Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server 2016 (13.x) y versiones posteriores
SQL Server 2016 (13.x) y versiones posteriores ![]() de Azure SQL Managed Instance
de Azure SQL Managed Instance
En la parte tres de esta serie de tutoriales de cuatro partes, entrenará un modelo predictivo en R. En la siguiente parte de esta serie, implementará este modelo en una base de datos de SQL Server con Machine Learning Services o en clústeres de macrodatos.
En la parte tres de esta serie de tutoriales de cuatro partes, entrenará un modelo predictivo en R. En la siguiente parte de esta serie, implementará este modelo en una base de datos de SQL Server con Machine Learning Services.
En la parte tres de esta serie de tutoriales de cuatro partes, entrenará un modelo predictivo en R. En la siguiente parte de esta serie, implementará este modelo en una base de datos con SQL Server R Services.
En la parte tres de esta serie de tutoriales de cuatro partes, entrenará un modelo predictivo en R. En la siguiente parte de esta serie, implementará este modelo en una base de datos de Azure SQL Managed Instance con Machine Learning Services.
En este artículo, aprenderá a:
- Entrenar dos modelos de aprendizaje automático
- Hacer predicciones a partir de ambos modelos
- Comparar los resultados para elegir el modelo más preciso
En la primera parte, ha aprendido a restaurar la base de datos de ejemplo.
En la segunda parte, ha aprendido a cargar los datos de una base de datos en una trama de datos de Python y a preparar los datos en R.
En la parte cuatro, aprenderá a almacenar el modelo en una base de datos y, a continuación, a crear procedimientos almacenados a partir de los scripts de Python que desarrolló en las partes dos y tres. Los procedimientos almacenados se ejecutarán en el servidor para realizar predicciones basándose en datos nuevos.
Prerequisites
En la parte tres de esta serie de tutoriales se da por supuesto que ha cumplido los requisitos previos de la parte uno y ha completado los pasos de la segunda parte.
Entrenamiento de dos modelos
Para encontrar el mejor modelo para los datos de alquiler de esquís, cree dos modelos distintos (regresión lineal y árbol de decisión) y vea cuál es más preciso en sus predicciones. Deberá usar la trama de datos rentaldata que creó en la primera parte de esta serie.
#First, split the dataset into two different sets:
# one for training the model and the other for validating it
train_data = rentaldata[rentaldata$Year < 2015,];
test_data = rentaldata[rentaldata$Year == 2015,];
#Use the RentalCount column to check the quality of the prediction against actual values
actual_counts <- test_data$RentalCount;
#Model 1: Use lm to create a linear regression model, trained with the training data set
model_lm <- lm(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
#Model 2: Use rpart to create a decision tree model, trained with the training data set
library(rpart);
model_rpart <- rpart(RentalCount ~ Month + Day + WeekDay + Snow + Holiday, data = train_data);
Hacer predicciones a partir de ambos modelos
Use una función de predicción para predecir el número de alquileres con cada modelo entrenado.
#Use both models to make predictions using the test data set.
predict_lm <- predict(model_lm, test_data)
predict_lm <- data.frame(RentalCount_Pred = predict_lm, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
predict_rpart <- predict(model_rpart, test_data)
predict_rpart <- data.frame(RentalCount_Pred = predict_rpart, RentalCount = test_data$RentalCount,
Year = test_data$Year, Month = test_data$Month,
Day = test_data$Day, Weekday = test_data$WeekDay,
Snow = test_data$Snow, Holiday = test_data$Holiday)
#To verify it worked, look at the top rows of the two prediction data sets.
head(predict_lm);
head(predict_rpart);
Este es el conjunto de resultados.
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 27.45858 42 2 11 4 0 0
2 387.29344 360 3 29 1 0 0
3 16.37349 20 4 22 4 0 0
4 31.07058 42 3 6 6 0 0
5 463.97263 405 2 28 7 1 0
6 102.21695 38 1 12 2 1 0
RentalCount_Pred RentalCount Month Day WeekDay Snow Holiday
1 40.0000 42 2 11 4 0 0
2 332.5714 360 3 29 1 0 0
3 27.7500 20 4 22 4 0 0
4 34.2500 42 3 6 6 0 0
5 645.7059 405 2 28 7 1 0
6 40.0000 38 1 12 2 1 0
Comparación de los resultados
Ahora quiere ver cuál de los modelos ofrece las mejores predicciones. Una manera rápida y sencilla de hacerlo es usar una función de trazado básica para ver la diferencia entre los valores reales de los datos de entrenamiento y los valores previstos.
#Use the plotting functionality in R to visualize the results from the predictions
par(mfrow = c(1, 1));
plot(predict_lm$RentalCount_Pred - predict_lm$RentalCount, main = "Difference between actual and predicted. lm")
plot(predict_rpart$RentalCount_Pred - predict_rpart$RentalCount, main = "Difference between actual and predicted. rpart")
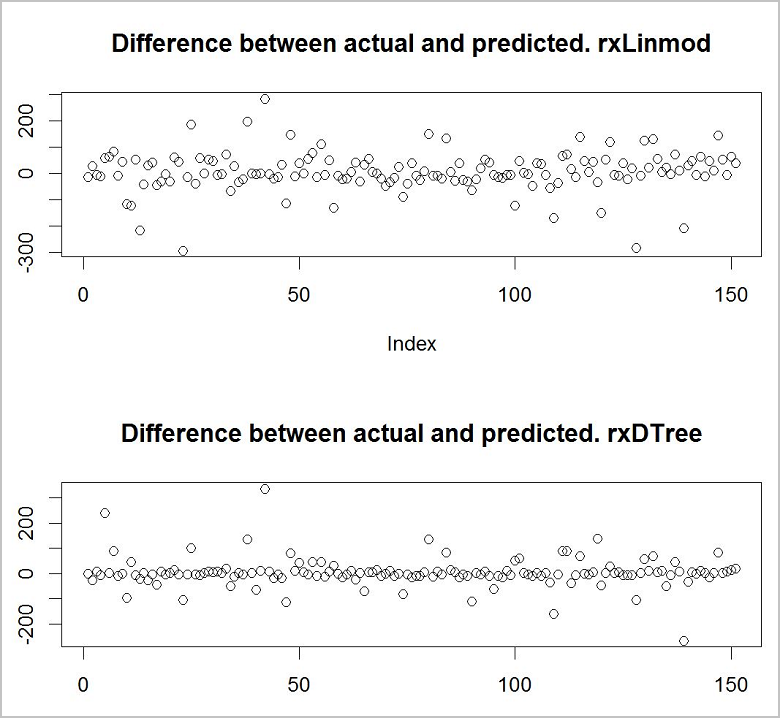
Parece que el modelo de árbol de decisión es el más preciso de los dos modelos.
Limpieza de recursos
Si no quiere continuar con este tutorial, elimine la base de datos TutorialDB.
Pasos siguientes
En la tercera parte de la serie de tutoriales, ha aprendido a:
- Entrenar dos modelos de aprendizaje automático
- Hacer predicciones a partir de ambos modelos
- Comparar los resultados para elegir el modelo más preciso
Para implementar el modelo de aprendizaje automático que ha creado, siga la parte cuatro de esta serie de tutoriales: