Consideraciones de rendimiento para EF 4, 5 y 6
Por David Obando, Eric Dettinger y otros
Publicado: abril de 2012
Última actualización: mayo de 2014
1. Introducción
Los marcos de asignación relacional de objetos son una manera cómoda de proporcionar una abstracción para el acceso a datos en una aplicación orientada a objetos. En el caso de las aplicaciones .NET, la O/RM recomendada de Microsoft es Entity Framework. Sin embargo, con cualquier abstracción, el rendimiento puede convertirse en un problema.
Esta notas del producto se escribió para mostrar las consideraciones de rendimiento al desarrollar aplicaciones mediante Entity Framework, para dar a los desarrolladores una idea de los algoritmos internos de Entity Framework que pueden afectar al rendimiento y proporcionar sugerencias para investigar y mejorar el rendimiento en sus aplicaciones que usan Entity Framework. Hay una serie de buenos temas sobre el rendimiento ya disponibles en la web y también hemos intentado apuntar a estos recursos siempre que sea posible.
El rendimiento es un tema complicado. Estas notas del producto están pensadas como un recurso para ayudarle a tomar decisiones relacionadas con el rendimiento para las aplicaciones que usan Entity Framework. Hemos incluido algunas métricas de prueba para demostrar el rendimiento, pero estas métricas no están pensadas como indicadores absolutos del rendimiento que verá en la aplicación.
Para fines prácticos, en este documento se da por supuesto que Entity Framework 4 se ejecuta en .NET 4.0 y Entity Framework 5 y 6 se ejecutan en .NET 4.5. Muchas de las mejoras de rendimiento realizadas para Entity Framework 5 residen en los componentes principales que se incluyen con .NET 4.5.
Entity Framework 6 es una versión fuera de banda y no depende de los componentes de Entity Framework que se incluyen con .NET. Entity Framework 6 funciona tanto en .NET 4.0 como en .NET 4.5, y puede ofrecer una gran ventaja de rendimiento a aquellos que no se han actualizado desde .NET 4.0, pero quieren los bits de Entity Framework más recientes en su aplicación. Cuando este documento menciona Entity Framework 6, hace referencia a la versión más reciente disponible en el momento de redactar este documento: versión 6.1.0.
2. Acceso esporádico Ejecución de consultas activas
La primera vez que se realiza cualquier consulta en un modelo determinado, Entity Framework hace mucho trabajo en segundo plano para cargar y validar el modelo. Con frecuencia, se hace referencia a esta primera consulta como una consulta "inactiva". Otras consultas en un modelo ya cargado se conocen como consultas "activas" y son mucho más rápidas.
Vamos a tomar una vista general de dónde se dedica el tiempo al ejecutar una consulta mediante Entity Framework y ver dónde se mejoran las cosas en Entity Framework 6.
Primera ejecución de consulta: consulta inactiva
| Escrituras de usuario de código | Acción | Impacto en el rendimiento de EF4 | Impacto en el rendimiento de EF5 | Impacto en el rendimiento de EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Creación de contexto | Media | Media | Bajo |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Creación de expresiones de consulta | Bajo | Bajo | Bajo |
var c1 = q1.First(); |
Ejecución de consultas LINQ | - Carga de metadatos: Alto pero almacenado en caché - Vista de generación: Potencialmente muy alto pero almacenado en caché - Evaluación de parámetros: Medio - Traducción de consultas: Medio - Generación de materializador: Medio pero almacenado en caché - Ejecución de consultas de base de datos: Potencialmente alta + Connection.Open + Command.ExecuteReader + DataReader.Read Materialización de objetos: Medio - Búsqueda de identidad: Medio |
- Carga de metadatos: Alto pero almacenado en caché - Vista de generación: Potencialmente muy alto pero almacenado en caché - Evaluación de parámetros: Baja - Traducción de consultas: Mediana pero almacenada en caché - Generación de materializador: Medio pero almacenado en caché - Ejecución de consultas de base de datos: Potencialmente alta (mejores consultas en algunas situaciones) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialización de objetos: Medio - Búsqueda de identidad: Medio |
- Carga de metadatos: Alto pero almacenado en caché - Vista de generación: Medio pero almacenado en caché - Evaluación de parámetros: Baja - Traducción de consultas: Mediana pero almacenada en caché - Generación de materializador: Medio pero almacenado en caché - Ejecución de consultas de base de datos: Potencialmente alta (mejores consultas en algunas situaciones) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialización de objetos: Medio (más rápido que EF5) - Búsqueda de identidad: Medio |
} |
Connection.Close | Bajo | Bajo | Bajo |
Segunda ejecución de consulta: consulta activa
| Escrituras de usuario de código | Acción | Impacto en el rendimiento de EF4 | Impacto en el rendimiento de EF5 | Impacto en el rendimiento de EF6 |
|---|---|---|---|---|
using(var db = new MyContext()) { |
Creación de contexto | Media | Media | Bajo |
var q1 = from c in db.Customers where c.Id == id1 select c; |
Creación de expresiones de consulta | Bajo | Bajo | Bajo |
var c1 = q1.First(); |
Ejecución de consultas LINQ | - Metadatos - Ver - Evaluación de parámetros: Medio - Consulta - Materializador - Ejecución de consultas de base de datos: Potencialmente alta + Connection.Open + Command.ExecuteReader + DataReader.Read Materialización de objetos: Medio - Búsqueda de identidad: Medio |
- Metadatos - Ver - Evaluación de parámetros: Baja - Consulta - Materializador - Ejecución de consultas de base de datos: Potencialmente alta (mejores consultas en algunas situaciones) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialización de objetos: Medio - Búsqueda de identidad: Medio |
- Metadatos - Ver - Evaluación de parámetros: Baja - Consulta - Materializador - Ejecución de consultas de base de datos: Potencialmente alta (mejores consultas en algunas situaciones) + Connection.Open + Command.ExecuteReader + DataReader.Read Materialización de objetos: Medio (más rápido que EF5) - Búsqueda de identidad: Medio |
} |
Connection.Close | Bajo | Bajo | Bajo |
Hay varias maneras de reducir el costo de rendimiento de las consultas en frío y en caliente y echaremos un vistazo a ellas en la sección siguiente. En concreto, veremos cómo reducir el costo de la carga del modelo en consultas inactivas mediante vistas generadas previamente, lo que debería ayudar a aliviar los problemas de rendimiento experimentados durante la generación de vistas. En el caso de las consultas activas, trataremos el almacenamiento en caché del plan de consulta, sin consultas de seguimiento y diferentes opciones de ejecución de consultas.
2.1 ¿Qué es la generación de vistas?
Para comprender qué es la generación de vistas, primero debemos comprender qué “son las vistas” de asignación. Las vistas de asignación son representaciones ejecutables de las transformaciones especificadas en la asignación de cada conjunto de entidades y asociación. Internamente, estas vistas de asignación toman la forma de CQT (árboles de consulta canónicos). Hay dos tipos de vistas de asignación:
- Vistas de consulta: representan la transformación necesaria para pasar del esquema de base de datos al modelo conceptual.
- Vistas de actualización: representan la transformación necesaria para pasar del modelo conceptual al esquema de la base de datos.
Tenga en cuenta que el modelo conceptual puede diferir del esquema de la base de datos de varias maneras. Por ejemplo, se puede usar una sola tabla para almacenar los datos de dos tipos de entidad diferentes. La herencia y las asignaciones no triviales desempeñan un papel en la complejidad de las vistas de asignación.
El proceso de calcular estas vistas en función de la especificación de la asignación es lo que llamamos generación de vistas. La generación de vistas puede tener lugar dinámicamente cuando se carga un modelo, o en tiempo de compilación, mediante el uso de "vistas generadas previamente"; este último se serializa en forma de instrucciones Entity SQL en un archivo C# o VB.
Cuando se generan vistas, también se validan. Desde el punto de vista del rendimiento, la gran mayoría del costo de la generación de vistas es realmente la validación de las vistas, lo que garantiza que las conexiones entre las entidades tengan sentido y tengan la cardinalidad correcta para todas las operaciones admitidas.
Cuando se ejecuta una consulta sobre un conjunto de entidades, la consulta se combina con la vista de consulta correspondiente y el resultado de esta composición se ejecuta a través del compilador de planes para crear la representación de la consulta que el almacén de respaldo puede comprender. Para SQL Server, el resultado final de esta compilación será una instrucción SELECT de T-SQL. La primera vez que se realiza una actualización a través de un conjunto de entidades, la vista de actualización se ejecuta a través de un proceso similar para transformarla en instrucciones DML para la base de datos de destino.
2.2 Factores que afectan al rendimiento de la generación de vistas
El rendimiento del paso de generación de vistas no solo depende del tamaño del modelo, sino también de la interconexión del modelo. Si dos entidades están conectadas a través de una cadena de herencia o una asociación, se dice que están conectadas. De forma similar, si dos tablas están conectadas a través de una clave externa, están conectadas. A medida que aumenta el número de entidades y tablas conectadas en los esquemas, aumenta el costo de generación de vistas.
El algoritmo que usamos para generar y validar vistas es exponencial en el peor de los casos, aunque usamos algunas optimizaciones para mejorar esto. Los factores más importantes que parecen afectar negativamente al rendimiento son:
- Tamaño del modelo, que hace referencia al número de entidades y la cantidad de asociaciones entre estas entidades.
- Complejidad del modelo, en concreto la herencia que implica un gran número de tipos.
- Usar asociaciones independientes, en lugar de asociaciones de clave externa.
Para modelos pequeños y sencillos, el costo puede ser lo suficientemente pequeño como para no molestarse en el uso de vistas generadas previamente. A medida que aumenta el tamaño del modelo y la complejidad, hay varias opciones disponibles para reducir el costo de la generación y validación de vistas.
2.3 Uso de vistas generadas previamente para reducir el tiempo de carga del modelo
Para obtener información detallada sobre cómo usar vistas generadas previamente en Entity Framework 6, visite vistas de asignación generadas previamente
2.3.1 Vistas generadas previamente mediante Entity Framework Power Tools Community Edition
Puede usar el Entity Framework 6 Power Tools Community Edition para generar vistas de modelos EDMX y Code First haciendo clic con el botón derecho en el archivo de clase de modelo y usando el menú Entity Framework para seleccionar “Generar vistas”. Entity Framework Power Tools Community Edition solo funciona en contextos derivados de DbContext.
2.3.2 Uso de vistas generadas previamente con un modelo creado por EDMGen
EDMGen es una utilidad que se incluye con .NET y funciona con Entity Framework 4 y 5, pero no con Entity Framework 6. EDMGen permite generar un archivo de modelo, la capa de objetos y las vistas desde la línea de comandos. Una de las salidas será un archivo Views en el lenguaje que prefiera, VB o C#. Se trata de un archivo de código que contiene fragmentos de código de Entity SQL para cada conjunto de entidades. Para habilitar las vistas generadas previamente, basta con incluir el archivo en el proyecto.
Si realiza modificaciones manualmente en los archivos de esquema del modelo, deberá volver a generar el archivo de vistas. Para ello, ejecute EDMGen con la marca de /mode:ViewGeneration.
2.3.3 Uso de vistas generadas previamente con un archivo EDMX
También puede usar EDMGen para generar vistas para un archivo EDMX: el tema de MSDN al que se hace referencia anteriormente describe cómo agregar un evento anterior a la compilación para hacerlo, pero esto es complicado y hay algunos casos en los que no es posible. Por lo general, es más fácil usar una plantilla T4 para generar las vistas cuando el modelo está en un archivo edmx.
El blog del equipo de ADO.NET tiene una entrada que describe cómo usar una plantilla de T4 para la generación de vistas ( <https://learn.microsoft.com/archive/blogs/adonet/how-to-use-a-t4-template-for-view-generation>). Esta publicación incluye una plantilla que se puede descargar y agregar al proyecto. La plantilla se escribió para la primera versión de Entity Framework, por lo que no se garantiza que funcionen con las versiones más recientes de Entity Framework. Sin embargo, puede descargar un conjunto más actualizado de plantillas de generación de vistas para Entity Framework 4 y 5 desde la Galería de Visual Studio:
- VB.NET: <http://visualstudiogallery.msdn.microsoft.com/118b44f2-1b91-4de2-a584-7a680418941d>
- C#: <http://visualstudiogallery.msdn.microsoft.com/ae7730ce-ddab-470f-8456-1b313cd2c44d>
Si’usa Entity Framework 6, puede obtener las plantillas T4 de generación de vistas desde la Galería de Visual Studio en <http://visualstudiogallery.msdn.microsoft.com/18a7db90-6705-4d19-9dd1-0a6c23d0751f>.
2.4 Reducir el costo de la generación de vistas
El uso de vistas generadas previamente mueve el costo de la generación de vistas desde la carga del modelo (tiempo de ejecución) hasta el tiempo de diseño. Aunque esto mejora el rendimiento de inicio en tiempo de ejecución, seguirá experimentando el dolor de generación de vistas mientras desarrolla. Hay varios trucos adicionales que pueden ayudar a reducir el costo de la generación de vistas, tanto en tiempo de compilación como en tiempo de ejecución.
