Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server
SQL Server![]() SSIS Integration Runtime en Azure Data Factory
SSIS Integration Runtime en Azure Data Factory
Feature Pack de SQL Server Integration Services (SSIS) para Azure es una extensión que proporciona los componentes que se muestran en esta página para que SSIS se conecte a los servicios de Azure, para transferir datos entre Azure y orígenes de datos locales, y para procesar los datos almacenados en Azure.
 Descargar Feature Pack de SSIS para Azure
Descargar Feature Pack de SSIS para Azure
- Para SQL Server 2022 - Feature Pack de Microsoft SQL Server 2022 Integration Services para Azure
- Para SQL Server 2019 - Feature Pack de Microsoft SQL Server 2019 Integration Services para Azure
- Para SQL Server 2017 - Feature Pack de Microsoft SQL Server 2017 Integration Services para Azure
- Para SQL Server 2016 - Feature Pack de Microsoft SQL Server 2016 Integration Services para Azure
- Para SQL Server 2014 - Feature Pack de Microsoft SQL Server 2014 Integration Services para Azure
- Para SQL Server 2012 - Feature Pack de Microsoft SQL Server 2012 Integration Services para Azure
En las páginas de descarga también se incluye información sobre los requisitos previos. Asegúrese de instalar SQL Server antes de instalar el Feature Pack de Azure en un servidor o es posible que los componentes del Feature Pack no estén disponibles al implementar los paquetes en la base de datos de catálogo de SSIS, SSISDB, en el servidor.
Componentes de Feature Pack
Administradores de conexión
Tareas
Componentes de flujo de datos
Enumerador de archivos para Blob de Azure, Azure Data Lake Store y Data Lake Storage Gen2. Consultar Contenedor de bucles Para cada uno
Uso de TLS 1.2
La versión de TLS que usa Azure Feature Pack sigue la configuración de .NET Framework del sistema.
Para usar TLS 1.2, agregue un valor REG_DWORD denominado SchUseStrongCrypto con datos 1 en las dos claves del Registro siguientes.
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\.NETFramework\v4.0.30319HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\.NETFramework\v4.0.30319
Dependencia en Java
Java es necesario para usar formatos de archivo ORC/Parquet con conectores de Azure Data Lake Store/archivos flexibles.
La arquitectura (32 o 64 bits) de la compilación de Java debe coincidir con la del entorno de ejecución de SSIS que se va a usar.
Se han probado las siguientes compilaciones de Java.
Configurar OpenJDK de Zulu
- Descargue y extraiga el paquete ZIP de instalación.
- Desde el símbolo del sistema, ejecute
sysdm.cpl. - En la pestaña Avanzadas, haga clic en Variables de entorno.
- En la sección Variables del sistema, haga clic en Nueva.
- Escriba
JAVA_HOMEpara el Nombre de variable. - Seleccione Examinar directorio, vaya a la carpeta extraída y seleccione la subcarpeta
jre. Luego seleccione Aceptar y el campo Valor de la variable se rellena de forma automática. - Haga clic en Aceptar para cerrar el cuadro de diálogo Nueva variable del sistema.
- Seleccione Aceptar para cerrar el cuadro de diálogo Variables de entorno.
- Seleccione Aceptar para cerrar el cuadro de diálogo Propiedades del sistema.
Sugerencia
Si usa el formato de Parquet y recibe un error que dice que se ha producido un error al invocar Java, con el mensaje: java.lang.OutOfMemoryError:Java heap space, puede agregar una variable de entorno _JAVA_OPTIONS para ajustar el tamaño mínimo y máximo del montón de JVM.
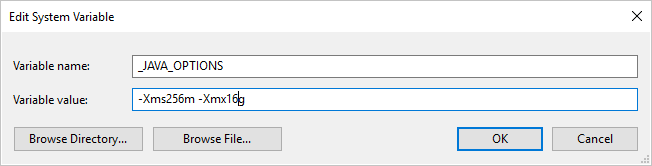
Ejemplo: establecimiento de la variable _JAVA_OPTIONS con el valor -Xms256m -Xmx16g. La marca Xms especifica el grupo de asignación de memoria inicial para una Máquina virtual Java (JVM), mientras que Xmx especifica el grupo de asignación de memoria máxima. Esto significa que JVM se iniciará con la cantidad de memoria Xms y podrá utilizar Xmx como máximo. Los valores predeterminados son 64 MB como mínimo y 1 G como máximo.
