Creación y configuración de un grupo de disponibilidad para SQL Server en Linux
Se aplica a: ![]() SQL Server - Linux
SQL Server - Linux
En este tutorial se habla de cómo crear y configurar un grupo de disponibilidad para SQL Server en Linux. A diferencia de SQL Server 2016 (13.x) y versiones anteriores en Windows, puede habilitar un grupo de disponibilidad creando primero el clúster de Pacemaker subyacente o sin hacerlo. La integración con el clúster, si fuera necesaria, no se realiza hasta más tarde.
El tutorial incluye las siguientes tareas:
- Habilitar grupos de disponibilidad.
- Crear puntos de conexión y certificados de grupo de disponibilidad.
- Usar SQL Server Management Studio (SSMS) o Transact-SQL para crear un grupo de disponibilidad.
- Crear el inicio de sesión de SQL Server y los permisos para Pacemaker.
- Crear recursos de grupo de disponibilidad en un clúster de Pacemaker (solo tipo Externo).
Requisitos previos
Implemente el clúster de alta disponibilidad de Pacemaker tal como se explica en Implementar un clúster de Pacemaker para SQL Server en Linux.
Habilitar la característica de grupos de disponibilidad
A diferencia de como se hace en Windows, no puede usar PowerShell ni SQL Server Configuration Manager para habilitar la característica de grupos de disponibilidad. En Linux, debe usar mssql-conf para habilitar la característica. Hay dos maneras de habilitar la característica de grupos de disponibilidad: usar la utilidad mssql-conf o editar el archivo mssql.conf manualmente.
Importante
La característica de grupos de disponibilidad debe estar habilitada para las réplicas de solo configuración, incluso en SQL Server Express.
Usar la utilidad mssql-conf
En un símbolo del sistema, emita el siguiente comando:
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
Editar el archivo mssql.conf
También puede modificar el archivo mssql.conf, que se encuentra en la carpeta /var/opt/mssql, para agregar las siguientes líneas:
[hadr]
hadr.hadrenabled = 1
Reiniciar SQL Server
Después de habilitar los grupos de disponibilidad, como en Windows, debe reiniciar SQL Server usando el siguiente comando:
sudo systemctl restart mssql-server
Crear los puntos de conexión y los certificados del grupo de disponibilidad
Un grupo de disponibilidad usa puntos de conexión TCP para la comunicación. En Linux, los puntos de conexión de un grupo de disponibilidad solo se admiten si se usan certificados para la autenticación. Debe restaurar el certificado de una instancia en todas las demás instancias que vayan a ser réplicas participantes en el mismo grupo de disponibilidad. El proceso de certificado es necesario incluso para una réplica de solo configuración.
La creación de puntos de conexión y la restauración de certificados solo se pueden realizar mediante Transact-SQL. También puede usar certificados no generados por SQL Server. Además necesita un proceso para administrar y reemplazar los certificados que expiren.
Importante
Si tiene previsto usar el asistente de SQL Server Management Studio para crear el grupo de disponibilidad, debe crear y restaurar los certificados mediante Transact-SQL en Linux.
Para obtener la sintaxis completa de las opciones disponibles para los distintos comandos (incluida la seguridad), vea:
Nota:
Aunque va a crear un grupo de disponibilidad, el tipo de punto de conexión usa FOR DATABASE_MIRRORING, ya que algunos aspectos subyacentes se han compartido en algún momento con esa característica ahora en desuso.
En este ejemplo se crean certificados para una configuración de tres nodos. Los nombres de las instancias son LinAGN1, LinAGN2 y LinAGN3.