2.4.1 Uso de asociaciones de claves externas para reducir el costo de generación de vistas
Hemos visto una serie de casos en los que cambiar las asociaciones en el modelo de asociaciones independientes a asociaciones de clave externa ha mejorado considerablemente el tiempo invertido en la generación de vistas.
Para demostrar esta mejora, hemos generado dos versiones del modelo de Navision mediante EDMGen. Nota: vea el apéndice C para obtener una descripción del modelo de Navision. El modelo Navision es interesante para este ejercicio debido a su gran cantidad de entidades y relaciones entre ellos.
Se generó una versión de este modelo muy grande con asociaciones de claves externas y la otra se generó con asociaciones independientes. A continuación, se ha temporizador cuánto tiempo se tarda en generar las vistas de cada modelo. La prueba de Entity Framework 5 usó el método GenerateViews() de la clase EntityViewGenerator para generar las vistas, mientras que la prueba de Entity Framework 6 usaba el método GenerateViews() de la clase StorageMappingItemCollection. Esto se debe a la reestructuración del código que se produjo en el código base de Entity Framework 6.
Con Entity Framework 5, la generación de vistas para el modelo con claves externas tardó 65 minutos en una máquina de laboratorio. Se desconoce cuánto tiempo habría tardado en generar las vistas del modelo que usaban asociaciones independientes. Dejamos la prueba en ejecución durante más de un mes antes de reiniciar la máquina en nuestro laboratorio para instalar actualizaciones mensuales.
Con Entity Framework 6, la generación de vistas para el modelo con claves externas tardó 28 segundos en la misma máquina de laboratorio. La generación de vistas para el modelo que usa asociaciones independientes tardó 58 segundos. Las mejoras realizadas en Entity Framework 6 en su código de generación de vistas significan que muchos proyectos no necesitarán vistas generadas previamente para obtener tiempos de inicio más rápidos.
Es importante señalar que la generación previa de vistas en Entity Framework 4 y 5 se puede realizar con EDMGen o Entity Framework Power Tools. Para la generación de vistas de Entity Framework 6 se puede realizar a través de Entity Framework Power Tools o mediante programación, como se describe en vistas de asignación generadas previamente.
2.4.1.1 Cómo usar claves externas en lugar de asociaciones independientes
Cuando se usa EDMGen o el Diseñador de entidades en Visual Studio, se obtienen los FK de forma predeterminada y solo se toma una sola casilla o marca de línea de comandos para cambiar entre los FK e IAs.
Si tiene un modelo de Code First grande, el uso de asociaciones independientes tendrá el mismo efecto en la generación de vistas. Puede evitar este impacto si incluye propiedades de clave externa en las clases de los objetos dependientes, aunque algunos desarrolladores considerarán que está contaminando su modelo de objetos. Puede encontrar más información sobre este tema en <http://blog.oneunicorn.com/2011/12/11/whats-the-deal-with-mapping-foreign-keys-using-the-entity-framework/>.
| Cuando se usa | Haga lo siguiente |
|---|---|
| Diseñador de entidades | Después de agregar una asociación entre dos entidades, asegúrese de que tiene una restricción referencial. Las restricciones referenciales indican a Entity Framework que use claves externas en lugar de asociaciones independientes. Para obtener detalles adicionales, visite <https://learn.microsoft.com/archive/blogs/efdesign/foreign-keys-in-the-entity-framework>. |
| EDMGen | Al usar EDMGen para generar los archivos desde la base de datos, se respetarán las claves externas y se agregarán al modelo como tal. Para obtener más información sobre las distintas opciones expuestas por EDMGen, visite http://msdn.microsoft.com/library/bb387165.aspx. |
| Code First | Vea la sección "Convención de relaciones" del tema Convenciones de Code First para obtener información sobre cómo incluir propiedades de clave externa en objetos dependientes al usar Code First. |
2.4.2 Traslado del modelo a un ensamblado independiente
Cuando el modelo se incluye directamente en el proyecto de la aplicación y genera vistas a través de un evento de compilación previa o una plantilla de T4, la generación de vistas y la validación se realizarán siempre que se vuelva a generar el proyecto, incluso si el modelo no se cambió. Si mueve el modelo a un ensamblado independiente y hace referencia a él desde el proyecto de la aplicación, puede realizar otros cambios en la aplicación sin necesidad de volver a generar el proyecto que contiene el modelo.
Nota: al mover el modelo a ensamblados independientes recuerde copiar las cadenas de conexión del modelo en el archivo de configuración de la aplicación del proyecto cliente.
2.4.3 Deshabilitar la validación de un modelo basado en edmx
Los modelos EDMX se validan en tiempo de compilación, incluso si el modelo no cambia. Si el modelo ya se ha validado, puede suprimir la validación en tiempo de compilación estableciendo la propiedad "Validar en compilación" en false en la ventana de propiedades. Al cambiar la asignación o el modelo, puede volver a habilitar temporalmente la validación para comprobar los cambios.
Tenga en cuenta que las mejoras de rendimiento se realizaron en Entity Framework Designer para Entity Framework 6 y el costo de “Validar en compilación” es mucho menor que en versiones anteriores del diseñador.
3 Almacenamiento en caché en Entity Framework
Entity Framework tiene las siguientes formas de almacenamiento en caché integrados:
- Almacenamiento en caché de objetos: el ObjectStateManager integrado en una instancia de ObjectContext realiza un seguimiento en la memoria de los objetos que se han recuperado mediante esa instancia. Esto también se conoce como caché de primer nivel.
- Almacenamiento en caché del plan de consulta: reutilización del comando de almacén generado cuando se ejecuta una consulta más de una vez.
- Almacenamiento en caché de metadatos: comparte los metadatos de un modelo en distintas conexiones con el mismo modelo.
Además de las memorias caché que EF proporciona de forma predeterminada, también se puede usar un tipo especial de proveedor de datos de ADO.NET conocido como proveedor de ajuste para ampliar Entity Framework con una memoria caché para los resultados recuperados de la base de datos, también conocido como almacenamiento en caché de segundo nivel.
3.1 Almacenamiento en caché de objetos
De forma predeterminada, cuando se devuelve una entidad en los resultados de una consulta, justo antes de que EF lo materialice, ObjectContext comprobará si ya se ha cargado una entidad con la misma clave en su ObjectStateManager. Si una entidad con las mismas claves ya está presente, EF la incluirá en los resultados de la consulta. Aunque EF seguirá emitiendo la consulta en la base de datos, este comportamiento puede omitir gran parte del costo de materializar la entidad varias veces.
3.1.1 Obtención de entidades de la caché de objetos mediante DbContext Find
A diferencia de una consulta normal, el método Find en DbSet (API incluidas por primera vez en EF 4.1) realizará una búsqueda en la memoria antes de incluso emitir la consulta en la base de datos. Es importante tener en cuenta que dos instancias de ObjectContext diferentes tendrán dos instancias de ObjectStateManager diferentes, lo que significa que tienen cachés de objetos independientes.
Buscar usa el valor de clave principal para intentar buscar una entidad de la que realiza el seguimiento el contexto. Si la entidad no está en el contexto, se ejecutará y evaluará una consulta en la base de datos y se devolverá null si la entidad no se encuentra en el contexto o en la base de datos. Tenga en cuenta que Find también devuelve entidades que se han agregado al contexto, pero que aún no se han guardado en la base de datos.
Se debe tener en cuenta una consideración de rendimiento al usar Find. Las invocaciones a este método de forma predeterminada desencadenarán una validación de la memoria caché de objetos para detectar cambios que todavía están pendientes de confirmación en la base de datos. Este proceso puede ser muy caro si hay un gran número de objetos en la memoria caché de objetos o en un gráfico de objetos grande que se agrega a la memoria caché de objetos, pero también se puede deshabilitar. En ciertos casos, es posible que perciba un orden de magnitud de diferencia en llamar al método Find al deshabilitar la detección automática de cambios. Sin embargo, se percibe un segundo orden de magnitud cuando el objeto está realmente en la memoria caché frente a cuando el objeto tiene que recuperarse de la base de datos. Este es un gráfico de ejemplo con medidas tomadas mediante algunas de nuestras marcas microbianas, expresadas en milisegundos, con una carga de 5000 entidades:

Ejemplo de Búsqueda con detección automática de cambios deshabilitados:
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
context.Configuration.AutoDetectChangesEnabled = true;
...
Lo que debe tener en cuenta al usar el método Find es:
- Si el objeto no está en la memoria caché, las ventajas de Find se niegan, pero la sintaxis sigue siendo más sencilla que una consulta por clave.
- Si la detección automática de cambios está habilitada, el costo del método Find puede aumentar en un orden de magnitud, o incluso más en función de la complejidad del modelo y la cantidad de entidades en la memoria caché de objetos.
Además, tenga en cuenta que Find solo devuelve la entidad que está buscando y no carga automáticamente sus entidades asociadas si aún no están en la caché de objetos. Si necesita recuperar entidades asociadas, puede usar una consulta mediante clave con carga diligente. Para obtener más información, vea 8.1 Carga diferida frente a Carga diligente.
3.1.2 Problemas de rendimiento cuando la caché de objetos tiene muchas entidades
La caché de objetos ayuda a aumentar la capacidad de respuesta general de Entity Framework. Sin embargo, cuando la caché de objetos tiene una gran cantidad de entidades cargadas, puede afectar a ciertas operaciones como Agregar, Quitar, Buscar, Entrada, SaveChanges y mucho más. En concreto, las operaciones que desencadenan una llamada a DetectChanges se verán afectadas negativamente por cachés de objetos muy grandes. DetectChanges sincroniza el gráfico de objetos con el administrador de estado de objetos y su rendimiento determinará directamente por el tamaño del gráfico de objetos. Para obtener más información sobre DetectChanges, vea Seguimiento de cambios en entidades POCO.
Al usar Entity Framework 6, los desarrolladores pueden llamar a AddRange y RemoveRange directamente en un DbSet, en lugar de iterar en una colección y llamar a Add una vez por instancia. La ventaja de usar los métodos de intervalo es que el costo de DetectChanges solo se paga una vez por todo el conjunto de entidades, en lugar de una vez por cada entidad agregada.
3.2 Almacenamiento en caché del plan de consulta
La primera vez que se ejecuta una consulta, pasa por el compilador de planes internos para traducir la consulta conceptual al comando store (por ejemplo, el T-SQL que se ejecuta cuando se ejecuta en SQL Server). Si el almacenamiento en caché del plan de consulta está habilitado, la próxima vez que se ejecute la consulta, el comando store se recupera directamente desde la memoria caché del plan de consulta para su ejecución, omitiendo el compilador de planes.
La caché del plan de consulta se comparte entre instancias de ObjectContext dentro del mismo AppDomain. No es necesario mantener en una instancia de ObjectContext para beneficiarse del almacenamiento en caché del plan de consulta.
3.2.1 Algunas notas sobre el almacenamiento en caché del plan de consulta
- La caché del plan de consultas se comparte para todos los tipos de consultas: Entity SQL, LINQ to Entities y objetos CompiledQuery.
- De forma predeterminada, el almacenamiento en caché del plan de consulta está habilitado para las consultas de Entity SQL, independientemente de si se ejecutan a través de EntityCommand o a través de ObjectQuery. También está habilitado de forma predeterminada para las consultas LINQ to Entities en Entity Framework en .NET 4.5 y en Entity Framework 6.
- El almacenamiento en caché del plan de consulta se puede deshabilitar estableciendo la propiedad EnablePlanCaching (en EntityCommand o ObjectQuery) en false. Por ejemplo:
var query = from customer in context.Customer
where customer.CustomerId == id
select new
{
customer.CustomerId,
customer.Name
};
ObjectQuery oQuery = query as ObjectQuery;
oQuery.EnablePlanCaching = false;
- En el caso de las consultas con parámetros, el cambio del valor del parámetro seguirá presionando la consulta almacenada en caché. Pero cambiar las facetas de un parámetro (por ejemplo, tamaño, precisión o escala) alcanzará una entrada diferente en la memoria caché.
- Al usar Entity SQL, la cadena de consulta forma parte de la clave. Cambiar la consulta en absoluto dará lugar a entradas de caché diferentes, incluso si las consultas son funcionalmente equivalentes. Esto incluye cambios en mayúsculas o espacios en blanco.
- Al usar LINQ, la consulta se procesa para generar una parte de la clave. El cambio de la expresión LINQ generará una clave diferente.
- Se pueden aplicar otras limitaciones técnicas; vea Consultas autocompiladas para obtener más detalles.
3.2.2 Algoritmo de expulsión de caché
Comprender cómo funciona el algoritmo interno le ayudará a averiguar cuándo habilitar o deshabilitar el almacenamiento en caché del plan de consulta. El algoritmo de limpieza es el siguiente:
- Una vez que la caché contiene un número establecido de entradas (800), iniciamos un temporizador que barre la memoria caché periódicamente (una vez por minuto).
