Procedimientos recomendados de unificación de datos
Al configurar reglas para unificar sus datos en un perfil de cliente, tenga en cuenta estas prácticas recomendadas:
Equilibrar el tiempo necesario para unificar y completar la coincidencia. Intentar capturar todas las coincidencias posibles da lugar a muchas reglas y a una unificación que lleva mucho tiempo.
Agregue reglas progresivamente y realice un seguimiento de los resultados. Eliminar las reglas que no mejoran el resultado del partido.
Desduplica cada tabla para que cada cliente esté representado en una sola fila.
Utilice la normalización para estandarizar las variaciones en cómo se ingresaron los datos, como Calle vs. Calle vs. Calle vs. Calle.
Utilice la coincidencia aproximada de manera estratégica para corregir errores tipográficos y errores como bob@contoso.com y bob@contoso.cm. Las coincidencias aproximadas tardan más en ejecutarse que las coincidencias exactas. Pruebe siempre para ver si el tiempo extra que se dedica a la coincidencia aproximada vale la tasa de coincidencia adicional.
Limite el alcance de las coincidencias con coincidencia exacta. Asegúrese de que cada regla con condiciones difusas tenga al menos una condición de coincidencia exacta.
No haga coincidir columnas que contengan datos muy repetidos. Asegúrese de que las columnas de coincidencia aproximada no tengan valores repetidos con frecuencia, como el valor predeterminado de un formulario, "Nombre".
Rendimiento de unificación
Cada regla lleva tiempo para ejecutarse. Patrones como comparar cada tabla con todas las demás o intentar capturar todas las posibles coincidencias de registros pueden generar largos tiempos de procesamiento de unificación. También devuelve pocas coincidencias, si es que hay alguna, en un plan que compara cada tabla con una tabla base.
El mejor enfoque es comenzar con un conjunto básico de reglas que sabe que son necesarias, como comparar cada tabla con su tabla principal. La tabla principal debe ser la tabla con los datos más completos y precisos. Esta tabla debe ordenarse en la parte superior en la unificación de reglas de coincidencia paso.
Agregue progresivamente varias reglas y vea cuánto tardan en ejecutarse los cambios y si sus resultados mejoran. Vaya a Configuración>Estado>del del Sistema y Seleccionar Coincidencia para ver cuánto tiempo tomó la deduplicación y la coincidencia para cada ejecución de unificación.
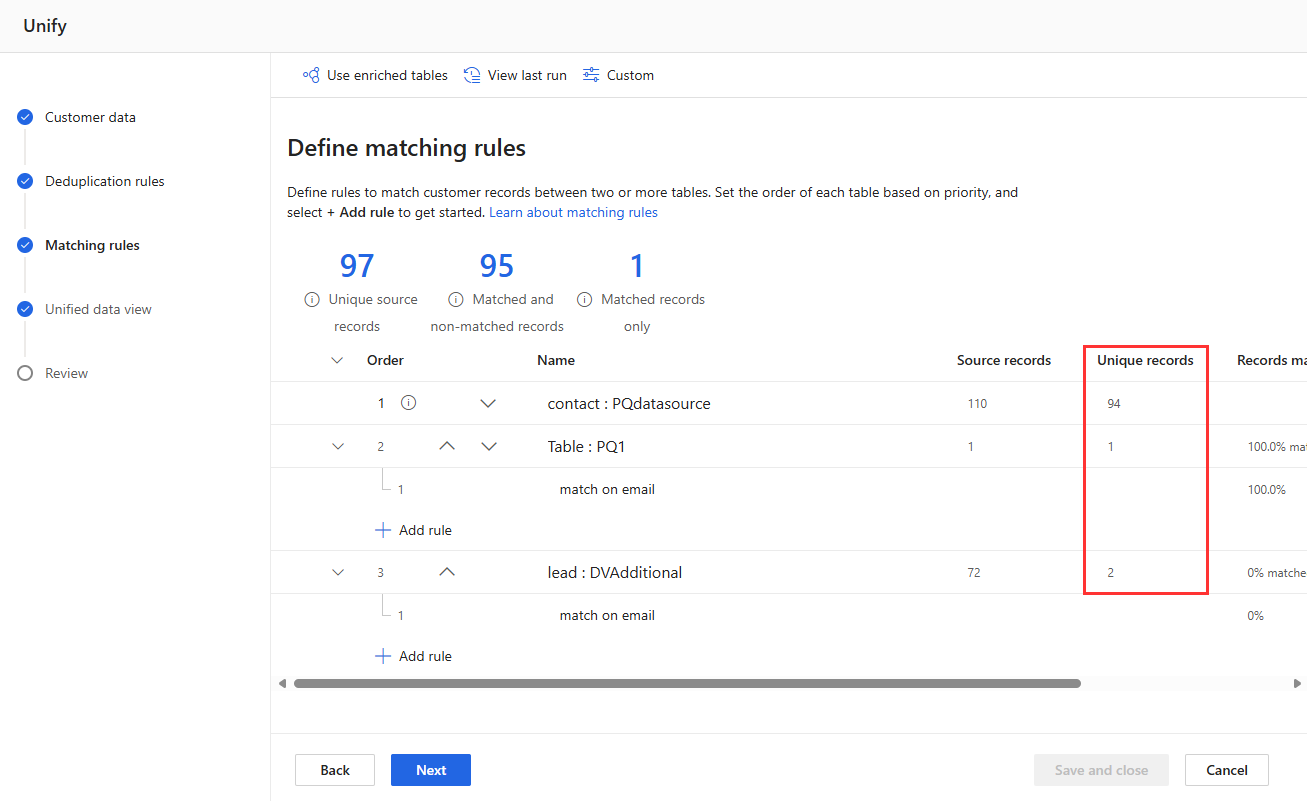
Vea las estadísticas de las reglas en las páginas de Reglas de deduplicación y Reglas de coincidencia para ver si cambia la cantidad de registros únicos . Si una nueva regla coincide con algunos registros y el recuento de registros únicos no cambia, entonces una regla anterior identifica esas coincidencias.
Desduplicación
Utilice reglas de deduplicación para eliminar registros de clientes duplicados dentro de una tabla de modo que una sola fila en cada tabla represente a cada cliente. Una buena regla identifica a un cliente único.
En este ejemplo simple, los registros 1, 2 y 3 Compartir son un correo electrónico o un número de teléfono y representan a la misma persona.
| ID | Name | Teléfono | |
|---|---|---|---|
| 1 | Persona 1 | (425) 555-1111 | AAA@A.com |
| 2 | Persona 1 | (425) 555-1111 | BBB@B.com |
| 3 | Persona 1 | (425) 555-2222 | BBB@B.com |
| 4 | Persona 2 | (206) 555-9999 | Person2@contoso.com |
No queremos hacer coincidir solo el nombre, ya que eso haría coincidir a diferentes personas con el mismo nombre.
Cree la regla 1 usando Nombre y Teléfono, que coincida con los registros 1 y 2.
Cree la regla 2 usando Nombre y Correo electrónico, que coincida con los registros 2 y 3.
La combinación de la Regla 1 y la Regla 2 crea un grupo de coincidencia único porque comparten el registro 2.
Usted decide el número de reglas y condiciones que identifican de forma única a sus clientes. Las reglas exactas dependen de los datos que tenga disponibles para comparar, la calidad de sus datos y qué tan exhaustivo desea que sea el proceso de deduplicación.
Récords de ganador y alternos
Una vez que se ejecutan las reglas y se identifican los registros duplicados, el proceso de deduplicación selecciona una "fila ganadora". Las filas no ganadoras se denominan "filas alternativas". Las filas alternativas se utilizan en la unificación de reglas de coincidencia paso para hacer coincidir los registros de otras tablas con la fila ganadora. Las filas se comparan con los datos de las filas alternativas además de la fila ganadora.
Una vez que agrega una regla a una tabla, puede configurar qué fila será Seleccionar como la fila ganadora a través de Preferencias de combinación. Las preferencias de combinación se establecen por tabla. Independientemente de la política de combinación seleccionada, si hay un empate en una fila ganadora, se utiliza la primera fila en el orden de datos como desempate.
Normalización
Utilice la normalización para estandarizar los datos para una mejor coincidencia. La normalización funciona bien en grandes conjuntos de datos.
Los datos normalizados solo se utilizan con fines de comparación para hacer coincidir los registros de los clientes de manera más efectiva. No cambia los datos en la salida final unificada del perfil del cliente.
| Normalización | Ejemplos |
|---|---|
| Números | Convierte muchos símbolos Unicode que representan números en números simples. Ejemplos: ❽ y Ⅷ están ambos normalizados al número 8. Nota: Los símbolos deben estar codificados en formato de puntos Unicode. |
| Símbolos | Elimina símbolos y caracteres especiales. Ejemplos: !?"#$%&'( )+,.-/:;<=>@^~{}`[ ] |
| Texto en minúsculas | Convierte los caracteres en mayúscula a minúscula. Ejemplo: "ESTE ES UN EJEMPLO" se convierte en "este es un ejemplo" |
| Tipo: Teléfono | Convierte teléfonos en varios formatos a dígitos y tiene en cuenta las variaciones en la forma en que se presentan los códigos de país o región y las extensiones. Ejemplo: +01 425.555.1212 = 1 (425) 555-1212 |
| Tipo: Nombre | Convierte más de 500 variaciones de nombres y títulos comunes. Ejemplos: "debby" -> "deborah" "prof" y "profesor" -> "Prof." |
| Tipo: Dirección | Convierte partes comunes de direcciones Ejemplos: "calle" -> "C." y "noroeste" -> "NO" |
| Tipo: Organización | Elimina alrededor de 50 "palabras ruidosas" de nombres de empresas, como "co", "corp", "corporación" y "ltd". |
| Unicode a ASCII | Convierte los caractertes Unicode en su equivalente ASCII Ejemplo: Los caracteres 'à,' 'á,' 'â,' 'À,' 'Á,' 'Â,' 'Ã,' 'Ä,' 'Ⓐ,' y 'A' se convierten todos en 'a'. |
| Espacio en blanco | Elimina todos los espacios en blanco |
| Asignación de alias | Le permite cargar una lista personalizada de pares de cadenas que luego se pueden usar para indicar cadenas que siempre deben considerarse una coincidencia exacta. Utilice la asignación de alias cuando tenga ejemplos de datos específicos que crea que deberían coincidir y no coincidan utilizando uno de los otros patrones de normalización. Ejemplo: Scott y Scooter, o MSFT y Microsoft. |
| Omisión personalizada | Le permite cargar una lista personalizada de cadenas que luego se pueden usar para indicar cadenas que nunca deben ser coincidencia. La omisión personalizada es útil cuando tienes datos con valores comunes que deben ignorarse, como un número de teléfono ficticio o un correo electrónico ficticio. Ejemplo: Nunca coincida con el teléfono 555-1212, o test@contoso.com |
Coincidencia exacta
Utilice la precisión para determinar qué tan cerca deben estar dos cadenas para considerarse una coincidencia. La configuración de precisión predeterminada requiere una coincidencia exacta. Cualquier otro valor habilita la coincidencia difusa para esa condición.
La precisión se puede establecer en baja (30 % de coincidencia), media (60 % de coincidencia) y alta (80 % de coincidencia). O puede personalizar y configurar la precisión en incrementos del 1%.
Condiciones exactas de coincidencia
Primero se ejecutan las condiciones de coincidencia exactas para obtener un conjunto de valores Más pequeño para coincidencias difusas. Para que sean efectivas, las condiciones de coincidencia exacta deben tener un grado razonable de unicidad. Por ejemplo, si todos sus clientes viven en el mismo país o región, tener una coincidencia exacta en el país o región no ayudará a limitar el alcance.
Columnas como los campos de nombre completo, correo electrónico, teléfono o dirección tienen buena singularidad y son excelentes columnas para usar como coincidencia exacta.
Asegúrese de que la columna que utiliza para una condición de coincidencia exacta no tenga ningún valor que se repita con frecuencia, como un valor predeterminado de "Nombre" capturado por un formulario. Los conocimientos del cliente pueden perfilar columnas de datos para brindar información sobre los principales valores repetidos. Puede habilitar la creación de perfiles de datos en conexiones de Azure Data Lake (mediante el formato Delta o Common Data Model) y Synapse. El perfil de datos se ejecuta la próxima vez que se actualiza origen de datos. Para obtener más información, visite Perfilado de datos.
Coincidencia difusa
Utilice la coincidencia difusa para hacer coincidir cadenas que estén cerca pero que no sean exactas debido a errores tipográficos u otras pequeñas variaciones. Utilice la coincidencia aproximada estratégicamente, ya que es más lenta que las coincidencias exactas. Asegúrese de que haya al menos una condición de coincidencia exacta en cualquier regla que tenga condiciones difusas.
La coincidencia difusa no está destinada a capturar variaciones de nombres como Suzzie y Suzanne. Estas variaciones se capturan mejor con el patrón de Normalización Tipo: Nombre o la Coincidencia de alias personalizada, donde los clientes pueden ingresar su lista de variaciones de nombre que desean considerar como coincidencias.
Puede agregar condiciones a una regla, como hacer coincidir el nombre y el teléfono. Las condiciones dentro de una regla dada son condiciones "Y". Cada condición debe coincidir para que las filas coincidan. Las reglas separadas son condiciones "O". Si la regla 1 no coincide con las filas, entonces las filas se comparan con la regla 2.
Nota
Sólo las columnas de tipo de datos de cadena pueden utilizar concordancia aproximada. Para las columnas con otros tipos de datos, como entero, doble o fecha y hora, el campo de precisión es de solo lectura y se establece para la coincidencia exacta.
Cálculos de coincidencia difusa
Las coincidencias difusas se determinan calculando la puntuación de distancia de edición entre dos cadenas. Si la puntuación cumple o supera el umbral de precisión, las cadenas se consideran coincidentes.
La distancia de edición es la cantidad de ediciones necesarias para convertir una cadena en otra, agregando, eliminando o cambiando un carácter.
Por ejemplo, las cadenas "Jacqueline" y "Jaclyne" tienen una distancia de edición de cinco cuando eliminamos los caracteres q, u, e, i y e, e insertamos el carácter y.
Para calcular la puntuación de la distancia de edición, utilice esta fórmula: (Longitud de la cadena base – Distancia de edición) / Longitud de la cadena base.
| Cadena base | Cadena de comparación | Puntuación |
|---|---|---|
| Jacqueline | Jaclyne | (10-4)/10=0,6 |
| fred@contoso.com | fred@contso.cm | (14-2) / 14 = 0,857 |
| franklin | frank | (8-3) / 8 = 0,625 |