Conectar a tablas de Common Data Model en Azure Data Lake Storage
Nota
Azure Active Directory es ahora Microsoft Entra ID. Más información
Ingiera datos en Dynamics 365 Customer Insights - Data usando su cuenta de Azure Data Lake Storage con tablas Common Data Model. La ingesta de datos puede ser completa o incremental.
Requisitos previos
La cuenta de Azure Data Lake Storage debe tener espacio de nombres jerárquico habilitado. Los datos deben almacenarse en un formato de carpeta jerárquica que define la carpeta raíz y tiene subcarpetas para cada tabla. Las subcarpetas pueden tener carpetas de datos completos o de datos incrementales.
Para autenticarse con una entidad de servicio de Microsoft Entra, asegúrese de que esté configurada en su inquilino. Para obtener más información, consulte Conectarse a una cuenta de Azure Data Lake Storage mediante el uso de una entidad de servicio de Microsoft Entra.
Para conectar con un almacenamiento protegido por cortafuegos, Configurar vínculos privados de Azure Private.
Si su lago de datos tiene actualmente alguna conexión de enlace privado con él, Customer Insights - Data debe conectarse también mediante un vínculo privado, independientemente de la configuración de acceso a la red.
El Azure Data Lake Storage al que se va a conectar y del que va a ingerir datos debe estar en la misma región de Azure que el entorno de Dynamics 365 Customer Insights y las suscripciones deben estar en el mismo inquilino. No se admiten las conexiones a una carpeta de Common Data Model desde un lago de datos en una región de Azure diferente. Para conocer la región de Azure del entorno en vaya a Configuración>Sistema>Acerca de en Customer Insights - Data.
Los datos almacenados en servicios en línea pueden almacenarse en una ubicación diferente a la que se procesan o almacenan. Al importar datos almacenados en servicios en línea, o conectarse a ellos, acepta que los datos pueden transferirse y almacenarse. Obtenga más información en el Centro de confianza de Microsoft.
La entidad de servicio de Customer Insights - Data debe tener uno de los siguientes roles para acceder a la cuenta de almacenamiento. Para más información, consulte Otorgar permisos a la entidad de servicio para acceder a la cuenta de almacenamiento.
- Lector de datos de blobs de almacenamiento
- Propietario de datos de blobs de almacenamiento
- Colaborador de datos de blob de almacenamiento
Al conectarse a su almacenamiento de Azure mediante la opción Suscripción de Azure, el usuario que configura la conexión origen de datos necesita al menos los permisos de Colaborador de datos de blob de almacenamiento en la cuenta de almacenamiento.
Al conectarse a su almacenamiento de Azure mediante la opción Recurso de Azure, el usuario que configura la conexión origen de datos necesita al menos el permiso para la acción Microsoft.Storage/storageAccounts/read en la cuenta de almacenamiento. Un rol integrado de Azure que incluye esta acción es el rol de Lector. Para limitar el acceso solo a la acción necesaria, cree un rol personalizado de Azure que incluya solo esta acción.
Para un rendimiento óptimo, el tamaño de una partición debe ser de 1 GB o menos y la cantidad de archivos de partición en una carpeta no debe exceder los 1000.
Los datos en su Data Lake Storage deben seguir el estándar de Common Data Model para el almacenamiento de sus datos y tener el manifiesto de Common Data Model para representar el esquema de los archivos de datos (*.csv o *.parquet). El manifiesto debe proporcionar los detalles de las tablas, como columnas de tabla y tipos de datos, y la ubicación del archivo de datos y el tipo de archivo. Para obtener más información, consulte El manifiesto de Common Data Model. Si el manifiesto no está presente, los usuarios administradores con acceso Storage Blob Data Owner o Storage Blob Data colaborador pueden definir el esquema al ingerir los datos.
Nota
Si alguno de los campos en los archivos .parquet tiene el tipo de datos Int96, es posible que los datos no se muestren en la página Tablas. Recomendamos utilizar tipos de datos estándar, como el formato de marca de tiempo Unix (que representa el tiempo como el número de segundos desde el 1 de enero de 1970, a la medianoche UTC).
Limitaciones
- Customer Insights - Data no admite columnas de tipo decimal con precisión mayor que 16.
Conectar con Azure Data Lake Storage
Los nombres de conexión de datos, las rutas de acceso de datos, como carpetas dentro de un contenedor, y los nombres de tablas deben usar nombres que comiencen con una letra. Los nombres solo pueden contener letras, números y el carácter de subrayado (_). No se admiten caracteres especiales.
Vaya a Datos>Orígenes de datos.
Seleccione Agregar un origen de datos.
Seleccione Tablas Azure Data Lake Common Data Model.