Ejecute la siguiente secuencia de comandos en
LinAGN1para crear la clave maestra, el certificado y el punto de conexión, así como para realizar una copia de seguridad del certificado. En este ejemplo se usa el puerto TCP típico de 5022 para el punto de conexión.CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<StrongPassword>'; GO CREATE CERTIFICATE LinAGN1_Cert WITH SUBJECT = 'LinAGN1 AG Certificate'; GO BACKUP CERTIFICATE LinAGN1_Cert TO FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING(AUTHENTICATION = CERTIFICATE LinAGN1_Cert, ROLE = ALL); GOHaga lo mismo en
LinAGN2:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<StrongPassword>'; GO CREATE CERTIFICATE LinAGN2_Cert WITH SUBJECT = 'LinAGN2 AG Certificate'; GO BACKUP CERTIFICATE LinAGN2_Cert TO FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL) FOR DATABASE_MIRRORING ( AUTHENTICATION = CERTIFICATE LinAGN2_Cert, ROLE = ALL); GOPor último, realice la misma secuencia en
LinAGN3:CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<StrongPassword>'; GO CREATE CERTIFICATE LinAGN3_Cert WITH SUBJECT = 'LinAGN3 AG Certificate'; GO BACKUP CERTIFICATE LinAGN3_Cert TO FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GO CREATE ENDPOINT AGEP STATE = STARTED AS TCP ( LISTENER_PORT = 5022, LISTENER_IP = ALL ) FOR DATABASE_MIRRORING(AUTHENTICATION = CERTIFICATE LinAGN3_Cert, ROLE = ALL); GOCon
scpu otra utilidad, copie las copias de seguridad del certificado en todos los nodos que vayan a formar parte del grupo de disponibilidad.En este ejemplo:
- Copie
LinAGN1_Cert.cerenLinAGN2yLinAGN3. - Copie
LinAGN2_Cert.cerenLinAGN1yLinAGN3. - Copie
LinAGN3_Cert.cerenLinAGN1yLinAGN2.
- Copie
Cambie la propiedad y el grupo asociados a los archivos de certificado copiados en
mssql.sudo chown mssql:mssql <CertFileName>Cree los inicios de sesión de nivel de instancia y los usuarios asociados a
LinAGN2yLinAGN3enLinAGN1.CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GORealice la restauración de
LinAGN2_CertyLinAGN3_CertenLinAGN1. El disponer de los certificados de las otras réplicas es un aspecto importante de la comunicación y la seguridad de los grupos de disponibilidad.CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOConceda permiso para conectarse al punto de conexión en
LinAGN1a los inicios de sesión asociados aLinAG2yLinAGN3.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCree los inicios de sesión de nivel de instancia y los usuarios asociados a
LinAGN1yLinAGN3enLinAGN2.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN3_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN3_User FOR LOGIN LinAGN3_Login; GORealice la restauración de
LinAGN1_CertyLinAGN3_CertenLinAGN2.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN3_Cert AUTHORIZATION LinAGN3_User FROM FILE = '/var/opt/mssql/data/LinAGN3_Cert.cer'; GOConceda permiso para conectarse al punto de conexión en
LinAGN2a los inicios de sesión asociados aLinAG1yLinAGN3.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN3_Login; GOCree los inicios de sesión de nivel de instancia y los usuarios asociados a
LinAGN1yLinAGN2enLinAGN3.CREATE LOGIN LinAGN1_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN1_User FOR LOGIN LinAGN1_Login; GO CREATE LOGIN LinAGN2_Login WITH PASSWORD = '<StrongPassword>'; CREATE USER LinAGN2_User FOR LOGIN LinAGN2_Login; GORealice la restauración de
LinAGN1_CertyLinAGN2_CertenLinAGN3.CREATE CERTIFICATE LinAGN1_Cert AUTHORIZATION LinAGN1_User FROM FILE = '/var/opt/mssql/data/LinAGN1_Cert.cer'; GO CREATE CERTIFICATE LinAGN2_Cert AUTHORIZATION LinAGN2_User FROM FILE = '/var/opt/mssql/data/LinAGN2_Cert.cer'; GOConceda permiso para conectarse al punto de conexión en
LinAGN3a los inicios de sesión asociados aLinAG1yLinAGN2.GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN1_Login; GO GRANT CONNECT ON ENDPOINT::AGEP TO LinAGN2_Login; GO
Crear el grupo de disponibilidad
En esta sección se explica cómo usar SQL Server Management Studio (SSMS) o Transact-SQL para crear el grupo de disponibilidad para SQL Server.
