Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Microsoft Fabric es un servicio de análisis integrado que acelera el tiempo para obtener información sobre almacenes de datos y sistemas de macrodatos. La visualización de datos en cuadernos es una característica clave que permite obtener información sobre los datos, lo que ayuda a los usuarios a identificar patrones, tendencias y valores atípicos con facilidad.
Al trabajar con Apache Spark en Fabric, tiene opciones integradas para visualizar datos, incluidas las características del gráfico de cuadernos de Fabric y el acceso a bibliotecas populares de código abierto.
Los cuadernos de Fabric también permiten convertir los resultados tabulares en gráficos personalizados sin escribir ningún código, lo que permite una experiencia de exploración de datos más intuitiva y sin problemas.
Comando de visualización integrada: función display()
La función de visualización integrada de Fabric permite transformar DataFrames de Apache Spark, DataFrames de Pandas y resultados de consultas SQL en visualizaciones de datos enriquecidas e interactivas.
Con la función de visualización , puede representar pySpark y Scala Spark DataFrames o conjuntos de datos distribuidos resistentes (RDD) como tablas o gráficos dinámicos.
Puede especificar el recuento de filas de la trama de datos que se va a representar. El valor predeterminado es 1000. El widget de salida visualizar de Notebook permite visualizar y perfilar 10000 filas de un único DataFrame como máximo.

Puede usar la función de filtro en la barra de herramientas global para aplicar reglas personalizadas a los datos. La condición de filtro se aplica a una columna especificada y los resultados se reflejan en las vistas de tabla y gráfico.

La salida de la instrucción SQL adopta el mismo widget de salida con display() de forma predeterminada.
Vista de tabla de trama de datos enriquecida
Soporte de selección libre en la vista de tabla
De forma predeterminada, la vista de tabla se representa al usar el comando display() en un cuaderno de Fabric. La vista previa de tramas de datos enriquecidas ofrece una función de selección gratuita intuitiva, diseñada para mejorar la experiencia de análisis de datos al habilitar opciones de selección flexibles e interactivas. Esta característica permite a los usuarios navegar y explorar de forma eficaz tramas de datos con facilidad.
Selección de columna
- columna única: haga clic en el encabezado de columna para seleccionar toda la columna.
- Varias columnas: Después de seleccionar una sola columna, mantenga presionada la tecla "Mayús" y luego haga clic en otro encabezado de columna para seleccionar varias columnas.
Selección de fila
- fila única: haga clic en un encabezado de fila para seleccionar toda la fila.
- Varias filas: Después de seleccionar una sola fila, mantenga presionada la tecla "Mayús", y luego haga clic en el encabezado de otra fila para seleccionar varias filas.
vista previa del contenido de la celda: obtenga una vista previa del contenido de celdas individuales para obtener un vistazo rápido y detallado a los datos sin necesidad de escribir código adicional.
resumen de columnas: obtenga un resumen de cada columna, incluida la distribución de datos y las estadísticas clave, para comprender rápidamente las características de los datos.
selección de área libre: seleccione cualquier segmento continuo de la tabla para obtener información general de las celdas seleccionadas totales y los valores numéricos del área seleccionada.
Copiar Contenido Seleccionado: En todos los casos de selección, puede copiar rápidamente el contenido seleccionado con el atajo de teclado "Ctrl + C". Los datos seleccionados se copian en formato CSV, lo que facilita el procesamiento en otras aplicaciones.