Escriba un Nombre de origen de datos y una Descripción opcional. Se hace referencia al nombre en los procesos posteriores y no es posible cambiarlo después de crear el origen de datos.
Elija una de las siguientes opciones para Conecte su almacenamiento usando. Para obtener más información, consulte Conectarse a una cuenta de Azure Data Lake Storage mediante el uso de una entidad de servicio de Microsoft Entra.
- Recurso Azure: Introduzca el Id. de recurso.
- Suscripción Azure: seleccione Suscripción y luego el Grupo de recursos y Cuenta de almacenamiento.
Nota
Necesita uno de los siguientes roles para el contenedor para crear el origen de datos:
- El Lector de datos de Storage Blob es suficiente para leer desde una cuenta de almacenamiento e incorporar los datos a Customer Insights - Data.
- Se requiere el propietario o el colaborador de datos de Storage Blob Storage si desea editar los archivos de manifiesto directamente en Customer Insights - Data.
Tener el rol en la cuenta de almacenamiento proporcionará el mismo rol en todos sus contenedores.
Elige el nombre del Contenedor que contiene los datos y el esquema (archivo model.json o manifest.json) para importar datos.
Nota
Cualquier archivo model.json o manifest.json asociado con otro origen de datos del entorno no se mostrará en la lista. Sin embargo, el mismo archivo model.json o manifest.json se puede utilizar para orígenes de datos en varios entornos.
Opcionalmente, si desea ingerir datos de una cuenta de almacenamiento a través de Azure Private Link, seleccione Habilitar Private Link. Para obtener más información, consulte Private Links.
Para crear un nuevo esquema, vaya a Crear un nuevo archivo de esquema.
Para usar un esquema existente, vaya a la carpeta que contiene el archivo model.json o manifest.cdm.json. Puede buscar dentro de un directorio para encontrar el archivo.
Seleccione el archivo json y, a continuación, Siguiente. Aparece una lista de tablas disponibles.
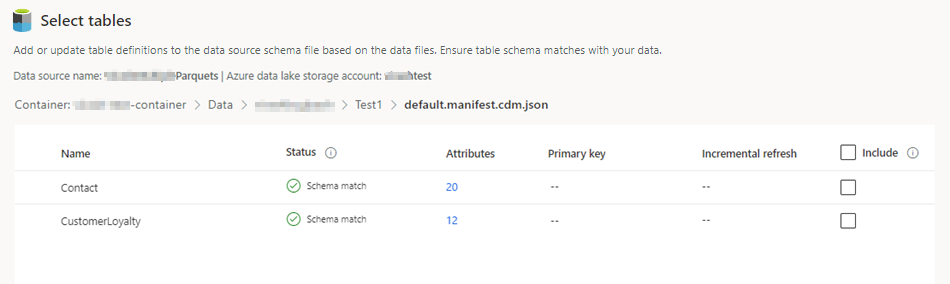
Seleccione las tablas analíticas que desee incluir.
Propina
Para editar una tabla en una interfaz de edición JSON, seleccione la tabla y después Editar archivo de esquema. Realice los cambios y seleccione Guardar.
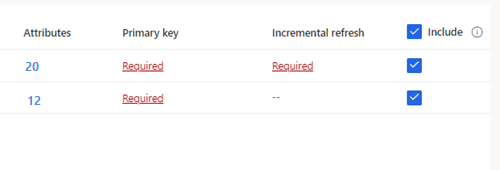
Para tablas seleccionadas donde no se ha definido una clave principal, Obligatorio aparece debajo de Clave primaria. Para cada una de estas tablas:
- Seleccione Obligatorio. El panel Editar tabla aparece.
- Elija la Clave principal. La clave principal es un atributo exclusivo de la tabla. Para que un atributo pueda ser una clave principal válida, no debe incluir valores duplicados, no deben faltar valores ni debe haber valores nulos. Los atributos de tipo de datos de cadena, entero y GUID se admiten como claves principales.
- Opcionalmente, cambie el patrón de partición.
- Seleccione Cerrar para guardar y cerrar el panel.
Seleccione el número de Columnas para cada tabla incluida. Aparece la página Administrar atributos.
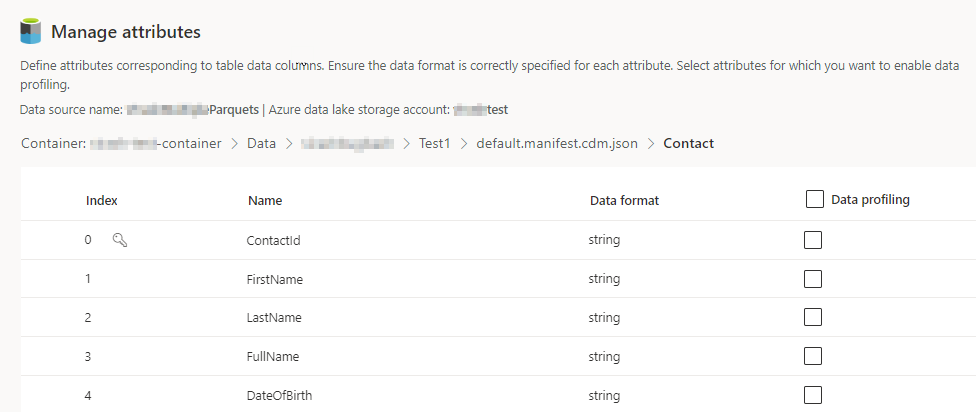
- Cree nuevas columnas, edite o elimine columnas existentes. Puede cambiar el nombre, el formato de datos o agregar un tipo semántico.
- Para habilitar el análisis y otras capacidades, seleccione Perfilado de datos para toda la tabla o para columnas específicas. De forma predeterminada, ninguna tabla está habilitada para la creación de perfiles de datos.
- Seleccione Listo.
Seleccione Guardar. La página Orígenes de datos se abre y muestra el nuevo origen de datos en estado Actualizando.
Propina
Existen estados para tareas y procesos. La mayoría de los procesos dependen de otros procesos ascendentes, como las fuentes de datos y actualizaciones de perfiles de datos.
Seleccione el estado para abrir el panel Detalles de progreso y vea el progreso de las tareas. Para cancelar el trabajo, seleccione Cancelar trabajo en la parte inferior del panel.
En cada tarea, puede seleccionar Ver detalles para obtener más información sobre el progreso, como el tiempo de procesamiento, la fecha del último procesamiento y los errores y advertencias aplicables asociados con la tarea o el proceso. Seleccione Ver el estado del sistema en la parte inferior del panel para ver otros procesos en el sistema.

La carga de datos puede llevar tiempo. Una vez completada una actualización, se pueden revisar los datos ingeridos en la página Tablas.
Cree un nuevo archivo de esquema
Seleccione Crear archivo de esquema.
Especifique un nombre para el archivo y seleccione Guardar.
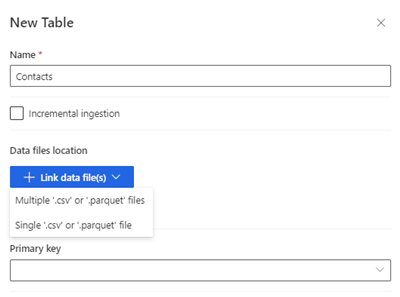
Seleccione Nueva tabla. El panel Nueva tabla aparece.
Introduzca el nombre de la tabla y elija la Ubicación de los archivos de datos.
- Múltiples archivos .csv o .parquet: vaya a la carpeta raíz, seleccione el tipo de patrón e ingrese la expresión.
- Archivos individuales .csv o .parquet: busque el archivo .csv o .parquet y selecciónelo.
Seleccione Guardar.
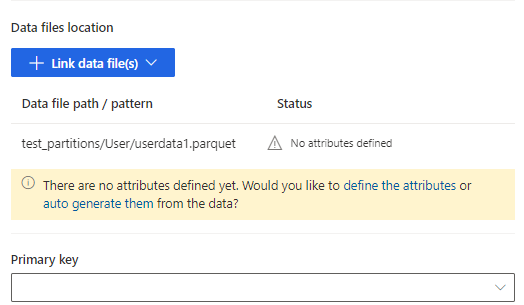
Seleccione definir los atributos para agregar manualmente los atributos, o seleccione generarlos automáticamente. Para definir los atributos, ingrese un nombre, seleccione el formato de datos y el tipo semántico opcional. Para atributos generados automáticamente:
Después de que los atributos se generen automáticamente, seleccione Revisar atributos. Aparece la página Administrar atributos.
Asegúrese de que el formato de datos sea correcto para cada atributo.
Para habilitar el análisis y otras capacidades, seleccione Perfilado de datos para toda la tabla o para columnas específicas. De forma predeterminada, ninguna tabla está habilitada para la creación de perfiles de datos.
Seleccione Listo. Aparece la página Seleccionar tablas.
Continúe agregando tablas y columnas, si corresponde.
Después de agregar todas las tablas, seleccione Incluir para incluir las tablas en la ingestión origen de datos.
Para tablas seleccionadas donde no se ha definido una clave principal, Obligatorio aparece debajo de Clave primaria. Para cada una de estas tablas:
- Seleccione Obligatorio. El panel Editar tabla aparece.
