Diagnóstico y resolución de contenciones de bloqueos temporales en SQL Server
En esta guía se explica cómo identificar y resolver problemas de contención de bloqueos temporales observados al ejecutar aplicaciones de SQL Server en sistemas de alta simultaneidad con determinadas cargas de trabajo.
A medida que aumenta el número de núcleos de CPU en los servidores, el aumento asociado de simultaneidad puede agregar puntos de contención a las estructuras de datos a las que se debe acceder en serie en el motor de base de datos. Esto es especialmente cierto en el caso de las cargas de trabajo de procesamiento de transacciones (OLTP) de alta simultaneidad o alto rendimiento. Hay una serie de herramientas, técnicas y formas de abordar estos desafíos, así como procedimientos que se pueden seguir a la hora de diseñar aplicaciones, que pueden ayudar a evitarlos por completo. En este artículo se habla de un tipo determinado de contención en las estructuras de datos que usan bloqueos por subproceso para serializar el acceso a estas estructuras de datos.
Nota:
Este contenido fue escrito por el equipo de Microsoft SQL Server Customer Advisory Team (SQLCAT) tomando como base su proceso para identificar y resolver problemas relacionados con la contención de bloqueos temporales de página en aplicaciones de SQL Server en sistemas de alta simultaneidad. Las recomendaciones y los procedimientos recomendados que se documentan aquí se basan en la experiencia práctica durante el desarrollo y la implementación de sistemas de OLTP reales.
¿Qué es la contención de bloqueos temporales de SQL Server?
Los bloqueos temporales son primitivos de sincronización ligeros que usa el motor de SQL Server para garantizar la coherencia de las estructuras en memoria, lo que incluye índices, páginas de datos y estructuras internas, como páginas no hoja de un árbol B. SQL Server usa bloqueos temporales de búfer para proteger las páginas del grupo de búferes y bloqueos temporales de E/S para proteger las páginas que aún no se han cargado en él. Siempre que se escriben o se leen datos en una página del grupo de búferes de SQL Server, primero es necesario que un subroceso de trabajo adquiera un bloqueo temporal de búfer para la página. Hay varios tipos de bloqueos temporales de búfer disponibles para acceder a las páginas del grupo de búferes, que incluyen el bloqueo temporal exclusivo (PAGELATCH_EX) y el bloqueo temporal compartido (PAGELATCH_SH). Cuando SQL Server intenta acceder a una página que aún no está presente en el grupo de búferes, se publica una E/S asincrónica para cargar la página en él. Si SQL Server tiene que esperar a que el subsistema de E/S responda, espera un bloqueo temporal de E/S exclusivo (PAGEIOLATCH_EX) o compartido (PAGEIOLATCH_SH), en función del tipo de solicitud. Esto se hace para evitar que otro subproceso de trabajo cargue la misma página en el grupo de búferes con un bloqueo temporal no compatible. Los bloqueos temporales también se usan para proteger el acceso a estructuras de memoria internas distintas a las páginas del grupo de búferes; estos se conocen como bloqueos temporales no de búfer.
La contención en bloqueos temporales de página es el escenario más común en los sistemas de varias CPU y, por tanto, casi la totalidad de este artículo se va a centrar en ellos.
La contención de bloqueos temporales se produce cuando varios subprocesos intentan adquirir bloqueos temporales no compatibles de forma simultánea en la misma estructura en memoria. Dado que un bloqueo temporal es un mecanismo de control interno, el motor de SQL determina automáticamente cuándo se usan. Puesto que el comportamiento de los bloqueos temporales es determinista, las decisiones de aplicación, incluido el diseño de esquema, pueden afectar a este comportamiento. En este artículo se proporciona la siguiente información:
- Información básica sobre cómo usa SQL Server los bloqueos temporales.
- Herramientas usadas para investigar la contención de bloqueos temporales.
- Cómo determinar si la cantidad de contención que se observa es problemática.
Se van a tratar algunos escenarios comunes y cómo controlarlos mejor para aliviar la contención.
¿Cómo usa SQL Server los bloqueos temporales?
Una página de SQL Server ocupa 8 KB y puede almacenar varias filas. A fin de aumentar la simultaneidad y el rendimiento, los bloqueos temporales de búfer solo se mantienen mientras dura la operación física en la página, a diferencia de los bloqueos, que se mantienen durante la transacción lógica.
Los bloqueos temporales son internos del motor de SQL y se usan para proporcionar coherencia de memoria, mientras que SQL Server usa los bloqueos para proporcionar coherencia transaccional lógica. En la siguiente tabla se comparan los bloqueos temporales con los bloqueos:
| Estructura | Fin | Controlado por | Costo de rendimiento | Expuesto por |
|---|---|---|---|---|
| Bloqueo temporal | Garantizar la coherencia de las estructuras en memoria. | Solo el motor de SQL Server. | El costo de rendimiento es bajo. A fin de lograr la máxima simultaneidad y proporcionar el máximo rendimiento, los bloqueos temporales solo se mantienen mientras dura la operación física en la estructura en memoria, a diferencia de los bloqueos, que se mantienen durante la transacción lógica. | sys.dm_os_wait_stats (Transact-SQL): proporciona información sobre los tipos de espera PAGELATCH, PAGEIOLATCH y LATCH (LATCH_EX y LATCH_SH se usan para agrupar todos los tiempos de espera de bloqueo temporal no de búfer). sys.dm_os_latch_stats (Transact-SQL): proporciona información detallada sobre los tiempos de espera de bloqueo temporal no de búfer. sys.dm_db_index_operational_stats (Transact-SQL): esta DMV proporciona esperas agregadas de cada índice, lo que resulta útil para solucionar problemas de rendimiento relacionados con los bloqueos temporales. |
| Bloquear | Garantizar la coherencia de las transacciones. | Puede ser controlado por el usuario. | El costo de rendimiento es elevado con respecto a los bloqueos temporales, ya que los bloqueos se deben mantener mientras dura la transacción. | sys.dm_tran_locks (Transact-SQL). sys.dm_exec_sessions (Transact-SQL). |
Modos de bloqueo temporal de SQL Server y compatibilidad
Cierta contención de bloqueos temporales es de esperar como parte del funcionamiento normal del motor de SQL Server. Es inevitable que se produzcan varias solicitudes de bloqueo temporal simultáneas de distinta compatibilidad en un sistema de alta simultaneidad. SQL Server aplica la compatibilidad de los bloqueos temporales al exigir que las solicitudes de bloqueo temporal no compatibles esperen en una cola hasta que se completen las solicitudes de bloqueo temporal pendientes.
Los bloqueos temporales se adquieren de uno de cinco modos diferentes relacionados con el nivel de acceso. Los modos de bloqueo temporal de SQL Server se pueden resumir de la manera siguiente:
KP: bloqueo temporal de mantenimiento, que garantiza que la estructura a la que se hace referencia no se pueda destruir. Se usa cuando un subproceso quiere examinar una estructura de búfer. Dado que el bloqueo temporal de KP es compatible con todos los bloqueos temporales salvo el de destrucción (DT), se considera "ligero", lo que significa que el impacto sobre el rendimiento cuando se usa es mínimo. Puesto que el bloqueo temporal de KP no es compatible con el de DT, evita que cualquier otro subproceso destruya la estructura a la que se hace referencia. Por ejemplo, un bloqueo temporal de KP evita que el proceso de escritura diferida destruya la estructura a la que se hace referencia. Para obtener más información sobre cómo se usa el proceso de escritura diferida con la administración de páginas de búfer de SQL Server, vea Escribir páginas.
SH: bloqueo temporal compartido, necesario para leer la estructura a la que se hace referencia (por ejemplo, leer una página de datos). Varios subprocesos pueden acceder de forma simultánea a un recurso para leerlo bajo un bloqueo temporal compartido.
UP: bloqueo temporal de actualización, que es compatible con SH (bloqueo temporal compartido) y KP, pero no con otros y, por lo tanto, no permite que un bloqueo temporal de EX escriba en la estructura a la que se hace referencia.
EX: bloqueo temporal exclusivo, que evita que otros subprocesos escriban o lean en la estructura a la que se hace referencia. Un ejemplo de uso sería la modificación del contenido de una página para la protección contra página rasgada.
DT: bloqueo temporal de destrucción, que debe adquirirse antes de destruir contenido de la estructura a la que se hace referencia. Por ejemplo, el proceso de escritura diferida debe adquirir un bloqueo temporal de DT para liberar una página limpia antes de agregarla a la lista de búferes disponibles para su uso por parte de otros subprocesos.
Los modos de bloqueo temporal tienen distintos niveles de compatibilidad; por ejemplo, un bloqueo temporal compartido (SH) es compatible con uno de actualización (UP) o mantenimiento (KP), pero no con uno de destrucción (DT). Se pueden adquirir varios bloqueos temporales de forma simultánea en la misma estructura siempre que sean compatibles. Cuando un subproceso intenta adquirir un bloqueo temporal mantenido en un modo que no es compatible, se coloca en una cola para esperar una señal que indica que el recurso está disponible. Se usa un bloqueo por subproceso de tipo SOS_Task para proteger la cola de espera mediante la aplicación de acceso en serie a esta. Este bloqueo por subproceso debe adquirirse para agregar elementos a la cola. El bloqueo por subproceso SOS_Task también indica a los subprocesos de la cola cuándo se liberan bloqueos temporales no compatibles, lo que permite a los subprocesos en espera adquirir un bloqueo temporal compatible y seguir trabajando. La cola de espera se procesa mediante el sistema primero en entrar, primero en salir (FIFO) a medida que se liberan solicitudes de bloqueos temporales. Los bloqueos temporales siguen este sistema FIFO para garantizar la equidad y evitar el colapso de subprocesos.