Use SQL Server Management Studio
En esta sección se muestra cómo crear un grupo de disponibilidad con un tipo de clúster Externo mediante SSMS con el Asistente para nuevo grupo de disponibilidad.
En SSMS, expanda Alta disponibilidad de Always On, haga clic con el botón derecho en Grupos de disponibilidad y seleccione Asistente para nuevo grupo de disponibilidad.
En el cuadro de diálogo Introducción, seleccione Siguiente.
En el cuadro de diálogo Especificar opciones de grupo de disponibilidad, escriba un nombre para el grupo de disponibilidad y seleccione un tipo de clúster
EXTERNALoNONEen la lista desplegable. Debe usarse Externo cuando se vaya a implementar Pacemaker. Ninguno es para escenarios especializados, como el escalado horizontal de lectura. La selección de la opción para la detección del estado del nivel de la base de datos es opcional. Para obtener más información sobre esta opción, vea Opción de conmutación por error de detección del estado del nivel de la base de datos de un grupo de disponibilidad. Seleccione Siguiente.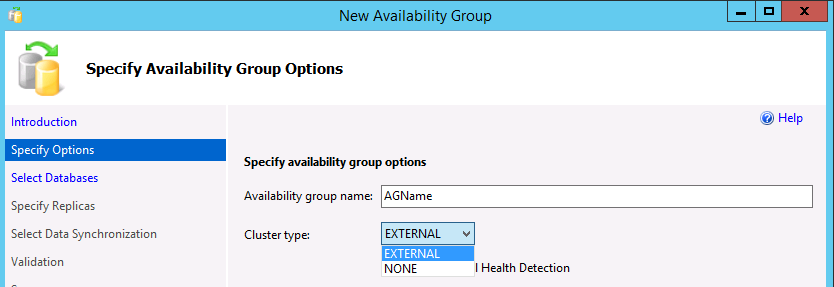
En el cuadro de diálogo Seleccionar bases de datos, seleccione las bases de datos que van a participar en el grupo de disponibilidad. Cada base de datos debe tener una copia de seguridad completa para que se pueda agregar a un grupo de disponibilidad. Seleccione Siguiente.
En el cuadro de diálogo Especificar réplicas, seleccione Agregar réplica.
En el cuadro de diálogo Conectar al servidor, escriba el nombre de la instancia de Linux de SQL Serverque va a ser la réplica secundaria y las credenciales para conectarse. Seleccione Conectar.
Repita los dos pasos anteriores para la instancia que vaya a contener una réplica de solo configuración u otra réplica secundaria.
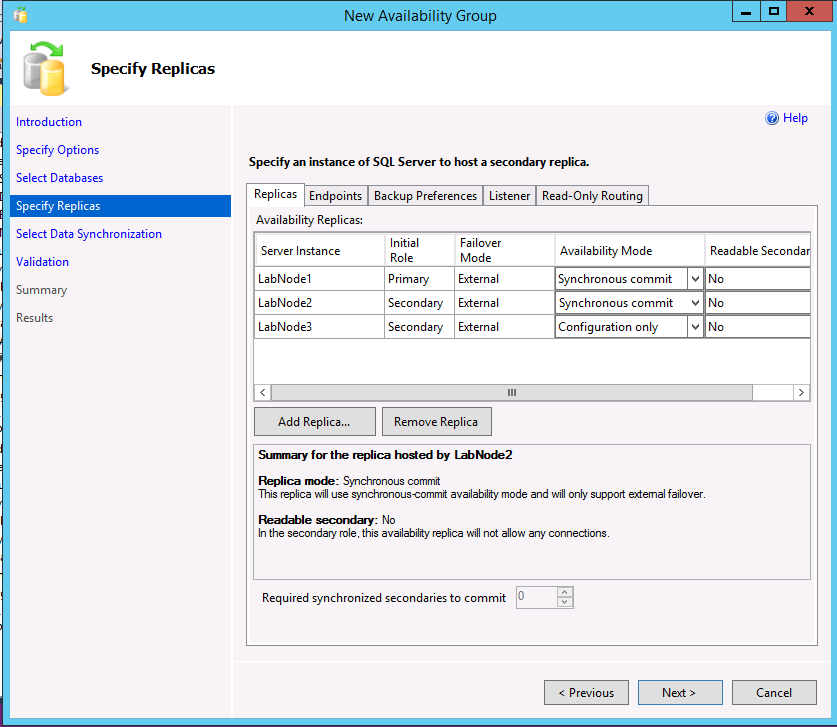
Las tres instancias ahora deben aparecer en el cuadro de diálogo Especificar réplicas. Si usa un tipo de clúster Externo, en la réplica secundaria que va a ser una secundaria verdadera, asegúrese de que el modo de disponibilidad coincida con el de la réplica principal y de que el modo de conmutación por error esté establecido en Externo. En el caso de la réplica de solo configuración, seleccione un modo de disponibilidad de solo configuración.