- Elija la Clave principal. La clave principal es un atributo exclusivo de la tabla. Para que un atributo pueda ser una clave principal válida, no debe incluir valores duplicados, no deben faltar valores ni debe haber valores nulos. Los atributos de tipo de datos de cadena, entero y GUID se admiten como claves principales.
- Opcionalmente, cambie el patrón de partición.
- Seleccione Cerrar para guardar y cerrar el panel.
Seleccione Guardar. La página Orígenes de datos se abre y muestra el nuevo origen de datos en estado Actualizando.
Propina
Existen estados para tareas y procesos. La mayoría de los procesos dependen de otros procesos ascendentes, como las fuentes de datos y actualizaciones de perfiles de datos.
Seleccione el estado para abrir el panel Detalles de progreso y vea el progreso de las tareas. Para cancelar el trabajo, seleccione Cancelar trabajo en la parte inferior del panel.
En cada tarea, puede seleccionar Ver detalles para obtener más información sobre el progreso, como el tiempo de procesamiento, la fecha del último procesamiento y los errores y advertencias aplicables asociados con la tarea o el proceso. Seleccione Ver el estado del sistema en la parte inferior del panel para ver otros procesos en el sistema.
La carga de datos puede llevar tiempo. Una vez completada una actualización, se pueden revisar los datos ingeridos en la página Datos>Tablas.
Editar un origen de datos Azure Data Lake Storage
Puede actualizar la opción Conéctese a la cuenta de almacenamiento usando. Para obtener más información, consulte Conectarse a una cuenta de Azure Data Lake Storage mediante el uso de una entidad de servicio de Microsoft Entra. Para conectarse a un contenedor diferente de su cuenta de almacenamiento o cambiar el nombre de la cuenta, cree una nueva conexión de origen de datos.
Vaya a Datos>Orígenes de datos. Junto al origen de datos que desea actualizar, seleccione Editar.
Cambie cualquiera de la información siguiente:
Description
Conecte su almacenamiento usando e información de conexión. No puede cambiar la información de Contenido al actualizar la conexión.
Nota
Se debe asignar uno de los siguientes roles a la cuenta de almacenamiento o al contenedor:
- Lector de datos de blobs de almacenamiento
- Propietario de datos de blobs de almacenamiento
- Colaborador de datos de blob de almacenamiento
Habilitar Private Link si desea ingerir datos de una cuenta de almacenamiento a través de Azure Private Link. Para obtener más información, consulte Private Links.
Seleccione Siguiente.
Cambie cualquiera de las siguientes:
Navegue a un archivo model.json o manifest.json diferente con un conjunto diferente de tablas del contenedor.
Para agregar tablas adicionales para ingerir, seleccione Nueva tabla.
Para eliminar cualquier tabla ya seleccionada si no hay dependencias, seleccione la tabla y Borrar.
Importante
Si hay dependencias en el archivo model.json o manifest.json existente y el conjunto de tablas, verá un mensaje de error y no podrá seleccionar un archivo model.json o manifest.json diferente. Elimine esas dependencias antes de cambiar el archivo model.json o manifest.json o cree un nuevo origen de datos con el archivo model.json o manifest.json que desea utilizar para evitar eliminar las dependencias.
Para cambiar la ubicación del archivo de datos o la clave principal, seleccione Editar.
Solo cambie el nombre de la tabla para que coincida con el nombre de la tabla en el archivo .json.
Nota
Mantenga siempre el mismo nombre de la tabla que el nombre de la tabla en el archivo model.json o manifest.json después de la ingesta. Customer Insights - Data valida todos los nombres de las tablas con model.json o manifest.json durante cada actualización del sistema. Si el nombre de una tabla cambia, se produce un error porque Customer Insights - Data no puede encontrar el nuevo nombre de la tabla en el archivo .json. Si se cambió accidentalmente el nombre de una tabla ingerida, edítelo para que coincida con el nombre en el archivo .json.
Seleccione Columnas para agregarlas o cambiarlas, o para habilitar la creación de perfiles de datos. A continuación, seleccione Hecho.
Seleccione Guardar para aplicar los cambios y volver a la página Orígenes de datos.
Propina
Existen estados para tareas y procesos. La mayoría de los procesos dependen de otros procesos ascendentes, como las fuentes de datos y actualizaciones de perfiles de datos.
Seleccione el estado para abrir el panel Detalles de progreso y vea el progreso de las tareas. Para cancelar el trabajo, seleccione Cancelar trabajo en la parte inferior del panel.
En cada tarea, puede seleccionar Ver detalles para obtener más información sobre el progreso, como el tiempo de procesamiento, la fecha del último procesamiento y los errores y advertencias aplicables asociados con la tarea o el proceso. Seleccione Ver el estado del sistema en la parte inferior del panel para ver otros procesos en el sistema.