En la tabla siguiente se muestra la compatibilidad de los modos de bloqueo temporal (Y indica compatibilidad y N indica no compatibilidad):
| Modo de bloqueo temporal | KP | SH | UP | EX | DT |
|---|---|---|---|---|---|
| KP | Y | Y | Y | Y | No |
| SH | Y | Y | Y | N | N |
| UP | Y | Y | N | N | N |
| EX | Y | N | N | N | N |
| DT | N | N | N | N | N |
SuperLatches y sub-bloqueos temporales de SQL Server
Con la presencia en aumento de sistemas de varios sockets o núcleos basados en NUMA, SQL Server 2005 presentó los SuperLatches, también conocidos como sub-bloqueos temporales, que solo son eficaces en sistemas con 32 procesadores lógicos o más. Los SuperLatches mejoran la eficacia del motor de SQL en determinados patrones de uso de cargas de trabajo de OLTP de alta simultaneidad; por ejemplo, cuando ciertas páginas tienen un patrón de acceso intensivo compartido (SH) de solo lectura, pero es raro que se escriban en ellas. Un ejemplo de página con este tipo de patrón de acceso es una página raíz de árbol B (es decir, índice); el motor de SQL requiere que se mantenga un bloqueo temporal compartido en la página raíz cuando se produce una división de página en cualquier nivel del árbol B. En una carga de trabajo de OLTP con gran cantidad de operaciones de inserción y alta simultaneidad, el número de divisiones de página aumenta en general en línea con el rendimiento, lo que puede degradar este. Los SuperLatches pueden aportar un mayor rendimiento para acceder a páginas compartidas en las que varios subprocesos de trabajo que se ejecutan simultáneamente requieren bloqueos temporales de SH. Para lograrlo, el motor de SQL Server promociona de forma dinámica un bloqueo temporal de una página de ese tipo a SuperLatch. Un SuperLatch particiona un bloqueo temporal único en una matriz de estructuras de sub-bloqueos temporales, un sub-bloqueo temporal por partición por núcleo de CPU, mientras que el bloqueo temporal principal se convierte en un redirector de proxy y la sincronización de estado global no es necesaria para los bloqueos temporales de solo lectura. Al hacerlo, el trabajo, que siempre se asigna a una CPU específica, solo necesita adquirir el sub-bloqueo temporal compartido (SH) asignado al programador local.
Nota:
La documentación utiliza el término árbol B generalmente en referencia a los índices. En los índices del almacén de filas, el motor de la base de datos implementa un árbol B+. Esto no se aplica a los índices de almacén de columnas ni a los índices de tablas optimizadas para memoria. Para obtener más información, consulte la guía de diseño y arquitectura de índices de SQL Server y Azure SQL.
La adquisición de bloqueos temporales compatibles, como un SuperLatch compartido, usa menos recursos y escala el acceso a las páginas activas mejor que un bloqueo temporal compartido sin particiones, ya que la eliminación del requisito de sincronización de estado global mejora considerablemente el rendimiento al acceder únicamente a la memoria NUMA local. Por el contrario, la adquisición de un SuperLatch exclusivo (EX) es más costosa que la de un bloqueo temporal normal de EX, ya que SQL debe señalar en todos los sub-bloqueos. Si se observa que un SuperLatch usa un patrón de acceso de EX intensivo, el motor de SQL puede degradarlo después de descartar la página del grupo de búferes. En el diagrama siguiente se muestran un bloqueo temporal normal y un SuperLatch con particiones:
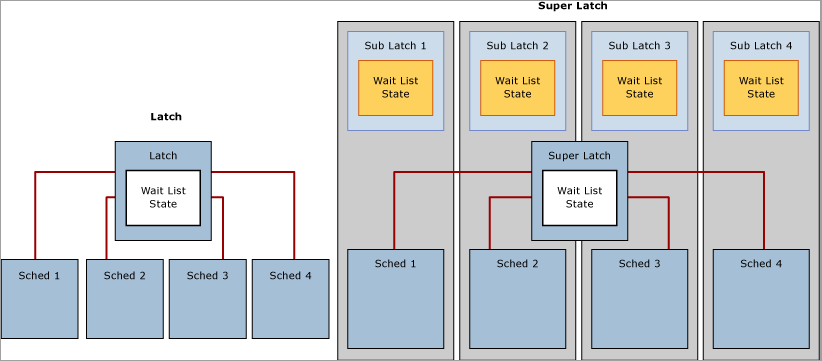
Use el objeto SQL Server:Latches y los contadores asociados del Monitor de rendimiento para recopilar información sobre los SuperLatches, incluido el número de ellos, las promociones por segundo y las degradaciones por segundo. Para obtener más información sobre el objeto SQL Server:Latches y los contadores asociados, vea Latches (objeto de SQL Server).
Tipos de tiempos de espera de bloqueo temporal
SQL Server realiza un seguimiento de la información de espera acumulada, a la que se puede acceder mediante la vista de administración dinámica (DMV) sys.dm_os_wait_stats. SQL Server emplea tres tipos de tiempos de espera de bloqueo temporal, tal como se define en el elemento wait_type correspondiente de la DMV sys.dm_os_wait_stats:
Bloqueo temporal de búfer (BUF): se usa para garantizar la coherencia de las páginas de datos y de índice de los objetos de usuario. También se usa para proteger el acceso a las páginas de datos que SQL Server usa para los objetos del sistema. Por ejemplo, las páginas que administran asignaciones están protegidas mediante bloqueos temporales de búfer. Estas incluyen páginas de Espacio disponible en páginas (PFS), Mapa de asignación global (GAM), Mapa de asignación global compartido (SGAM) y Mapa de asignación de índices (IAM). Los bloqueos temporales del búfer se notifican en
sys.dm_os_wait_statscon unwait_typede PAGELATCH_*.Bloqueo temporal no de búfer (no BUF): se usa para garantizar la coherencia de las estructuras en memoria que no son páginas del grupo de búferes. Cualquier espera de los bloqueos temporales sin búfer se notifica como un
wait_typede LATCH_*.Bloqueo temporal de E/S: subconjunto de bloqueos temporales de búfer que garantizan la coherencia de las mismas estructuras protegidas por los bloqueos temporales de búfer cuando estas estructuras necesitan cargarse en el grupo de búferes con una operación de E/S. Los bloqueos temporales de E/S evitan que otro subproceso cargue la misma página en el grupo de búferes con un bloqueo temporal no compatible. Asociado a un
wait_typede PAGEIOLATCH_*.Nota:
Si ve muchas esperas PAGEIOLATCH, eso significa que SQL Server está esperando al subsistema de E/S. Aunque es de esperar una cierta cantidad de esperas PAGEIOLATCH y es el comportamiento normal, si los tiempos de espera de PAGEIOLATCH medios suelen ser superiores a 10 milisegundos (ms), debe investigar por qué el subsistema de E/S está sometido a presión.
Al examinar la DMV sys.dm_os_wait_stats, si encuentra bloqueos temporales que no sean de búfer, se debe examinar sys.dm_os_latch_stats para obtener un desglose detallado de la información de espera acumulada de los bloqueos temporales que no sean de búfer. Todos los tiempos de espera de bloqueo temporal de búfer se clasifican en la clase de bloqueo temporal BUFFER; el resto se usa para clasificar los bloqueos temporales no de búfer.
Síntomas y causas de la contención de bloqueos temporales de SQL Server
En los sistemas de alta simultaneidad con mucha actividad, es normal observar contención activa en estructuras a las que se accede con frecuencia y que se protegen mediante bloqueos temporales y otros mecanismos de control de SQL Server. Se considera problemático si la contención y el tiempo de espera asociados a la adquisición de un bloqueo temporal para una página bastan para reducir el uso de recursos (CPU), lo que lastra el rendimiento.
Ejemplo de contención de bloqueos temporales
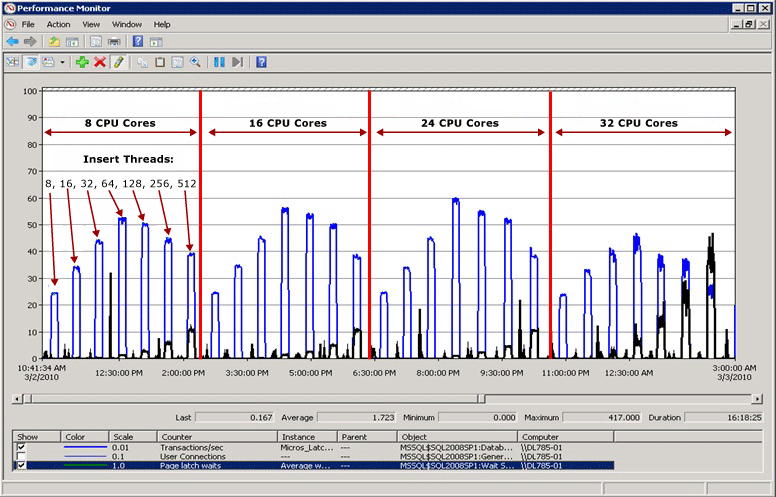
En el diagrama siguiente la línea azul representa el rendimiento de SQL Server medido en transacciones por segundo; la línea negra representa el tiempo de espera de bloqueo temporal de página medio. En este caso, cada transacción realiza una operación INSERT en un índice agrupado con un valor inicial que aumenta secuencialmente, como cuando se rellena una columna IDENTITY de tipo de datos bigint. A medida que el número de CPU aumenta hasta 32, resulta evidente que el rendimiento general ha disminuido y el tiempo de espera de bloqueo temporal de página ha aumentado a aproximadamente 48 milisegundos, como muestra la línea negra. Esta relación inversa entre rendimiento y tiempo de espera de bloqueo temporal de página es un escenario común que se diagnostica con facilidad.
Rendimiento al resolver la contención de bloqueos temporales
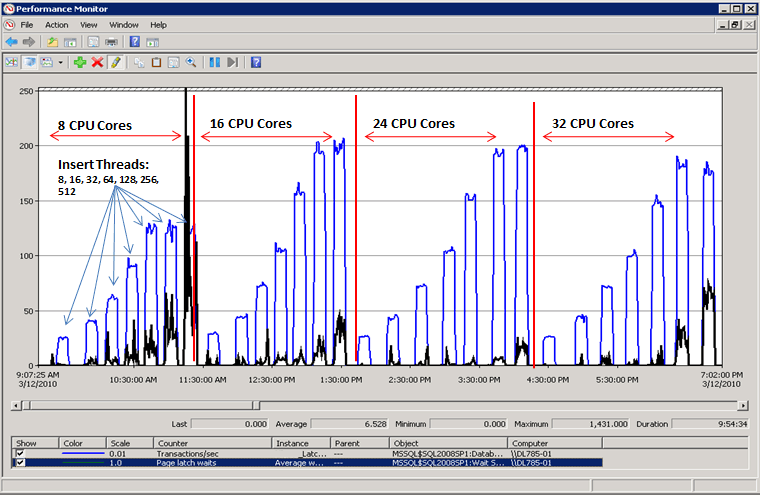
Como se muestra en el siguiente diagrama, SQL Server ya no tiene un cuello de botella en los tiempos de espera de bloqueo temporal de página y el rendimiento ha aumentado un 300 % medido en transacciones por segundo. Esto se ha conseguido con la técnica Uso de creación de particiones por hash con una columna calculada, que se explica más adelante en este artículo. Esta mejora del rendimiento está orientada a sistemas con un gran número de núcleos y un alto nivel de simultaneidad.