- Durante los barridos de caché, las entradas se quitan de la memoria caché en una base de LFRU (que se usa recientemente: con menos frecuencia). Este algoritmo tiene en cuenta el recuento de aciertos y la antigüedad al decidir qué entradas se expulsan.
- Al final de cada barrido de caché, la memoria caché contiene de nuevo 800 entradas.
Todas las entradas de caché se tratan igualmente al determinar qué entradas expulsar. Esto significa que el comando store de una CompiledQuery tiene la misma posibilidad de expulsión que el comando store para una consulta Entity SQL.
Tenga en cuenta que el temporizador de expulsión de caché se inicia cuando hay 800 entidades en la memoria caché, pero la memoria caché solo se elimina 60 segundos después de iniciar este temporizador. Esto significa que, durante un máximo de 60 segundos, la memoria caché puede crecer hasta ser bastante grande.
3.2.3 Métricas de prueba que muestran el rendimiento del almacenamiento en caché del plan de consulta
Para demostrar el efecto del almacenamiento en caché del plan de consulta en el rendimiento de la aplicación, hemos realizado una prueba en la que ejecutamos una serie de consultas Entity SQL en el modelo Navision. Vea el apéndice para obtener una descripción del modelo de Navision y los tipos de consultas que se ejecutaron. En esta prueba, primero recorremos en iteración la lista de consultas y ejecutamos cada una de ellas una vez para agregarlas a la memoria caché (si el almacenamiento en caché está habilitado). Este paso no está cronometrado. A continuación, dormimos el subproceso principal durante más de 60 segundos para permitir que se realice el barrido de caché; Por último, recorremos en iteración la lista una segunda vez para ejecutar las consultas almacenadas en caché. Además, la memoria caché del plan de SQL Server se vacía antes de que se ejecute cada conjunto de consultas para que las veces que obtengamos reflejen con precisión la ventaja dada por la memoria caché del plan de consulta.
3.2.3.1 Resultados de pruebas
| Prueba | EF5 sin caché | EF5 almacenado en caché | EF6 sin caché | EF6 almacenado en caché |
|---|---|---|---|---|
| Enumerar todas las consultas 18723 | 124 | 125,4 | 124,3 | 125.3 |
| Evitar barrido (solo las primeras 800 consultas, independientemente de la complejidad) | 41.7 | 5.5 | 40,5 | 5.4 |
| Solo las consultas AggregatingSubtotals (178 en total, lo que evita el barrido) | 39,5 | 4.5 | 38,1 | 4.6 |
Todas las veces en segundos.
Moral: al ejecutar una gran cantidad de consultas distintas (por ejemplo, consultas creadas dinámicamente), el almacenamiento en caché no ayuda y el vaciado resultante de la memoria caché puede mantener las consultas que más se beneficiarían del almacenamiento en caché del plan de su uso.
Las consultas AggregatingSubtotals son las más complejas de las consultas que probamos. Como se esperaba, cuanto más compleja sea la consulta, más ventaja verá del almacenamiento en caché del plan de consulta.
Dado que CompiledQuery es realmente una consulta LINQ con su plan almacenado en caché, la comparación de una CompiledQuery frente a la consulta de Entity SQL equivalente debe tener resultados similares. De hecho, si una aplicación tiene muchas consultas dinámicas de Entity SQL, rellenar la caché con consultas también hará que CompiledQueries se “descompile” cuando se vacían de la memoria caché. En este escenario, el rendimiento se puede mejorar deshabilitando el almacenamiento en caché en las consultas dinámicas para priorizar CompiledQueries. Mejor aún, por supuesto, sería volver a escribir la aplicación para usar consultas con parámetros en lugar de consultas dinámicas.
3.3 Uso de CompiledQuery para mejorar el rendimiento con consultas LINQ
Nuestras pruebas indican que el uso de CompiledQuery puede aportar una ventaja del 7 % sobre las consultas LINQ autocompiladas; esto significa que dedicará un 7 % menos tiempo a ejecutar código desde la pila de Entity Framework; no significa que la aplicación sea un 7 % más rápida. Por lo general, es posible que el costo de escribir y mantener objetos CompiledQuery en EF 5.0 no valga la pena en comparación con las ventajas. El kilometraje puede variar, por lo que puede ejercer esta opción si el proyecto requiere la inserción adicional. Tenga en cuenta que CompiledQueries solo son compatibles con los modelos derivados de ObjectContext y no son compatibles con los modelos derivados de DbContext.
Para obtener más información sobre cómo crear e invocar una CompiledQuery, vea Consultas compiladas (LINQ to Entities).
Hay dos consideraciones que debe tener en cuenta al usar CompiledQuery, es decir, el requisito de usar instancias estáticas y los problemas que tienen con la capacidad de composición. A continuación se muestra una explicación detallada de estas dos consideraciones.
3.3.1 Uso de instancias estáticas de CompiledQuery
Dado que la compilación de una consulta LINQ es un proceso que consume mucho tiempo, no queremos hacerlo cada vez que necesitamos capturar datos de la base de datos. Las instancias de CompiledQuery le permiten compilar una vez y ejecutarse varias veces, pero debe tener cuidado y adquirir para volver a usar la misma instancia de CompiledQuery cada vez en lugar de compilarla de nuevo. El uso de miembros estáticos para almacenar las instancias de CompiledQuery es necesario; de lo contrario, no verá ninguna ventaja.
Por ejemplo, supongamos que la página tiene el siguiente cuerpo del método para controlar la visualización de los productos de la categoría seleccionada:
// Warning: this is the wrong way of using CompiledQuery
using (NorthwindEntities context = new NorthwindEntities())
{
string selectedCategory = this.categoriesList.SelectedValue;
var productsForCategory = CompiledQuery.Compile<NorthwindEntities, string, IQueryable<Product>>(
(NorthwindEntities nwnd, string category) =>
nwnd.Products.Where(p => p.Category.CategoryName == category)
);
this.productsGrid.DataSource = productsForCategory.Invoke(context, selectedCategory).ToList();
this.productsGrid.DataBind();
}
this.productsGrid.Visible = true;
En este caso, creará una nueva instancia de CompiledQuery sobre la marcha cada vez que se llama al método. En lugar de ver las ventajas de rendimiento recuperando el comando store de la memoria caché del plan de consulta, CompiledQuery pasará por el compilador de planes cada vez que se cree una nueva instancia. De hecho, contaminará la memoria caché del plan de consulta con una nueva entrada CompiledQuery cada vez que se llame al método .
En su lugar, quiere crear una instancia estática de la consulta compilada, por lo que está invocando la misma consulta compilada cada vez que se llama al método . Una manera de hacerlo es agregando la instancia CompiledQuery como miembro del contexto del objeto. A continuación, puede hacer que las cosas sean un poco más limpias accediendo a CompiledQuery a través de un método auxiliar:
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IEnumerable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IEnumerable<Product> GetProductsForCategory(string categoryName)
{
return productsForCategoryCQ.Invoke(this, categoryName).ToList();
}
Este método auxiliar se invocaría de la siguiente manera:
this.productsGrid.DataSource = context.GetProductsForCategory(selectedCategory);
3.3.2 Redacción en una CompiledQuery
La capacidad de redactar en cualquier consulta LINQ es extremadamente útil; para ello, simplemente invoque un método después de IQueryable, como Skip() o Count(). Sin embargo, al hacerlo básicamente se devuelve un nuevo objeto IQueryable. Aunque no hay nada que impida técnicamente la redacción de una CompiledQuery, si lo hace, la generación de un nuevo objeto IQueryable que requiere volver a pasar por el compilador del plan.
Algunos componentes usarán objetos IQueryable compuestos para habilitar la funcionalidad avanzada. Por ejemplo, ASP.NET’s GridView puede enlazarse a datos a un objeto IQueryable a través de la propiedad SelectMethod. A continuación, GridView creará este objeto IQueryable para permitir la ordenación y paginación sobre el modelo de datos. Como puede ver, el uso de CompiledQuery para GridView no alcanzaría la consulta compilada, pero generaría una nueva consulta autocompilada.
Un lugar donde puede encontrarse con esto es cuando se agregan filtros progresivos a una consulta. Por ejemplo, supongamos que tenía una página Customers con varias listas desplegables para filtros opcionales (por ejemplo, Country y OrdersCount). Puede componer estos filtros a través de los resultados IQueryable de una CompiledQuery, pero si lo hace, la nueva consulta pasará por el compilador de planes cada vez que lo ejecute.
using (NorthwindEntities context = new NorthwindEntities())
{
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployee();
if (this.orderCountFilterList.SelectedItem.Value != defaultFilterText)
{
int orderCount = int.Parse(orderCountFilterList.SelectedValue);
myCustomers = myCustomers.Where(c => c.Orders.Count > orderCount);
}
if (this.countryFilterList.SelectedItem.Value != defaultFilterText)
{
myCustomers = myCustomers.Where(c => c.Address.Country == countryFilterList.SelectedValue);
}
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Para evitar esta nueva compilación, puede volver a escribir CompiledQuery para tener en cuenta los posibles filtros:
private static readonly Func<NorthwindEntities, int, int?, string, IQueryable<Customer>> customersForEmployeeWithFiltersCQ = CompiledQuery.Compile(
(NorthwindEntities context, int empId, int? countFilter, string countryFilter) =>
context.Customers.Where(c => c.Orders.Any(o => o.EmployeeID == empId))
.Where(c => countFilter.HasValue == false || c.Orders.Count > countFilter)
.Where(c => countryFilter == null || c.Address.Country == countryFilter)
);
Lo que se invocaría en la interfaz de usuario como:
using (NorthwindEntities context = new NorthwindEntities())
{
int? countFilter = (this.orderCountFilterList.SelectedIndex == 0) ?
(int?)null :
int.Parse(this.orderCountFilterList.SelectedValue);
string countryFilter = (this.countryFilterList.SelectedIndex == 0) ?
null :
this.countryFilterList.SelectedValue;
IQueryable<Customer> myCustomers = context.InvokeCustomersForEmployeeWithFilters(
countFilter, countryFilter);
this.customersGrid.DataSource = myCustomers;
this.customersGrid.DataBind();
}
Un inconveniente aquí es que el comando del almacén generado siempre tendrá los filtros con las comprobaciones null, pero estos deben ser bastante sencillos para que el servidor de bases de datos optimice:
...
WHERE ((0 = (CASE WHEN (@p__linq__1 IS NOT NULL) THEN cast(1 as bit) WHEN (@p__linq__1 IS NULL) THEN cast(0 as bit) END)) OR ([Project3].[C2] > @p__linq__2)) AND (@p__linq__3 IS NULL OR [Project3].[Country] = @p__linq__4)
3.4 Almacenamiento en caché de metadatos
Entity Framework también admite el almacenamiento en caché de metadatos. Básicamente, este es el almacenamiento en caché de la información de tipo y la información de asignación de tipos a base de datos en diferentes conexiones al mismo modelo. La caché de metadatos es única por AppDomain.
3.4.1 Algoritmo de almacenamiento en caché de metadatos
La información de metadatos de un modelo se almacena en ItemCollection para cada EntityConnection.
- Como nota lateral, hay diferentes objetos ItemCollection para diferentes partes del modelo. Por ejemplo, StoreItemCollections contiene la información sobre el modelo de base de datos; ObjectItemCollection contiene información sobre el modelo de datos; EdmItemCollection contiene información sobre el modelo conceptual.
Si dos conexiones usan la misma cadena de conexión, compartirán la misma instancia de ItemCollection.
Funcionalmente equivalente, pero textualmente diferentes cadenas de conexión pueden dar lugar a diferentes cachés de metadatos. Se realizan tokenizaciones de cadenas de conexión, por lo que simplemente cambiar el orden de los tokens debe dar lugar a metadatos compartidos. Sin embargo, es posible que dos cadenas de conexión que parezcan funcionalmente iguales no se evalúen como idénticas después de la tokenización.
ItemCollection se comprueba periódicamente para su uso. Si se determina que no se ha accedido recientemente a un área de trabajo, se marcará para la limpieza en el siguiente barrido de caché.
La mera creación de una EntityConnection hará que se cree una caché de metadatos (aunque las colecciones de elementos de ella no se inicializarán hasta que se abra la conexión). Esta área de trabajo permanecerá en memoria hasta que el algoritmo de almacenamiento en caché determine que no está “en uso”.
El equipo de asesoramiento al cliente ha escrito una entrada de blog que describe cómo mantener una referencia a ItemCollection para evitar "desuso" al usar modelos grandes: <https://learn.microsoft.com/archive/blogs/appfabriccat/holding-a-reference-to-the-ef-metadataworkspace-for-wcf-services>.
3.4.2 Relación entre el almacenamiento en caché de metadatos y el almacenamiento en caché del plan de consulta
La instancia de caché del plan de consulta reside en la colección ItemCollection de MetadataWorkspace de tipos de almacén. Esto significa que los comandos de almacén almacenados en caché se usarán para las consultas en cualquier contexto que se cree una instancia mediante un objeto MetadataWorkspace determinado. También significa que si tiene dos cadenas de conexiones que son ligeramente diferentes y no coinciden después de la tokenización, tendrá instancias de caché del plan de consulta diferentes.