En el ejemplo siguiente se muestra un grupo de disponibilidad con dos réplicas, un tipo de clúster Externo y una réplica de solo configuración.
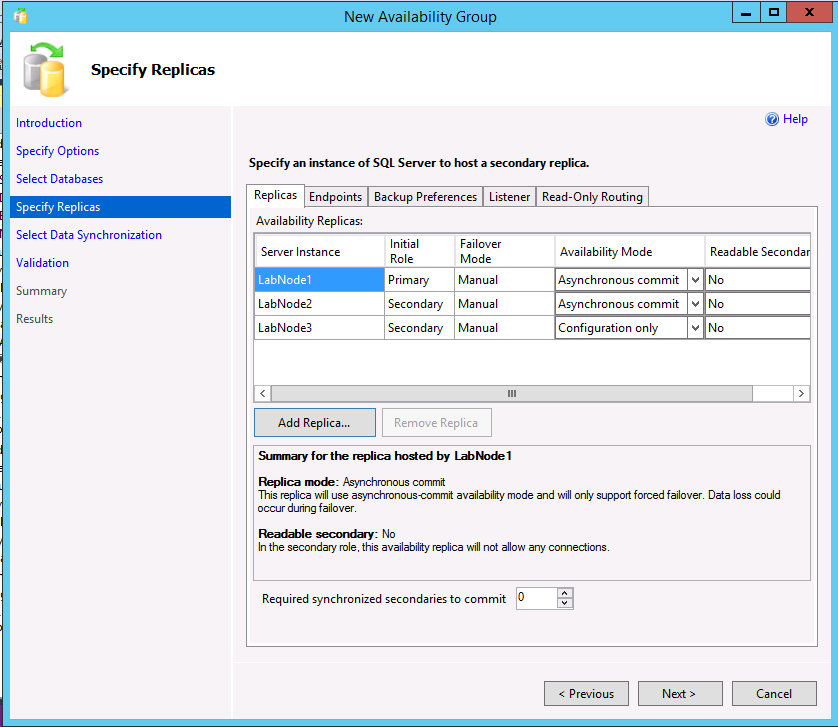
En el ejemplo siguiente se muestra un grupo de disponibilidad con dos réplicas, un tipo de clúster Ninguno y una réplica de solo configuración.
Si quiere modificar las preferencias de copia de seguridad, seleccione la pestaña Preferencias de copia de seguridad. Para obtener más información sobre las preferencias de copias de seguridad con grupos de disponibilidad, vea Configuración de copias de seguridad en réplicas secundarias de un grupo de disponibilidad Always On.
Si usa secundarias legibles o crea un grupo de disponibilidad con un tipo de clúster Ninguno para escalado de lectura, puede crear un cliente de escucha si selecciona la pestaña Agente de escucha. También se puede agregar un cliente de escucha más adelante. Para crear un cliente de escucha, seleccione la opción Crear un agente de escucha del grupo de disponibilidad y escriba un nombre, un puerto TCP/IP y si va a usar una dirección IP DHCP estática o asignada automáticamente. Recuerde que en un grupo de disponibilidad con un tipo de clúster Ninguno, la dirección IP debe ser estática y establecerse en la dirección IP del principal.