Factores que afectan a la contención de bloqueos temporales
La contención de bloqueos temporales que lastra el rendimiento en entornos de OLTP se debe normalmente a una alta simultaneidad relacionada con uno o varios de los siguientes factores:
| Factor | Detalles |
|---|---|
| Gran número de CPU lógicas usadas por SQL Server | La contención de bloqueos temporales puede producirse en cualquier sistema de varios núcleos. Según la experiencia de SQLCAT, la contención excesiva de bloqueos temporales que afecta al rendimiento de la aplicación más allá de los niveles aceptables se observa con más frecuencia en sistemas con más de 16 núcleos de CPU y puede aumentar a medida que hay más núcleos adicionales disponibles. |
| Diseño de esquemas y patrones de acceso | La profundidad del árbol B, el diseño de índices agrupados y no agrupados, el tamaño y la densidad de filas por página y los patrones de acceso (actividad de lectura, escritura y eliminación) son factores que pueden contribuir a una contención excesiva de bloqueos temporales de página. |
| Alto grado de simultaneidad en el nivel de aplicación | Normalmente, la contención excesiva de bloqueos temporales de página se produce en conjunción con un alto nivel de solicitudes simultáneas de la capa de aplicación. Existen determinados procedimientos de programación que también pueden incorporar un gran número de solicitudes para una página específica. |
| Diseño de archivos lógicos usados por las bases de datos de SQL Server | El diseño de archivos lógicos puede afectar al nivel de contención de bloqueos temporales de página causado por estructuras de asignación como las páginas de Espacio disponible en páginas (PFS), Mapa de asignación global (GAM), Mapa de asignación global compartido (SGAM) y Mapa de asignación de índices (IAM). Para obtener más información, vea Supervisión y solución de problemas de TempDB: Asignación de cuello de botella. |
| Rendimiento del subsistema de E/S | Muchas esperas PAGEIOLATCH indican que SQL Server está esperando al subsistema de E/S. |
Diagnóstico de la contención de bloqueos temporales de SQL Server
En esta sección se proporciona información para diagnosticar la contención de bloqueos temporales de SQL Server a fin de determinar si es problemática para el entorno.
Herramientas y métodos para diagnosticar la contención de bloqueos temporales
Las principales herramientas que se usan para diagnosticar la contención de bloqueos temporales son:
Monitor de rendimiento, para supervisar el uso de CPU y los tiempos de espera en SQL Server y establecer si existe una relación entre el uso de CPU y los tiempos de espera de bloqueo temporal.
DMV de SQL Server, que se pueden usar para determinar el tipo específico de bloqueo temporal que causa el problema y el recurso afectado.
En algunos casos se deben obtener volcados de memoria del proceso de SQL Server y analizarse con herramientas de depuración de Windows.
Nota:
Este nivel de solución avanzada de problemas normalmente solo es necesario al solucionar problemas de contención de bloqueos temporales no de búfer. Es posible que quiera ponerse en contacto con los servicios de soporte técnico de Microsoft para este tipo de solución avanzada de problemas.
El proceso técnico para diagnosticar la contención de bloqueos temporales se puede resumir en los pasos siguientes:
Determinar que existe contención que puede estar relacionada con un bloqueo temporal.
Use las vistas de DMV proporcionads en Anexo: scripts de contención de bloqueos temporales de SQL Server para determinar el tipo de bloqueo temporal y el/los recurso(s) afectados.
Aliviar la contención mediante alguna de las técnicas explicadas en Control de la contención de bloqueos temporales en diferentes patrones de tabla.
Indicadores de contención de bloqueos temporales
Como se ha indicado anteriormente, la contención de bloqueos temporales solo es problemática si la contención y el tiempo de espera asociados a la adquisición de bloqueos temporales de página evita que el rendimiento aumente cuando hay recursos de CPU disponibles. La determinación de una cantidad de contención aceptable requiere un enfoque holístico que tiene en cuenta los requisitos de rendimiento y los recursos de E/S y CPU disponibles. Esta sección sirve como guía a la hora de determinar el impacto de la contención de bloqueos temporales sobre la carga de trabajo de la manera siguiente:
Mida los tiempos de espera totales durante una prueba representativa.
Clasifíquelos en orden.
Determine la proporción de los que están relacionados con bloqueos temporales.
La información de espera acumulada está disponible en la DMV sys.dm_os_wait_stats. El tipo más común de contención de bloqueos temporales es el de búfer, que se observa como un aumento de los tiempos de espera de los bloqueos temporales con un elemento wait_type de *PAGELATCH_. Los bloqueos temporales sin búfer se agrupan bajo el tipo de espera LATCH*. Como se muestra en el diagrama siguiente, primero se debe echar un vistazo global a las esperas del sistema mediante la DMV sys.dm_os_wait_stats para determinar el porcentaje del tiempo de espera total causado por los bloqueos temporales de búfer o no de búfer. Si se detectan bloqueos temporales sin búfer, también se debe examinar la DMV sys.dm_os_latch_stats.
En el diagrama siguiente se describe la relación entre la información devuelta por las DMV sys.dm_os_wait_stats y sys.dm_os_latch_stats.

Para obtener más información sobre la DMV sys.dm_os_wait_stats, consulte sys.dm_os_wait_stats (Transact-SQL) en la ayuda de SQL Server.
Para obtener más información sobre la DMV sys.dm_os_latch_stats, consulte sys.dm_os_latch_stats (Transact-SQL) en la ayuda de SQL Server.
Las siguientes medidas de tiempo de espera de bloqueo temporal son indicadores de que una contención excesiva de bloqueos temporales está afectando al rendimiento de la aplicación:
El tiempo medio de espera de bloqueo temporal de páginas aumenta constantemente con el rendimiento: Si los tiempos de espera de bloqueo temporal de página medios aumentan sistemáticamente con el rendimiento y los tiempos de espera de bloqueo temporal de búfer también aumentan por encima de los tiempos de respuesta de disco esperados, se deben examinar las tareas actuales en espera mediante la DMV
sys.dm_os_waiting_tasks. Las medias pueden ser engañosas si se analizan por separado, así que es importante examinar el sistema en activo cuando sea posible para entender las características de la carga de trabajo. En concreto, compruebe si hay altas esperas de solicitudes PAGELATCH_EX o PAGELATCH_SH en cualquier página. Siga estos pasos para diagnosticar un aumento del tiempo de espera de bloqueo temporal de página medio con el rendimiento:- Use los scripts de ejemplo de Consulta de sys.dm_os_waiting_tasks ordenada por identificador de sesión o Cálculo de esperas a lo largo de un período de tiempo para examinar las tareas en espera actuales y medir el tiempo de espera de bloqueo temporal medio.
- Use el script de ejemplo de Consulta de los descriptores del búfer para determinar los objetos que causan la contención de bloqueos temporales para determinar el índice y la tabla subyacente donde se produce la contención.
- Mida el tiempo de espera de bloqueo temporal de página medio con el contador del Monitor de rendimiento MSSQL%InstanceName%\Wait Statistics\Page Latch Waits\Average Wait Time o mediante la ejecución de la DMV
sys.dm_os_wait_stats.
Nota:
Para calcular el tiempo de espera medio de un tipo de espera determinado (devuelto por
sys.dm_os_wait_statscomo wt_:type), divida el tiempo de espera total (devuelto comowait_time_ms) por el número de tareas en espera (devueltas comowaiting_tasks_count).Porcentaje del tiempo total de espera dedicado a los tipos de espera de enganche durante los picos de carga: Si el tiempo de espera de bloqueo temporal medio como porcentaje del tiempo de espera total aumenta en línea con la carga de la aplicación, la contención de bloqueos temporales puede afectar al rendimiento y debe investigarse.
Mida los tiempos de espera de bloqueo temporal de página y los que no son de página con los contadores de rendimiento de Wait Statistics (objeto de SQL Server). Luego compare los valores de estos contadores de rendimiento con los contadores de rendimiento asociados al rendimiento de CPU, E/S, memoria y red. Por ejemplo, transacciones/s y solicitudes por lotes/s son dos buenas medidas de uso de recursos.
Nota:
El tiempo de espera relativo de cada tipo de espera no se incluye en la DMV
sys.dm_os_wait_stats, ya que esta DMV mide los tiempos de espera desde la última vez que se inició la instancia de SQL Server o se restablecieron las estadísticas de espera acumuladas mediante DBCC SQLPERF. Para calcular el tiempo de espera relativo de cada tipo de espera, tome una instantánea desys.dm_os_wait_statsantes de la carga máxima, después de esta y calcule la diferencia. El script de ejemplo de Cálculo de esperas a lo largo de un período de tiempo puede usarse para este fin.Exclusivamente en el caso de un entorno que no sea de producción, borre la DMV
sys.dm_os_wait_statscon el siguiente comando:dbcc SQLPERF ('sys.dm_os_wait_stats', 'CLEAR')Se puede ejecutar un comando similar para borrar la DMV
sys.dm_os_latch_stats:dbcc SQLPERF ('sys.dm_os_latch_stats', 'CLEAR')El rendimiento no aumenta, y en algunos casos disminuye, a medida que aumentan la carga de la aplicación y el número de CPU disponibles en SQL Server: esto se muestra en el Ejemplo de contención del bloqueo temporal.
La utilización de la CPU no aumenta a medida que aumenta la carga de trabajo de la aplicación: Si el uso de CPU en el sistema no aumenta a medida que lo hace la simultaneidad basada en el rendimiento de la aplicación, eso es un indicador de que SQL Server está esperando algo y es síntoma de contención de bloqueos temporales.
Analice la causa principal. Aunque se cumplan todas las condiciones anteriores, es posible que la causa principal de los problemas de rendimiento sea otra. De hecho, en la mayoría de los casos, el uso poco óptimo de CPU se debe a otros tipos de esperas, como el bloqueo en bloqueos, las esperas relacionadas con E/S o problemas relacionados con la red. Como regla general, siempre es mejor resolver la espera de recurso que representa la mayor parte del tiempo de espera total antes de continuar con un análisis más exhaustivo.
Análisis de bloqueos temporales de búfer de espera actuales
La contención de bloqueos temporales de búfer se manifiesta como aumento de los tiempos de espera de los bloqueos temporales con un elemento wait_type de PAGELATCH_* o PAGEIOLATCH_*, como se muestra en la DMV sys.dm_os_wait_stats. Para examinar el sistema en tiempo real, ejecute la siguiente consulta en un sistema para unir las DMV sys.dm_os_wait_stats, sys.dm_exec_sessions y sys.dm_exec_requests. Los resultados se pueden usar para determinar el tipo de espera actual de las sesiones que se ejecutan en el servidor.
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc
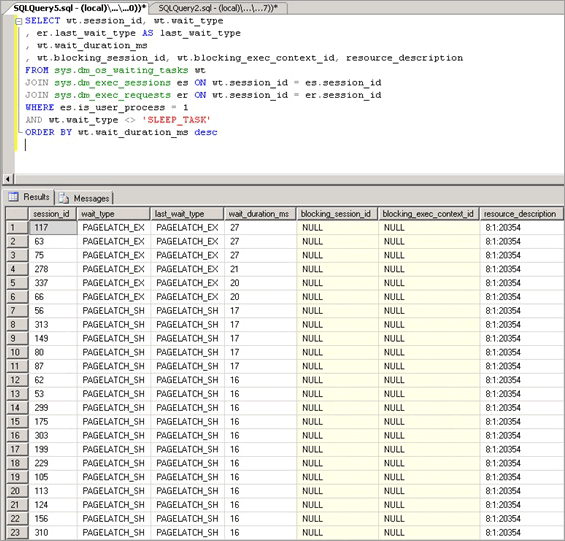
Las estadísticas expuestas por esta consulta se describen de la siguiente manera:
| Estadísticas | Descripción |
|---|---|
| Session_id | Id. de la sesión asociada a la tarea. |
| Wait_type | Tipo de espera que SQL Server ha registrado en el motor, que evita que se ejecute una solicitud actual. |
| Last_wait_type | Si esta solicitud se ha bloqueado anteriormente, esta columna devuelve el tipo de la última espera. No admite valores NULL. |
| Wait_duration_ms | Tiempo de espera total en milisegundos que se ha dedicado a esperar este tipo de espera desde que se inició la instancia de SQL Server o desde que se restablecieron las estadísticas de espera acumuladas. |
| Blocking_session_id | Id. de la sesión que bloquea la solicitud. |
| Blocking_exec_context_id | Id. del contexto de ejecución asociado a la tarea. |
| Resource_description | En la columna resource_description se indica la página exacta que se espera en el formato <database_id>:<file_id>:<page_id>. |
La siguiente consulta devuelve información sobre todos los bloqueos temporales no de búfer:
select * from sys.dm_os_latch_stats where latch_class <> 'BUFFER' order by wait_time_ms desc;
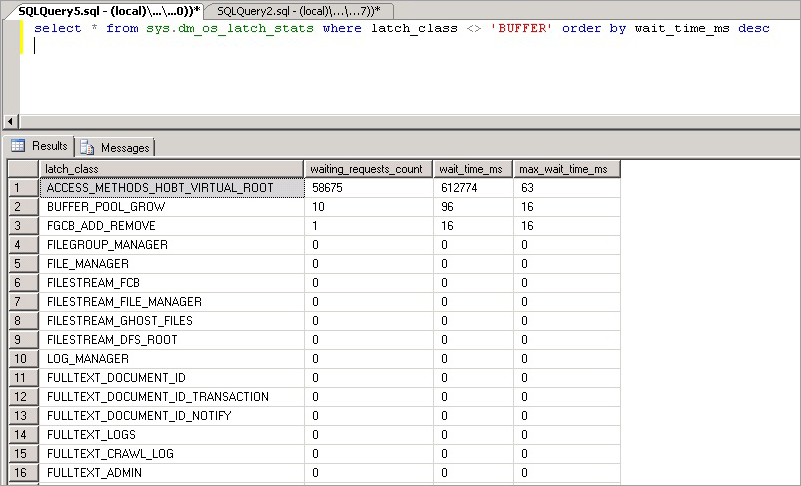
Las estadísticas expuestas por esta consulta se describen de la siguiente manera:
| Estadísticas | Descripción |
|---|---|
| latch_class | Tipo de bloqueo temporal que SQL Server ha registrado en el motor, que evita que se ejecute una solicitud actual. |
| waiting_requests_count | Número de esperas de bloqueos temporales en esta clase desde que se reinició SQL Server. Este recuento se incrementa al inicio de una espera de bloqueo temporal. |
| wait_time_ms | Tiempo de espera total en milisegundos que se ha dedicado a esperar este tipo de bloqueo temporal. |
| max_wait_time_ms | Tiempo máximo en milisegundos que cualquier solicitud ha dedicado a esperar este tipo de bloqueo temporal. |
Nota:
Los valores devueltos por esta DMV son acumulados desde la última vez que se reinició el motor de base de datos o se restableció la DMV. Use la columna sqlserver_start_time en sys.dm_os_sys_info para encontrar la hora del último inicio del motor de base de datos. En un sistema que se ha estado ejecutando durante mucho tiempo, esto significa que algunas estadísticas como max_wait_time_ms suelen ser útiles. El siguiente comando se puede usar para restablecer las estadísticas de espera de esta DMV:
DBCC SQLPERF ('sys.dm_os_latch_stats', CLEAR);
Escenarios de contención de bloqueos temporales de SQL Server
Se ha observado que los siguientes escenarios causan una contención excesiva de bloqueos temporales.
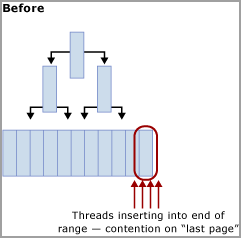
Contención de inserción de última o primera página
Un procedimiento común de OLTP es crear un índice agrupado en una columna de identidad o de fecha. Esto ayuda a mantener una buena organización física del índice, lo que puede beneficiar considerablemente al rendimiento de las lecturas y escrituras en el índice. Pero este diseño de esquema puede dar lugar sin querer a la contención de bloqueos temporales. Este problema se observa más frecuentemente con una tabla grande, con filas pequeñas, e inserciones en un índice que contiene una columna de clave inicial que aumenta secuencialmente, como una clave datetime o de entero ascendente. En este escenario, la aplicación casi nunca realiza actualizaciones o eliminaciones; la excepción son las operaciones de archivado.
En el ejemplo siguiente, el subproceso uno y el dos quieren realizar la inserción de un registro que se va a almacenar en la página 299. Desde la perspectiva de un bloqueo lógico no hay ningún problema, ya que se van a usar bloqueos de nivel de fila y se pueden mantener bloqueos exclusivos en ambos registros en la misma página a la vez. Pero para garantizar la integridad de la memoria física, solo un subproceso cada vez puede adquirir un bloqueo temporal exclusivo, así que se serializa el acceso a la página para evitar que se pierdan actualizaciones en memoria. En este caso, el subproceso 1 adquiere el bloqueo temporal exclusivo y el subproceso 2 espera, lo que registra una espera PAGELATCH_EX de este recurso en las estadísticas de espera. Esto se muestra a través del valor wait_type de la DMV sys.dm_os_waiting_tasks.
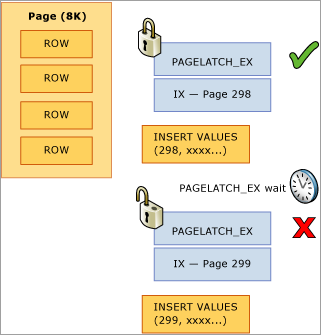
Esta contención se conoce normalmente como contención de "inserción de última página", porque se produce en el extremo derecho del árbol B, como se muestra en el diagrama siguiente:
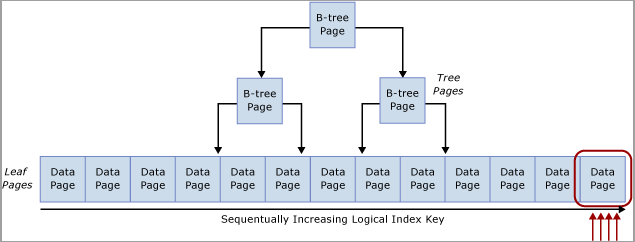
Este tipo de contención de bloqueos temporales puede explicarse del modo siguiente. Cuando se inserta una nueva fila en un índice, SQL Server usa el siguiente algoritmo para ejecutar la modificación:
Recorre el árbol B para buscar la página correcta para contener el nuevo registro.
Bloquea temporalmente la página con PAGELATCH_EX, lo que evita que otros la modifiquen, y adquiere bloqueos temporales compartidos (PAGELATCH_SH) en todas las páginas no hoja.
Nota:
En algunos casos, el motor de SQL también necesita que se adquieran bloqueos temporales de EX en páginas no hoja del árbol B. Por ejemplo, cuando se produce una división de página, las páginas que se van a ver afectadas directamente deben bloquearse temporal y exclusivamente (PAGELATCH_EX).
Registra una entrada de registro de que se ha modificado la fila.
Agrega la fila a la página y marca esta como desfasada.
Desbloquea temporalmente todas las páginas.
Si el índice de la tabla se basa en una clave que aumenta secuencialmente, cada nueva inserción va a la misma página del final del árbol B, hasta que está llena. En escenarios de alta simultaneidad esto puede provocar contención en el extremo derecho del árbol B, y puede ocurrir en índices agrupados y no agrupados. Las tablas afectadas por este tipo de contención aceptan fundamentalmente operaciones INSERT, y las páginas de los índices problemáticos suelen ser relativamente densas (por ejemplo, un tamaño de fila ~165 bytes (incluida la sobrecarga de fila) es igual a ~49 filas por página). En este ejemplo de inserción intensiva se espera que se produzcan esperas PAGELATCH_EX/PAGELATCH_SH, y esta es la observación típica. Para examinar las esperas de bloqueo temporal de página frente a esperas de bloqueo temporal de página de árbol, use la DMV sys.dm_db_index_operational_stats.
En la tabla siguiente se resumen los principales factores observados con este tipo de contención de bloqueos temporales:
| Factor | Observaciones típicas |
|---|---|
| CPU lógicas usadas por SQL Server | Este tipo de contención de bloqueos temporales se produce principalmente en sistemas de más de 16 núcleos de CPU y, con más frecuencia, en sistemas de más de 32 núcleos de CPU. |
| Diseño de esquemas y patrones de acceso | Usa un valor de identidad que aumenta secuencialmente como columna inicial de un índice en una tabla de datos transaccionales. El índice tiene una clave principal que aumenta con una alta tasa de inserciones. El índice tiene al menos un valor de columna que aumenta secuencialmente. Normalmente tiene un tamaño de fila pequeño con muchas filas por página. |
| Tipo de espera observado | Muchos subprocesos que compiten por el mismo recurso con tiempos de espera de bloqueo temporal exclusivo (EX) o compartido (SH) asociados al mismo elemento resource_description de la DMV sys.dm_os_waiting_tasks devueltos por la Consulta de sys.dm_os_waiting_tasks ordenada por duración de espera. |
| Factores de diseño que se deben tener en cuenta | Considere la posibilidad de cambiar el orden de las columnas del índice como se explica en la estrategia de mitigación de índices no secuenciales si puede garantizar que las inserciones se van a distribuir por todo el árbol B de manera uniforme a lo largo del tiempo. Si se usa la estrategia de mitigación de particiones hash, se pierde la capacidad de usar particiones para cualquier otro propósito, como el archivado de ventana deslizante. El uso de la estrategia de mitigación de particiones hash puede provocar problemas de eliminación de particiones en las consultas SELECT empleadas por la aplicación. |
Contención de bloqueos temporales en tablas pequeñas con un índice no agrupado e inserciones aleatorias (tabla de cola)
Este escenario se suele ver cuando se usa una tabla SQL como una cola temporal (por ejemplo, en un sistema de mensajería asincrónico).
