un vector de entrada en una distribución de probabilidad. -
GetOffsetasigna los elementos de la salida del modelo unidimensional a la posición correspondiente en un125 x 13 x 13tensor. -
ExtractBoundingBoxesextrae las dimensiones de la caja delimitadora de la salida del modelo mediante el métodoGetOffset. -
GetConfidenceextrae el valor de confianza que indica la certeza de que el modelo es que ha detectado un objeto y usa laSigmoidfunción para convertirlo en un porcentaje. -
MapBoundingBoxToCellutiliza las dimensiones de la caja delimitadora y las asigna a la celda correspondiente dentro de la imagen. -
ExtractClassesextrae las predicciones de clase para el cuadro delimitador de la salida del modelo usando el métodoGetOffsety las convierte en una distribución de probabilidad usando el métodoSoftmax. -
GetTopResultselecciona la clase de la lista de clases predichas con la probabilidad más alta. -
IntersectionOverUnionfiltra los cuadros de límite superpuestos con probabilidades más bajas.
Agregue el código para todos los métodos auxiliares debajo de la lista de classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Una vez que haya definido todos los métodos auxiliares, es el momento de usarlos para procesar la salida del modelo.
Debajo del IntersectionOverUnion método , cree el ParseOutputs método para procesar la salida generada por el modelo.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Cree una lista para almacenar sus cajas delimitadoras y defina variables dentro del ParseOutputs método.
var boxes = new List<YoloBoundingBox>();
Cada imagen se divide en una cuadrícula de 13 x 13 celdas. Cada celda contiene cinco cajas delimitadoras. Debajo de la boxes variable, agregue código para procesar todos los cuadros de cada una de las celdas.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Dentro del bucle más interno, calcule la posición inicial del cuadro actual dentro de la salida del modelo unidimensional.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Directamente debajo, use el ExtractBoundingBoxDimensions método para obtener las dimensiones del cuadro de límite actual.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
A continuación, use el GetConfidence método para obtener la confianza del cuadro de límite actual.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Después, use el MapBoundingBoxToCell método para asignar el cuadro de límite actual a la celda actual que se está procesando.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Antes de realizar cualquier procesamiento adicional, compruebe si el valor de confianza es mayor que el umbral proporcionado. Si no es así, procesa el siguiente cuadro delimitador.
if (confidence < threshold)
continue;
De lo contrario, continúe procesando la salida. El siguiente paso es obtener la distribución de probabilidad de las clases predichas para el cuadro de límite actual mediante el método ExtractClasses.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
A continuación, use el GetTopResult método para obtener el valor y el índice de la clase con la mayor probabilidad del cuadro actual y calcular su puntuación.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Usa el topScore para mantener de nuevo solo los cuadros de límite que están por encima del umbral especificado.
if (topScore < threshold)
continue;
Por último, si el cuadro de límite actual supera el umbral, cree un objeto BoundingBox nuevo y agréguelo a la lista boxes.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Una vez procesadas todas las celdas de la imagen, devuelva la boxes lista. Agregue la siguiente instrucción return debajo del bucle for más externo en el método ParseOutputs.
return boxes;
Filtrar cuadros superpuestos
Ahora que se han extraído todos los cuadros delimitadores de alta confianza de la salida del modelo, es necesario realizar un filtrado adicional para eliminar las imágenes superpuestas. Agregue un método llamado FilterBoundingBoxes debajo del ParseOutputs método :
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
Dentro del FilterBoundingBoxes método, empiece creando una matriz igual al tamaño de los cuadros detectados y marcando todas las ranuras como activas o listas para su procesamiento.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
A continuación, ordene la lista que contiene los cuadros de límite en orden descendente en función de la confianza.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Después, cree una lista para contener los resultados filtrados.
var results = new List<YoloBoundingBox>();
Comience a procesar cada cuadro delimitador iterando sobre cada uno de los cuadros delimitadores.
for (int i = 0; i < boxes.Count; i++)
{
}
Dentro de este bucle for, verifique si se puede procesar la caja delimitadora actual.