Compatibilidad con la generación de perfiles de datos en el panel de inspección

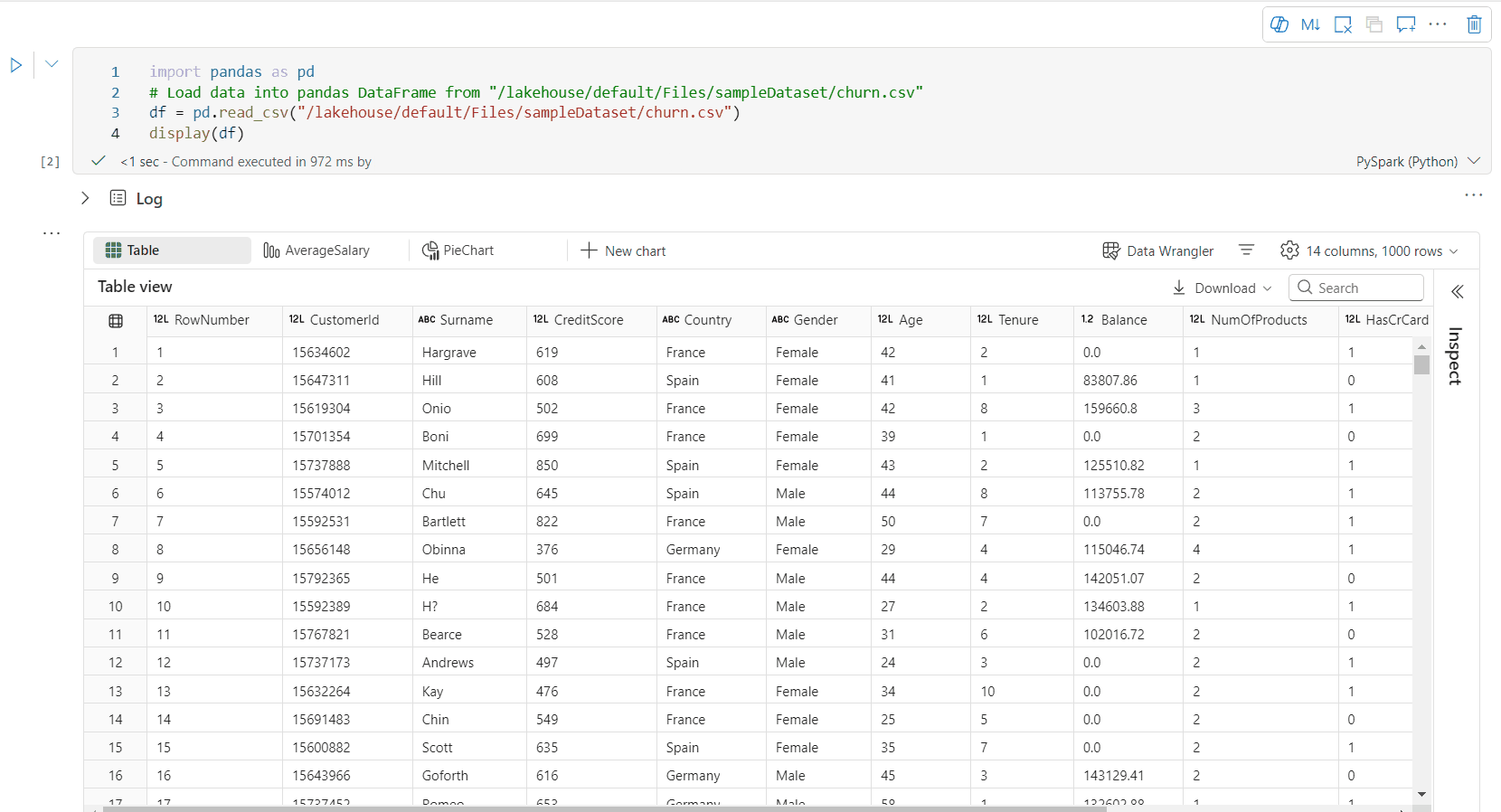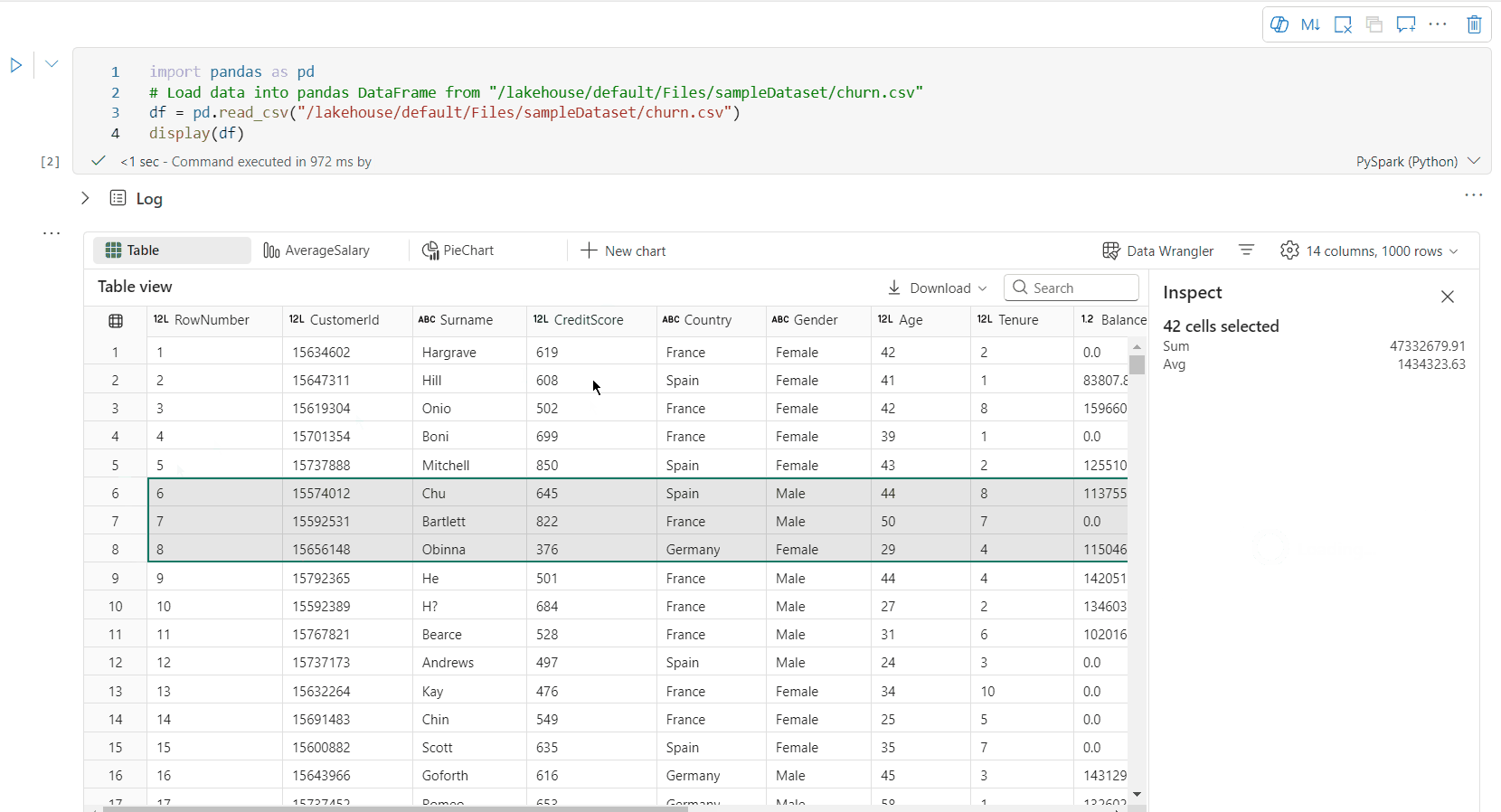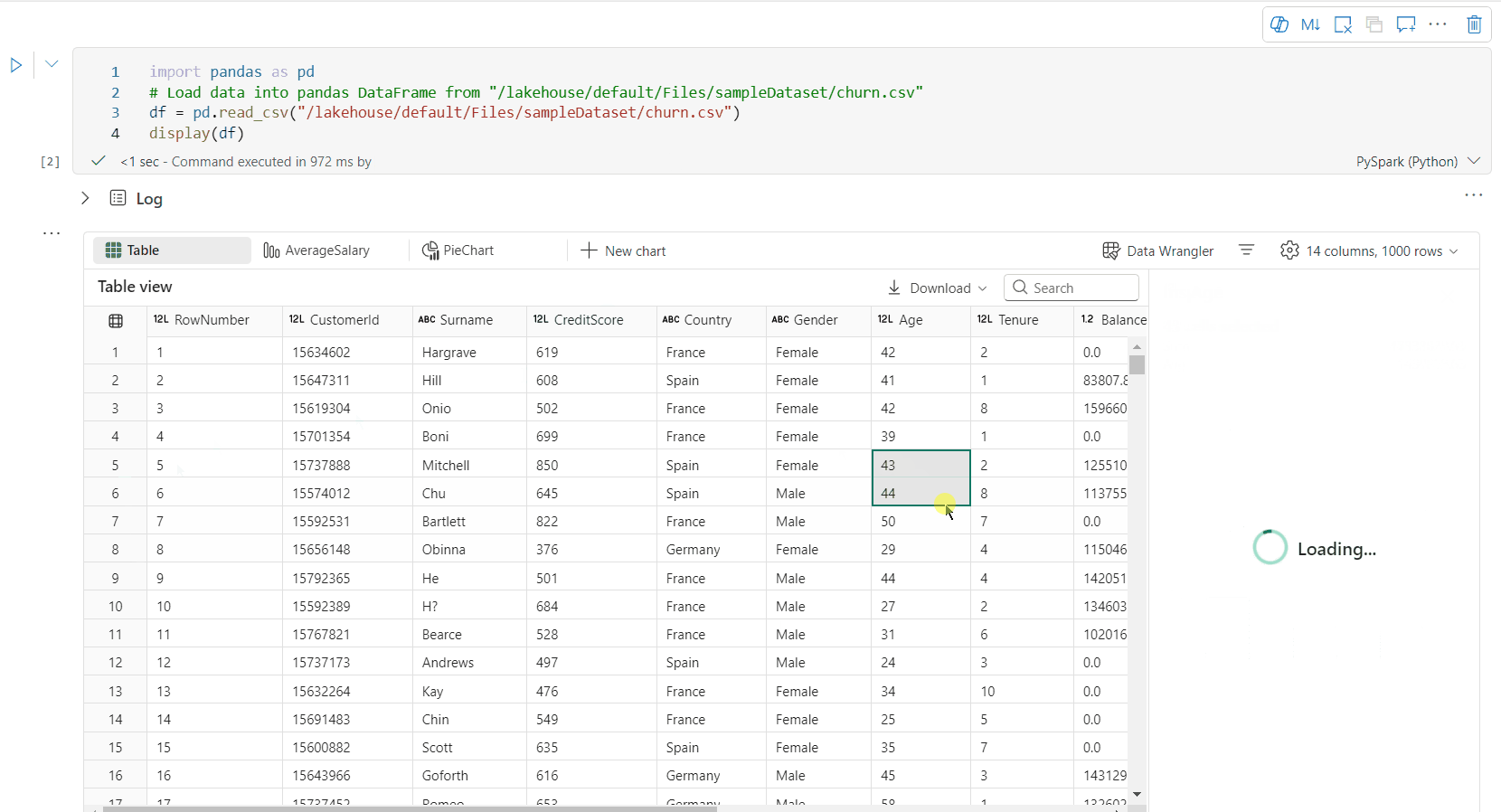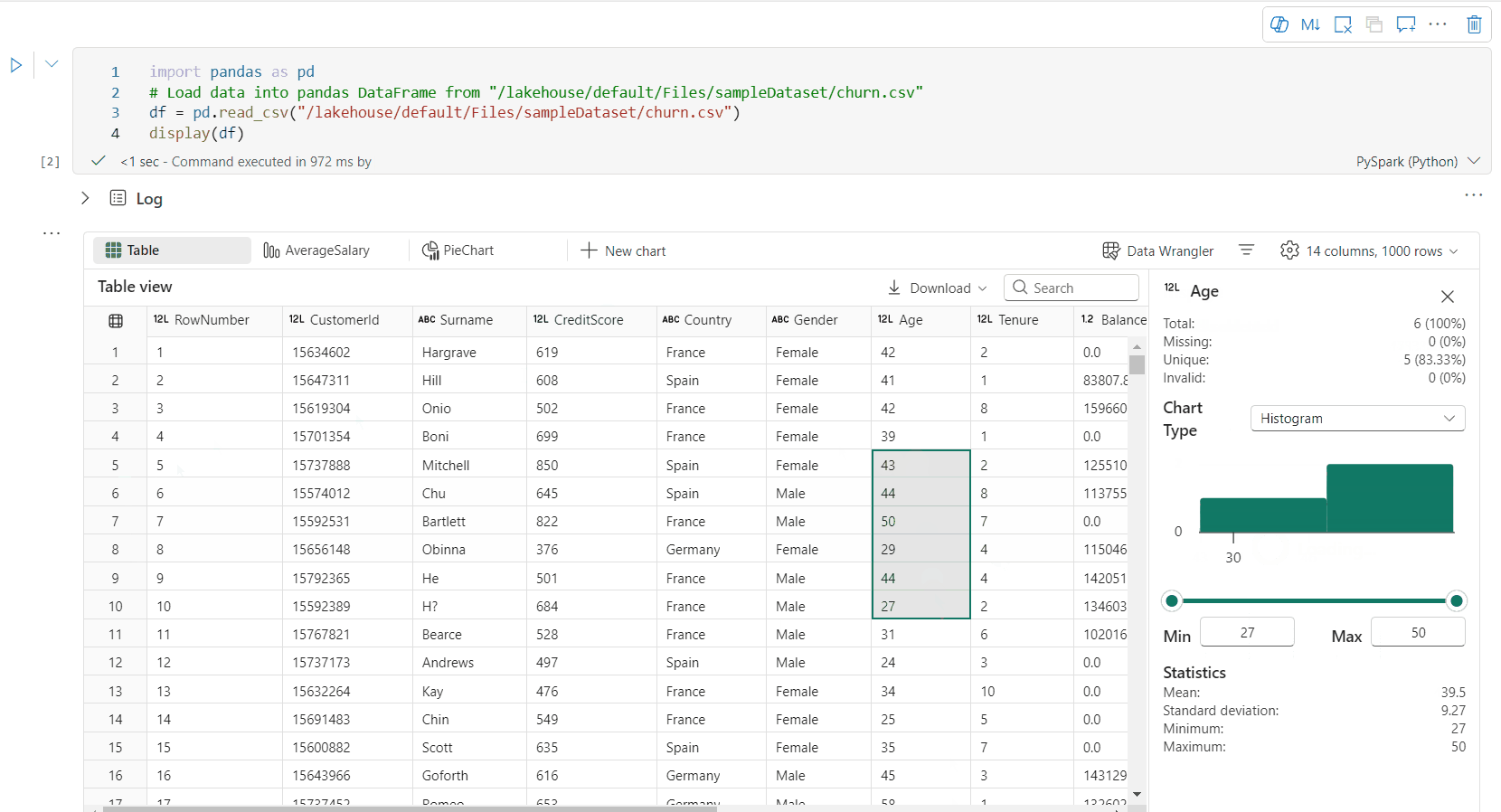
Para generar perfiles del DataFrame, haga clic en el botón Inspeccionar. Proporciona la distribución de datos resumida y muestra las estadísticas de cada columna.
Cada tarjeta del panel lateral "Inspeccionar" se asigna a una columna de DataFrame. Para ver más detalles, haga clic en la tarjeta o seleccione una columna de la tabla.
Para ver los detalles de la celda, haga clic en la celda de la tabla. Esta característica es útil cuando la trama de datos contiene un tipo de cadena largo de contenido.
Vista de gráfico de tramas de datos enriquecidas mejorada
La vista de gráfico mejorada en el comando display() ofrece una manera más intuitiva y dinámica de visualizar los datos.
Mejoras clave:
Compatibilidad con varios gráficos: agregue hasta cinco gráficos dentro de un único widget de salida display() seleccionando Nuevo gráfico, lo que permite comparaciones sencillas entre distintas columnas.
Recomendaciones de gráficos inteligentes: obtenga una lista de gráficos sugeridos en función de la trama de datos. Elija editar una visualización recomendada o crear un gráfico personalizado desde cero.