En este escenario puede producirse contención de bloqueos temporales exclusivos (EX) y compartidos (SH) en las siguientes condiciones:
- Se producen operaciones de inserción, selección, actualización o eliminación en situaciones de alta simultaneidad.
- El tamaño de fila es relativamente pequeño (lo que da lugar a páginas densas).
- El número de filas de la tabla es relativamente pequeño, lo que dar lugar a un árbol B superficial, definido por una profundidad de índice de dos o tres.
Nota:
Incluso los árboles B con mayor profundidad que esta pueden experimentar contención con este tipo de patrón de acceso si la frecuencia de lenguaje de manipulación de datos (DML) y simultaneidad del sistema es lo suficientemente alta. El nivel de contención de bloqueos temporales puede agravarse a medida que la simultaneidad aumenta si hay 16 núcleos de CPU disponibles en el sistema o más.
La contención de bloqueos temporales puede producirse incluso si el acceso es aleatorio en el árbol B, como cuando una columna no secuencial es la clave inicial de un índice agrupado. La captura de pantalla siguiente corresponde a un sistema que experimenta este tipo de contención de bloqueos temporales. En este ejemplo, la contención se debe a la densidad de las páginas provocada por un tamaño de fila pequeño y un árbol B relativamente superficial. A medida que aumenta la simultaneidad, se produce contención de bloqueos temporales en las páginas, aunque las inserciones son aleatorias en el árbol B, dado que un GUID era la columna inicial del índice.
En la siguiente captura de pantalla, las esperas se producen tanto en las páginas de datos de búfer como en las páginas de Espacio libre en páginas (PFS). Para obtener más información sobre la contención de bloqueos temporales de página de PFS, vea la siguiente entrada de blog de un tercero en SQLSkills: Evaluación comparativa: Múltiples archivos de datos en unidades SSD. Incluso al aumentar el número de archivos de datos, la contención de bloqueos temporales es frecuente en las páginas de datos de búfer.
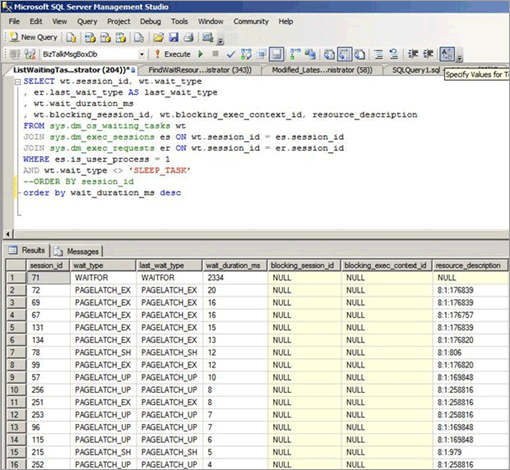
En la tabla siguiente se resumen los principales factores observados con este tipo de contención de bloqueos temporales:
| Factor | Observaciones típicas |
|---|---|
| CPU lógicas usadas por SQL Server | La contención de bloqueos temporales se produce principalmente en equipos con más de 16 núcleos de CPU. |
| Diseño de esquemas y patrones de acceso | Alta tasa de patrones de acceso de inserción/selección/actualización/eliminación en tablas pequeñas. Árbol B superficial (profundidad de índice de dos o tres). Tamaño de fila pequeño (muchos registros por página). |
| Nivel de simultaneidad | La contención de bloqueos temporales solo se va a producir con niveles altos de solicitudes simultáneas de la capa de aplicación. |
| Tipo de espera observado | Observe las esperas de bloqueo temporal de búfer (PAGELATCH_EX y PAGELATCH_SH) y no búfer ACCESS_METHODS_HOBT_VIRTUAL_ROOT debido a divisiones de raíz. PAGELATCH_UP también espera páginas de PFS. Para obtener más información sobre los tiempos de espera de bloqueo temporal no de búfer, vea sys.dm_os_latch_stats (Transact-SQL) en la ayuda de SQL Server. |
La combinación de un árbol B superficial e inserciones aleatorias en el índice es susceptible de provocar divisiones de página en el árbol B. Para realizar una división de página, SQL Server debe adquirir bloqueos temporales compartidos (SH) en todos los niveles y luego adquirir bloqueos temporales exclusivos (EX) en las páginas del árbol B que participan en las divisiones de página. Además, si la simultaneidad es alta y se insertan y eliminan datos continuamente, pueden producirse divisiones raíz del árbol B. En este caso, es posible que otras inserciones tengan que esperar a que se hayan adquirido bloqueos temporales no de búfer en el árbol B. Esto se manifiesta como un gran número de esperas del tipo de bloqueo temporal ACCESS_METHODS_HOBT_VIRTUAL_ROOT en la DMV sys.dm_os_latch_stats.
El siguiente script se puede modificar para determinar la profundidad del árbol B de los índices en la tabla afectada.
select o.name as [table],
i.name as [index],
indexProperty(object_id(o.name), i.name, 'indexDepth')
+ indexProperty(object_id(o.name), i.name, 'isClustered') as depth, --clustered index depth reported doesn't count leaf level
i.[rows] as [rows],
i.origFillFactor as [fillFactor],
case (indexProperty(object_id(o.name), i.name, 'isClustered'))
when 1 then 'clustered'
when 0 then 'nonclustered'
else 'statistic'
end as type
from sysIndexes i
join sysObjects o on o.id = i.id
where o.type = 'u'
and indexProperty(object_id(o.name), i.name, 'isHypothetical') = 0 --filter out hypothetical indexes
and indexProperty(object_id(o.name), i.name, 'isStatistics') = 0 --filter out statistics
order by o.name;
Contención de bloqueos temporales en páginas de Espacio disponible en páginas (PFS)
PFS significa Espacio disponible en páginas, SQL Server asigna una página de PFS por cada 8088 páginas (que empiezan por PageID = 1) de cada archivo de base de datos. Cada byte de la página de PFS registra información que incluye la cantidad de espacio disponible en la página, si está asignada o no y si la página almacena registros fantasma. La página de PFS contiene información sobre las páginas disponibles para asignar cuando una operación de inserción o actualización necesita una nueva página. La página de PFS debe actualizarse en una serie de escenarios que incluyen cuando se producen asignaciones o desasignaciones. Dado que se requiere el uso de un bloqueo temporal de actualización (UP) para proteger la página de PFS, puede producirse contención de bloqueos temporales en páginas de PFS si se tienen relativamente pocos archivos de datos en un grupo de archivos y un gran número de núcleos de CPU. Una manera sencilla de resolver esto es aumentar el número de archivos por grupo de archivos.
Advertencia
El aumento del número de archivos por grupo de archivos puede afectar negativamente al rendimiento de determinadas cargas, como aquellas con muchas operaciones de ordenación de gran tamaño que pierden memoria en disco.
Si se observan muchas esperas PAGELATCH_UP de páginas de PFS o SGAM en tempdb, siga estos pasos para eliminar este cuello de botella:
Agregue archivos de datos a tempdb para que el número de archivos de datos de tempdb sea igual al número de núcleos de procesador del servidor.
Habilite la marca de seguimiento 1118 de SQL Server.
Para obtener más información sobre los cuellos de botella de asignación causados por la contención en páginas del sistema, vea la entrada de blog ¿Qué es un cuello de botella de asignación?
Funciones con valores de tabla y contención de bloqueos temporales en tempdb
Hay otros factores más allá de la contención de asignación que pueden generar contención de bloqueos temporales en tempdb, como el uso intensivo de TVF en las consultas.
Control de la contención de bloqueos temporales en diferentes patrones de tabla
En las secciones siguientes se explican técnicas que se pueden usar para solucionar problemas de rendimiento relacionados con la contención excesiva de bloqueos temporales.
Uso de una clave de índice inicial no secuencial
Un método para controlar la contención de bloqueos temporales es reemplazar una clave de índice secuencial por una clave no secuencial a fin de distribuir uniformemente las inserciones en un intervalo de índices.
Normalmente, esto se hace con una columna inicial del índice que distribuye la carga de trabajo de forma proporcional. Hay un par de opciones para ello:
Opción: Empleo de una columna de la tabla para distribuir valores en el intervalo de claves de índice
Evalúe la carga de trabajo para obtener un valor natural que se pueda usar para distribuir las inserciones en el intervalo de claves. Por ejemplo, imagine un escenario de cajero automático de un banco donde ATM_ID puede ser un buen candidato para distribuir las inserciones en una tabla de transacciones de retiradas, ya que un cliente solo puede usar un cajero cada vez. Del mismo modo, en un sistema de puntos de venta, quizás Checkout_ID o un identificador de tienda sería un valor natural que podría usarse para distribuir inserciones en un intervalo de claves. Esta técnica exige la creación de una clave de índice compuesta donde la columna de clave inicial es el valor de la columna identificada o algún hash de ese valor combinado con una o más columnas adicionales para proporcionar exclusividad. En la mayoría de los casos, un hash del valor funciona mejor, porque demasiados valores distintos dan lugar a una mala organización física. Por ejemplo, en un sistema de puntos de venta, se puede crear un hash a partir del identificador de tienda, que es un módulo que se alinea con el número de núcleos de CPU. Esta técnica produciría un número relativamente pequeño de intervalos dentro de la tabla, pero sería suficiente para distribuir las inserciones de manera que se evitara la contención de bloqueos temporales. En la imagen siguiente se muestra esta técnica.
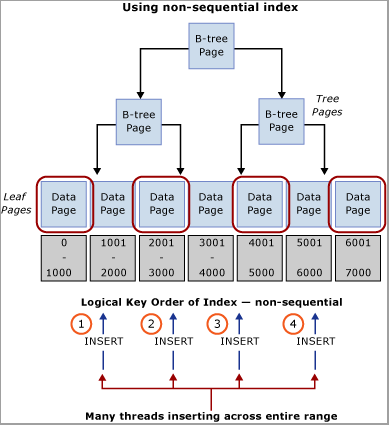
Importante
Este patrón contradice los procedimientos recomendados de indexación tradicionales. Aunque esta técnica ayuda a garantizar una distribución uniforme de las inserciones en el árbol B, también puede requerir un cambio de esquema en el nivel de aplicación. Además, este patrón puede afectar negativamente al rendimiento de las consultas que requieren exámenes de intervalo que usan el índice agrupado. Se necesita cierto análisis de los patrones de carga de trabajo para determinar si este enfoque de diseño va a funcionar bien. Este patrón se debe implementar si es posible sacrificar algún rendimiento de examen secuencial para obtener rendimiento de inserción y escala.