if (isActiveBoxes[i])
{
}
Si es así, agregue el cuadro delimitador a la lista de resultados. Si los resultados superan el límite especificado de cuadros que se van a extraer, interrumpa el bucle. Agregue el código siguiente dentro de la instrucción if.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
De lo contrario, examine las cajas delimitadoras adyacentes. Agregue el código siguiente debajo de la casilla límite.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Al igual que el primer cuadro, si el cuadro adyacente está activo o listo para procesarse, use el IntersectionOverUnion método para comprobar si la primera casilla y la segunda superan el umbral especificado. Añada el siguiente código al bucle for más interno.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Fuera del bucle for-most interno que comprueba los cuadros de límite adyacentes, vea si hay otros cuadros de límite que se van a procesar. Si no es así, salga del bucle for externo.
if (activeCount <= 0)
break;
Por último, fuera del bucle for inicial del método FilterBoundingBoxes, devuelve los resultados:
return results;
¡Bien! Ahora es el momento de usar este código junto con el modelo para la puntuación.
Uso del modelo para la puntuación
Al igual que con el posprocesamiento, hay algunas etapas en el proceso de puntuación. Para ayudar con esto, agregue una clase que contendrá la lógica de puntuación al proyecto.
En el Explorador de soluciones, haga clic con el botón derecho en el proyecto y seleccione Agregar>nuevo elemento.
En el cuadro de diálogo Agregar nuevo elemento , seleccione Clase y cambie el campo Nombre a OnnxModelScorer.cs. A continuación, seleccione Agregar.
El archivo OnnxModelScorer.cs se abre en el editor de código. Agregue las siguientes
usingdirectivas a la parte superior de OnnxModelScorer.cs:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;Dentro de la definición de clase
OnnxModelScorer, agregue las siguientes variables.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Directamente debajo, cree un constructor para la
OnnxModelScorerclase que inicializará las variables definidas anteriormente.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }Una vez creado el constructor, defina un par de estructuras que contengan variables relacionadas con la imagen y la configuración del modelo. Cree una estructura denominada
ImageNetSettingspara contener el alto y el ancho esperados como entrada para el modelo.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Después, cree otra estructura denominada
TinyYoloModelSettingsque contenga los nombres de las capas de entrada y salida del modelo. Para visualizar el nombre de las capas de entrada y salida del modelo, puede usar una herramienta como Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }A continuación, cree el primer conjunto de métodos que se usan para la puntuación. Cree el
LoadModelmétodo dentro de laOnnxModelScorerclase .private ITransformer LoadModel(string modelLocation) { }Dentro del
LoadModelmétodo , agregue el código siguiente para el registro.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");Las canalizaciones de ML.NET deben conocer el esquema de datos en el que operar cuando se llama al método
Fit. En este caso, se usará un proceso similar al entrenamiento. Sin embargo, dado que no se está realizando ningún entrenamiento real, es aceptable utilizar unIDataViewvacío. Cree un nuevoIDataViewpara la canalización a partir de una lista vacía.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Debajo, defina la canalización. La canalización constará de cuatro transformaciones.
-
LoadImagescarga la imagen como un mapa de bits. -
ResizeImagesvuelve a escalar la imagen al tamaño especificado (en este caso,416 x 416). -
ExtractPixelscambia la representación de píxeles de la imagen de un mapa de bits a un vector numérico. -
ApplyOnnxModelcarga el modelo ONNX y lo usa para puntuar en los datos proporcionados.
Importante
Use solo modelos de fuentes de confianza. La aplicación de modelos de orígenes que no son de confianza es un riesgo de seguridad.
Defina la canalización en el
LoadModelmétodo debajo de ladatavariable .var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Ahora es el momento de crear una instancia del modelo para el cálculo de puntuaciones. Llame al
Fitmétodo en la canalización y vuelva a él para su posterior procesamiento.var model = pipeline.Fit(data); return model;-
Una vez cargado el modelo, se puede usar para realizar predicciones. Para facilitar ese proceso, cree un método denominado PredictDataUsingModel debajo del LoadModel método .
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
Dentro de PredictDataUsingModel, agregue el código siguiente para el registro.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
A continuación, use el Transform método para puntuar los datos.
IDataView scoredData = model.Transform(testData);
Extraiga las probabilidades predichas y devuelvalas para su procesamiento adicional.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Ahora que ambos pasos están configurados, combínelos en un único método. Debajo del PredictDataUsingModel método , agregue un nuevo método denominado Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
¡Casi ahí! Ahora es el momento de ponerlo todo en uso.
Detección de objetos
Ahora que se ha completado toda la configuración, es el momento de detectar algunos objetos.