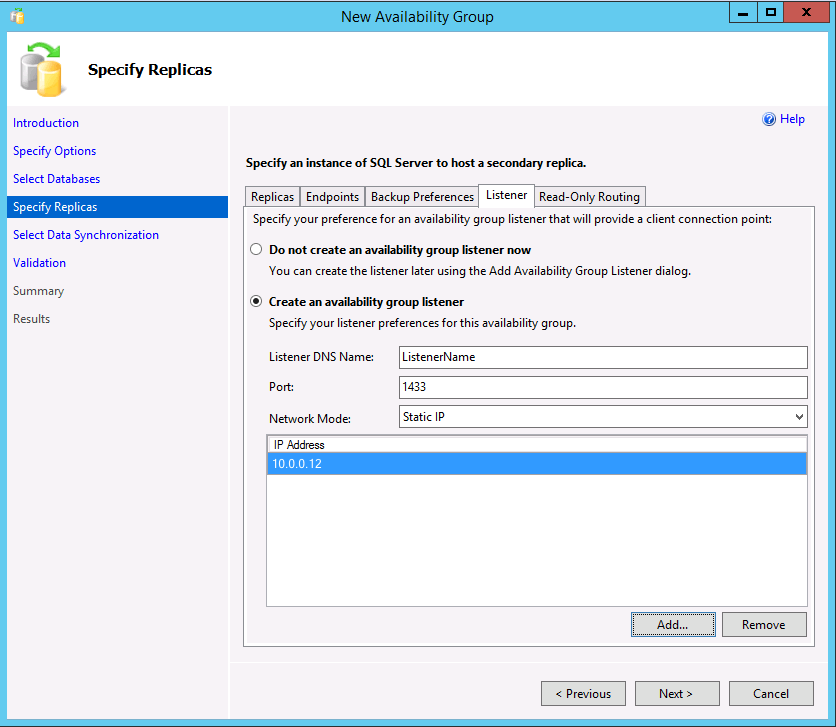
Si se crea un cliente de escucha para escenarios legibles, SSMS 17.3 o posterior permite la creación del enrutamiento de solo lectura en el asistente. También se puede agregar más adelante mediante SSMS o Transact-SQL. Para agregar enrutamiento de solo lectura ahora:
Seleccione la pestaña Enrutamiento de solo lectura.
Escriba las direcciones URL de las réplicas de solo lectura. Estas direcciones URL son similares a los puntos de conexión, salvo que usan el puerto de la instancia, no el punto de conexión.
Seleccione cada dirección URL y, en la parte inferior, seleccione las réplicas legibles. Para realizar una selección múltiple, mantenga presionada la tecla MAYÚS o seleccione y arrastre.
Seleccione Siguiente.
Elija cómo se van a inicializar las réplicas secundarias. El valor predeterminado es usar propagación automática, que requiere la misma ruta de acceso en todos los servidores que participan en el grupo de disponibilidad. También puede hacer que el asistente realice una copia de seguridad, copie y restaure (la segunda opción); la una si ha realizado una copia de seguridad de la base de datos, la ha copiado y restaurado manualmente en las réplicas (tercera opción); o agregue la base de datos más adelante (última opción). Al igual que con los certificados, si realiza copias de seguridad de forma manual y las copia, se deben establecer los permisos de los archivos de copia de seguridad en las otras réplicas. Seleccione Siguiente.
En el cuadro de diálogo Validación, si todo no se devuelve como Correcto, investigue. Algunas advertencias son aceptables y no son graves, por ejemplo si no se crea un cliente de escucha. Seleccione Siguiente.
En el cuadro de diálogo Resumen, seleccione Finalizar. El proceso de creación del grupo de disponibilidad ya comienza.
Una vez finalizada la creación del grupo de disponibilidad, seleccione Cerrar en los resultados. Ahora puede ver el grupo de disponibilidad en las réplicas en las vistas de administración dinámica y en la carpeta Alta disponibilidad de Always On de SSMS.