Configuración de OpenJDK de Zulú en Azure-SSIS Integration Runtime
Esto debe hacerse a través de la interfaz de instalación personalizada para Azure-SSIS Integration Runtime.
Supongamos que se usa zulu8.33.0.1-jdk8.0.192-win_x64.zip.
El contenedor de blobs se puede organizar de la manera siguiente:
main.cmd
install_openjdk.ps1
zulu8.33.0.1-jdk8.0.192-win_x64.zip
Como punto de entrada, main.cmd desencadena la ejecución del script install_openjdk.ps1 de PowerShell que, a su vez, extrae zulu8.33.0.1-jdk8.0.192-win_x64.zip y establece JAVA_HOME en consecuencia.
main.cmd
powershell.exe -file install_openjdk.ps1
Sugerencia
Si usa el formato de Parquet y recibe un error que dice que se ha producido un error al invocar Java, con el mensaje: java.lang.OutOfMemoryError:Java heap space, puede agregar un comando en main.cmd para ajustar el tamaño mínimo y máximo del montón de JVM. Ejemplo:
setx /M _JAVA_OPTIONS "-Xms256m -Xmx16g"
La marca Xms especifica el grupo de asignación de memoria inicial para una Máquina virtual Java (JVM), mientras que Xmx especifica el grupo de asignación de memoria máxima. Esto significa que JVM se iniciará con la cantidad de memoria Xms y podrá utilizar Xmx como máximo. Los valores predeterminados son 64 MB como mínimo y 1 G como máximo.
install_openjdk.ps1
Expand-Archive zulu8.33.0.1-jdk8.0.192-win_x64.zip -DestinationPath C:\
[Environment]::SetEnvironmentVariable("JAVA_HOME", "C:\zulu8.33.0.1-jdk8.0.192-win_x64\jre", "Machine")
Configurar Java SE Runtime Environment de Oracle
- Descargue y ejecute el instalador .exe.
- Siga las instrucciones del programa de instalación para completar la instalación.
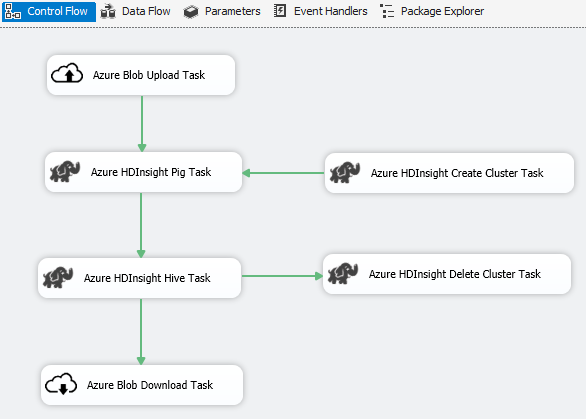
Escenario: Procesamiento de macrodatos
Use el Conector Azure para completar el trabajo de procesamiento de macrodatos siguiente:
Utilice la tarea de carga de blobs de Azure para cargar datos de entrada en el almacenamiento de blobs de Azure.
Utilice la tarea de creación de clúster de HDInsight de Azure para crear un clúster de HDInsight de Azure. Este paso es opcional si quiere utilizar su propio clúster.
Utilice la tarea de Hive de HDInsight de Azure o la tarea de Pig de HDInsight de Azure para invocar un trabajo de Pig o Hive en el clúster de HDInsight de Azure.
Utilice la tarea de eliminación de clúster de HDInsight de Azure para eliminar el clúster de HDInsight tras su uso si creó un clúster de HDInsight a petición en el paso 2.
Utilice la tarea de descarga de blobs de HDInsight de Azure para descargar los datos de salida de Pig o Hive del almacenamiento de blobs de Azure.
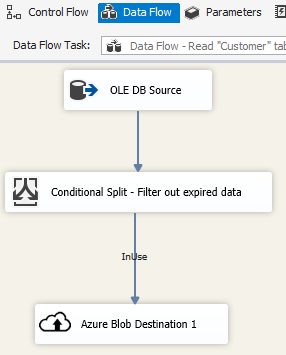
Escenario: Administración de datos en la nube
Use el destino de blobs de Azure en un paquete de SSIS para escribir los datos de salida en Almacenamiento de blobs de Azure o para utilizar el origen de blobs de Azure para leer datos desde un Almacenamiento de blobs de Azure.
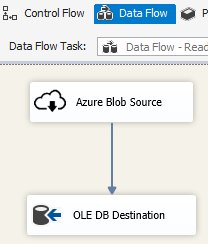
Utilice el contenedor de bucles Foreach con el enumerador de blobs de Azure para procesar los datos de varios archivos de blob.
Notas de la versión
Versión 1.21.0
Mejoras
- Log4j actualizado de la versión 1.2.17 a la 2.17.1.
Versión 1.20.0
Mejoras
- Se ha actualizado la versión de .NET Framework de destino de 4.6 a 4.7.2.
- Se ha cambiado el nombre de "Tarea de carga de Azure SQL DW" a "Tarea de Azure Synapse Analytics".
Correcciones
- Cuando se accede a Azure Blob Storage y la máquina que ejecuta SSIS está en una configuración regional que no es de EE. UU., se producirá un error en la ejecución del paquete y se mostrará el mensaje de error "String not recognized as a valid DateTime value" (La cadena no se ha reconocido como un valor DateTime válido).
- En el Administrador de conexiones de Azure Storage, se requiere un secreto (que no se haya usado) incluso cuando se usa la identidad administrada de Data Factory para autenticarse.
Version 1.19.0
Mejoras
- Se ha agregado compatibilidad con la autenticación de firma de acceso compartido en el administrador de conexiones de Azure Storage.
Versión 1.18.0
Mejoras
- En el caso de la tarea de archivo flexible, se han introducido tres mejoras: (1) se ha agregado compatibilidad con caracteres comodín para las operaciones de copia y eliminación; (2) el usuario puede habilitar o deshabilitar la búsqueda recursiva para la operación de eliminación; y (3) el nombre del archivo de destino para la operación de copia puede estar vacío para conservar el nombre del archivo de origen.
Versión 1.17.0
Se trata de una versión de revisión publicada solo para SQL Server 2019.
Correcciones
- Al ejecutarse en Visual Studio 2019 y establecer como destino SQL Server 2019, podría producirse un error en la tarea, origen o destino del archivo flexible con el mensaje de error
Attempted to access an element as a type incompatible with the array.. - Al ejecutarse en Visual Studio 2019 y establecer como destino SQL Server 2019, podría producirse un error en el origen o destino del archivo flexible mediante el formato ORC/Parquet con el mensaje de error
Microsoft.DataTransfer.Common.Shared.HybridDeliveryException: An unknown error occurred. JNI.JavaExceptionCheckException..
Versión 1.16.0
Correcciones
- En algunos casos, la ejecución de paquetes informa de "Error: No se puede cargar el archivo o ensamblado 'Newtonsoft.Json, Version=11.0.0.0, Culture=neutral, PublicKeyToken=30ad4fe6b2a6aeed' ni una de sus dependencias".
Versión 1.15.0
Mejoras
- Adición de la operación de eliminación de carpeta/archivo en la tarea de archivo flexible
- Adición de la función de conversión de tipos de datos externos/de salida en el origen de archivo flexible
Correcciones
- En algunos casos, las conexiones de prueba no funcionan correctamente para Data Lake Storage Gen2 con el mensaje de error de tipo "Se intentó obtener acceso a un elemento como un tipo incompatible con la matriz".
- Devolución del soporte técnico para el emulador de Azure Storage