Puntuar y analizar las salidas del modelo
Debajo de la creación de la variable mlContext, agregue una sentencia try-catch.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
Dentro del try bloque, empiece a implementar la lógica de detección de objetos. En primer lugar, cargue los datos en un IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
A continuación, cree una instancia de OnnxModelScorer y úsela para puntuar los datos cargados.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Ahora es el momento del paso posterior al procesamiento. Cree una instancia de YoloOutputParser y úsela para procesar la salida del modelo.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Una vez procesada la salida del modelo, es el momento de dibujar los cuadros de límite en las imágenes.
Visualización de predicciones
Una vez que el modelo haya puntuado las imágenes y se hayan procesado las salidas, se deben dibujar los rectángulos delimitadores en la imagen. Para ello, agregue un método denominado DrawBoundingBox debajo del GetAbsolutePath método dentro de Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
En primer lugar, cargue la imagen y obtenga las dimensiones de alto y ancho en el DrawBoundingBox método .
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
A continuación, cree un bucle for-each para recorrer en iteración cada uno de los cuadros de límite detectados por el modelo.
foreach (var box in filteredBoundingBoxes)
{
}
Dentro del bucle for-each, obtenga las dimensiones de la caja delimitadora.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Dado que las dimensiones del cuadro delimitador corresponden a la entrada del modelo de 416 x 416, ajuste las dimensiones del cuadro delimitador para que se correspondan con el tamaño real de la imagen.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
A continuación, defina una plantilla para el texto que aparecerá encima de cada caja delimitadora. El texto contendrá la clase del objeto dentro del cuadro delimitador correspondiente, así como el nivel de confianza.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Para dibujar en la imagen, conviértalo en un Graphics objeto .
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
Dentro del using bloque de código, ajuste la configuración del objeto del Graphics gráfico.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
A continuación, establezca las opciones de fuente y color para el texto y el cuadro delimitador.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Cree y rellene un rectángulo encima de la caja delimitadora para contener el texto mediante el método FillRectangle. Esto ayudará a contrastar el texto y mejorar la legibilidad.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
A continuación, dibuje el texto y el cuadro delimitador en la imagen mediante los métodos DrawString y DrawRectangle.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Fuera del bucle for-each, agregue código para guardar las imágenes en outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Para obtener comentarios adicionales que la aplicación realiza predicciones según lo previsto en tiempo de ejecución, agregue un método denominado LogDetectedObjects debajo del DrawBoundingBox método en el archivo Program.cs para generar los objetos detectados en la consola.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Ahora que tiene métodos auxiliares para crear retroalimentación visual a partir de las predicciones, agregue un bucle for para recorrer cada una de las imágenes puntuadas.
for (var i = 0; i < images.Count(); i++)
{
}
Dentro del bucle for, obtenga el nombre del archivo de imagen y los cuadros de límite asociados.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
A continuación, use el método DrawBoundingBox para dibujar las cajas de delimitación en la imagen.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Por último, use el LogDetectedObjects método para generar predicciones en la consola.
LogDetectedObjects(imageFileName, detectedObjects);
Después de la declaración try-catch, agregue lógica adicional para indicar que el proceso ha terminado de ejecutarse.
Console.WriteLine("========= End of Process..Hit any Key ========");
Eso es todo.
Results
Después de seguir los pasos anteriores, ejecute la aplicación de consola (Ctrl + F5). Los resultados deben ser similares a los siguientes resultados. Es posible que vea advertencias o mensajes de procesamiento, pero estos mensajes se han quitado de los siguientes resultados para mayor claridad.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Para ver las imágenes con cuadros de límite, vaya al directorio assets/images/output/. A continuación se muestra un ejemplo de una de las imágenes procesadas.

¡Felicidades! Ahora ha creado correctamente un modelo de aprendizaje automático para la detección de objetos mediante la reutilización de un modelo entrenado previamente ONNX en ML.NET.
Puede encontrar el código fuente de este tutorial en el repositorio dotnet/machinelearning-samples .
En este tutorial, ha aprendido a:
- Comprender el problema
- Obtenga información sobre qué es ONNX y cómo funciona con ML.NET
- Descripción del modelo
- Reutiliza el modelo entrenado previamente
- Detección de objetos con un modelo cargado
Consulte el repositorio de GitHub de ejemplos de Machine Learning para explorar un ejemplo de detección de objetos expandido.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.