Este patrón se implementó durante una interacción de laboratorio de rendimiento y resolvió la contención de bloqueos temporales en un sistema con 32 núcleos de CPU físicos. La tabla se usó para almacenar el saldo final al término de una transacción; cada transacción empresarial realizó una única inserción en la tabla.
Definición de tabla original
Al usar la definición de tabla original, se observó una contención excesiva de bloqueos temporales en el índice agrupado pk_table1:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (TransactionID, UserID);
go
Nota:
Los nombres de objetos de la definición de tabla han cambiado con respecto a sus valores originales.
Definición de índice reordenado
El volver a ordenar las columnas de clave del índice con UserID como columna inicial de la clave principal proporcionó una distribución casi aleatoria de inserciones en las páginas. La distribución resultante no fue un 100 % aleatoria, ya que no todos los usuarios se conectan al mismo tiempo, pero la distribución fue lo suficientemente aleatoria como para aliviar la contención excesiva de bloqueos temporales. Un riesgo de la reordenación de la definición de índice es que todas las consultas SELECT de esta tabla deben modificarse para usar UserID y TransactionID como predicados de igualdad.
Importante
Asegúrese de probar exhaustivamente los cambios en un entorno de prueba antes de ejecutar en un entorno de producción.
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
alter table table1
add constraint pk_table1
primary key clustered (UserID, TransactionID);
go
Uso de un valor hash como columna inicial de la clave principal
La siguiente definición de tabla se puede usar para generar un módulo que se alinea con el número de CPU; HashValue se genera mediante el valor TransactionID que aumenta secuencialmente para garantizar una distribución uniforme en el árbol B:
create table table1
(
TransactionID bigint not null,
UserID int not null,
SomeInt int not null
);
go
-- Consider using bulk loading techniques to speed it up
ALTER TABLE table1
ADD [HashValue] AS (CONVERT([tinyint], abs([TransactionID])%(32))) PERSISTED NOT NULL
alter table table1
add constraint pk_table1
primary key clustered (HashValue, TransactionID, UserID);
go
Opción: Uso de un GUID como columna de clave inicial del índice
Si no hay ningún separador natural, se puede usar una columna de GUID como columna de clave inicial del índice para garantizar la distribución uniforme de las inserciones. Aunque el uso del GUID como columna inicial en el enfoque de clave de índice permite el empleo de particiones para otras características, esta técnica también puede incorporar los posibles inconvenientes de más divisiones de página, una mala organización física y bajas densidades de página.
Nota:
El uso de GUID como columnas de clave iniciales de índices es un tema muy debatido. El debate detallado de las ventajas e inconvenientes de este método queda fuera del ámbito de este artículo.
Uso de creación de particiones por hash con una columna calculada
La creación de particiones de tabla de SQL Server se puede usar para mitigar la contención excesiva de bloqueos temporales. La creación de un esquema de creación de particiones por hash con una columna calculada en una tabla con particiones es un enfoque común que se puede lograr con estos pasos:
Cree un nuevo grupo de archivos o use uno existente para almacenar las particiones.
Si usa un grupo de archivos nuevo, equilibre equitativamente los archivos individuales en LUN, con cuidado de usar un diseño óptimo. Si el patrón de acceso conlleva una alta tasa de inserciones, asegúrese de crear el mismo número de archivos que de núcleos de CPU físicos en el equipo de SQL Server.
Use el comando CREATE PARTITION FUNCTION para particionar las tablas en X particiones, donde X es el número de núcleos de CPU físicos del equipo de SQL Server. (Hasta 32 particiones como mínimo)
Nota:
No siempre se necesita una alineación 1:1 del número de particiones con el número de núcleos de CPU. En muchos casos, puede ser algún valor menor que el número de núcleos de CPU. El hecho de tener más particiones puede suponer una mayor sobrecarga para las consultas que tienen que buscar en todas las particiones y, en estos casos, ayuda el tener menos particiones. En las pruebas de SQLCAT con sistemas de 64 y 128 CPU lógicas con particiones de 32 cargas de trabajo de clientes reales, las particiones han sido suficientes para resolver la contención excesiva de bloqueos temporales y alcanzar los objetivos de escala. En última instancia, el número ideal de particiones se debe determinar mediante pruebas.
Use el comando CREATE PARTITION SCHEME:
- Enlace la función de partición a los grupos de archivos.
- Agregue una columna hash de tipo tinyint o smallint a la tabla.
- Calcule una buena distribución de hash. Por ejemplo, use hashbytes con módulo o binary_checksum.
El siguiente script de ejemplo puede personalizarse para los fines de la implementación:
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Este script se puede usar para crear particiones por hash en una tabla que está experimentando problemas causados por Contención de inserción de última o primera página. Esta técnica mueve la contención de la última página al crear particiones en la tabla y distribuir las inserciones entre las particiones de tabla con una operación de módulo de valor hash.
Efecto de la creación de particiones por hash con una columna calculada
Como se muestra en el siguiente diagrama, esta técnica mueve la contención de la última página al recompilar el índice en la función hash y crear el mismo número de particiones que de núcleos de CPU físicos en el equipo de SQL Server. Las inserciones continúan hasta el final del intervalo lógico (un valor que aumenta secuencialmente), pero la operación de módulo de valor hash garantiza que se dividan entre los diferentes árboles B, lo que alivia el cuello de botella. Esto se muestra en los diagramas siguientes:
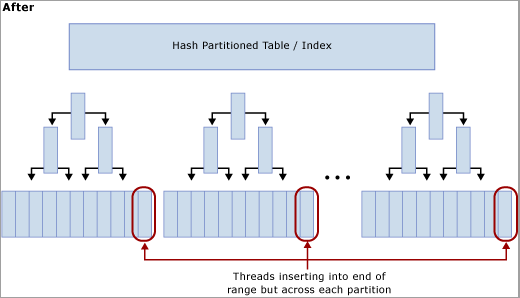
Ventajas e inconvenientes del uso de la creación de particiones por hash
Aunque la creación de particiones por hash puede eliminar la contención en las inserciones, hay varias ventajas y desventajas que se deben sopesar a la hora de decidir si se va a usar esta técnica:
En la mayoría de los casos, las consultas de selección se deben modificar para incluir la partición hash en el predicado y dan lugar a un plan de consulta que no proporciona ninguna eliminación de particiones cuando se emiten estas consultas. En la captura de pantalla siguiente se muestra un plan incorrecto sin eliminación de particiones después de implementar la creación de particiones por hash.
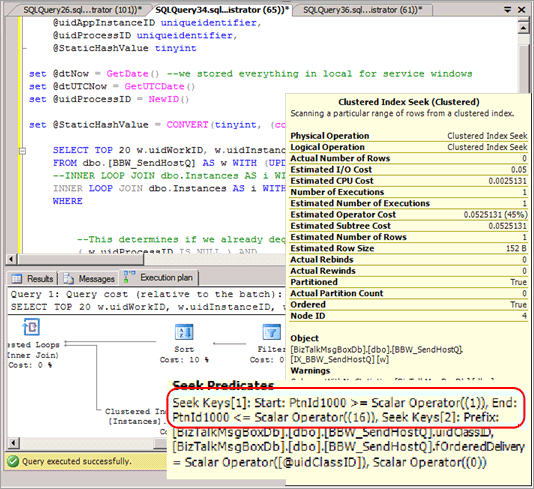
Elimina la posibilidad de que se produzca eliminación de particiones en algunas otras consultas, como los informes basados en intervalos.
Al combinar una tabla con particiones hash con otra tabla, a fin de lograr la eliminación de particiones, se deben crear particiones por hash en la segunda tabla conforme a la misma clave y la clave hash debe formar parte de los criterios de combinación.
La creación de particiones por hash evita el uso de particiones para otras características de administración como el archivado de ventana deslizante y la funcionalidad de conmutación de particiones.
La creación de particiones por hash es una estrategia eficaz para mitigar la contención excesiva de bloqueos temporales, ya que aumenta el rendimiento general del sistema al aliviar la contención en las inserciones. Dado que conlleva algunas ventajas e inconvenientes, puede no ser la solución óptima para algunos patrones de acceso.
Resumen de las técnicas usadas para solucionar la contención de bloqueos temporales
En las dos secciones siguientes se proporciona un resumen de las técnicas que se pueden usar para hacer frente a la contención excesiva de bloqueos temporales:
Índice o clave no secuencial
Ventajas:
- Permite el uso de otras características de creación de particiones, como el archivado de datos mediante un esquema de ventana deslizante y la funcionalidad de conmutación de particiones.
Desventajas:
- Posibles desafíos a la hora de elegir una clave o un índice para garantizar una distribución prácticamente uniforme de las inserciones en todo momento.
- Se puede usar el GUID como columna inicial para garantizar una distribución uniforme, con el riesgo de que puede dar lugar a operaciones de división de página excesivas.
- Las inserciones aleatorias en el árbol B pueden generar demasiadas operaciones de división de página y dar lugar a la contención de bloqueos temporales en páginas no hoja.
Creación de particiones por hash con una columna calculada
Ventajas:
- Es transparente para las inserciones.
Desventajas:
- Las particiones no se pueden usar para características de administración previstas como el archivado de datos mediante opciones de conmutación de particiones.
- Puede causar problemas de eliminación de particiones en las consultas, incluidas las consultas de selección o actualización individuales y basadas en intervalos y aquellas que realizan una combinación.
- La incorporación de una columna calculada persistente es una operación sin conexión.
Sugerencia
Para conocer técnicas adicionales, vea la entrada de blog Esperas PAGELATCH_EX e inserciones intensivas.
Tutorial: Diagnóstico de una contención de bloqueos temporales
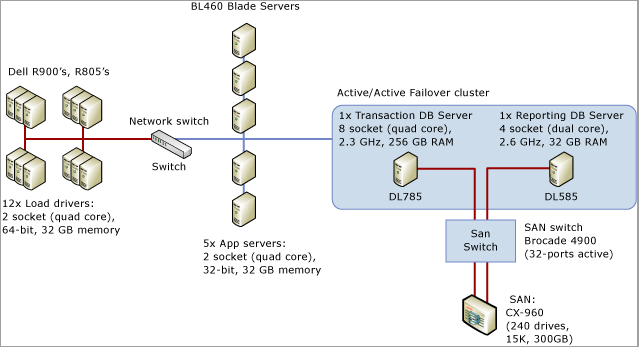
En el siguiente tutorial se muestran las herramientas y técnicas descritas en Diagnóstico de la contención de bloqueos temporales de SQL Server y Control de la contención de bloqueos temporales en diferentes patrones de tabla para resolver un problema en un escenario real. En este escenario se describe una interacción de cliente para realizar la prueba de carga de un sistema de puntos de venta que simulaba aproximadamente 8000 tiendas que realizaban transacciones en una aplicación de SQL Server que se ejecutaba en un sistema de 32 núcleos físicos de 8 sockets con 256 GB de memoria.
