Tutorial: creación, evaluación y puntuación de un modelo de detección de errores de máquina
En este tutorial se muestra un ejemplo completo de un flujo de trabajo de ciencia de datos de Synapse en Microsoft Fabric. En el escenario se usa el aprendizaje automático para tener un enfoque más sistemático del diagnóstico de errores con el fin de identificar de forma proactiva las incidencias y tomar medidas antes de que se produzca un error real de una máquina. El objetivo es predecir si una máquina experimentaría un error en función de la temperatura del proceso, la velocidad de rotación, etc.
En este tutorial se describen estos pasos:
- Instalación de bibliotecas personalizadas
- Cargar y procesar los datos
- Comprender los datos a través de un análisis exploratorio de los datos
- Usar scikit-learn, LightGBM y MLflow para entrenar modelos de Machine Learning y usar la característica de registro automático de Fabric para realizar un seguimiento de los experimentos
- Puntuar los modelos entrenados con la característica
PREDICTde Fabric, guardar el mejor modelo y cargarlo para las predicciones - Mostrar el rendimiento del modelo cargado con visualizaciones de Power BI
Requisitos previos
Obtenga una suscripción a Microsoft Fabric. También puede registrarse para obtener una evaluación gratuita de Microsoft Fabric.
Inicie sesión en Microsoft Fabric.
Use el conmutador de experiencia en el lado izquierdo de la página principal para cambiar a la experiencia de ciencia de datos de Synapse.
- Si es necesario, cree un almacén de lago de Microsoft Fabric como se describe en Creación de un almacén de lago en Microsoft Fabric.
Seguir en un cuaderno
Puede elegir una de estas opciones para seguir en un cuaderno:
- Abra y ejecute el cuaderno integrado en la experiencia de ciencia de datos
- Cargue su cuaderno desde GitHub a la experiencia de ciencia de datos
Abra el cuaderno integrado
El cuaderno de muestra Machine failure acompaña a este tutorial.
Para abrir el cuaderno de muestra integrado en el tutorial en la experiencia de ciencia de datos de Synapse:
Vaya a la página principal de ciencia de datos de Synapse.
Seleccione Utilizar una muestra.
Seleccione la muestra correspondiente:
- Desde la pestaña predeterminada Flujos de trabajo de un extremo a otro (Python), si la muestra es para un tutorial de Python.
- Desde la pestaña Flujos de trabajo de un extremo a otro (R), si la muestra es para un tutorial de R.
- En la pestaña Tutoriales rápidos, si la muestra es para un tutorial rápido.
Adjunte una instancia de LakeHouse al cuaderno antes de empezar a ejecutar código.
Importación del cuaderno desde GitHub
El cuaderno AISample - Predictive Maintenance acompaña a este tutorial.
Para abrir el cuaderno complementario para este tutorial, siga las instrucciones en Preparación del sistema para los tutoriales de ciencia de datos para importar el cuaderno en el área de trabajo.
Si prefiere copiar y pegar el código de esta página, puede crear un cuaderno nuevo.
Asegúrese de adjuntar una instancia de LakeHouse al cuaderno antes de empezar a ejecutar código.
Paso 1: Instalación de bibliotecas personalizadas
Para desarrollar modelos de Machine Learning o realizar análisis de datos ad hoc, es posible que tenga que instalar rápidamente una biblioteca personalizada para la sesión de Apache Spark. Tiene dos opciones para instalar bibliotecas.
- Use las funcionalidades de instalación insertadas (
%pipo%conda) del cuaderno para instalar una biblioteca solo en el cuaderno actual. - Como alternativa, puede crear un entorno de Fabric, instalar bibliotecas desde orígenes públicos o cargar bibliotecas personalizadas en él y, después, el administrador del área de trabajo puede asociar el entorno como valor predeterminado para el área de trabajo. Todas las bibliotecas del entorno estarán disponibles para su uso en los cuadernos y las definiciones de trabajo de Spark del área de trabajo. Para obtener más información sobre los entornos, consulte Creación, configuración y uso de un entorno en Microsoft Fabric.
En este tutorial, usará %pip install para instalar la biblioteca imblearn en el cuaderno.