3.5 Almacenamiento en caché de resultados
Con el almacenamiento en caché de resultados (también conocido como "almacenamiento en caché de segundo nivel"), se conservan los resultados de las consultas en una caché local. Al emitir una consulta, primero verá si los resultados están disponibles localmente antes de consultar en el almacén. Aunque Entity Framework no admite directamente el almacenamiento en caché de resultados, es posible agregar una caché de segundo nivel mediante un proveedor de ajuste. Un proveedor de ajuste de ejemplo con una caché de segundo nivel es la caché de segundo nivel de Alachisoft Caché de segundo nivel de Entity Framework basada en NCache.
Esta implementación del almacenamiento en caché de segundo nivel es una funcionalidad insertada que tiene lugar después de evaluar (y funcletizada) la expresión LINQ y el plan de ejecución de consultas se calcula o se recupera desde la caché de primer nivel. La memoria caché de segundo nivel almacenará solo los resultados de la base de datos sin procesar, por lo que la canalización de materialización se sigue ejecutando después.
3.5.1 Referencias adicionales para el almacenamiento en caché de resultados con el proveedor de ajuste
- Julie Lerman ha escrito un artículo de MSDN "Almacenamiento en caché de segundo nivel en Entity Framework y Windows Azure" que incluye cómo actualizar el proveedor de ajuste de ejemplo para usar el almacenamiento en caché de AppFabric de Windows Server: https://msdn.microsoft.com/magazine/hh394143.aspx
- Si trabaja con Entity Framework 5, el blog del equipo tiene una entrada que describe cómo ejecutar cosas con el proveedor de almacenamiento en caché de Entity Framework 5: <https://learn.microsoft.com/archive/blogs/adonet/ef-caching-with-jarek-kowalskis-provider>. También incluye una plantilla de T4 para ayudar a automatizar la adición del almacenamiento en caché del nivel 2 al proyecto.
4 Consultas autocompiladas
Cuando se emite una consulta en una base de datos mediante Entity Framework, debe pasar por una serie de pasos antes de materializar realmente los resultados; un paso de este tipo es La compilación de consultas. Se sabe que las consultas Entity SQL tienen un buen rendimiento, ya que se almacenan en caché automáticamente, por lo que la segunda o tercera vez que ejecuta la misma consulta que puede omitir el compilador del plan y usar el plan almacenado en caché en su lugar.
Entity Framework 5 introdujo también el almacenamiento en caché automático para las consultas LINQ to Entities. En ediciones anteriores de Entity Framework, la creación de una instancia de CompiledQuery para acelerar el rendimiento era una práctica habitual, ya que esto haría que la consulta LINQ to Entities se pueda almacenar en caché. Dado que el almacenamiento en caché ahora se realiza automáticamente sin el uso de CompiledQuery, llamamos a esta característica “consultas autocompiladas”. Para obtener más información sobre la caché del plan de consulta y su mecánica, vea Almacenamiento en caché del plan de consulta.
Entity Framework detecta cuándo es necesario volver a compilar una consulta y lo hace cuando se invoca la consulta incluso si se ha compilado antes. Las condiciones comunes que hacen que la consulta se vuelva a compilar son:
- Cambiar MergeOption asociado a la consulta. La consulta almacenada en caché no se usará, sino que el compilador del plan se ejecutará de nuevo y el plan recién creado se almacenará en caché.
- Cambiar el valor de ContextOptions.UseCSharpNullComparisonBehavior. Obtiene el mismo efecto que cambiar MergeOption.
Otras condiciones pueden impedir que la consulta use la memoria caché. Los ejemplos comunes son:
- Uso de IEnumerable<T>. Contiene<>(valor T).
- Uso de funciones que generan consultas con constantes.
- Usar las propiedades de un objeto no asignado.
- Vinculación de la consulta a otra consulta que requiere volver a compilarse.
4.1 Uso de IEnumerable<T>. Contiene<T>(valor T)
Entity Framework no almacena en caché las consultas que invocan IEnumerable<T>. Contiene<T>(valor T) en una colección en memoria, ya que los valores de la colección se consideran volátiles. La consulta de ejemplo siguiente no se almacenará en caché, por lo que el compilador del plan siempre lo procesará:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var query = context.MyEntities
.Where(entity => ids.Contains(entity.Id));
var results = query.ToList();
...
}
Tenga en cuenta que el tamaño de IEnumerable con el que se ejecuta Contains determina la rapidez o la lentitud de la consulta. El rendimiento puede sufrir significativamente al usar colecciones grandes, como la que se muestra en el ejemplo anterior.
Entity Framework 6 contiene optimizaciones de la forma en que IEnumerable<T>. Contiene<T>(valor T) funciona cuando se ejecutan consultas. El código SQL que se genera es mucho más rápido para generar y más legible, y en la mayoría de los casos también se ejecuta más rápido en el servidor.
4.2 Uso de funciones que generan consultas con constantes
Los operadores LINQ Skip(), Take(), Contains() y DefautIfEmpty() no generan consultas SQL con parámetros, sino que colocan los valores pasados a ellos como constantes. Por este motivo, las consultas que podrían ser idénticas terminan contaminando la memoria caché del plan de consulta, tanto en la pila de EF como en el servidor de bases de datos, y no se vuelven a usar a menos que se usen las mismas constantes en una ejecución de consulta posterior. Por ejemplo:
var id = 10;
...
using (var context = new MyContext())
{
var query = context.MyEntities.Select(entity => entity.Id).Contains(id);
var results = query.ToList();
...
}
En este ejemplo, cada vez que se ejecuta esta consulta con un valor diferente para id, la consulta se compilará en un nuevo plan.
En particular, preste atención al uso de Skip y Take al realizar la paginación. En EF6, estos métodos tienen una sobrecarga lambda que hace que el plan de consulta almacenado en caché sea reutilizable porque EF puede capturar variables pasadas a estos métodos y traducirlas a SQLparameters. Esto también ayuda a mantener la caché limpia, ya que, de lo contrario, cada consulta con una constante diferente para Skip y Take obtendría su propia entrada de caché del plan de consulta.
Tenga en cuenta el código siguiente, que es poco óptimo, pero solo está diseñado para ejemplificar esta clase de consultas:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
Una versión más rápida de este mismo código implicaría llamar a Skip con una expresión lambda:
var customers = context.Customers.OrderBy(c => c.LastName);
for (var i = 0; i < count; ++i)
{
var currentCustomer = customers.Skip(() => i).FirstOrDefault();
ProcessCustomer(currentCustomer);
}
El segundo fragmento de código puede ejecutarse hasta un 11 % más rápido porque se usa el mismo plan de consulta cada vez que se ejecuta la consulta, lo que ahorra tiempo de CPU y evita contaminar la caché de consultas. Además, dado que el parámetro para Skip está en un cierre, el código podría tener un aspecto similar ahora:
var i = 0;
var skippyCustomers = context.Customers.OrderBy(c => c.LastName).Skip(() => i);
for (; i < count; ++i)
{
var currentCustomer = skippyCustomers.FirstOrDefault();
ProcessCustomer(currentCustomer);
}
4.3 Uso de las propiedades de un objeto no asignado
Cuando una consulta usa las propiedades de un tipo de objeto no asignado como parámetro, la consulta no se almacenará en caché. Por ejemplo:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myObject.MyProperty)
select entity;
var results = query.ToList();
...
}
En este ejemplo, supongamos que la clase NonMappedType no forma parte del modelo de entidad. Esta consulta se puede cambiar fácilmente para no usar un tipo no asignado y, en su lugar, usar una variable local como parámetro para la consulta:
using (var context = new MyContext())
{
var myObject = new NonMappedType();
var myValue = myObject.MyProperty;
var query = from entity in context.MyEntities
where entity.Name.StartsWith(myValue)
select entity;
var results = query.ToList();
...
}
En este caso, la consulta podrá obtener la memoria caché y se beneficiará de la memoria caché del plan de consulta.
4.4 Vinculación a consultas que requieren volver a compilar
Siguiendo el mismo ejemplo anterior, si tiene una segunda consulta que se basa en una consulta que debe volver a compilarse, también se volverá a compilar la segunda consulta. Este es un ejemplo para ilustrar este escenario:
int[] ids = new int[10000];
...
using (var context = new MyContext())
{
var firstQuery = from entity in context.MyEntities
where ids.Contains(entity.Id)
select entity;
var secondQuery = from entity in context.MyEntities
where firstQuery.Any(otherEntity => otherEntity.Id == entity.Id)
select entity;
var results = secondQuery.ToList();
...
}
El ejemplo es genérico, pero muestra cómo vincular a firstQuery hace que secondQuery no pueda obtener la memoria caché. Si firstQuery no hubiera sido una consulta que requiere volver a compilar, secondQuery se habría almacenado en caché.
5 Consultas sin seguimiento
5.1 Deshabilitación del seguimiento de cambios para reducir la sobrecarga de administración de estados
Si está en un escenario de solo lectura y desea evitar la sobrecarga de cargar los objetos en ObjectStateManager, puede emitir consultas "Sin seguimiento". El seguimiento de cambios se puede deshabilitar en el nivel de consulta.
Tenga en cuenta que, al deshabilitar el seguimiento de cambios, está desactivando eficazmente la caché de objetos. Cuando se consulta una entidad, no se puede omitir la materialización mediante la extracción de los resultados de la consulta materializada anteriormente del ObjectStateManager. Si está consultando repetidamente las mismas entidades en el mismo contexto, es posible que realmente vea una ventaja de rendimiento de habilitar el seguimiento de cambios.
Al realizar consultas mediante ObjectContext, las instancias ObjectQuery y ObjectSet recordarán una MergeOption una vez establecida y las consultas que se componen en ellas heredarán la MergeOption efectiva de la consulta primaria. Cuando se usa DbContext, el seguimiento se puede deshabilitar llamando al modificador AsNoTracking() en DbSet.
5.1.1 Deshabilitación del seguimiento de cambios para una consulta al usar DbContext
Puede cambiar el modo de una consulta a NoTracking encadenando una llamada al método AsNoTracking() de la consulta. A diferencia de ObjectQuery, las clases DbSet y DbQuery de la API DbContext no tienen una propiedad mutable para MergeOption.
var productsForCategory = from p in context.Products.AsNoTracking()
where p.Category.CategoryName == selectedCategory
select p;
5.1.2 Deshabilitación del seguimiento de cambios en el nivel de consulta mediante ObjectContext
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
((ObjectQuery)productsForCategory).MergeOption = MergeOption.NoTracking;
5.1.3 Deshabilitación del seguimiento de cambios para un conjunto de entidades completo mediante ObjectContext
context.Products.MergeOption = MergeOption.NoTracking;
var productsForCategory = from p in context.Products
where p.Category.CategoryName == selectedCategory
select p;
5.2 Métricas de prueba que muestran la ventaja de rendimiento de las consultas NoTracking
En esta prueba, veremos el costo de rellenar ObjectStateManager comparando las consultas Tracking con NoTracking para el modelo Navision. Vea el apéndice para obtener una descripción del modelo de Navision y los tipos de consultas que se ejecutaron. En esta prueba, recorremos en iteración la lista de consultas y ejecutamos cada una de ellas una vez. Hemos ejecutado dos variaciones de la prueba, una vez con consultas NoTracking y una vez con la opción de combinación predeterminada de "AppendOnly". Ejecutamos cada variación 3 veces y tomamos el valor medio de las ejecuciones. Entre las pruebas borramos la caché de consultas en SQL Server y reducimos tempdb mediante la ejecución de los siguientes comandos:
- DBCC DROPCLEANBUFFERS
- DBCC FREEPROCCACHE
- DBCC SHRINKDATABASE (tempdb, 0)
Resultados de la prueba, mediana de más de 3 ejecuciones:
| NINGÚN SEGUIMIENTO: CONJUNTO DE TRABAJO | SIN SEGUIMIENTO: HORA | ANEXAR SOLO: CONJUNTO DE TRABAJO | SÓLO ANEXAR: TIEMPO | |
|---|---|---|---|---|
| Entity Framework 5 | 460361728 | 1163536 ms | 596545536 | 1273042 ms |
| Entity Framework 6 | 647127040 | 190228 ms | 832798720 | 195521 ms |
Entity Framework 5 tendrá una superficie de memoria menor al final de la ejecución que Entity Framework 6. La memoria adicional consumida por Entity Framework 6 es el resultado de estructuras de memoria y código adicionales que permiten nuevas características y un mejor rendimiento.
También hay una diferencia clara en la superficie de memoria al usar ObjectStateManager. Entity Framework 5 aumentó su superficie en un 30 % al realizar un seguimiento de todas las entidades que materializamos desde la base de datos. Entity Framework 6 aumentó su superficie en un 28 % al hacerlo.
En términos de tiempo, Entity Framework 6 supera el rendimiento de Entity Framework 5 en esta prueba por un margen grande. Entity Framework 6 completó la prueba en aproximadamente el 16 % del tiempo consumido por Entity Framework 5. Además, Entity Framework 5 tarda un 9 % más en completarse cuando se usa ObjectStateManager. En comparación, Entity Framework 6 usa un 3 % más de tiempo cuando se usa ObjectStateManager.