En el siguiente diagrama se detalla el hardware empleado para probar el sistema de puntos de venta:
Síntoma: bloqueos temporales frecuentes
En este caso se han observado altas esperas de PAGELATCH_EX, donde normalmente altas se define como una media de más de 1 ms. En este caso se han observado esperas que superan los 20 ms sistemáticamente.
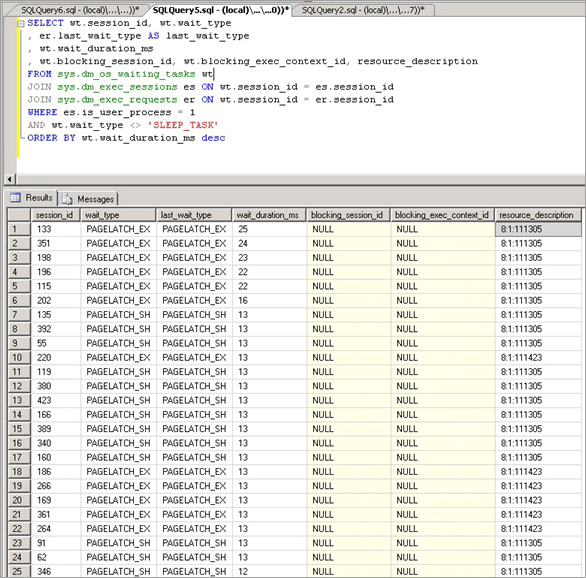
Una vez que se ha determinado que la contención de bloqueos temporales es problemática, se va a determinar lo que causa la contención de bloqueos temporales.
Aislamiento del objeto que causa la contención de bloqueos temporales
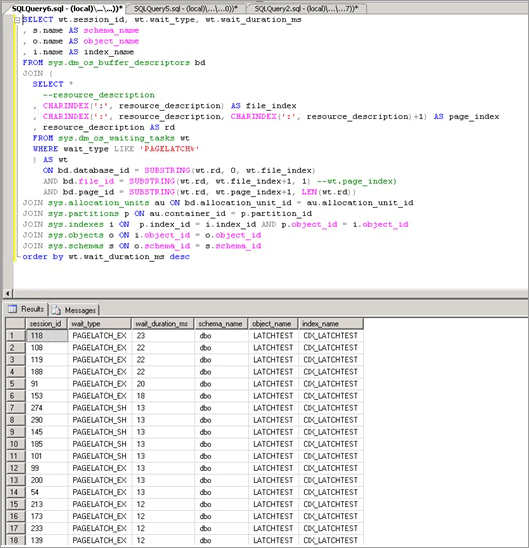
El siguiente script usa la columna resource_description para aislar el índice que está causando la contención PAGELATCH_EX:
Nota:
La columna resource_description devuelta por este script proporciona la descripción del recurso en el formato <DatabaseID,FileID,PageID>, donde se puede determinar el nombre de la base de datos asociada a DatabaseID si se pasa el valor de DatabaseID a la función DB_NAME ().
SELECT wt.session_id, wt.wait_type, wt.wait_duration_ms
, s.name AS schema_name
, o.name AS object_name
, i.name AS index_name
FROM sys.dm_os_buffer_descriptors bd
JOIN (
SELECT *
--resource_description
, CHARINDEX(':', resource_description) AS file_index
, CHARINDEX(':', resource_description, CHARINDEX(':', resource_description)+1) AS page_index
, resource_description AS rd
FROM sys.dm_os_waiting_tasks wt
WHERE wait_type LIKE 'PAGELATCH%'
) AS wt
ON bd.database_id = SUBSTRING(wt.rd, 0, wt.file_index)
AND bd.file_id = SUBSTRING(wt.rd, wt.file_index+1, 1) --wt.page_index)
AND bd.page_id = SUBSTRING(wt.rd, wt.page_index+1, LEN(wt.rd))
JOIN sys.allocation_units au ON bd.allocation_unit_id = au.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
order by wt.wait_duration_ms desc;
Como se muestra aquí, la contención está en la tabla LATCHTEST y el nombre de índice CIX_LATCHTEST. Observe que los nombres se han cambiado para garantizar el anonimato de la carga de trabajo.
Para obtener un script más avanzado que sondea repetidamente y usa una tabla temporal para determinar el tiempo de espera total durante un período configurable, vea Consulta de los descriptores del búfer para determinar los objetos que causan la contención de bloqueos temporales en el apéndice.
Técnica alternativa para aislar el objeto que causa la contención de bloqueos temporales
A veces, puede resultar poco práctico consultar sys.dm_os_buffer_descriptors. A medida que la memoria del sistema disponible para el grupo de búferes aumenta, lo hace el tiempo necesario para ejecutar esta DMV. En un sistema de 256 GB, esta DMV puede tardar hasta 10 minutos o más en ejecutarse. Hay una técnica alternativa disponible que se ha ejecutado en el laboratorio, que, en general, se describe del modo siguiente y se muestra con otra carga de trabajo:
Consulte las tareas en espera actuales mediante el script del apéndice Consulta de sys.dm_os_waiting_tasks ordenada por duración de espera.
Identifique la página principal en la que se observa un convoy, lo que sucede cuando varios subprocesos compiten en la misma página. En este ejemplo, los subprocesos que realizan la inserción están compitiendo en la página final del árbol B y van a esperar hasta que puedan adquirir un bloqueo temporal EX. Esto se indica mediante resource_description en la primera consulta, en este caso 8:1:111305.
Habilite la marca de seguimiento 3604, que expone más información sobre la página mediante DBCC PAGE con la siguiente sintaxis, sustituya el valor obtenido mediante resource_description por el valor entre paréntesis:
--enable trace flag 3604 to enable console output dbcc traceon (3604); --examine the details of the page dbcc page (8,1, 111305, -1);Examine la salida de DBCC. Debe haber un elemento ObjectID de metadatos asociado, en este caso "78623323".
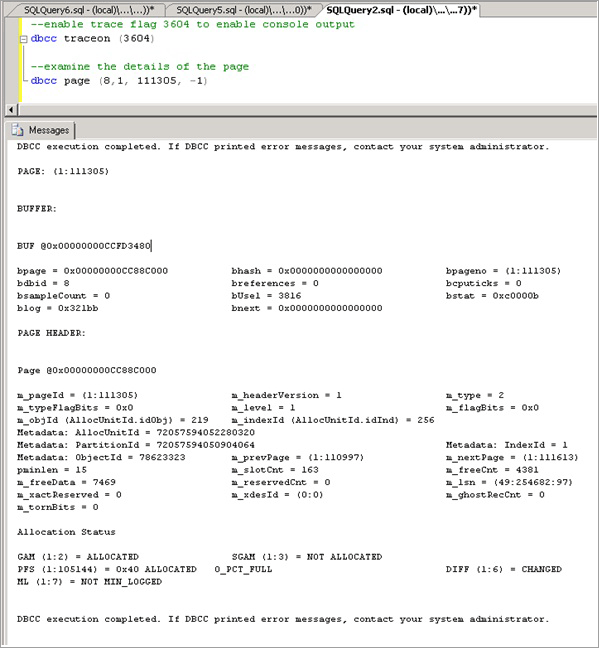
Ahora se puede ejecutar el siguiente comando para determinar el nombre del objeto que causa la contención, que, como se esperaba, es LATCHTEST.
Nota:
Asegúrese de que está en el contexto de base de datos correcto; de lo contrario, la consulta devuelve NULL.
--get object name select OBJECT_NAME (78623323);
Resumen y resultados
Mediante la técnica anterior se ha podido confirmar que la contención se estaba produciendo en un índice agrupado con un valor de clave que aumentaba secuencialmente en la tabla que con diferencia recibía el mayor número de inserciones. Este tipo de contención no es rara en los índices con un valor de clave que aumenta secuencialmente como datetime, identity o transactionID generado por la aplicación.
Para resolver este problema, se ha usado la Creación de particiones por hash con una columna calculada y se ha observado una mejora del rendimiento del 690 %. En la tabla siguiente se resume el rendimiento de la aplicación antes y después de implementar la creación de particiones por hash con una columna calculada. El uso de CPU aumenta en gran medida en línea con el rendimiento según lo esperado después de eliminar el cuello de botella de contención de bloqueos temporales:
| Medida | Antes de la creación de particiones por hash | Después de la creación de particiones por hash |
|---|---|---|
| Transacciones empresariales/s | 36 | 249 |
| Tiempo de espera de bloqueo temporal de página medio | 36 milisegundos | 0,6 milisegundos |
| Tiempos de espera de bloqueo temporal/s | 9562 | 2873 |
| Tiempo de procesador SQL | 24% | 78 % |
| Solicitudes por lotes de SQL/s | 12 368 | 47 045 |
Como se puede ver en la tabla anterior, identificar y resolver correctamente los problemas de rendimiento causados por una contención excesiva de bloqueos temporales de página puede tener un impacto positivo sobre el rendimiento general de la aplicación.
Anexo: Técnica alternativa
Una posible estrategia para evitar la contención excesiva de bloqueos temporales de página es rellenar las filas con una columna CHAR para asegurarse de que cada fila use una página completa. Esta estrategia es una opción cuando el tamaño total de los datos es pequeño y se necesita solucionar la contención de bloqueos temporales de página EX debida a la siguiente combinación de factores:
- Tamaño de fila pequeño
- Árbol B superficial
- Patrón de acceso con una alta tasa de operaciones de inserción, selección, actualización y eliminación aleatorias
- Tablas pequeñas, como las tablas de colas temporales
Al rellenar las filas para que ocupen una página completa, necesita que SQL asigne páginas adicionales, lo que hace que haya más páginas disponibles para las inserciones y reduce la contención de bloqueos temporales de página EX.
Relleno de filas para garantizar que cada fila ocupe una página completa
Se puede usar un script similar al siguiente para rellenar las filas de modo que ocupen una página completa:
ALTER TABLE mytable ADD Padding CHAR(5000) NOT NULL DEFAULT ('X');
Nota:
Use el char más pequeño posible que fuerce una fila por página para reducir los requisitos de CPU adicionales de valor de relleno y espacio adicional necesarios para registrar la fila. Cada byte cuenta en un sistema de alto rendimiento.