Uso de Transact-SQL
En esta sección se muestran ejemplos de creación de un grupo de disponibilidad mediante Transact-SQL. El cliente de escucha y el enrutamiento de solo lectura se pueden configurar una vez creado el grupo de disponibilidad. El propio grupo de disponibilidad se puede modificar con ALTER AVAILABILITY GROUP, pero el cambio de tipo de clúster no se puede realizar en SQL Server 2017 (14.x). Si no pretende crear un grupo de disponibilidad con un tipo de clúster Externo, debe eliminarlo y volver a crearlo con un tipo de clúster Ninguno. Puede encontrar más información y otras opciones en los vínculos siguientes:
- CREATE AVAILABILITY GROUP (Transact-SQL)
- ALTER AVAILABILITY GROUP (Transact-SQL)
- Configuración del enrutamiento de solo lectura para un grupo de disponibilidad Always On
- Configuración de un agente de escucha para un grupo de disponibilidad Always On
Ejemplo A: dos réplicas con una réplica de solo configuración (tipo de clúster Externo)
En este ejemplo se muestra cómo crear un grupo de disponibilidad de dos réplicas que use una réplica de solo configuración.
Ejecute en el nodo que vaya a ser la réplica principal que contiene la copia de lectura o escritura completa de las bases de datos. En este ejemplo se usa propagación automática.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE <DBName> REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N' TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', AVAILABILITY_MODE = CONFIGURATION_ONLY); GOEn una ventana de consulta conectada a la otra réplica, ejecute lo siguiente para unir la réplica al grupo de disponibilidad e iniciar el proceso de propagación desde la réplica principal a la secundaria.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GOEn una ventana de consulta conectada a la réplica de solo configuración, únala al grupo de disponibilidad.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO
Ejemplo B: tres réplicas con enrutamiento de solo lectura (tipo de clúster Externo)
En este ejemplo se muestran tres réplicas completas y cómo se puede configurar el enrutamiento de solo lectura como parte de la creación inicial del grupo de disponibilidad.
Ejecute en el nodo que vaya a ser la réplica principal que contiene la copia de lectura o escritura completa de las bases de datos. En este ejemplo se usa propagación automática.
CREATE AVAILABILITY GROUP [<AGName>] WITH (CLUSTER_TYPE = EXTERNAL) FOR DATABASE < DBName > REPLICA ON N'LinAGN1' WITH ( ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN2.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:1433') ), N'LinAGN2' WITH ( ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN3.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:1433') ), N'LinAGN3' WITH ( ENDPOINT_URL = N'TCP://LinAGN3.FullyQualified.Name:5022', FAILOVER_MODE = EXTERNAL, SEEDING_MODE = AUTOMATIC, AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = ( ( 'LinAGN1.FullyQualified.Name', 'LinAGN2.FullyQualified.Name' ) )), SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN3.FullyQualified.Name:1433') ) LISTENER '<ListenerName>' ( WITH IP = ('<IPAddress>', '<SubnetMask>'), Port = 1433 ); GOAlgunos aspectos que se deben tener en cuenta sobre esta configuración:
AGNamees el nombre del grupo de disponibilidad.DBNamees el nombre de la base de datos que se usa con el grupo de disponibilidad. También puede ser una lista de nombres separados por comas.ListenerNamees un nombre distinto a cualquiera de los servidores o nodos subyacentes. Se registra en DNS junto conIPAddress.IPAddresses una dirección IP asociada aListenerName. También es única y no es lo mismo que ninguno de los servidores o nodos. Las aplicaciones y los usuarios finales usanListenerNameoIPAddresspara conectarse al grupo de disponibilidad.SubnetMaskes la máscara de subred deIPAddress. En SQL Server 2019 (15.x) y versiones anteriores, es255.255.255.255. En SQL Server 2022 (16.x) y versiones posteriores, es0.0.0.0.
En una ventana de consulta conectada a la otra réplica, ejecute lo siguiente para unir la réplica al grupo de disponibilidad e iniciar el proceso de propagación desde la réplica principal a la secundaria.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = EXTERNAL); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GORepita el paso 2 para la tercera réplica.
