Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server en Linux
SQL Server en Linux
En este tutorial, se explica cómo configurar grupos de disponibilidad de SQL Server con HPE Serviceguard para Linux, ejecutándose en máquinas virtuales (VM) del entorno local o de Azure.
Para obtener información general sobre los clústeres de HPE Serviceguard, consulte Clústeres de HPE Serviceguard.
Nota
Microsoft admite el movimiento de datos, el grupo de disponibilidad y los componentes de SQL Server. Póngase en contacto con HPE para obtener soporte técnico relacionado con la documentación de administración de clústeres y cuórum de HPE Serviceguard.
Este tutorial consta de las tareas siguientes:
- Instale SQL Server en las tres máquinas virtuales que planea incluir en el grupo de disponibilidad.
- Instale HPE Serviceguard en las máquinas virtuales.
- Cree el clúster HPE Serviceguard.
- Cree el equilibrador de carga en Azure Portal.
- Cree el grupo de disponibilidad y agregue una base de datos de ejemplo al grupo de disponibilidad.
- Implemente la carga de trabajo de SQL Server en el grupo de disponibilidad mediante el administrador de clústeres de Serviceguard.
- Realice una conmutación por falla automática y vuelva a unir el nodo al clúster.
Requisitos previos
En Azure, cree tres máquinas virtuales basadas en Linux. Para crear máquinas virtuales basadas en Linux en Azure, consulte Inicio rápido: Creación de una máquina virtual Linux en Azure Portal. Al implementar las máquinas virtuales, asegúrese de utilizar distribuciones de Linux compatibles con HPE Serviceguard. También puede implementar las máquinas virtuales localmente en un entorno local si lo prefiere.
Para obtener un ejemplo de una distribución compatible, vea HPE Serviceguard para Linux. Póngase en contacto con HPE para obtener información sobre la compatibilidad con los entornos de nube pública.
Las instrucciones de este tutorial se validan con HPE Serviceguard para Linux. Hay una edición de prueba disponible para descargar desde HPE.
Archivos de base de datos SQL Server en el montaje de volumen lógico (LVM) para las tres máquinas virtuales. Consulte guía de inicio rápido para Serviceguard Linux (HPE).
Asegúrese de que tiene instalado el entorno de ejecución de Java de OpenJDK en las máquinas virtuales. No se admite el SDK de Java de IBM.
Instalar SQL Server
En las tres máquinas virtuales, siga uno de los pasos descritos en la sección siguiente en función de la distribución de Linux que elija para este tutorial. Los pasos para instalar SQL Server y las herramientas.
Red Hat Enterprise Linux (RHEL)
SUSE Linux Enterprise Server (SLES)
Nota
A partir de SQL Server 2025 (17.x), no se admite SUSE Linux Enterprise Server (SLES).
Cuando termine este paso, tendrá instalado el servicio y las herramientas de SQL Server en las tres máquinas virtuales que van a participar en el grupo de disponibilidad.
Instalación de HPE Serviceguard en las máquinas virtuales
En este paso, instale HPE Serviceguard para Linux en las tres máquinas virtuales. En la tabla siguiente se describe el rol que desempeña cada servidor en el clúster.
| Número de VM | Rol HPE Serviceguard | Rol de réplica de grupo de disponibilidad de Microsoft SQL Server |
|---|---|---|
| 1 | Nodos de clúster de HPE Serviceguard | Réplica principal |
| 1 o más | Nodo de clúster de HPE Serviceguard | Réplica secundaria |
| 1 | Servidor de cuórum de HPE Serviceguard | Réplica de solo configuración |
Nota
Consulte este vídeo de HPE, que describe cómo instalar y configurar un clúster de HPE Serviceguard a través de la interfaz de usuario.
Para instalar Serviceguard, use el método cminstaller. Las instrucciones específicas están disponibles en los vínculos siguientes:
- Instale Serviceguard para Linux en dos nodos. Consulte la sección Install_serviceguard_using_cminstaller.
- Instale el servidor de cuórum de Serviceguard en el tercer nodo. Consulte la sección Install_QS_from_the_ISO.
Después de completar la instalación del clúster hpe Serviceguard, puede habilitar el portal de administración de clústeres en el puerto TCP 5522 en el nodo de réplica principal. En los pasos siguientes se agrega una regla al firewall para permitir 5522. El siguiente comando es para Red Hat Enterprise Linux (RHEL). Debe ejecutar comandos similares para otras distribuciones:
sudo firewall-cmd --zone=public --add-port=5522/tcp --permanent
sudo firewall-cmd --reload
Creación del clúster de HPE Serviceguard
Siga estas instrucciones para configurar y crear el clúster de HPE Serviceguard. En este paso, también configurará el servidor de quórum.
- Configure el servidor de cuórum de Serviceguard en el tercer nodo. Consulte la sección Configure_QS.
- Configure y cree un clúster de Serviceguard en los otros dos nodos. Consulte la sección Configure_and_create_Cluster.
Nota
Puede omitir la instalación manual del clúster y el cuórum de HPE Serviceguard agregando la extensión HPE Serviceguard para Linux (SGLX) desde Azure VM Marketplace al crear la máquina virtual.
Creación del grupo de disponibilidad y adición de una base de datos de ejemplo
En este paso, creará un grupo de disponibilidad con dos o más réplicas sincrónicas y una réplica de solo configuración, que proporciona protección de datos y también puede proporcionar alta disponibilidad. El diagrama siguiente representa esta arquitectura:
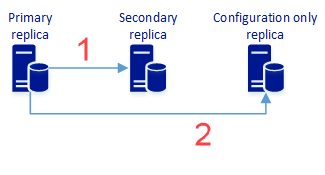
Replicación sincrónica de datos de usuario en la réplica secundaria. También incluye los metadatos de configuración del grupo de disponibilidad.
Replicación sincrónica de los metadatos de configuración del grupo de disponibilidad. No incluye datos de usuario.
Para más información, vea Alta disponibilidad y protección de datos para las configuraciones de grupo de disponibilidad.
Para crear el grupo de disponibilidad, siga estos pasos:
- Habilite grupos de disponibilidad y reinicie mssql-server en todas las máquinas virtuales, incluida la réplica de solo configuración.
-
Habilite una sesión de eventos
AlwaysOn_health(opcional). - Cree un certificado en la máquina virtual principal.
- Crear el certificado en los servidores secundarios
- Cree los puntos de conexión de creación de reflejo de la base de datos en las réplicas.
- CREATE AVAILABILITY GROUP
- Combine las réplicas secundarias.
- Agregar una base de datos al grupo de disponibilidad
Habilitación de grupos de disponibilidad y reinicio de mssql-server
Habilite los grupos de disponibilidad en todos los nodos que hospedan una instancia de SQL Server. Después, reinicie mssql-server. Ejecute el script siguiente en los tres nodos:
sudo /opt/mssql/bin/mssql-conf
set hadr.hadrenabled 1 sudo systemctl restart mssql-server
Habilitación de una sesión de eventos AlwaysOn_health (opcional)
Opcionalmente, habilite los eventos extendidos de grupos de disponibilidad Always On para ayudar con el diagnóstico de causa raíz al resolver problemas de un grupo de disponibilidad. Ejecute el comando siguiente en todas las instancias de SQL Server:
ALTER EVENT SESSION AlwaysOn_health ON SERVER
WITH (STARTUP_STATE = ON);
GO
Creación de un certificado en la máquina virtual principal
El script de Transact-SQL siguiente crea una clave maestra y un certificado. Después, realiza una copia de seguridad del certificado y protege el archivo con una clave privada. Actualice el script con contraseñas seguras. Conéctese a la instancia de SQL Server principal y ejecute el siguiente script de Transact-SQL:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
ENCRYPTION BY PASSWORD = '<private-key-password>'
);
En este momento, la réplica principal de SQL Server tiene un certificado en /var/opt/mssql/data/dbm_certificate.cer y una clave privada en var/opt/mssql/data/dbm_certificate.pvk. Copie estos dos archivos en la misma ubicación en todos los servidores que hospedan las réplicas de disponibilidad. Para acceder a estos archivos, use el mssql usuario o conceda permiso al mssql usuario.
Por ejemplo, en el servidor de origen, el siguiente comando copia los archivos en el equipo de destino. Reemplace los valores node2 por el nombre del host que ejecuta la instancia de SQL Server secundaria. Copie el certificado en la réplica solo de configuración y ejecute los siguientes comandos en ese nodo.
cd /var/opt/mssql/data
scp dbm_certificate.* root@<node2>:/var/opt/mssql/data/
Ahora, en las máquinas virtuales secundarias que ejecutan la instancia secundaria y la única réplica de configuración de SQL Server, ejecute los siguientes comandos para que el mssql usuario pueda poseer el certificado copiado:
cd /var/opt/mssql/data
chown mssql:mssql dbm_certificate.*
Crear el certificado en los servidores secundarios
El script de Transact-SQL siguiente crea una clave maestra y un certificado a partir de la copia de seguridad creada en la réplica principal de SQL Server. Actualice el script con contraseñas seguras. La contraseña de descifrado es la misma que usó para crear el .pvk archivo en un paso anterior. Para crear el certificado, ejecute el script siguiente en todos los servidores secundarios, excepto en la réplica de solo configuración:
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>';
CREATE CERTIFICATE dbm_certificate
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
DECRYPTION BY PASSWORD = '<private-key-password>'
);
En el ejemplo anterior, reemplace <private-key-password> por la misma contraseña que usó al crear el certificado en la réplica principal.