Esta técnica se ha explicado para ofrecer una visión completa; en la práctica, SQLCAT solo la ha usado en una tabla pequeña con 10 000 filas en una única interacción de rendimiento. Esta técnica tiene un uso limitado porque aumenta la presión de la memoria sobre SQL Server en tablas grandes y puede dar lugar a la contención de bloqueos temporales no de búfer en páginas no hoja. La presión de memoria adicional puede ser un factor limitador importante para la aplicación de esta técnica. Con la cantidad de memoria disponible en un servidor moderno, una gran proporción del espacio de trabajo para cargas de trabajo de OLTP normalmente se mantiene en memoria. Cuando el conjunto de datos aumenta hasta un tamaño que ya no cabe en la memoria, se produce un descenso significativo del rendimiento. Por lo tanto, esta técnica es algo que solo se aplica a tablas pequeñas. SQLCAT no usa esta técnica en escenarios como la contención de inserción de última o primera página en tablas grandes.
Importante
El empleo de esta estrategia puede generar un gran número de esperas del tipo de bloqueo temporal ACCESS_METHODS_HOBT_VIRTUAL_ROOT, ya que esta estrategia puede dar lugar a un gran número de divisiones de página que se producen en los niveles no hoja del árbol B. Si ocurre esto, SQL Server debe adquirir bloqueos temporales compartidos (SH) en todos los niveles seguidos de bloqueos temporales exclusivos (EX) en las páginas del árbol B donde sea posible una división de página. Busque una gran número de esperas del tipo de bloqueo temporal ACCESS_METHODS_HBOT_VIRTUAL_ROOT tras el relleno de filas en la DMV sys.dm_os_latch_stats.
Anexo: Scripts de contención de bloqueos temporales de SQL Server
Esta sección contiene scripts que se pueden usar para ayudar a diagnosticar y solucionar problemas de contención de bloqueos temporales.
Consulta de sys.dm_os_waiting_tasks ordenada por Id. de sesión
El siguiente script de ejemplo consulta sys.dm_os_waiting_tasks y devuelve los tiempos de espera de bloqueo temporal ordenados por identificador de sesión:
-- WAITING TASKS ordered by session_id
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id,
resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY session_id;
Consulta de sys.dm_os_waiting_tasks ordenada por duración de espera
El siguiente script de ejemplo consulta sys.dm_os_waiting_tasks y devuelve los tiempos de espera de bloqueo temporal ordenados por duración de espera:
-- WAITING TASKS ordered by wait_duration_ms
SELECT wt.session_id, wt.wait_type
, er.last_wait_type AS last_wait_type
, wt.wait_duration_ms
, wt.blocking_session_id, wt.blocking_exec_context_id, resource_description
FROM sys.dm_os_waiting_tasks wt
JOIN sys.dm_exec_sessions es ON wt.session_id = es.session_id
JOIN sys.dm_exec_requests er ON wt.session_id = er.session_id
WHERE es.is_user_process = 1
AND wt.wait_type <> 'SLEEP_TASK'
ORDER BY wt.wait_duration_ms desc;
Cálculo de esperas a lo largo de un período de tiempo
El script siguiente calcula y devuelve los tiempos de espera de bloqueo temporal a lo largo de un período de tiempo.
/* Snapshot the current wait stats and store so that this can be compared over a time period
Return the statistics between this point in time and the last collection point in time.
**This data is maintained in tempdb so the connection must persist between each execution**
**alternatively this could be modified to use a persisted table in tempdb. if that
is changed code should be included to clean up the table at some point.**
*/
use tempdb
go
declare @current_snap_time datetime;
declare @previous_snap_time datetime;
set @current_snap_time = GETDATE();
if not exists(select name from tempdb.sys.sysobjects where name like '#_wait_stats%')
create table #_wait_stats
(
wait_type varchar(128)
,waiting_tasks_count bigint
,wait_time_ms bigint
,avg_wait_time_ms int
,max_wait_time_ms bigint
,signal_wait_time_ms bigint
,avg_signal_wait_time int
,snap_time datetime
);
insert into #_wait_stats (
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,snap_time
)
select
wait_type
,waiting_tasks_count
,wait_time_ms
,max_wait_time_ms
,signal_wait_time_ms
,getdate()
from sys.dm_os_wait_stats;
--get the previous collection point
select top 1 @previous_snap_time = snap_time from #_wait_stats
where snap_time < (select max(snap_time) from #_wait_stats)
order by snap_time desc;
--get delta in the wait stats
select top 10
s.wait_type
, (e.waiting_tasks_count - s.waiting_tasks_count) as [waiting_tasks_count]
, (e.wait_time_ms - s.wait_time_ms) as [wait_time_ms]
, (e.wait_time_ms - s.wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_wait_time_ms]
, (e.max_wait_time_ms) as [max_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms) as [signal_wait_time_ms]
, (e.signal_wait_time_ms - s.signal_wait_time_ms)/((e.waiting_tasks_count - s.waiting_tasks_count)) as [avg_signal_time_ms]
, s.snap_time as [start_time]
, e.snap_time as [end_time]
, DATEDIFF(ss, s.snap_time, e.snap_time) as [seconds_in_sample]
from #_wait_stats e
inner join (
select * from #_wait_stats
where snap_time = @previous_snap_time
) s on (s.wait_type = e.wait_type)
where
e.snap_time = @current_snap_time
and s.snap_time = @previous_snap_time
and e.wait_time_ms > 0
and (e.waiting_tasks_count - s.waiting_tasks_count) > 0
and e.wait_type NOT IN ('LAZYWRITER_SLEEP', 'SQLTRACE_BUFFER_FLUSH'
, 'SOS_SCHEDULER_YIELD','DBMIRRORING_CMD', 'BROKER_TASK_STOP'
, 'CLR_AUTO_EVENT', 'BROKER_RECEIVE_WAITFOR', 'WAITFOR'
, 'SLEEP_TASK', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT'
, 'FT_IFTS_SCHEDULER_IDLE_WAIT', 'BROKER_TO_FLUSH', 'XE_DISPATCHER_WAIT'
, 'SQLTRACE_INCREMENTAL_FLUSH_SLEEP')
order by (e.wait_time_ms - s.wait_time_ms) desc ;
--clean up table
delete from #_wait_stats
where snap_time = @previous_snap_time;
Consulta de los descriptores del búfer para determinar los objetos que causan la contención de bloqueos temporales
El script siguiente consulta los descriptores del búfer para determinar qué objetos están asociados a los tiempos de espera de bloqueo temporal más largos.
IF EXISTS (SELECT * FROM tempdb.sys.objects WHERE [name] like '#WaitResources%') DROP TABLE #WaitResources;
CREATE TABLE #WaitResources (session_id INT, wait_type NVARCHAR(1000), wait_duration_ms INT,
resource_description sysname NULL, db_name NVARCHAR(1000), schema_name NVARCHAR(1000),
object_name NVARCHAR(1000), index_name NVARCHAR(1000));
GO
declare @WaitDelay varchar(16), @Counter INT, @MaxCount INT, @Counter2 INT
SELECT @Counter = 0, @MaxCount = 600, @WaitDelay = '00:00:00.100'-- 600x.1=60 seconds
SET NOCOUNT ON;
WHILE @Counter < @MaxCount
BEGIN
INSERT INTO #WaitResources(session_id, wait_type, wait_duration_ms, resource_description)--, db_name, schema_name, object_name, index_name)
SELECT wt.session_id,
wt.wait_type,
wt.wait_duration_ms,
wt.resource_description
FROM sys.dm_os_waiting_tasks wt
WHERE wt.wait_type LIKE 'PAGELATCH%' AND wt.session_id <> @@SPID
--select * from sys.dm_os_buffer_descriptors
SET @Counter = @Counter + 1;
WAITFOR DELAY @WaitDelay;
END;
--select * from #WaitResources;
update #WaitResources
set db_name = DB_NAME(bd.database_id),
schema_name = s.name,
object_name = o.name,
index_name = i.name
FROM #WaitResources wt
JOIN sys.dm_os_buffer_descriptors bd
ON bd.database_id = SUBSTRING(wt.resource_description, 0, CHARINDEX(':', wt.resource_description))
AND bd.file_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description) + 1, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) - CHARINDEX(':', wt.resource_description) - 1)
AND bd.page_id = SUBSTRING(wt.resource_description, CHARINDEX(':', wt.resource_description, CHARINDEX(':', wt.resource_description) +1 ) + 1, LEN(wt.resource_description) + 1)
--AND wt.file_index > 0 AND wt.page_index > 0
JOIN sys.allocation_units au ON bd.allocation_unit_id = AU.allocation_unit_id
JOIN sys.partitions p ON au.container_id = p.partition_id
JOIN sys.indexes i ON p.index_id = i.index_id AND p.object_id = i.object_id
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id;
select * from #WaitResources order by wait_duration_ms desc;
GO
/*
--Other views of the same information
SELECT wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY wait_type, db_name, schema_name, object_name, index_name;
SELECT session_id, wait_type, db_name, schema_name, object_name, index_name, SUM(wait_duration_ms) [total_wait_duration_ms] FROM #WaitResources
GROUP BY session_id, wait_type, db_name, schema_name, object_name, index_name;
*/
--SELECT * FROM #WaitResources
--DROP TABLE #WaitResources;
Script de creación de particiones por hash
El uso de este script se describe en Uso de creación de particiones por hash con una columna calculada y debe personalizarse para los fines de la implementación.
--Create the partition scheme and function, align this to the number of CPU cores 1:1 up to 32 core computer
-- so for below this is aligned to 16 core system
CREATE PARTITION FUNCTION [pf_hash16] (tinyint) AS RANGE LEFT FOR VALUES
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15);
CREATE PARTITION SCHEME [ps_hash16] AS PARTITION [pf_hash16] ALL TO ( [ALL_DATA] );
-- Add the computed column to the existing table (this is an OFFLINE operation)
-- Consider using bulk loading techniques to speed it up
ALTER TABLE [dbo].[latch_contention_table]
ADD [HashValue] AS (CONVERT([tinyint], abs(binary_checksum([hash_col])%(16)),(0))) PERSISTED NOT NULL;
--Create the index on the new partitioning scheme
CREATE UNIQUE CLUSTERED INDEX [IX_Transaction_ID]
ON [dbo].[latch_contention_table]([T_ID] ASC, [HashValue])
ON ps_hash16(HashValue);
Pasos siguientes
Para obtener más información sobre las herramientas de supervisión, consulte Herramientas de supervisión y optimización del rendimiento.