Ejemplo C: dos réplicas con enrutamiento de solo lectura (tipo de clúster Ninguno)
En este ejemplo se muestra la creación de una configuración de dos réplicas con un tipo de clúster Ninguno. Se usa para el escenario de escalado de lectura donde no se espera conmutación por error. Crea el cliente de escucha que es realmente la réplica principal y el enrutamiento de solo lectura, con la funcionalidad round robin.
- Ejecute en el nodo que vaya a ser la réplica principal que contiene la copia de lectura o escritura completa de las bases de datos. En este ejemplo se usa propagación automática.
CREATE AVAILABILITY
GROUP [<AGName>]
WITH (CLUSTER_TYPE = NONE)
FOR DATABASE <DBName> REPLICA ON
N'LinAGN1' WITH (
ENDPOINT_URL = N'TCP://LinAGN1.FullyQualified.Name: <PortOfEndpoint>',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
PRIMARY_ROLE(
ALLOW_CONNECTIONS = READ_WRITE,
READ_ONLY_ROUTING_LIST = (('LinAGN1.FullyQualified.Name'.'LinAGN2.FullyQualified.Name'))
),
SECONDARY_ROLE(
ALLOW_CONNECTIONS = ALL,
READ_ONLY_ROUTING_URL = N'TCP://LinAGN1.FullyQualified.Name:<PortOfInstance>'
)
),
N'LinAGN2' WITH (
ENDPOINT_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfEndpoint>',
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC,
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
PRIMARY_ROLE(ALLOW_CONNECTIONS = READ_WRITE, READ_ONLY_ROUTING_LIST = (
('LinAGN1.FullyQualified.Name',
'LinAGN2.FullyQualified.Name')
)),
SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL, READ_ONLY_ROUTING_URL = N'TCP://LinAGN2.FullyQualified.Name:<PortOfInstance>')
),
LISTENER '<ListenerName>' (WITH IP = (
'<PrimaryReplicaIPAddress>',
'<SubnetMask>'),
Port = <PortOfListener>
);
GO
Donde:
AGNamees el nombre del grupo de disponibilidad.DBNamees el nombre de la base de datos que se va a usar con el grupo de disponibilidad. También puede ser una lista de nombres separados por comas.PortOfEndpointes el número de puerto que usa el punto de conexión creado.PortOfInstancees el número de puerto que usa la instancia de SQL Server.ListenerNamees un nombre distinto a cualquiera de las réplicas subyacentes, pero no se usa realmente.PrimaryReplicaIPAddresses la dirección IP de la réplica principal.SubnetMaskes la máscara de subred deIPAddress. En SQL Server 2019 (15.x) y versiones anteriores, es255.255.255.255. En SQL Server 2022 (16.x) y versiones posteriores, es0.0.0.0.
Una la réplica secundaria al grupo de disponibilidad e inicie la propagación automática.
ALTER AVAILABILITY GROUP [<AGName>] JOIN WITH (CLUSTER_TYPE = NONE); GO ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE; GO
Crear el inicio de sesión de SQL Server y los permisos para Pacemaker
Un clúster de alta disponibilidad de Pacemaker subyacente a SQL Server en Linux necesita acceso a la instancia de SQL Server y permisos en el propio grupo de disponibilidad. Estos pasos crean el inicio de sesión y los permisos asociados, junto con un archivo que indica a Pacemaker cómo iniciar sesión en SQL Server.
En una ventana de consulta conectada a la réplica principal, ejecute la siguiente secuencia de comandos:
CREATE LOGIN PMLogin WITH PASSWORD ='<StrongPassword>'; GO GRANT VIEW SERVER STATE TO PMLogin; GO GRANT ALTER, CONTROL, VIEW DEFINITION ON AVAILABILITY GROUP::<AGThatWasCreated> TO PMLogin; GOEn Nodo 1, escriba el comando
sudo emacs /var/opt/mssql/secrets/passwdAsí se abre el editor Emacs.