Creación de los puntos de conexión de creación de reflejo de la base de datos en las réplicas
En las réplicas primaria y secundaria, ejecute los siguientes comandos para crear los extremos de mirroring de la base de datos.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Nota
5022 es el puerto estándar que se usa para el punto de conexión de creación de reflejo de la base de datos, pero puede cambiarlo por cualquier puerto disponible.
En la réplica de configuración solamente, cree el punto de conexión de reflejo de la base de datos mediante el siguiente comando. Establezca el valor para Role en WITNESS, que es el rol requerido para la réplica solo de configuración.
CREATE ENDPOINT [hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING
(
ROLE = WITNESS,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [hadr_endpoint]
STATE = STARTED;
Crear grupo de disponibilidad
En la instancia de la réplica principal, ejecute los comandos siguientes. Estos comandos crean un grupo de disponibilidad denominado ag1 que tiene un elemento cluster_type externo y concede el permiso CREATE DATABASE al grupo de disponibilidad.
Antes de ejecutar los siguientes scripts, reemplace los <node1>, <node2> y <node3> (réplica solo de configuración) por los nombres de las máquinas virtuales que creó en los pasos anteriores.
CREATE AVAILABILITY GROUP [ag1]
WITH (CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'<node1>' WITH (
ENDPOINT_URL = N'tcp://<node1>:<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node2>' WITH (
ENDPOINT_URL = N'tcp://<node2>:\<5022>',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC
),
N'<node3>' WITH (
ENDPOINT_URL = N'tcp://<node3>:<5022>',
AVAILABILITY_MODE = CONFIGURATION_ONLY
);
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
Unirse a las réplicas secundarias
Ejecute los comandos siguientes en todas las réplicas secundarias. Estos comandos combinan las réplicas secundarias al grupo de disponibilidad ag1 con la réplica principal y proporcionan acceso de creación de base de datos al grupo de disponibilidad ag1.
ALTER AVAILABILITY GROUP [ag1]
JOIN WITH (CLUSTER_TYPE = EXTERNAL);
GO
ALTER AVAILABILITY GROUP [ag1]
GRANT CREATE ANY DATABASE;
GO
Agregar una base de datos al grupo de disponibilidad
Conéctese a la réplica principal y ejecute los comandos T-SQL siguientes para:
Cree una base de datos de ejemplo denominada
db1, que agregará al grupo de disponibilidad.CREATE DATABASE [db1]; GOEstablecer el modelo de recuperación de la base de datos en Completa. Todas las bases de datos de un grupo de disponibilidad requieren el modelo de recuperación completa.
ALTER DATABASE [db1] SET RECOVERY FULL;Realice una copia de seguridad de la base de datos. Una base de datos necesita al menos una copia de seguridad completa antes de poder agregarla a un grupo de disponibilidad.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Establezca la base de datos en el modelo de recuperación completa.
ALTER DATABASE [db1] SET RECOVERY FULL;Realice una copia de seguridad de la base de datos en el disco.
BACKUP DATABASE [db1] TO DISK = N'/var/opt/mssql/data/db1.bak';Agregue la base de datos
db1al grupo de disponibilidad.ALTER AVAILABILITY GROUP [ag1] ADD DATABASE [db1];
Después de completar los pasos anteriores, verá un grupo de disponibilidad ag1. Las tres máquinas virtuales se agregan como réplicas, con una réplica principal, una réplica secundaria y una réplica destinada solo a la configuración.
ag1 contiene una base de datos.
Implementación de la carga de trabajo del grupo de disponibilidad de SQL Server (Administrador de clústeres de HPE)
En HPE Serviceguard, implemente la carga de trabajo de SQL Server en el grupo de disponibilidad a través de la interfaz de usuario del administrador de clústeres de Serviceguard.
Implemente la carga de trabajo del grupo de disponibilidad y habilite la alta disponibilidad (HA) y la recuperación ante desastres (DR) a través del clúster de Serviceguard mediante la interfaz gráfica de usuario del administrador de Serviceguard. Consulte la sección Protección de Microsoft SQL Server en Linux para grupos de disponibilidad Always On.
Creación del equilibrador de carga en Azure Portal
Para las implementaciones en la nube de Azure, HPE Serviceguard para Linux requiere un equilibrador de carga para habilitar las conexiones de cliente con la réplica principal para sustituir las direcciones IP tradicionales.
En Azure Portal, abra el grupo de recursos que contiene los nodos de clúster o máquinas virtuales de Serviceguard.
En el grupo de recursos, seleccione Agregar.
Busque "equilibrador de carga" y, a continuación, en los resultados de la búsqueda, seleccione la instancia del equilibrador de carga publicada por Microsoft.
En el panel Equilibrador de carga, seleccione Crear.
Configure el equilibrador de carga de la siguiente manera:
Configuración Importancia Nombre Nombre del equilibrador de carga. Por ejemplo, SQLAvailabilityGroupLB.Tipo Interno SKU Básico o Estándar Red virtual Red virtual usada para las réplicas de máquina virtual Subred Subred en la que se hospedan instancias de SQL Server Asignación de dirección IP Estática Dirección IP privada Creación de una dirección IP privada dentro de la subred Suscripción Elección de la suscripción de interés Grupo de recursos Elección del grupo de recursos de interés Ubicación Selección de la misma ubicación que los nodos SQL
Configuración del grupo back-end
El grupo de back-end son las direcciones de las dos instancias en las que está configurado el clúster de Serviceguard.
- En el grupo de recursos, seleccione el equilibrador de carga que ha creado.
- Vaya a Configuración>Grupos de back-end, y seleccione Agregar para crear un grupo de direcciones de back-end.
- En Agregar grupo de back-end, en Nombre, especifique un nombre para el grupo de back-end.
- En Asociado a, seleccione Máquina virtual.
- Seleccione cada una de las máquinas virtuales del entorno y asocie la dirección IP adecuada a cada selección.
- Selecciona Agregar.
Elaboración de un sondeo
El sondeo define cómo Azure comprueba cuál de los nodos del clúster de Serviceguard es la réplica principal. Azure analiza el servició con arreglo a la dirección IP de un puerto que estableció al crear el sondeo.
En el panel Configuración del equilibrador de carga, seleccione Sondeos de estado.
En el panel Sondeos de estado , seleccione Agregar.
Utilice los valores siguientes para configurar el sondeo.
Configuración Importancia Nombre Nombre que representa el sondeo. Por ejemplo, SQLAGPrimaryReplicaProbe.Protocol TCP Puerto Puede usar cualquier puerto que esté disponible. Por ejemplo, 59999. Intervalo 5 Umbral incorrecto 2 Selecciona Aceptar.
Inicie sesión en todas las máquinas virtuales y abra el puerto de sondeo con los siguientes comandos:
sudo firewall-cmd --zone=public --add-port=59999/tcp --permanent sudo firewall-cmd --reload
Azure crea el sondeo y, a continuación, lo usa para probar el nodo Serviceguard en el que se ejecuta la instancia de la réplica principal del grupo de disponibilidad. Recuerde el puerto que configuró (59999), que es necesario para implementar el grupo de disponibilidad (AG) en el clúster de Serviceguard.
Configuración de las reglas de equilibrio de carga
Las reglas de equilibrio de carga configuran cómo el equilibrador de carga enruta el tráfico al nodo Serviceguard, que es la réplica principal del clúster. Para este equilibrador de carga, habilite Direct Server Return, ya que solo uno de los nodos del clúster de Serviceguard puede ser una réplica principal al mismo tiempo.
En Configuración del equilibrador de carga, seleccione Reglas de equilibrio de carga.
En Reglas de equilibrio de carga, seleccione Agregar.
Configure la regla de equilibrio de carga con los siguientes valores:
Configuración Importancia Nombre Nombre que representa las reglas de equilibrio de carga. Por ejemplo, SQLAGPrimaryReplicaListener.Protocol TCP Puerto 1433 Puerto back-end 1433. Este valor se ignora porque esta regla utiliza IP flotante. Sondeo Utilice el nombre del sondeo que creó para este equilibrador de carga. Persistencia de la sesión Ninguno Tiempo de espera de inactividad (minutos) 4 IP flotante Habilitado Selecciona Aceptar.
Azure configura la regla de equilibrio de carga. Ahora, el equilibrador de carga está configurado para enrutar el tráfico al nodo de Serviceguard que es la instancia de réplica principal del clúster.
Tome nota de la dirección IP de frontend del equilibrador de carga LbReadWriteIP, que necesita para desplegar el AG en el clúster de Serviceguard.
En este punto, el grupo de recursos dispone de un equilibrador de carga que se conecta con todos los nodos de Serviceguard. El equilibrador de carga también contiene una dirección IP para que los clientes se conecten a la instancia de réplica principal del clúster, de modo que cualquier máquina que sea una réplica principal pueda responder a las solicitudes del grupo de disponibilidad.
Realización de la conmutación automática por error y combinación del nodo con el clúster
Para la prueba de conmutación automática por error, desconecte la réplica principal (apagado). Esta acción replica la falta de disponibilidad repentina del nodo principal. Éste es el comportamiento esperado:
El administrador de clústeres promueve a principal una de las réplicas secundarias del grupo de disponibilidad.
La réplica principal con error se combina automáticamente con el clúster después de que se reinicie. El administrador de clústeres la promueve a una réplica secundaria.
Para HPE Serviceguard, consulte Prueba de la configuración para la preparación de la conmutación por error.