Personalización flexible: personalice las visualizaciones con configuraciones ajustables que se adapten en función del tipo de gráfico seleccionado.
Categoría Configuración básica Descripción Tipo de gráfico La función display admite una amplia gama de tipos de gráficos, como gráficos de barras, gráficos de dispersión, gráficos de líneas, tablas dinámicas y muchos más. Título Título Título del gráfico. Título Subtítulo Subtítulo del gráfico con más descripciones. Datos Eje X Especifique la clave del gráfico. Datos Eje Y Especifique los valores del gráfico. Leyenda Mostrar leyenda Habilite o deshabilite la leyenda. Leyenda Posición Personalice la posición de la leyenda. Otros Grupo de series Use esta configuración para determinar los grupos de la agregación. Otros Agregación Use este método para agregar datos en la visualización. Otros Apilado Configure el estilo de visualización del resultado. Otros Valores faltantes y valores NULL Configurar cómo se muestran los valores del gráfico que están ausentes o son NULL. Nota:
Además, puede especificar el número de filas mostradas, con una configuración predeterminada de 1000. El widget de visualización de salida del cuaderno admite la visualización y el perfilado de hasta 10 000 filas de un DataFrame. Seleccione Agregación de todos los resultados y después Aplicar para aplicar la generación del gráfico al dataframe completo. Un trabajo de Spark se desencadena cuando cambia la configuración del gráfico. El cálculo puede tardar varios minutos en completarse y representar el gráfico.
Categoría Configuración avanzada Descripción Color Tema Defina el conjunto de colores del tema del gráfico. Eje X Etiqueta Especifique una etiqueta en el eje X. Eje X Escala Especifique la función de escala del eje X. Eje X Intervalo Especifique el eje X del intervalo de valores. Eje Y Etiqueta Especifique una etiqueta en el eje Y. Eje Y Escala Especifique la función de escala del eje Y. Eje Y Intervalo Especifique el eje Y del intervalo de valores. Pantalla Mostrar etiquetas Muestre u oculte las etiquetas de resultados en el gráfico. Los cambios de las configuraciones surten efecto inmediatamente y todas las configuraciones se guardan automáticamente en el contenido del cuaderno.

Puede cambiar fácilmente el nombre, duplicar, eliminar o mover gráficos en el menú de pestañas del gráfico. También puede arrastrar y colocar pestañas para reordenarlas. La primera pestaña se mostrará como predeterminada cuando se abra el cuaderno.
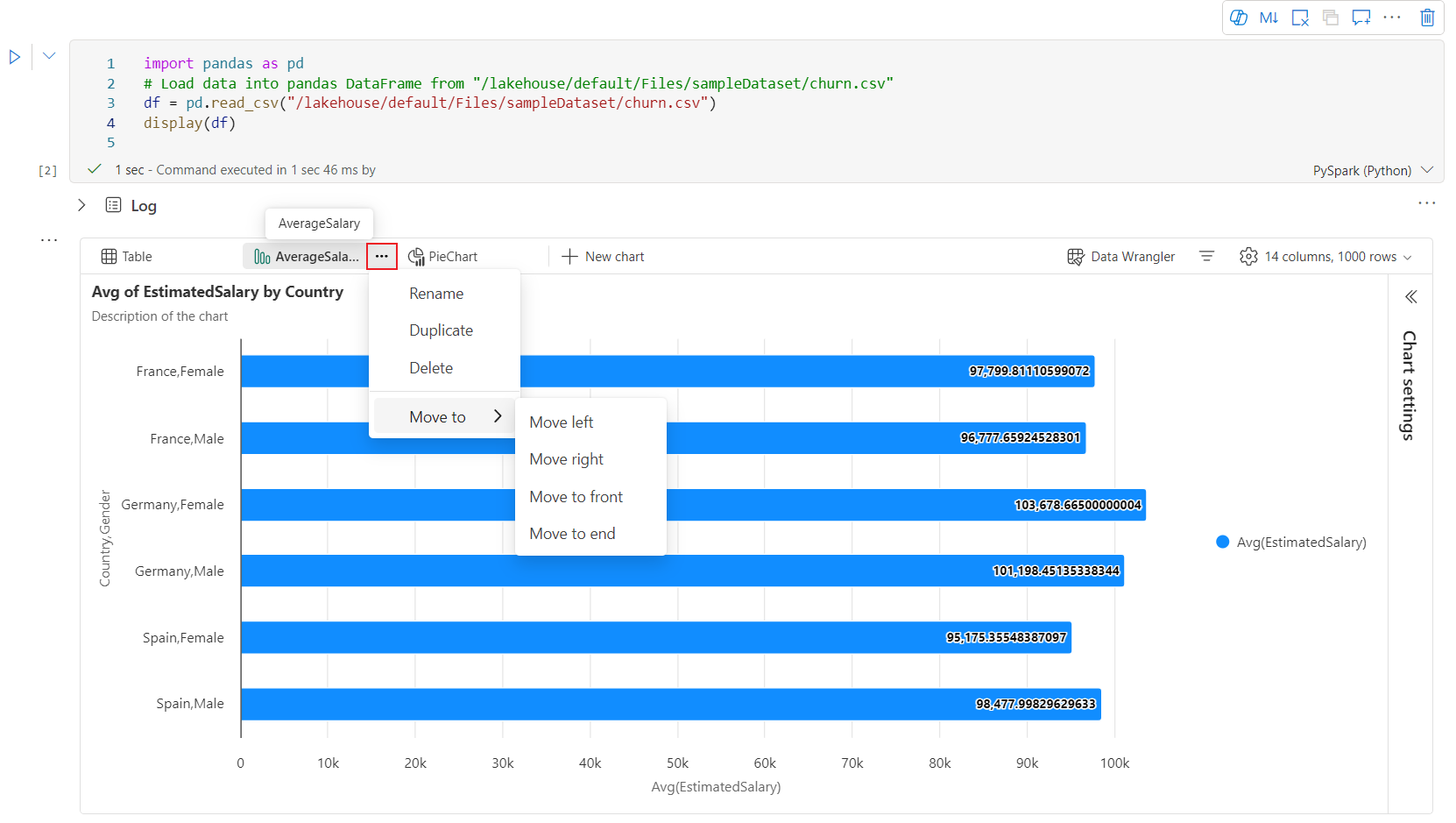
Una barra de herramientas interactiva está disponible en la nueva experiencia de gráfico cuando el usuario mantiene el puntero sobre un gráfico. Soporta operaciones como acercar, alejar, seleccionar para acercar, restablecer, desplazamiento, edición de anotaciones, etc.

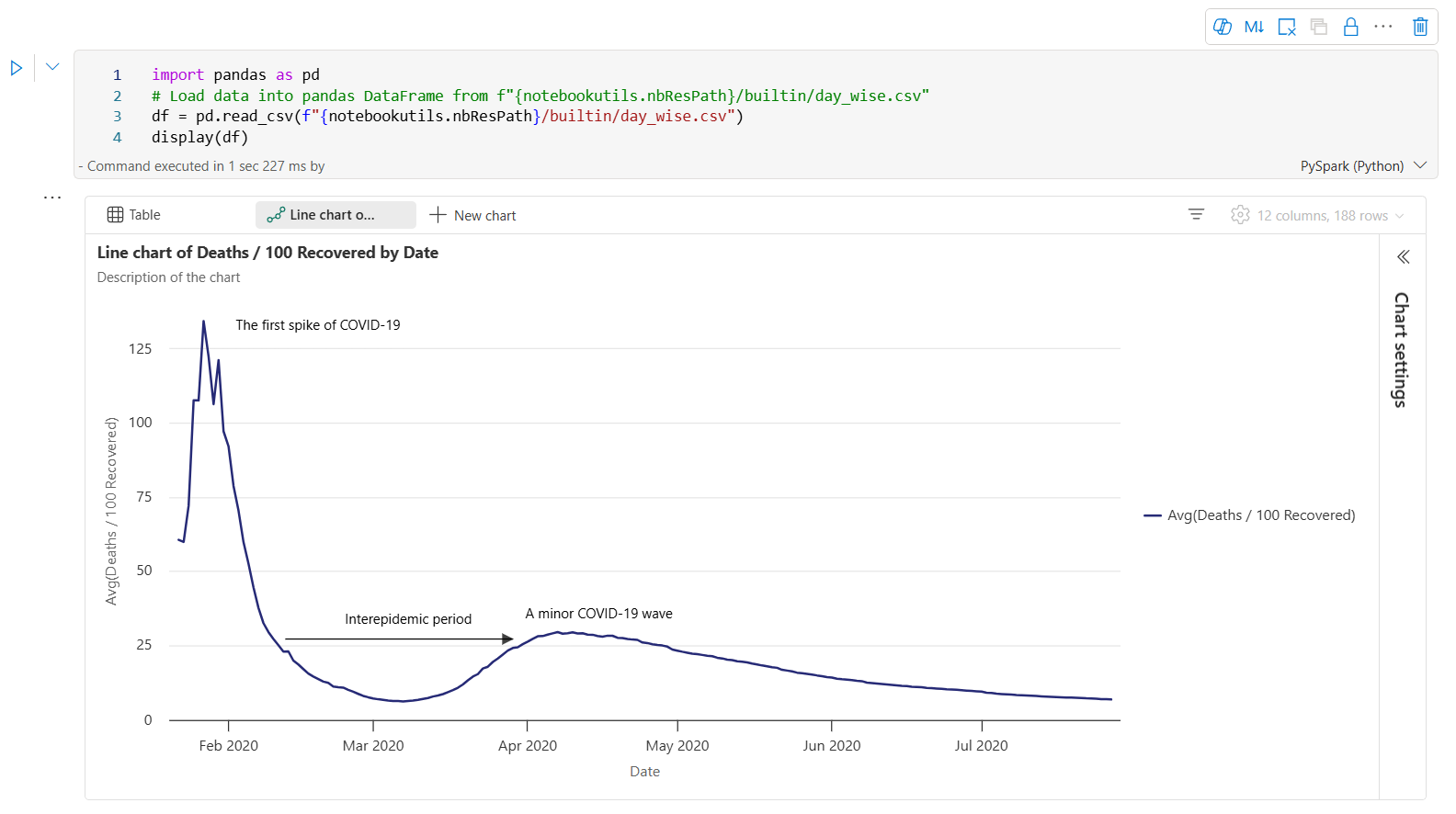
Este es un ejemplo de anotación de gráfico.