6 Opciones de ejecución de consultas
Entity Framework ofrece varias maneras diferentes de consultar. Veremos las siguientes opciones, compararemos las ventajas y desventajas de cada una y examinaremos sus características de rendimiento:
- LINQ to Entities
- No hay LINQ to Entities de seguimiento.
- Entity SQL a través de ObjectQuery.
- Entity SQL a través de EntityCommand.
- ExecuteStoreQuery.
- SqlQuery.
- CompiledQuery.
6.1 Consultas LINQ to Entities
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Ventajas
- Adecuado para las operaciones CUD.
- Objetos totalmente materializados.
- Es más sencillo escribir con sintaxis integrada en el lenguaje de programación.
- Buen rendimiento.
Desventajas
- Ciertas restricciones técnicas, como:
- Los patrones que usan DefaultIfEmpty para las consultas OUTER JOIN generan consultas más complejas que instrucciones OUTER JOIN simples en Entity SQL.
- Todavía no puede usar LIKE con coincidencias de patrones generales.
6.2 Consultas LINQ to Entities No Tracking
Cuando el contexto deriva ObjectContext:
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
Cuando el contexto deriva DbContext:
var q = context.Products.AsNoTracking()
.Where(p => p.Category.CategoryName == "Beverages");
Ventajas
- Rendimiento mejorado a través de consultas LINQ normales.
- Objetos totalmente materializados.
- Es más sencillo escribir con sintaxis integrada en el lenguaje de programación.
Desventajas
- No es adecuado para las operaciones CUD.
- Ciertas restricciones técnicas, como:
- Los patrones que usan DefaultIfEmpty para las consultas OUTER JOIN generan consultas más complejas que instrucciones OUTER JOIN simples en Entity SQL.
- Todavía no puede usar LIKE con coincidencias de patrones generales.
Tenga en cuenta que no se realiza un seguimiento de las consultas de las propiedades escalares del proyecto aunque no se especifique NoTracking. Por ejemplo:
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages").Select(p => new { p.ProductName });
Esta consulta en particular no especifica explícitamente NoTracking, pero dado que no materializa un tipo conocido para el administrador de estado de objetos, no se realiza un seguimiento del resultado materializado.
6.3 Entity SQL a través de ObjectQuery
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
Ventajas
- Adecuado para las operaciones CUD.
- Objetos totalmente materializados.
- Admite el almacenamiento en caché del plan de consulta.
Desventajas
- Implica cadenas de consulta textuales que son más propensas a errores de usuario que las construcciones de consulta integradas en el lenguaje.
6.4 Entity SQL a través de un comando Entity
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
while (reader.Read())
{
// manually 'materialize' the product
}
}
Ventajas
- Admite el almacenamiento en caché del plan de consulta en .NET 4.0 (el almacenamiento en caché del plan es compatible con todos los demás tipos de consulta de .NET 4.5).
Desventajas
- Implica cadenas de consulta textuales que son más propensas a errores de usuario que las construcciones de consulta integradas en el lenguaje.
- No es adecuado para las operaciones CUD.
- Los resultados no se materializan automáticamente y deben leerse desde el lector de datos.
6.5 SqlQuery y ExecuteStoreQuery
SqlQuery en la base de datos:
// use this to obtain entities and not track them
var q1 = context.Database.SqlQuery<Product>("select * from products");
SqlQuery en DbSet:
// use this to obtain entities and have them tracked
var q2 = context.Products.SqlQuery("select * from products");
ExecuteStoreQuery:
var beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued, P.DiscontinuedDate
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
Ventajas
- Por lo general, el rendimiento es más rápido, ya que se omite el compilador del plan.
- Objetos totalmente materializados.
- Adecuado para las operaciones CUD cuando se usa desde DbSet.
Desventajas
- La consulta es textual y propensa a errores.
- La consulta está vinculada a un backend específico mediante la semántica de almacén en lugar de la semántica conceptual.
- Cuando la herencia está presente, la consulta artesanal debe tener en cuenta las condiciones de asignación del tipo solicitado.
6.6 CompiledQuery
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
…
var q = context.InvokeProductsForCategoryCQ("Beverages");
Ventajas
- Proporciona hasta un 7 % de mejora del rendimiento en las consultas LINQ normales.
- Objetos totalmente materializados.
- Adecuado para las operaciones CUD.
Desventajas
- Mayor complejidad y sobrecarga de programación.
- La mejora del rendimiento se pierde al redactar sobre una consulta compilada.
- Algunas consultas LINQ no se pueden escribir como CompiledQuery; por ejemplo, proyecciones de tipos anónimos.
6.7 Comparación de rendimiento de diferentes opciones de consulta
Las marcas de microbenchmarks simples en las que no se ha cronometrado la creación del contexto se pusieron a prueba. Hemos medido la consulta 5000 veces para un conjunto de entidades no almacenadas en caché en un entorno controlado. Estos números se deben tomar con una advertencia: no reflejan los números reales producidos por una aplicación, sino que son una medida muy precisa de la cantidad de una diferencia de rendimiento que hay cuando se comparan diferentes opciones de consulta manzanas a manzanas, excepto el costo de crear un nuevo contexto.
| EF | Prueba | Tiempo (ms) | Memoria |
|---|---|---|---|
| EF5 | ObjectContext ESQL | 2414 | 38801408 |
| EF5 | Consulta Linq de ObjectContext | 2692 | 38277120 |
| EF5 | DbContext Linq Query No Tracking | 2818 | 41840640 |
| EF5 | Consulta Linq de DbContext | 2930 | 41771008 |
| EF5 | ObjectContext Linq Query No Tracking | 3013 | 38412288 |
| EF6 | ObjectContext ESQL | 2059 | 46039040 |
| EF6 | Consulta Linq de ObjectContext | 3074 | 45248512 |
| EF6 | DbContext Linq Query No Tracking | 3125 | 47575040 |
| EF6 | Consulta Linq de DbContext | 3420 | 47652864 |
| EF6 | ObjectContext Linq Query No Tracking | 3593 | 45260800 |


Los microbionchmarks son muy sensibles a pequeños cambios en el código. En este caso, la diferencia entre los costos de Entity Framework 5 y Entity Framework 6 se debe a la adición de interceptación y mejoras transaccionales. Sin embargo, estos números de microbionchmarks son una visión amplificada en un fragmento muy pequeño de lo que hace Entity Framework. Los escenarios reales de consultas activas no deben ver una regresión de rendimiento al actualizar de Entity Framework 5 a Entity Framework 6.
Para comparar el rendimiento real de las distintas opciones de consulta, creamos 5 variaciones de prueba independientes en las que usamos una opción de consulta diferente para seleccionar todos los productos cuyo nombre de categoría es "Bebidas". Cada iteración incluye el costo de crear el contexto y el costo de materializar todas las entidades devueltas. Se ejecutan 10 iteraciones sin tiempo antes de tomar la suma de 1000 iteraciones cronometradas. Los resultados que se muestran son la ejecución mediana tomada de 5 ejecuciones de cada prueba. Para obtener más información, vea el Apéndice B, que incluye el código de la prueba.
| EF | Prueba | Tiempo (ms) | Memoria |
|---|---|---|---|
| EF5 | ObjectContext Entity (comando) | 621 | 39350272 |
| EF5 | Consulta Sql de DbContext en la base de datos | 825 | 37519360 |
| EF5 | Consulta del almacén de ObjectContext | 878 | 39460864 |
| EF5 | ObjectContext Linq Query No Tracking | 969 | 38293504 |
| EF5 | ObjectContext Entity Sql mediante la consulta de objetos | 1089 | 38981632 |
| EF5 | Consulta compilada ObjectContext | 1099 | 38682624 |
| EF5 | Consulta Linq de ObjectContext | 1152 | 38178816 |
| EF5 | DbContext Linq Query No Tracking | 1208 | 41803776 |
| EF5 | Consulta sql de DbContext en DbSet | 1414 | 37982208 |
| EF5 | Consulta Linq de DbContext | 1574 | 41738240 |
| EF6 | ObjectContext Entity (comando) | 480 | 47247360 |
| EF6 | Consulta del almacén de ObjectContext | 493 | 46739456 |
| EF6 | Consulta Sql de DbContext en la base de datos | 614 | 41607168 |
| EF6 | ObjectContext Linq Query No Tracking | 684 | 46333952 |
| EF6 | ObjectContext Entity Sql mediante la consulta de objetos | 767 | 48865280 |
| EF6 | Consulta compilada ObjectContext | 788 | 48467968 |
| EF6 | DbContext Linq Query No Tracking | 878 | 47554560 |
| EF6 | Consulta Linq de ObjectContext | 953 | 47632384 |
| EF6 | Consulta sql de DbContext en DbSet | 1023 | 41992192 |
| EF6 | Consulta Linq de DbContext | 1290 | 47529984 |

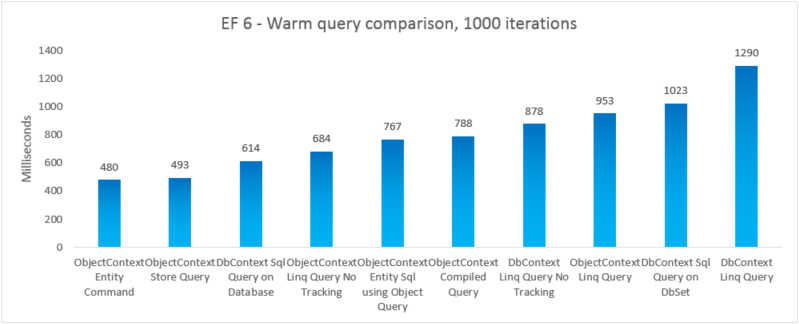
Nota:
Por integridad, hemos incluido una variación en la que se ejecuta una consulta Entity SQL en un EntityCommand. Sin embargo, dado que los resultados no se materializan para estas consultas, la comparación no es necesariamente manzanas a manzanas. La prueba incluye una aproximación cercana a la materialización para intentar hacer que la comparación sea más justa.
En este caso de un extremo a otro, Entity Framework 6 supera el rendimiento de Entity Framework 5 debido a las mejoras de rendimiento realizadas en varias partes de la pila, incluida una inicialización DbContext mucho más ligera y más rápida MetadataCollection<T> búsquedas.
7 Consideraciones sobre el rendimiento del tiempo de diseño
7.1 Estrategias de herencia
Otra consideración de rendimiento al usar Entity Framework es la estrategia de herencia que se usa. Entity Framework admite 3 tipos básicos de herencia y sus combinaciones:
- Tabla por jerarquía (TPH): donde cada conjunto de herencia se asigna a una tabla con una columna discriminador para indicar qué tipo concreto de la jerarquía se representa en la fila.
- Tabla por tipo (TPT): donde cada tipo tiene su propia tabla en la base de datos; las tablas secundarias solo definen las columnas que la tabla primaria no contiene.
- Tabla por clase (TPC): donde cada tipo tiene su propia tabla completa en la base de datos; las tablas secundarias definen todos sus campos, incluidos los definidos en los tipos primarios.
Si el modelo usa la herencia de TPT, las consultas que se generan serán más complejas que las generadas con las otras estrategias de herencia, lo que puede dar lugar a tiempos de ejecución más largos en el almacén. Por lo general, se tardará más tiempo en generar consultas a través de un modelo TPT y para materializar los objetos resultantes.
Vea la entrada de blog "Consideraciones de rendimiento al usar la herencia de TPT (tabla por tipo) en Entity Framework" de MSDN: <https://learn.microsoft.com/archive/blogs/adonet/performance-considerations-when-using-tpt-table-per-type-inheritance-in-the-entity-framework>.
7.1.1 Evitar TPT en las aplicaciones Model First o Code First
Al crear un modelo a través de una base de datos existente que tenga un esquema TPT, no tiene muchas opciones. Pero al crear una aplicación mediante Model First o Code First, debe evitar la herencia de TPT para problemas de rendimiento.
Al usar Model First en el Asistente para diseñadores de entidades, obtendrá TPT para cualquier herencia del modelo. Si desea cambiar a una estrategia de herencia de TPH con Model First, puede usar "Entity Designer Database Generation Power Pack" disponible en la Galería de Visual Studio ( <http://visualstudiogallery.msdn.microsoft.com/df3541c3-d833-4b65-b942-989e7ec74c87/>).
Al usar Code First para configurar la asignación de un modelo con herencia, EF usará TPH de forma predeterminada, por lo que todas las entidades de la jerarquía de herencia se asignarán a la misma tabla. Vea la sección "Asignación con Fluent API" del artículo "Code First in Entity Framework4.1" de MSDN Magazine ( http://msdn.microsoft.com/magazine/hh126815.aspx) para obtener más información.
7.2 Actualización desde EF4 para mejorar el tiempo de generación de modelos
Una mejora específica de SQL Server para el algoritmo que genera la capa de almacén (SSDL) del modelo está disponible en Entity Framework 5 y 6, y como una actualización de Entity Framework 4 cuando se instala Visual Studio 2010 SP1. Los siguientes resultados de la prueba muestran la mejora al generar un modelo muy grande, en este caso el modelo Navision. Vea el Apéndice C para obtener más información sobre él.
El modelo contiene 1005 conjuntos de entidades y 4227 conjuntos de asociaciones.
| Configuración | Desglose del tiempo consumido |
|---|---|
| Visual Studio 2010, Entity Framework 4 | Generación de SSDL: 2 horas 27 minutos Generación de asignaciones: 1 segundo Generación de CSDL: 1 segundo Generación de ObjectLayer: 1 segundo Generación de vistas: 2 h 14 min |
| Visual Studio 2010 SP1, Entity Framework 4 | Generación de SSDL: 1 segundo Generación de asignaciones: 1 segundo Generación de CSDL: 1 segundo Generación de ObjectLayer: 1 segundo Generación de vistas: 1 h 53 min |
| Visual Studio 2013, Entity Framework 5 | Generación de SSDL: 1 segundo Generación de asignaciones: 1 segundo Generación de CSDL: 1 segundo Generación de ObjectLayer: 1 segundo Generación de vistas: 65 minutos |
| Visual Studio 2013, Entity Framework 6 | Generación de SSDL: 1 segundo Generación de asignaciones: 1 segundo Generación de CSDL: 1 segundo Generación de ObjectLayer: 1 segundo Generación de vistas: 28 segundos. |
Vale la pena tener en cuenta que al generar la SSDL, la carga se invierte casi por completo en SQL Server, mientras que el equipo de desarrollo de cliente está esperando que los resultados vuelvan del servidor. Los DBA deben apreciar especialmente esta mejora. También merece la pena tener en cuenta que el costo completo de la generación de modelos tiene lugar ahora en View Generation.
7.3 Dividir modelos grandes con la base de datos primero y el modelo primero
A medida que aumenta el tamaño del modelo, la superficie del diseñador se vuelve desordenada y difícil de usar. Normalmente, se considera que un modelo con más de 300 entidades es demasiado grande para usar eficazmente el diseñador. En la entrada de blog siguiente se describen varias opciones para dividir modelos grandes: <https://learn.microsoft.com/archive/blogs/adonet/working-with-large-models-in-entity-framework-part-2>.
La publicación se escribió para la primera versión de Entity Framework, pero se siguen aplicando los pasos.
7.4 Consideraciones de rendimiento con el control de origen de datos de entidad
Hemos visto casos en pruebas de rendimiento y esfuerzo multiproceso en los que el rendimiento de una aplicación web que usa EntityDataSource Control se deteriora significativamente. La causa subyacente es que EntityDataSource llama repetidamente a MetadataWorkspace.LoadFromAssembly en los ensamblados a los que hace referencia la aplicación web para detectar los tipos que se usarán como entidades.
La solución consiste en establecer ContextTypeName de EntityDataSource en el nombre de tipo de la clase ObjectContext derivada. Esto desactiva el mecanismo que examina todos los ensamblados a los que se hace referencia para los tipos de entidad.
Al establecer el campo ContextTypeName también se impide un problema funcional en el que EntityDataSource en .NET 4.0 produce una excepción ReflectionTypeLoadException cuando no puede cargar un tipo desde un ensamblado a través de la reflexión. Este problema se ha corregido en .NET 4.5.
7.5 Entidades POCO y servidores proxy de seguimiento de cambios
Entity Framework permite usar clases de datos personalizadas junto con el modelo de datos sin realizar modificaciones en las propias clases de datos. Esto significa que podrá utilizar objetos CLR "antiguos" (POCO), tales como objetos de dominio existentes, con el modelo de datos. Estas clases de datos POCO (también conocidas como objetos que ignoran la persistencia), que se asignan a entidades definidas en un modelo de datos, admiten la mayoría de los mismos comportamientos de consulta, inserción, actualización y eliminación como tipos de entidad generados por las herramientas del modelo de datos de entidad.
Entity Framework también puede crear clases de proxy derivadas de los tipos POCO, que se usan cuando desea habilitar características como la carga diferida y el seguimiento automático de cambios en entidades POCO. Las clases POCO deben cumplir ciertos requisitos para permitir que Entity Framework use servidores proxy, como se describe aquí: http://msdn.microsoft.com/library/dd468057.aspx.
Los servidores proxy de seguimiento de probabilidades notificarán al administrador de estado de objetos cada vez que cualquiera de las propiedades de las entidades ha cambiado su valor, por lo que Entity Framework conoce el estado real de las entidades todo el tiempo. Esto se hace agregando eventos de notificación al cuerpo de los métodos establecedores de las propiedades y haciendo que el administrador de estado de objetos procese estos eventos. Tenga en cuenta que la creación de una entidad de proxy suele ser más costosa que la creación de una entidad POCO que no es de proxy debido al conjunto agregado de eventos creados por Entity Framework.
Cuando una entidad POCO no tiene un proxy de seguimiento de cambios, los cambios se encuentran comparando el contenido de las entidades con una copia de un estado guardado anterior. Esta comparación profunda se convertirá en un proceso largo cuando tenga muchas entidades en su contexto o cuando las entidades tengan una gran cantidad de propiedades, incluso si ninguna de ellas ha cambiado desde la última comparación.
En resumen:’pagará un impacto de rendimiento al crear el proxy de seguimiento de cambios, pero el seguimiento de cambios le ayudará a acelerar el proceso de detección de cambios cuando las entidades tengan muchas propiedades o cuando tenga muchas entidades en el modelo. En el caso de las entidades con un pequeño número de propiedades en las que la cantidad de entidades no crece demasiado, es posible que tener servidores proxy de seguimiento de cambios no sea de gran ventaja.
8 Carga de entidades relacionadas
8.1 Carga diferida frente a Carga diligente
Entity Framework ofrece varias maneras diferentes de cargar las entidades relacionadas con la entidad de destino. Por ejemplo, al consultar productos, hay diferentes formas de cargar los pedidos relacionados en el Administrador de estado de objetos. Desde el punto de vista del rendimiento, la pregunta más importante que se debe tener en cuenta al cargar entidades relacionadas será si se debe usar la carga diferida o la carga diligente.
Al usar La carga diligente, las entidades relacionadas se cargan junto con el conjunto de entidades de destino. Use una instrucción Include en la consulta para indicar qué entidades relacionadas desea incluir.
Cuando se usa carga diferida, la consulta inicial solo incluye el conjunto de entidades de destino. Pero siempre que se accede a una propiedad de navegación, se emite otra consulta en el almacén para cargar la entidad relacionada.
Una vez que se ha cargado una entidad, cualquier consulta adicional de la entidad la cargará directamente desde el Administrador de estado de objetos, tanto si usa la carga diferida como la carga diligente.
8.2 Cómo elegir entre la carga diferida y la carga diligente
Lo importante es que comprenda la diferencia entre la carga diferida y la carga diligente para que pueda tomar la opción correcta para la aplicación. Esto le ayudará a evaluar el equilibrio entre varias solicitudes en la base de datos frente a una única solicitud que puede contener una carga grande. Puede ser adecuado usar la carga diligente en algunas partes de la aplicación y la carga diferida en otras partes.
Como ejemplo de lo que sucede en segundo plano, supongamos que desea consultar a los clientes que viven en el Reino Unido y su recuento de pedidos.
Uso de la carga diligente
using (NorthwindEntities context = new NorthwindEntities())
{
var ukCustomers = context.Customers.Include(c => c.Orders).Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Uso de la carga diferida
using (NorthwindEntities context = new NorthwindEntities())
{
context.ContextOptions.LazyLoadingEnabled = true;
//Notice that the Include method call is missing in the query
var ukCustomers = context.Customers.Where(c => c.Address.Country == "UK");
var chosenCustomer = AskUserToPickCustomer(ukCustomers);
Console.WriteLine("Customer Id: {0} has {1} orders", customer.CustomerID, customer.Orders.Count);
}
Al usar la carga diligente, emitirá una única consulta que devuelva todos los clientes y todos los pedidos. El comando store tiene el siguiente aspecto:
SELECT
[Project1].[C1] AS [C1],
[Project1].[CustomerID] AS [CustomerID],
[Project1].[CompanyName] AS [CompanyName],
[Project1].[ContactName] AS [ContactName],
[Project1].[ContactTitle] AS [ContactTitle],
[Project1].[Address] AS [Address],
[Project1].[City] AS [City],
[Project1].[Region] AS [Region],
[Project1].[PostalCode] AS [PostalCode],
[Project1].[Country] AS [Country],
[Project1].[Phone] AS [Phone],
[Project1].[Fax] AS [Fax],
[Project1].[C2] AS [C2],
[Project1].[OrderID] AS [OrderID],
[Project1].[CustomerID1] AS [CustomerID1],
[Project1].[EmployeeID] AS [EmployeeID],
[Project1].[OrderDate] AS [OrderDate],
[Project1].[RequiredDate] AS [RequiredDate],
[Project1].[ShippedDate] AS [ShippedDate],
[Project1].[ShipVia] AS [ShipVia],
[Project1].[Freight] AS [Freight],
[Project1].[ShipName] AS [ShipName],
[Project1].[ShipAddress] AS [ShipAddress],
[Project1].[ShipCity] AS [ShipCity],
[Project1].[ShipRegion] AS [ShipRegion],
[Project1].[ShipPostalCode] AS [ShipPostalCode],
[Project1].[ShipCountry] AS [ShipCountry]
FROM ( SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax],
1 AS [C1],
[Extent2].[OrderID] AS [OrderID],
[Extent2].[CustomerID] AS [CustomerID1],
[Extent2].[EmployeeID] AS [EmployeeID],
[Extent2].[OrderDate] AS [OrderDate],
[Extent2].[RequiredDate] AS [RequiredDate],
[Extent2].[ShippedDate] AS [ShippedDate],
[Extent2].[ShipVia] AS [ShipVia],
[Extent2].[Freight] AS [Freight],
[Extent2].[ShipName] AS [ShipName],
[Extent2].[ShipAddress] AS [ShipAddress],
[Extent2].[ShipCity] AS [ShipCity],
[Extent2].[ShipRegion] AS [ShipRegion],
[Extent2].[ShipPostalCode] AS [ShipPostalCode],
[Extent2].[ShipCountry] AS [ShipCountry],
CASE WHEN ([Extent2].[OrderID] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C2]
FROM [dbo].[Customers] AS [Extent1]
LEFT OUTER JOIN [dbo].[Orders] AS [Extent2] ON [Extent1].[CustomerID] = [Extent2].[CustomerID]
WHERE N'UK' = [Extent1].[Country]
) AS [Project1]
ORDER BY [Project1].[CustomerID] ASC, [Project1].[C2] ASC
Al usar la carga diferida, emitirá inicialmente la siguiente consulta:
SELECT
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[CompanyName] AS [CompanyName],
[Extent1].[ContactName] AS [ContactName],
[Extent1].[ContactTitle] AS [ContactTitle],
[Extent1].[Address] AS [Address],
[Extent1].[City] AS [City],
[Extent1].[Region] AS [Region],
[Extent1].[PostalCode] AS [PostalCode],
[Extent1].[Country] AS [Country],
[Extent1].[Phone] AS [Phone],
[Extent1].[Fax] AS [Fax]
FROM [dbo].[Customers] AS [Extent1]
WHERE N'UK' = [Extent1].[Country]
Y cada vez que accede a la propiedad de navegación orden de un cliente, se emite otra consulta como la siguiente en el almacén:
exec sp_executesql N'SELECT
[Extent1].[OrderID] AS [OrderID],
[Extent1].[CustomerID] AS [CustomerID],
[Extent1].[EmployeeID] AS [EmployeeID],
[Extent1].[OrderDate] AS [OrderDate],
[Extent1].[RequiredDate] AS [RequiredDate],
[Extent1].[ShippedDate] AS [ShippedDate],
[Extent1].[ShipVia] AS [ShipVia],
[Extent1].[Freight] AS [Freight],
[Extent1].[ShipName] AS [ShipName],
[Extent1].[ShipAddress] AS [ShipAddress],
[Extent1].[ShipCity] AS [ShipCity],
[Extent1].[ShipRegion] AS [ShipRegion],
[Extent1].[ShipPostalCode] AS [ShipPostalCode],
[Extent1].[ShipCountry] AS [ShipCountry]
FROM [dbo].[Orders] AS [Extent1]
WHERE [Extent1].[CustomerID] = @EntityKeyValue1',N'@EntityKeyValue1 nchar(5)',@EntityKeyValue1=N'AROUT'
Para obtener más información, vea la Carga de objetos relacionados.
8.2.1 Carga diferida frente a la hoja de referencia rápida de carga diligente
No hay nada como un ajuste de un solo tamaño para elegir la carga diligente frente a la carga diferida. Intente comprender primero las diferencias entre ambas estrategias para que pueda tomar una decisión bien fundamentada; además, tenga en cuenta si el código se ajusta a cualquiera de los escenarios siguientes:
| Escenario | Nuestra sugerencia |
|---|---|
| ¿Necesita acceder a muchas propiedades de navegación desde las entidades capturadas? | No: Ambas opciones probablemente lo harán. Sin embargo, si la carga útil que lleva la consulta no es demasiado grande, puede experimentar ventajas de rendimiento mediante la carga diligente, ya que requerirá menos recorridos de ida y vuelta de red para materializar los objetos. Sí: Si necesita acceder a muchas propiedades de navegación desde las entidades, lo haría mediante varias instrucciones include en la consulta con carga diligente. Cuantos más entidades incluya, mayor será la carga que devolverá la consulta. Una vez que incluya tres o más entidades en la consulta, considere la posibilidad de cambiar a carga diferida. |
| ¿Sabe exactamente qué datos se necesitarán en tiempo de ejecución? | No: La carga diferida será mejor para usted. De lo contrario, es posible que termine consultando los datos que no necesitará. Sí: Carga diligente es probablemente su mejor opción; ayudará a cargar conjuntos completos más rápido. Si la consulta requiere capturar una gran cantidad de datos y esto se vuelve demasiado lento, pruebe la carga diferida en su lugar. |
| ¿El código se ejecuta lejos de la base de datos? (mayor latencia de red) | No: Cuando la latencia de red no es un problema, el uso de la carga diferida puede simplificar el código. Recuerde que la topología de la aplicación puede cambiar, por lo que no se concede la proximidad de la base de datos. Sí: Cuando la red es un problema, solo puede decidir lo que mejor se adapte a su escenario. Normalmente, la carga diligente será mejor porque requiere menos recorridos de ida y vuelta. |
8.2.2 Problemas de rendimiento con varias inclusiones
Cuando escuchamos preguntas de rendimiento que implican problemas de tiempo de respuesta del servidor, el origen del problema es consultas frecuentes con varias instrucciones Include. Aunque la inclusión de entidades relacionadas en una consulta es eficaz, es importante comprender lo que sucede en segundo plano.
Tarda un tiempo relativamente largo en una consulta con varias instrucciones Include en ella para pasar por nuestro compilador de planes internos para generar el comando store. La mayoría de este tiempo se dedica a intentar optimizar la consulta resultante. El comando de almacén generado contendrá una combinación externa o unión para cada Include, en función de la asignación. Las consultas como esta traen gráficos conectados de gran tamaño de la base de datos en una sola carga, lo que acentuará cualquier problema de ancho de banda, especialmente cuando haya una gran cantidad de redundancia en la carga (por ejemplo, cuando se usan varios niveles de Include para atravesar asociaciones en la dirección uno a varios).
Puede comprobar si hay casos en los que las consultas devuelven cargas excesivamente grandes accediendo al TSQL subyacente para la consulta mediante ToTraceString y ejecutando el comando store en SQL Server Management Studio para ver el tamaño de la carga. En tales casos, puede intentar reducir el número de instrucciones Include de la consulta para que solo incluya los datos que necesita. O puede dividir la consulta en una secuencia más pequeña de subconsultas, por ejemplo:
Antes de interrumpir la consulta:
using (NorthwindEntities context = new NorthwindEntities())
{
var customers = from c in context.Customers.Include(c => c.Orders)
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Después de interrumpir la consulta:
using (NorthwindEntities context = new NorthwindEntities())
{
var orders = from o in context.Orders
where o.Customer.LastName.StartsWith(lastNameParameter)
select o;
orders.Load();
var customers = from c in context.Customers
where c.LastName.StartsWith(lastNameParameter)
select c;
foreach (Customer customer in customers)
{
...
}
}
Esto solo funcionará en consultas de seguimiento, ya que estamos haciendo uso de la capacidad que el contexto tiene para realizar la resolución de identidades y la corrección de asociaciones automáticamente.
Al igual que con la carga diferida, la compensación será más consultas para cargas más pequeñas. También puede usar proyecciones de propiedades individuales para seleccionar explícitamente solo los datos que necesita de cada entidad, pero no se cargarán entidades en este caso y no se admitirán las actualizaciones.
8.2.3 Solución alternativa para obtener la carga diferida de propiedades
Entity Framework no admite actualmente la carga diferida de propiedades escalares o complejas. Sin embargo, en los casos en los que tenga una tabla que incluya un objeto grande, como un BLOB, puede usar la división de tablas para separar las propiedades grandes en una entidad independiente. Por ejemplo, supongamos que tiene una tabla Product que incluye una columna de foto varbinary. Si no necesita acceder a esta propiedad con frecuencia en las consultas, puede usar la división de tablas para incluir solo las partes de la entidad que normalmente necesita. La entidad que representa la foto del producto solo se cargará cuando lo necesite explícitamente.
Un buen recurso que muestra cómo habilitar la división de tablas es la entrada de blog "División de tablas en Entity Framework" de Gil Fink: <http://blogs.microsoft.co.il/blogs/gilf/archive/2009/10/13/table-splitting-in-entity-framework.aspx>.
9 Otras consideraciones
9.1 Recolección de elementos no utilizados del servidor
Algunos usuarios pueden experimentar contención de recursos que limita el paralelismo que esperan cuando el recolector de elementos no utilizados no está configurado correctamente. Siempre que EF se use en un escenario multiproceso o en cualquier aplicación que se parezca a un sistema del lado servidor, asegúrese de habilitar la recolección de elementos no utilizados del servidor. Esto se hace a través de una configuración sencilla en el archivo de configuración de la aplicación:
<?xmlversion="1.0" encoding="utf-8" ?>
<configuration>
<runtime>
<gcServer enabled="true" />
</runtime>
</configuration>
Esto debe reducir la contención de subprocesos y aumentar el rendimiento hasta un 30 % en escenarios saturados de CPU. En términos generales, siempre debe probar cómo se comporta la aplicación mediante la recolección clásica de elementos no utilizados (que se ajusta mejor para escenarios de interfaz de usuario y cliente), así como la recolección de elementos no utilizados del servidor.
9.2 AutoDetectChanges
Como se mencionó anteriormente, Entity Framework podría mostrar problemas de rendimiento cuando la caché de objetos tiene muchas entidades. Ciertas operaciones, como Add, Remove, Find, Entry y SaveChanges, desencadenan llamadas a DetectChanges que podrían consumir una gran cantidad de CPU en función de la gran cantidad de memoria caché de objetos. El motivo de esto es que la memoria caché de objetos y el administrador de estado de objetos intentan mantenerse lo más sincronizado posible en cada operación realizada en un contexto para que se garantice que los datos generados sean correctos en una amplia variedad de escenarios.
Por lo general, se recomienda dejar habilitada la detección automática de cambios de Entity Framework para toda la vida útil de la aplicación. Si el escenario se ve afectado negativamente por un uso elevado de la CPU y los perfiles indican que el culpable es la llamada a DetectChanges, considere la posibilidad de desactivar temporalmente AutoDetectChanges en la parte confidencial del código:
try
{
context.Configuration.AutoDetectChangesEnabled = false;
var product = context.Products.Find(productId);
...
}
finally
{
context.Configuration.AutoDetectChangesEnabled = true;
}
Antes de desactivar AutoDetectChanges, es bueno entender que esto puede hacer que Entity Framework pierda su capacidad de realizar un seguimiento de cierta información sobre los cambios que se producen en las entidades. Si se controla incorrectamente, esto puede provocar incoherencia de datos en la aplicación. Para obtener más información sobre cómo desactivar AutoDetectChanges, lea <http://blog.oneunicorn.com/2012/03/12/secrets-of-detectchanges-part-3-switching-off-automatic-detectchanges/>.
9.3 Contexto por solicitud
Los contextos de Entity Framework están diseñados para usarse como instancias de corta duración para proporcionar la experiencia de rendimiento más óptima. Se espera que los contextos sean de corta duración y se descarten y, como tal, se han implementado para ser muy ligeros y reutilizar metadatos siempre que sea posible. En escenarios web, es importante tener esto en cuenta y no tener un contexto durante más de la duración de una sola solicitud. Del mismo modo, en escenarios que no son web, el contexto debe descartarse en función de la comprensión de los distintos niveles de almacenamiento en caché en Entity Framework. Por lo general, uno debe evitar tener una instancia de contexto durante toda la vida de la aplicación, así como contextos por subproceso y contextos estáticos.
9.4 Semántica nula de la base de datos
Entity Framework generará de forma predeterminada código SQL que tenga semántica de comparación null de C#. Considere la siguiente consulta de ejemplo:
int? categoryId = 7;
int? supplierId = 8;
decimal? unitPrice = 0;
short? unitsInStock = 100;
short? unitsOnOrder = 20;
short? reorderLevel = null;
var q = from p incontext.Products
where p.Category.CategoryName == "Beverages"
|| (p.CategoryID == categoryId
|| p.SupplierID == supplierId
|| p.UnitPrice == unitPrice
|| p.UnitsInStock == unitsInStock
|| p.UnitsOnOrder == unitsOnOrder
|| p.ReorderLevel == reorderLevel)
select p;
var r = q.ToList();
En este ejemplo, estamos comparando una serie de variables que aceptan valores NULL con propiedades que aceptan valores NULL en la entidad, como SupplierID y UnitPrice. El SQL generado para esta consulta preguntará si el valor del parámetro es el mismo que el valor de columna, o si los valores de parámetro y columna son null. Esto ocultará la forma en que el servidor de bases de datos controla los valores null y proporcionará una experiencia de C# null coherente en diferentes proveedores de bases de datos. Por otro lado, el código generado es un poco complicado y puede que no funcione bien cuando la cantidad de comparaciones en la instrucción where de la consulta crece a un gran número.
Una manera de tratar esta situación es mediante la semántica nula de la base de datos. Tenga en cuenta que esto podría comportarse de forma diferente a la semántica de C# null, ya que ahora Entity Framework generará SQL más sencillo que expone la forma en que el motor de base de datos controla valores null. La semántica null de la base de datos se puede activar por contexto con una sola línea de configuración en la configuración de contexto:
context.Configuration.UseDatabaseNullSemantics = true;
Las consultas de tamaño pequeño a mediano no mostrarán una mejora perceptible del rendimiento al usar la semántica null de la base de datos, pero la diferencia se volverá más notable en las consultas con un gran número de posibles comparaciones null.
En la consulta de ejemplo anterior, la diferencia de rendimiento era inferior al 2 % en una marca microbiana que se ejecuta en un entorno controlado.
9.5 Asincrónico
Entity Framework 6 introdujo compatibilidad con operaciones asincrónicas al ejecutarse en .NET 4.5 o posterior. En la mayor parte, las aplicaciones que tienen contención relacionada con E/S se beneficiarán más del uso de operaciones asincrónicas de consulta y guardado. Si la aplicación no sufre de contención de E/S, el uso de async, en los mejores casos, ejecutará sincrónicamente y devolverá el resultado en la misma cantidad de tiempo que una llamada sincrónica o, en el peor de los casos, simplemente aplazará la ejecución a una tarea asincrónica y agregará tiempo adicional a la finalización de su escenario.
Para obtener información sobre cómo funciona la programación asincrónica que le ayudará a decidir si async mejorará el rendimiento de la aplicación, consulte Programación asincrónica con Async y Await. Para obtener más información sobre el uso de operaciones asincrónicas en Entity Framework, consulte Consulta asincrónica y Guardar.
9.6 NGEN
Entity Framework 6 no se incluye en la instalación predeterminada de .NET Framework. Por lo tanto, los ensamblados de Entity Framework no son NGEN’d de forma predeterminada, lo que significa que todo el código de Entity Framework está sujeto a los mismos costos de JIT que cualquier otro ensamblado MSIL. Esto puede degradar la experiencia F5 mientras desarrolla y también el inicio en frío de la aplicación en los entornos de producción. Para reducir los costos de CPU y memoria de JIT, es aconsejable NGEN las imágenes de Entity Framework según corresponda. Para obtener más información sobre cómo mejorar el rendimiento de inicio de Entity Framework 6 con NGEN, vea Mejorar el rendimiento de inicio con NGen.
9.7 Code First frente a EDMX
Entity Framework causa el problema de falta de coincidencia de impedancia entre la programación orientada a objetos y las bases de datos relacionales al tener una representación en memoria del modelo conceptual (los objetos), el esquema de almacenamiento (la base de datos) y una asignación entre los dos. Estos metadatos se denominan Entity Data Model o EDM para abreviar. A partir de este EDM, Entity Framework derivará las vistas a los datos de ida y vuelta de los objetos en memoria a la base de datos y a la copia de seguridad.
Cuando Entity Framework se usa con un archivo EDMX que especifica formalmente el modelo conceptual, el esquema de almacenamiento y la asignación, la fase de carga del modelo solo tiene que validar que el EDM es correcto (por ejemplo, asegúrese de que no falta ninguna asignación), genere las vistas y, a continuación, valide las vistas y tenga estos metadatos listos para su uso. Solo entonces se puede ejecutar una consulta o guardarse nuevos datos en el almacén de datos.
El enfoque de Code First es, en su centro, un sofisticado generador de Entity Data Model. Entity Framework tiene que generar un EDM a partir del código proporcionado; lo hace mediante el análisis de las clases implicadas en el modelo, la aplicación de convenciones y la configuración del modelo a través de Fluent API. Una vez compilado el EDM, Entity Framework se comporta básicamente de la misma manera que si hubiera estado presente un archivo EDMX en el proyecto. Por lo tanto, la compilación del modelo a partir de Code First agrega una complejidad adicional que se traduce en un tiempo de inicio más lento para Entity Framework en comparación con tener un EDMX. El costo depende completamente del tamaño y la complejidad del modelo que se está compilando.
Al elegir usar EDMX frente a Code First, es importante saber que la flexibilidad introducida por Code First aumenta el costo de crear el modelo por primera vez. Si la aplicación puede soportar el costo de esta carga por primera vez, normalmente Code First será la manera preferida de ir.
10 Investigación del rendimiento
10.1 Uso del generador de perfiles de Visual Studio
Si tiene problemas de rendimiento con Entity Framework, puede usar un generador de perfiles como el integrado en Visual Studio para ver dónde la aplicación pasa su tiempo. Esta es la herramienta que usamos para generar los gráficos circulares en la entrada de blog “Exploración del rendimiento de ADO.NET Entity Framework: Parte 1” ( <https://learn.microsoft.com/archive/blogs/adonet/exploring-the-performance-of-the-ado-net-entity-framework-part-1>) que muestran dónde Entity Framework pasa su tiempo durante consultas inactivas y cálidas.
La entrada de blog "Generación de perfiles de Entity Framework con Visual Studio 2010 Profiler" escrita por el equipo de asesoramiento de clientes de datos y modelado muestra un ejemplo real de cómo usaron el generador de perfiles para investigar un problema de rendimiento. <https://learn.microsoft.com/archive/blogs/dmcat/profiling-entity-framework-using-the-visual-studio-2010-profiler>. Esta publicación se escribió para una aplicación windows. Si necesita generar perfiles de una aplicación web, las herramientas Windows Performance Recorder (WPR) y Windows Performance Analyzer (WPA) pueden funcionar mejor que trabajar desde Visual Studio. WPR y WPA son parte del kit de herramientas de rendimiento de Windows que se incluye con el kit de implementación y evaluación de Windows.
10.2 Generación de perfiles de aplicación/base de datos
Las herramientas como el generador de perfiles integrado en Visual Studio le indican dónde pasa tiempo la aplicación. Otro tipo de generador de perfiles está disponible que realiza análisis dinámicos de la aplicación en ejecución, ya sea en producción o preproducción en función de las necesidades, y busca problemas comunes y antipatrones de acceso a bases de datos.
Dos generadores de perfiles disponibles comercialmente son Entity Framework Profiler ( <http://efprof.com>) y ORMProfiler ( <http://ormprofiler.com>).
Si la aplicación es una aplicación de MVC mediante Code First, puede usar el MiniProfiler de StackExchange. Scott Hanselman describe esta herramienta en su blog en: <http://www.hanselman.com/blog/NuGetPackageOfTheWeek9ASPNETMiniProfilerFromStackExchangeRocksYourWorld.aspx>.
Para obtener más información sobre cómo generar perfiles de la actividad de base de datos de la aplicación, vea el artículo de MSDN Magazine de Julie Lerman titulado Actividad de base de datos de generación de perfiles en Entity Framework.
10.3 Registrador de base de datos
Si usa Entity Framework 6, considere también la posibilidad de usar la funcionalidad de registro integrada. Se puede indicar a la propiedad base de datos del contexto que registre su actividad a través de una configuración sencilla de una línea:
using (var context = newQueryComparison.DbC.NorthwindEntities())
{
context.Database.Log = Console.WriteLine;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
En este ejemplo, la actividad de base de datos se registrará en la consola, pero la propiedad Log se puede configurar para llamar a cualquier acción<cadena> delegado.
Si desea habilitar el registro de base de datos sin volver a compilar y usa Entity Framework 6.1 o posterior, puede hacerlo agregando un interceptor en el archivo web.config o app.config de la aplicación.
<interceptors>
<interceptor type="System.Data.Entity.Infrastructure.Interception.DatabaseLogger, EntityFramework">
<parameters>
<parameter value="C:\Path\To\My\LogOutput.txt"/>
</parameters>
</interceptor>
</interceptors>
Para obtener más información sobre cómo agregar el registro sin volver a compilar, vaya a <http://blog.oneunicorn.com/2014/02/09/ef-6-1-turning-on-logging-without-recompiling/>.
11 Apéndice
11.1 A. Entorno de prueba
Este entorno usa una configuración de 2 máquinas con la base de datos en una máquina independiente de la aplicación cliente. Las máquinas están en el mismo bastidor, por lo que la latencia de red es relativamente baja, pero más realista que un entorno de una sola máquina.
11.1.1 Servidor de aplicaciones
11.1.1.1 Entorno de software
- Entorno de software de Entity Framework 4
- Nombre del sistema operativo: Windows Server 2008 R2 Enterprise SP1.
- Visual Studio 2010: Ultimate.
- Visual Studio 2010 SP1 (solo para algunas comparaciones).
- Entity Framework 5 y 6 Software Environment
- Nombre del sistema operativo: Windows 8.1 Enterprise
- Visual Studio 2013: Ultimate.
11.1.1.2 Entorno de Hardware
- Procesador dual: Intel(R) Xeon(R) CPU L5520 W3530 @ 2,27GHz, 2261 Mhz8 GHz, 4 núcleos, 84 procesadores lógicos.
- 2412 GB de RamRAM.
- 136 GB SCSI250GB unidad SATA 7200 rpm de 3 GB/s dividida en 4 particiones.
11.1.2 Servidor de base de datos
11.1.2.1 Entorno de Software
- Nombre del sistema operativo: Windows Server 2008 R28.1 Enterprise SP1.
- SQL Server 2008 R22012.
11.1.2.2 Entorno de Hardware
- Procesador dual: Intel(R) Xeon(R) CPU L5520 @ 2.27GHz, 2261 MhzES-1620 0 @ 3.60GHz, 4 núcleos, 8 procesadores lógicos.
- RamRAM de 824 GB.
- 465 GB ATA500GB unidad SATA 7200 rpm de 6 GB/s dividida en 4 particiones.
11.2 B. Pruebas de comparación de rendimiento de consultas
El modelo Northwind se usó para ejecutar estas pruebas. Se generó a partir de la base de datos mediante el diseñador de Entity Framework. A continuación, se usó el código siguiente para comparar el rendimiento de las opciones de ejecución de consultas:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity.Infrastructure;
using System.Data.EntityClient;
using System.Data.Objects;
using System.Linq;
namespace QueryComparison
{
public partial class NorthwindEntities : ObjectContext
{
private static readonly Func<NorthwindEntities, string, IQueryable<Product>> productsForCategoryCQ = CompiledQuery.Compile(
(NorthwindEntities context, string categoryName) =>
context.Products.Where(p => p.Category.CategoryName == categoryName)
);
public IQueryable<Product> InvokeProductsForCategoryCQ(string categoryName)
{
return productsForCategoryCQ(this, categoryName);
}
}
public class QueryTypePerfComparison
{
private static string entityConnectionStr = @"metadata=res://*/Northwind.csdl|res://*/Northwind.ssdl|res://*/Northwind.msl;provider=System.Data.SqlClient;provider connection string='data source=.;initial catalog=Northwind;integrated security=True;multipleactiveresultsets=True;App=EntityFramework'";
public void LINQIncludingContextCreation()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTracking()
{
using (NorthwindEntities context = new NorthwindEntities())
{
context.Products.MergeOption = MergeOption.NoTracking;
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void CompiledQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
var q = context.InvokeProductsForCategoryCQ("Beverages");
q.ToList();
}
}
public void ObjectQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectQuery<Product> products = context.Products.Where("it.Category.CategoryName = 'Beverages'");
products.ToList();
}
}
public void EntityCommand()
{
using (EntityConnection eConn = new EntityConnection(entityConnectionStr))
{
eConn.Open();
EntityCommand cmd = eConn.CreateCommand();
cmd.CommandText = "Select p From NorthwindEntities.Products As p Where p.Category.CategoryName = 'Beverages'";
using (EntityDataReader reader = cmd.ExecuteReader(CommandBehavior.SequentialAccess))
{
List<Product> productsList = new List<Product>();
while (reader.Read())
{
DbDataRecord record = (DbDataRecord)reader.GetValue(0);
// 'materialize' the product by accessing each field and value. Because we are materializing products, we won't have any nested data readers or records.
int fieldCount = record.FieldCount;
// Treat all products as Product, even if they are the subtype DiscontinuedProduct.
Product product = new Product();
product.ProductID = record.GetInt32(0);
product.ProductName = record.GetString(1);
product.SupplierID = record.GetInt32(2);
product.CategoryID = record.GetInt32(3);
product.QuantityPerUnit = record.GetString(4);
product.UnitPrice = record.GetDecimal(5);
product.UnitsInStock = record.GetInt16(6);
product.UnitsOnOrder = record.GetInt16(7);
product.ReorderLevel = record.GetInt16(8);
product.Discontinued = record.GetBoolean(9);
productsList.Add(product);
}
}
}
}
public void ExecuteStoreQuery()
{
using (NorthwindEntities context = new NorthwindEntities())
{
ObjectResult<Product> beverages = context.ExecuteStoreQuery<Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Database.SqlQuery\<QueryComparison.DbC.Product>(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void ExecuteStoreQueryDbSet()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var beverages = context.Products.SqlQuery(
@" SELECT P.ProductID, P.ProductName, P.SupplierID, P.CategoryID, P.QuantityPerUnit, P.UnitPrice, P.UnitsInStock, P.UnitsOnOrder, P.ReorderLevel, P.Discontinued
FROM Products AS P INNER JOIN Categories AS C ON P.CategoryID = C.CategoryID
WHERE (C.CategoryName = 'Beverages')"
);
beverages.ToList();
}
}
public void LINQIncludingContextCreationDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
public void LINQNoTrackingDbContext()
{
using (var context = new QueryComparison.DbC.NorthwindEntities())
{
var q = context.Products.AsNoTracking().Where(p => p.Category.CategoryName == "Beverages");
q.ToList();
}
}
}
}
11.3 C. Modelo Navision
La base de datos Navision es una base de datos grande que se usa para demostrar Microsoft Dynamics – NAV. El modelo conceptual generado contiene 1005 conjuntos de entidades y 4227 conjuntos de asociaciones. El modelo que se usa en la prueba no es “plano”, no se ha agregado ninguna herencia a ella.
11.3.1 Consultas usadas para las pruebas de Navision
La lista de consultas usada con el modelo de Navision contiene 3 categorías de consultas Entity SQL:
11.3.1.1 Búsqueda
Una consulta de búsqueda simple sin agregaciones
- Recuento: 16232
- Ejemplo:
<Query complexity="Lookup">
<CommandText>Select value distinct top(4) e.Idle_Time From NavisionFKContext.Session as e</CommandText>
</Query>
11.3.1.2 SingleAggregating
Una consulta de BI normal con varias agregaciones, pero no subtotales (consulta única)
- Recuento: 2313
- Ejemplo:
<Query complexity="SingleAggregating">
<CommandText>NavisionFK.MDF_SessionLogin_Time_Max()</CommandText>
</Query>
Donde MDF_SessionLogin_Time_Max() se define en el modelo como:
<Function Name="MDF_SessionLogin_Time_Max" ReturnType="Collection(DateTime)">
<DefiningExpression>SELECT VALUE Edm.Min(E.Login_Time) FROM NavisionFKContext.Session as E</DefiningExpression>
</Function>
11.3.1.3 AggregatingSubtotals
Una consulta de BI con agregaciones y subtotales (a través de union all)
- Recuento: 178
- Ejemplo:
<Query complexity="AggregatingSubtotals">
<CommandText>
using NavisionFK;
function AmountConsumed(entities Collection([CRONUS_International_Ltd__Zone])) as
(
Edm.Sum(select value N.Block_Movement FROM entities as E, E.CRONUS_International_Ltd__Bin as N)
)
function AmountConsumed(P1 Edm.Int32) as
(
AmountConsumed(select value e from NavisionFKContext.CRONUS_International_Ltd__Zone as e where e.Zone_Ranking = P1)
)
----------------------------------------------------------------------------------------------------------------------
(
select top(10) Zone_Ranking, Cross_Dock_Bin_Zone, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking, E.Cross_Dock_Bin_Zone
)
union all
(
select top(10) Zone_Ranking, Cast(null as Edm.Byte) as P2, AmountConsumed(GroupPartition(E))
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed
group by E.Zone_Ranking
)
union all
{
Row(Cast(null as Edm.Int32) as P1, Cast(null as Edm.Byte) as P2, AmountConsumed(select value E
from NavisionFKContext.CRONUS_International_Ltd__Zone as E
where AmountConsumed(E.Zone_Ranking) > @MinAmountConsumed))
}</CommandText>
<Parameters>
<Parameter Name="MinAmountConsumed" DbType="Int32" Value="10000" />
</Parameters>
</Query>
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de