Nota:
El kernel de PySpark se reiniciará después de %pip install ejecuciones. Si lo necesita, instale bibliotecas antes de ejecutar cualquier otra celda.
# Use pip to install imblearn
%pip install imblearn
Paso 2: Carga de los datos
El conjunto de datos simula el registro de los parámetros de una máquina de fabricación como una función de tiempo, que es común en la configuración industrial. Consta de 10 000 puntos de datos almacenados como filas con características como columnas. Estas características incluyen lo siguiente:
Un identificador único (UID) comprendido entre 1 y 10 000
Id. del producto, que consta de una letra L (para baja), M (para media) o H (para alta), que indica la variante de calidad del producto y un número de serie específico de variante. Las variantes de baja, media y alta calidad constituyen un 60 %, un 30 % y un 10 % de todos los productos, respectivamente
Temperatura del aire, en grados Kelvin (K)
Temperatura del proceso, en grados Kelvin
Velocidad rotacional, en revoluciones por minuto (RPM)
Par motor, en metros Newton (Nm)
Desgaste de la herramienta, en minutos. Las variantes de calidad H, M y L agregan 5, 3 y 2 minutos de desgaste de herramienta respectivamente a la herramienta usada en el proceso
Una etiqueta de error de la máquina, para indicar si la máquina produjo un error en el punto de datos específico. Este punto de datos específico puede tener cualquiera de los cinco modos de error independientes siguientes:
- Error de desgaste de la herramienta (TWF): la herramienta se reemplaza o produce un error en un tiempo de desgaste de herramienta seleccionado aleatoriamente entre 200 y 240 minutos
- Error de disipación de calor (HDF): la disipación de calor provoca un error de proceso si la diferencia entre la temperatura del aire y la temperatura del proceso es inferior a 8,6 K y la velocidad rotacional de la herramienta está por debajo de 1380 RPM.
- Error de alimentación (PWF): el producto del par motor y la velocidad de rotación (en rad/s) es igual a la potencia necesaria para el proceso. El proceso produce un error si esta potencia baja de 3500 W o supera 9000 W
- Error de sobreesfuerzo (OSF): si el producto del desgaste de la herramienta y el par motor supera los 11 000 Nm mínimos para la variante del producto L (12 000 para M y 13 000 para H), el proceso produce un error debido a sobreesfuerzo
- Errores aleatorios (RNF): cada proceso tiene una posibilidad de error del 0,1 % independientemente de sus parámetros de proceso
Nota:
Si al menos uno de los modos de error anteriores es true, se produce un error en el proceso y la etiqueta "error de la máquina" se establece en 1. El método de aprendizaje automático no puede determinar qué modo de error provocó el error del proceso.
Descarga del conjunto de datos y carga en un almacén de lago de datos
Conéctese al contenedor de Azure Open Datasets y cargue el conjunto de datos de mantenimiento predictivo. El código siguiente descarga una versión disponible públicamente del conjunto de datos y, a continuación, la almacena en un almacén de lago de Fabric:
Importante
Agregue un almacén de lago al cuaderno antes de ejecutarlo. De lo contrario, recibirá un error. Para obtener información sobre cómo agregar un almacén de lago, consulte Conexión de almacenes de lago y cuadernos.
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Después de descargar el conjunto de datos en el almacén de lago, puede cargarlo como DataFrame de Spark:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
En esta tabla se muestra una vista previa de los datos:
| UDI | Product ID | Tipo | Temperatura del aire [K] | Temperatura del proceso [K] | Velocidad de rotación [rpm] | Par motor [Nm] | Desgaste de la herramienta [min] | Destino | Tipo del error |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298,1 | 308,6 | 1 551 | 42,8 | 0 | 0 | No hay ningún error |
| 2 | L47181 | L | 298,2 | 308,7 | 1408 | 46,3 | 3 | 0 | No hay ningún error |
| 3 | L47182 | L | 298,1 | 308,5 | 1498 | 49,4 | 5 | 0 | No hay ningún error |
| 4 | L47183 | L | 298,2 | 308,6 | 1433 | 39,5 | 7 | 0 | No hay ningún error |
| 5 | L47184 | L | 298,2 | 308,7 | 1408 | 40,0 | 9 | 0 | No hay ningún error |
Escritura de un DataFrame de Spark en una tabla delta de almacén de lago
Dé formato a los datos (por ejemplo, reemplace los espacios por un carácter de subrayado) para facilitar las operaciones de Spark en los pasos posteriores:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
En esta tabla se muestra una vista previa de los datos con nombres de columna con nuevo formato:
| UDI | Product_ID | Tipo | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Destino | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298,1 | 308,6 | 1 551 | 42,8 | 0 | 0 | No hay ningún error |
| 2 | L47181 | L | 298,2 | 308,7 | 1408 | 46,3 | 3 | 0 | No hay ningún error |
| 3 | L47182 | L | 298,1 | 308,5 | 1498 | 49,4 | 5 | 0 | No hay ningún error |
| 4 | L47183 | L | 298,2 | 308,6 | 1433 | 39,5 | 7 | 0 | No hay ningún error |
| 5 | L47184 | L | 298,2 | 308,7 | 1408 | 40,0 | 9 | 0 | No hay ningún error |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Paso 3: Preprocesamiento y realización de análisis exploratorios de datos
Convierta el DataFrame de Spark en un DataFrame de Pandas para usar bibliotecas de trazado populares compatibles con Pandas.
Sugerencia
En el caso de los conjuntos de datos grandes, es posible que tenga que cargar una parte del conjunto de datos.
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
Convierta columnas específicas del conjunto de datos en tipos flotantes o enteros según sea necesario, y asigne cadenas ('L', 'M' y 'H') a valores numéricos (0, 1 y 2):
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
Exploración de datos a través de visualizaciones
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()

Como se esperaba, el error (IsFail) tiene correlación con las características seleccionadas (columnas). La matriz de correlación muestra que Air_temperature, Process_temperature, Rotational_speed, Torque y Tool_wear tienen la correlación más alta con la variable IsFail.
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])

Como se muestra en los gráficos trazados, las variables Air_temperature, Process_temperature, Rotational_speed, Torque y Tool_wear no son dispersas. Parecen tener una buena continuidad en el espacio de características. Estos trazados confirman que el entrenamiento de un modelo de Machine Learning en este conjunto de datos es probable que genere resultados fiables que se puedan generalizar en un nuevo conjunto de datos.
Inspección de la variable de destino para el desequilibrio de clases
Cuente el número de muestras de las máquinas con errores y sin errores e inspeccione el equilibrio de datos de cada clase (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()

Los trazados indican que la clase sin error (mostrada como IsFail=0 en el segundo trazado) constituye la mayoría de las muestras. Use una técnica de sobremuestreo para crear un conjunto de datos de entrenamiento más equilibrado:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Sobremuestreo para equilibrar las clases del conjunto de datos de entrenamiento
El análisis anterior mostró que el conjunto de datos está muy desequilibrado. El desequilibrio para a ser un problema porque la clase que es minoría tiene demasiado pocos para que el modelo aprenda eficazmente el límite de decisión.
SMOTE puede resolver el problema. SMOTE es una técnica de sobremuestreo ampliamente utilizada que genera ejemplos sintéticos. Genera ejemplos para la clase que es minoría en función de las distancias euclidianas entre los puntos de datos. Este método difiere del sobremuestreo aleatorio, ya que crea nuevos ejemplos que no solo duplican la clase que es minoría. El método se convierte en una técnica más eficaz para controlar conjuntos de datos desequilibrados.
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
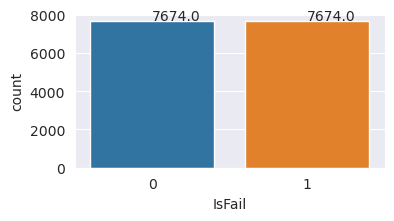
Ha equilibrado correctamente el conjunto de datos. Ahora puede pasar al entrenamiento del modelo.
Paso 4: Entrenamiento y evaluación de los modelos
MLflow registra modelos, entrena y compara varios modelos, y elige el mejor modelo con fines de predicción. Puede usar los tres modelos siguientes para el entrenamiento de modelos:
- Clasificador de bosque aleatorio
- Clasificador de regresión logística
- Clasificador de XGBoost
Entrenamiento de un clasificador de bosque aleatorio
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
A partir de la salida, tanto el conjunto de datos de entrenamiento como el de prueba producen una puntuación F1, precisión y coincidencia de aproximadamente 0,9 mediante el clasificador de bosque aleatorio.
Entrenamiento de un modelo de regresión logística
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Entrenamiento de un clasificador de XGBoost
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Paso 5: Selección del mejor modelo y predicción de salidas
En la sección anterior, ha entrenado tres clasificadores diferentes: bosque aleatorio, regresión logística y XGBoost. Ahora tiene la opción de acceder mediante programación a los resultados o usar la interfaz de usuario (UI).
Para usar la opción de ruta de acceso de la UI, vaya al área de trabajo y filtre los modelos.

Seleccione modelos individuales para obtener más información sobre el rendimiento del modelo.

En este ejemplo se muestra cómo acceder mediante programación a los modelos a través de MLflow:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
Aunque XGBoost produce los mejores resultados en el conjunto de entrenamiento, funciona de forma deficiente en el conjunto de datos de prueba. Este rendimiento deficiente indica un sobreajuste. El clasificador de regresión logística funciona de forma deficiente tanto en conjuntos de datos de entrenamiento como de prueba. En general, el bosque aleatorio alcanza un buen equilibrio entre el rendimiento de entrenamiento y evitar el sobreajuste.
En la sección siguiente, elija el modelo de bosque aleatorio registrado y realice una predicción mediante la característica PREDICT:
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
Con el objeto MLFlowTransformer que ha creado para cargar el modelo para la inferencia, use la API de Transformer para puntuar el modelo con el conjunto de datos de prueba:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
En esta tabla se muestra la salida:
| Tipo | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | predicciones |
|---|---|---|---|---|---|---|
| 0 | 300,6 | 309,7 | 1639,0 | 30,4 | 121,0 | 0 |
| 0 | 303,9 | 313,0 | 1551,0 | 36,8 | 140.0 | 0 |
| 1 | 299,1 | 308,6 | 1491,0 | 38,5 | 166,0 | 0 |
| 0 | 300,9 | 312,1 | 1359,0 | 51,7 | 146,0 | 1 |
| 0 | 303,7 | 312,6 | 1621,0 | 38,8 | 182,0 | 0 |
| 0 | 299,0 | 310,3 | 1868,0 | 24,0 | 221,0 | 1 |
| 2 | 297,8 | 307,5 | 1631,0 | 31.3 | 124,0 | 0 |
| 0 | 297,5 | 308,2 | 1327,0 | 56,5 | 189,0 | 1 |
| 0 | 301,3 | 310,3 | 1460,0 | 41,5 | 197,0 | 0 |
| 2 | 297,6 | 309,0 | 1413,0 | 40,2 | 51,0 | 0 |
| 1 | 300,9 | 309,4 | 1724,0 | 25,6 | 119,0 | 0 |
| 0 | 303,3 | 311,3 | 1389,0 | 53,9 | 39,0 | 0 |
| 0 | 298,4 | 307,9 | 1981,0 | 23,2 | 16.0 | 0 |
| 0 | 299,3 | 308,8 | 1636,0 | 29,9 | 201,0 | 0 |
| 1 | 298,1 | 309,2 | 1460,0 | 45.8 | 80.0 | 0 |
| 0 | 300,0 | 309,5 | 1728,0 | 26,0 | 37,0 | 0 |
| 2 | 299,0 | 308,7 | 1940,0 | 19,9 | 98,0 | 0 |
| 0 | 302,2 | 310,8 | 1383,0 | 46,9 | 45,0 | 0 |
| 0 | 300,2 | 309,2 | 1431,0 | 51,3 | 57,0 | 0 |
| 0 | 299,6 | 310,2 | 1468,0 | 48,0 | 9.0 | 0 |
Guarde los datos en el almacén de lago. A continuación, los datos estarán disponibles para usos posteriores; por ejemplo, un panel de Power BI.
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Paso 6: Visualización de la inteligencia empresarial a través de visualizaciones en Power BI
Mostrar los resultados en un formato sin conexión, con un panel de Power BI.
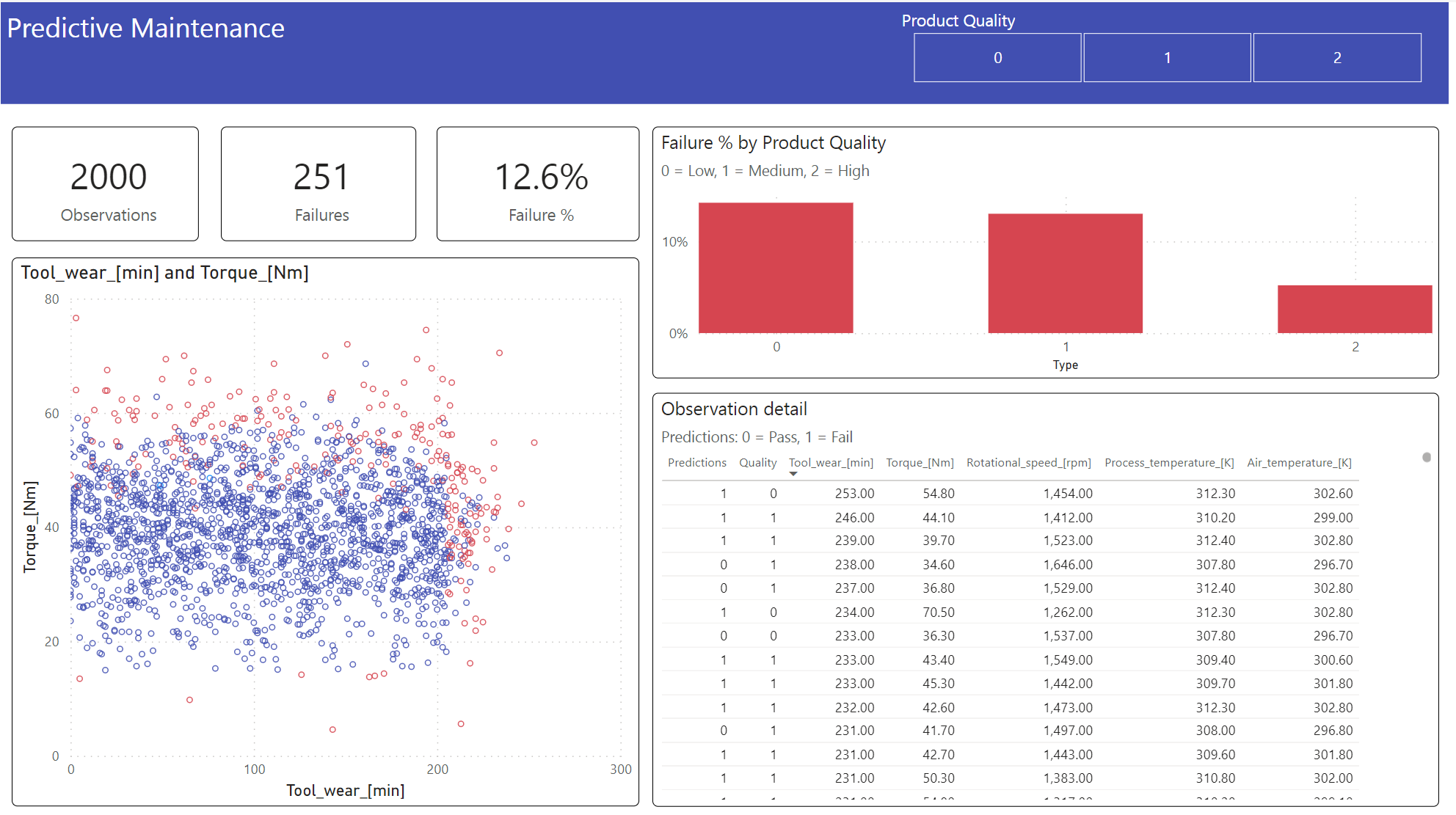
El panel muestra que Tool_wear y Torque crean un límite notable entre los casos con errores y sin error, como se esperaba en el análisis de correlación anterior en el paso 2.