Vista de resumen de display()
Use display(df, summary = true) para consultar el resumen de estadísticas de un determinado DataFrame de Apache Spark. El resumen incluye el nombre de la columna, el tipo de columna, los valores únicos y los valores que faltan para cada columna. También puede seleccionar una columna específica para ver el valor mínimo, el valor máximo, el valor medio y la desviación estándar.

opción displayHTML()
Los cuadernos de Fabric admiten gráficos HTML mediante la función displayHTML.
La imagen siguiente es un ejemplo de creación de visualizaciones mediante D3.js.

Para crear esta visualización, ejecute el código siguiente.
displayHTML("""<!DOCTYPE html>
<meta charset="utf-8">
<!-- Load d3.js -->
<script src="https://d3js.org/d3.v4.js"></script>
<!-- Create a div where the graph will take place -->
<div id="my_dataviz"></div>
<script>
// set the dimensions and margins of the graph
var margin = {top: 10, right: 30, bottom: 30, left: 40},
width = 400 - margin.left - margin.right,
height = 400 - margin.top - margin.bottom;
// append the svg object to the body of the page
var svg = d3.select("#my_dataviz")
.append("svg")
.attr("width", width + margin.left + margin.right)
.attr("height", height + margin.top + margin.bottom)
.append("g")
.attr("transform",
"translate(" + margin.left + "," + margin.top + ")");
// Create Data
var data = [12,19,11,13,12,22,13,4,15,16,18,19,20,12,11,9]
// Compute summary statistics used for the box:
var data_sorted = data.sort(d3.ascending)
var q1 = d3.quantile(data_sorted, .25)
var median = d3.quantile(data_sorted, .5)
var q3 = d3.quantile(data_sorted, .75)
var interQuantileRange = q3 - q1
var min = q1 - 1.5 * interQuantileRange
var max = q1 + 1.5 * interQuantileRange
// Show the Y scale
var y = d3.scaleLinear()
.domain([0,24])
.range([height, 0]);
svg.call(d3.axisLeft(y))
// a few features for the box
var center = 200
var width = 100
// Show the main vertical line
svg
.append("line")
.attr("x1", center)
.attr("x2", center)
.attr("y1", y(min) )
.attr("y2", y(max) )
.attr("stroke", "black")
// Show the box
svg
.append("rect")
.attr("x", center - width/2)
.attr("y", y(q3) )
.attr("height", (y(q1)-y(q3)) )
.attr("width", width )
.attr("stroke", "black")
.style("fill", "#69b3a2")
// show median, min and max horizontal lines
svg
.selectAll("toto")
.data([min, median, max])
.enter()
.append("line")
.attr("x1", center-width/2)
.attr("x2", center+width/2)
.attr("y1", function(d){ return(y(d))} )
.attr("y2", function(d){ return(y(d))} )
.attr("stroke", "black")
</script>
"""
)
Inserción de un informe de Power BI en un cuaderno
Importante
Esta característica se encuentra en versión preliminar.
El paquete de Python Powerbiclient ahora se admite de forma nativa en los cuadernos de Fabric. No es necesario definir ninguna configuración adicional (como el proceso de autenticación) en el entorno de ejecución de Spark 3.4 de los cuadernos de Fabric. Solo tiene que importar powerbiclient y continuar con la exploración. Para obtener más información sobre cómo usar el paquete powerbiclient, consulte la documentación de powerbiclient.
Powerbiclient admite las siguientes características clave.
Representación de un informe de Power BI existente
Puede insertar e interactuar fácilmente con informes de Power BI en los cuadernos con solo unas pocas líneas de código.
La imagen siguiente es un ejemplo de representación del informe de Power BI existente.

Ejecute el código siguiente para representar un informe de Power BI existente.
from powerbiclient import Report
report_id="Your report id"
report = Report(group_id=None, report_id=report_id)
report
Creación de objetos visuales de informe a partir de un DataFrame de Spark
Puede usar un DataFrame de Spark en el cuaderno para generar rápidamente visualizaciones con información. También puede seleccionar Guardar en el informe insertado para crear un elemento de informe en un área de trabajo de destino.
La imagen siguiente es un ejemplo de un elemento QuickVisualize() de un DataFrame de Spark.

Ejecute el código siguiente para representar un informe de un DataFrame de Spark.
# Create a spark dataframe from a Lakehouse parquet table
sdf = spark.sql("SELECT * FROM testlakehouse.table LIMIT 1000")
# Create a Power BI report object from spark data frame
from powerbiclient import QuickVisualize, get_dataset_config
PBI_visualize = QuickVisualize(get_dataset_config(sdf))
# Render new report
PBI_visualize
Creación de objetos visuales de informe a partir de un DataFrame de Pandas
También puede crear informes a partir de un DataFrame de Pandas en un cuaderno.
La imagen siguiente es un ejemplo de un elemento QuickVisualize() de un DataFrame de Pandas.

Ejecute el código siguiente para representar un informe de un DataFrame de Spark.
import pandas as pd
# Create a pandas dataframe from a URL
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv")
# Create a pandas dataframe from a Lakehouse csv file
from powerbiclient import QuickVisualize, get_dataset_config
# Create a Power BI report object from your data
PBI_visualize = QuickVisualize(get_dataset_config(df))
# Render new report
PBI_visualize
Bibliotecas populares
Cuando se trata de la visualización de datos, Python ofrece varias bibliotecas de gráficos equipadas con varias características diferentes. De forma predeterminada, cada grupo de Apache Spark de Fabric contiene un conjunto de populares bibliotecas de código abierto seleccionadas.
Matplotlib
Puede representar bibliotecas de trazado estándar, como Matplotlib, mediante las funciones de representación integradas para cada biblioteca.
En la imagen siguiente se muestra un ejemplo de cómo crear un gráfico de barras mediante Matplotlib.


Ejecute el código de ejemplo siguiente para dibujar este gráfico de barras.
# Bar chart
import matplotlib.pyplot as plt
x1 = [1, 3, 4, 5, 6, 7, 9]
y1 = [4, 7, 2, 4, 7, 8, 3]
x2 = [2, 4, 6, 8, 10]
y2 = [5, 6, 2, 6, 2]
plt.bar(x1, y1, label="Blue Bar", color='b')
plt.bar(x2, y2, label="Green Bar", color='g')
plt.plot()
plt.xlabel("bar number")
plt.ylabel("bar height")
plt.title("Bar Chart Example")
plt.legend()
plt.show()
Efecto Bokeh
Puede representar bibliotecas HTML o interactivas, como bokeh, mediante displayHTML(df).
La imagen siguiente es un ejemplo del trazado de glifos en un mapa mediante bokeh.

Para dibujar esta imagen, ejecute el siguiente código de ejemplo.
from bokeh.plotting import figure, output_file
from bokeh.tile_providers import get_provider, Vendors
from bokeh.embed import file_html
from bokeh.resources import CDN
from bokeh.models import ColumnDataSource
tile_provider = get_provider(Vendors.CARTODBPOSITRON)
# range bounds supplied in web mercator coordinates
p = figure(x_range=(-9000000,-8000000), y_range=(4000000,5000000),
x_axis_type="mercator", y_axis_type="mercator")
p.add_tile(tile_provider)
# plot datapoints on the map
source = ColumnDataSource(
data=dict(x=[ -8800000, -8500000 , -8800000],
y=[4200000, 4500000, 4900000])
)
p.circle(x="x", y="y", size=15, fill_color="blue", fill_alpha=0.8, source=source)
# create an html document that embeds the Bokeh plot
html = file_html(p, CDN, "my plot1")
# display this html
displayHTML(html)
Plotly
Puede representar bibliotecas HTML o interactivas, como Plotly, mediante displayHTML() .
Para dibujar esta imagen, ejecute el siguiente código de ejemplo.

from urllib.request import urlopen
import json
with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:
counties = json.load(response)
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/fips-unemp-16.csv",
dtype={"fips": str})
import plotly
import plotly.express as px
fig = px.choropleth(df, geojson=counties, locations='fips', color='unemp',
color_continuous_scale="Viridis",
range_color=(0, 12),
scope="usa",
labels={'unemp':'unemployment rate'}
)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
# create an html document that embeds the Plotly plot
h = plotly.offline.plot(fig, output_type='div')
# display this html
displayHTML(h)
Pandas
Puede ver la salida HTML de los DataFrames de Pandas como salida predeterminada. Los cuadernos de Fabric muestran automáticamente el contenido HTML con estilo.

import pandas as pd
import numpy as np
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df