Escriba las dos líneas siguientes en el editor:
PMLogin <StrongPassword>Mantenga presionada la tecla
Ctrly presioneX; luegoC, para salir y guardar el archivo.Execute
sudo chmod 400 /var/opt/mssql/secrets/passwdpara bloquear el archivo.
Repita los pasos 1-5 en los otros servidores que vayan a actuar como réplicas.
Crear recursos de grupo de disponibilidad en el clúster de Pacemaker (solo Externo)
Después de crear un grupo de disponibilidad en SQL Server, se deben crear los recursos correspondientes en Pacemaker si se ha especificado un tipo de clúster Externo. Hay dos recursos asociados a un grupo de disponibilidad: el propio grupo de disponibilidad y una dirección IP. La configuración del recurso de dirección IP es opcional si no se usa la funcionalidad del cliente de escucha, pero se recomienda.
El recurso de grupo de disponibilidad que ha creado es un tipo de recurso denominado clon. El recurso de grupo de disponibilidad básicamente tiene copias en cada nodo y hay un recurso que controla denominado maestro. El maestro está asociado al servidor que hospeda la réplica principal. El resto de recursos hospedan réplicas secundarias (normales o de solo configuración) y se pueden promover a maestras en una conmutación por error.
Nota
Comunicación sin prejuicios
Este artículo contiene referencias al término esclavo, que Microsoft considera ofensivo cuando se usa en este contexto. El término aparece en este artículo porque actualmente aparece en el software. Cuando se quite el término del software, se quitará también del artículo.
Cree el recurso de grupo de disponibilidad con la siguiente sintaxis:
sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s --master meta notify=truedonde
NameForAGResourcees el nombre único asignado a este recurso de clúster para el grupo de disponibilidad yAGNamees el nombre del grupo de disponibilidad que se ha creado.En RHEL 7.7 y Ubuntu 18.04, y versiones posteriores, puede encontrar una advertencia con el uso de
--mastero un error comosqlag_monitor_0 on ag1 'not configured' (6): call=6, status=complete, exitreason='Resource must be configured with notify=true'. Para evitar esta situación:sudo pcs resource create <NameForAGResource> ocf:mssql:ag ag_name=<AGName> meta failure-timeout=30s master notify=trueCree el recurso de dirección IP para el grupo de disponibilidad que se va a asociar a la funcionalidad del cliente de escucha.
sudo pcs resource create <NameForIPResource> ocf:heartbeat:IPaddr2 ip=<IPAddress> cidr_netmask=<Netmask>donde
NameForIPResourcees el nombre único del recurso de IP yIPAddresses la dirección IP estática asignada al recurso.Para asegurarse de que la dirección IP y el recurso de grupo de disponibilidad se están ejecutando en el mismo nodo, debe configurarse una restricción de ubicación.
sudo pcs constraint colocation add <NameForIPResource> <NameForAGResource>-master INFINITY with-rsc-role=MasterDonde
NameForIPResourcees el nombre del recurso IP yNameForAGResourcees el nombre del recurso del grupo de disponibilidad.Cree una restricción de orden para asegurarse de que el recurso de grupo de disponibilidad está en funcionamiento antes que la dirección IP. Aunque la restricción de ubicación implica una restricción de orden, esto la aplica.
sudo pcs constraint order promote <NameForAGResource>-master then start <NameForIPResource>Donde
NameForIPResourcees el nombre del recurso IP yNameForAGResourcees el nombre del recurso del grupo de disponibilidad.
Paso siguiente
En este tutorial ha aprendido a crear y configurar un grupo de disponibilidad para SQL Server en Linux. Ha aprendido a:
- Habilitar grupos de disponibilidad.
- Crear puntos de conexión y certificados de grupo de disponibilidad.
- Usar SQL Server Management Studio (SSMS) o Transact-SQL para crear un grupo de disponibilidad.
- Crear el inicio de sesión de SQL Server y los permisos para Pacemaker.
- Crear recursos de grupo de disponibilidad en un clúster de Pacemaker.
Para la mayoría de las tareas de administración de grupos de disponibilidad, incluidas las actualizaciones y la conmutación por error, vea: