Directrices y patrones de migración de Azure Data Lake Storage
Puede migrar los datos, las cargas de trabajo y las aplicaciones de Azure Data Lake Storage Gen1 a Azure Data Lake Storage Gen2. En este artículo, se explica el enfoque de migración recomendado y se tratan los diferentes patrones de migración y cuándo usar cada uno. Para facilitar la lectura, en este artículo se usa el término Gen1 para hacer referencia a Azure Data Lake Storage Gen1 y el término Gen2 para hacer referencia a Azure Data Lake Storage Gen2.
Nota:
Azure Data Lake Storage Gen1 ahora se ha retirado. Consulte el anuncio de retirada aquí. Ya no se puede acceder a los recursos de Data Lake Storage Gen1.
Azure Data Lake Storage Gen2 se basa en Azure Blob Storage y proporciona un conjunto de funcionalidades dedicadas al análisis de macrodatos. Data Lake Storage Gen2 combina características de Azure Data Lake Storage Gen1, como la semántica del sistema de archivos y la seguridad y escala de nivel de directorio y archivo con las funcionalidades de recuperación ante desastres y alta disponibilidad, así como de almacenamiento en niveles de bajo costo de Azure Blob Storage.
Nota:
Puesto que Gen1 y Gen2 son servicios diferentes, no hay una experiencia de actualización local. Para simplificar la migración a Gen2 mediante Azure Portal, consulte Migración de Azure Data Lake Storage Gen1 a Gen2 mediante Azure Portal.
Enfoque recomendado
Para migrar de Gen1 a Gen2, se recomienda el siguiente método.
Paso 1: Evaluación de la preparación
Paso 2: Preparación de la migración
Paso 3: Migración de los datos y las cargas de trabajo de las aplicaciones
Paso 4: Paso de Gen1 a Gen2
Paso 1: Evaluación de la preparación
Obtenga información sobre la oferta de Data Lake Storage Gen2, sus beneficios, los costes y la arquitectura general.
Compare las funcionalidades de Gen1 con las de Gen2.
Revise una lista de problemas conocidos para evaluar cualquier brecha que se produzca en la funcionalidad.
Gen2 admite las características de Blob Storage, como el registro de diagnóstico, los niveles de acceso y las directivas de administración del ciclo de vida de Blob Storage. Si le interesa usar cualquiera de estas características, vea el nivel actual de soporte técnico.
Vea el estado actual de compatibilidad con el ecosistema de Azure para asegurarse de que Gen2 admite todos los servicios de los que dependen sus soluciones.
Paso 2: Preparación de la migración
Identifique los conjuntos de datos que va a migrar.
Aproveche esta oportunidad para limpiar los conjuntos de datos que ya no usa. A menos que planee migrar todos los datos al mismo tiempo, dedique este tiempo a identificar los grupos lógicos de datos que puede migrar en fases.
Realice un análisis de antigüedad (o similar) en su cuenta de Gen1 para identificar qué archivos o carpetas permanecen en el inventario durante mucho tiempo o quizás se están volviendo obsoletos.
Determine el impacto que una migración tendrá en su empresa.
Por ejemplo, piense si puede permitirse que haya un tiempo de inactividad mientras se realiza la migración. Estas consideraciones pueden ayudarle a identificar un patrón de migración adecuado y a elegir las herramientas más adecuadas.
Cree un plan de migración.
Se recomiendan estos patrones de migración. Puede elegir uno de estos patrones, combinarlos o diseñar un patrón personalizado propio.
Paso 3: Migración de datos, cargas de trabajo y aplicaciones
Migre los datos, las cargas de trabajo y las aplicaciones con el patrón que prefiera. Se recomienda validar los escenarios de forma incremental.
Cree una cuenta de almacenamiento y habilite la característica de espacio de nombres jerárquico.
Migre los datos.
Configure los servicios de las cargas de trabajo para que apunten a su punto de conexión de Gen2.
Para los clústeres de HDInsight, puede agregar la configuración de la cuenta de almacenamiento al archivo %HADOOP_HOME%/conf/core-site.xml. Si tiene previsto migrar tablas externas de Hive de Gen1 a Gen2, asegúrese de agregar también la configuración de la cuenta de almacenamiento al archivo %HIVE_CONF_DIR%/hive-site.xml.
Puede modificar la configuración de cada archivo mediante Apache Ambari. Para buscar la configuración de la cuenta de almacenamiento, vea Soporte técnico de Azure para Hadoop: ABFS (Azure Data Lake Storage Gen2). En este ejemplo, se usa la configuración
fs.azure.account.keypara habilitar la autorización de clave compartida:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Para ver vínculos a artículos que le ayudan a configurar HDInsight, Azure Databricks y otros servicios de Azure para usar Gen2, consulte Servicios de Azure que admiten Azure Data Lake Storage Gen2.
Actualice las aplicaciones para que usen las API de Gen2. Consulte estas guías:
Actualice los scripts para usar los cmdlets de PowerShell y los comandos de la CLI de Azure de Data Lake Storage Gen2.
Busque referencias del identificador URI que contengan la cadena
adl://en los archivos de código o en los cuadernos de Databricks, archivos HQL de Apache Hive o cualquier otro archivo que se use como parte de las cargas de trabajo. Sustituya estas referencias por el identificador URI con formato de Gen2 de la nueva cuenta de almacenamiento. Por ejemplo: el identificador URI de Gen1:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilepodría convertirse enabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile.Configure la seguridad en su cuenta para que incluya roles de Azure, seguridad de nivel de archivo y carpeta, así como redes virtuales y firewalls de Azure Storage.
Paso 4: Paso de Gen1 a Gen2
Una vez que esté seguro de que tanto las aplicaciones como las cargas de trabajo son estables en Gen2, puede empezar a usar Gen2 para satisfacer sus escenarios empresariales. Desactive las restantes canalizaciones que se estén ejecutando en Gen1 y dé de baja su cuenta de Gen1.
Funcionalidades de Gen1 frente a las de Gen2
En esta tabla se comparan las funcionalidades de Gen1 con las de Gen2.
Patrones de Gen1 a Gen2
Elija un patrón de migración y, después, modifíquelo tanto como sea necesario.
| Patrón de migración | Detalles |
|---|---|
| Lift-and-shift | El patrón más simple. Ideal si sus canalizaciones de datos pueden permitirse un tiempo de inactividad. |
| Copia incremental | Similar a lift-and-shift, pero con menos tiempo de inactividad. Ideal para grandes cantidades de datos que tardan más tiempo en copiarse. |
| Canalización dual | Ideal para canalizaciones que no pueden permitirse ningún tiempo de inactividad. |
| Sincronización bidireccional | Es similar a la canalización dual, pero con un enfoque más escalonado, que es adecuado para canalizaciones más complicadas. |
Examinemos más detenidamente cada patrón.
Patrón lift-and-shift
Este es el patrón más sencillo.
Detenga todas las escrituras en Gen1.
Mueva los datos de Gen1 a Gen2. Se recomienda Azure Data Factory o mediante Azure Portal. Las ACL se copian con los datos.
Apunte las operaciones de ingesta y las cargas de trabajo a Gen2.
Dé de baja Gen1.
Consulte nuestro código de ejemplo para el patrón lift-and-shift en nuestro ejemplo de migración mediante lift-and-shift.
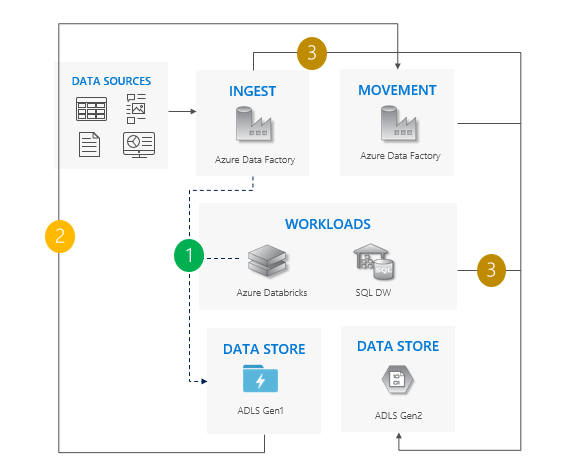
Consideraciones sobre el uso del patrón lift-and-shift
Pase de Gen1 a Gen2 en todas las cargas de trabajo al mismo tiempo.
Cabe esperar que se produzca un tiempo de inactividad durante la migración y el período de transferencia.
Ideal para canalizaciones que pueden permitirse un tiempo de inactividad y todas las aplicaciones se pueden actualizar a la vez.
Sugerencia
Considere la posibilidad de usar Azure Portal para reducir el tiempo de inactividad y el número de pasos necesarios para completar la migración.
Patrón de copia incremental
Empiece a mover los datos de Gen1 a Gen2. Se recomienda Azure Data Factory. Las ACL se copian con los datos.
Copie de forma incremental los datos nuevos de Gen1.
Después de que se copien todos los datos, detenga todas las escrituras en Gen1 y apunte las cargas de trabajo a Gen2.
Dé de baja Gen1.
Consulte nuestro código de ejemplo para obtener el patrón de copia incremental de nuestro ejemplo de migración de copia incremental.
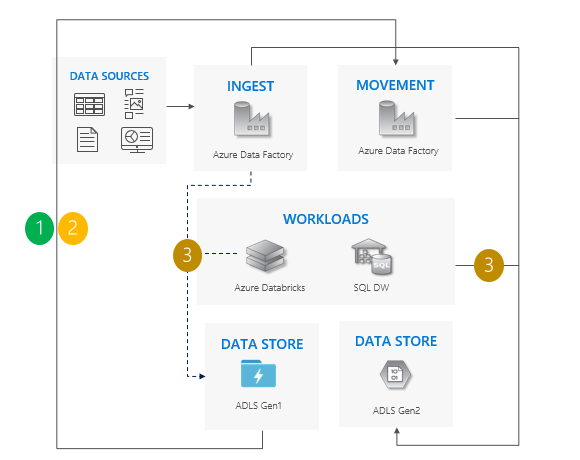
Consideraciones sobre el uso del patrón de copia incremental:
Pase de Gen1 a Gen2 en todas las cargas de trabajo al mismo tiempo.
Cabe esperar un tiempo de inactividad solo durante el período de transferencia.
Ideal para canalizaciones en las que todas las aplicaciones se han actualizado al mismo tiempo, pero la copia de datos requiere más tiempo.
Patrón de canalización dual
Mueva los datos de Gen1 a Gen2. Se recomienda Azure Data Factory. Las ACL se copian con los datos.
Ingiera los datos nuevos tanto a Gen1 como a Gen2.
Apunte las cargas de trabajo a Gen2.
Detenga todas las escrituras en Gen1 y, después, dé de baja Gen1.
Consulte nuestro código de ejemplo para obtener el patrón de canalización dual de nuestro ejemplo de migración de canalización dual.
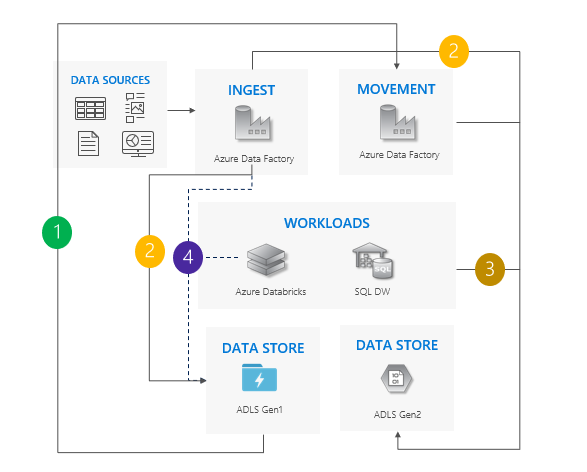
Consideraciones sobre el uso del patrón de canalización dual:
Las canalizaciones de Gen1 y Gen2 se ejecutan en paralelo.
Admite el tiempos de inactividad cero.
Ideal en aquellas situaciones en las que las cargas de trabajo y las aplicaciones no se pueden permitir ningún tiempo de inactividad, y el usuario puede ingerir en ambas cuentas de almacenamiento.
Patrón de sincronización bidireccional
Configure la replicación bidireccional entre Gen1 y Gen2. Se recomienda utilizar WanDisco. Ofrece una característica de reparación para los datos existentes.
Cuando se hayan completado todos los movimientos, detenga todas las escrituras en Gen1 y desactive la replicación bidireccional.
Dé de baja Gen1.
Consulte nuestro código de ejemplo para obtener el patrón de sincronización bidireccional de nuestro ejemplo de migración de sincronización bidireccional.
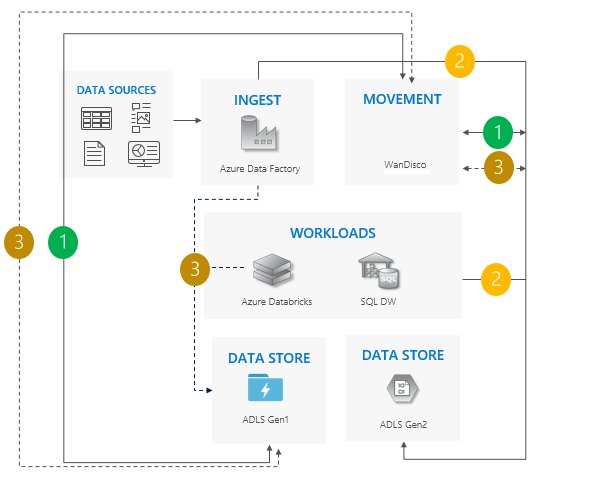
Consideraciones sobre el uso del patrón de sincronización bidireccional:
Ideal para escenarios complejos que implican un gran número de canalizaciones y dependencias en las que un enfoque por fases podría tener más sentido.
El esfuerzo de la migración es elevado, pero proporciona compatibilidad en paralelo para Gen1 y Gen2.
Pasos siguientes
- Obtenga información sobre las distintas partes de la configuración de la seguridad de una cuenta de almacenamiento. Para obtener más información, vea la Guía de seguridad de Azure Storage.
- Optimice el rendimiento de Data Lake Store. Consulte Optimización de Azure Data Lake Storage Gen2 para el rendimiento
- Revise los procedimientos recomendados para administrar Data Lake Store. Consulte Procedimientos recomendados para usar Azure Data Lake Storage Gen2