Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aplica a:![]() SQL Server 2016 (13.x) y versiones posteriores
SQL Server 2016 (13.x) y versiones posteriores ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Base de datos SQL en Microsoft Fabric
Base de datos SQL en Microsoft Fabric
La virtualización de datos permite ejecutar consultas de Transact-SQL (T-SQL) a través de datos externos sin cargarlos en la base de datos. PolyBase es la característica motor de base de datos que implementa la virtualización de datos en SQL Server y Azure SQL. Defina un origen de datos externo, un formato de archivo opcional y una tabla externa y, a continuación, consulte la tabla externa con SELECT como cualquier otra tabla.
Esta guía le ayuda a:
- Comprenda qué características de PolyBase admiten su plataforma SQL y su versión.
- Elija entre
OPENROWSET, tablas externas yBULK INSERTpara consultar o ingerir datos. - Siga los vínculos paso a paso para escenarios comunes.
- Revise el rendimiento, la solución de problemas y los procedimientos recomendados para cargas de trabajo de producción.
Casos de uso comunes
En la tabla siguiente se describen posibles escenarios de uso.
| Escenario | Uso |
|---|---|
| Exploración de archivos ad hoc | OPENROWSET(BULK ...) |
| Consulta de archivos reutilizables para BI/reporting | Tablas externas sobre archivos |
| Consulta entre bases de datos (SQL Server, Oracle, Teradata, MongoDB, ODBC) | Conectores de PolyBase con tablas externas |
| Exportación de resultados de consulta a archivos |
CREATE EXTERNAL TABLE AS SELECT (CETAS) |
| Ingesta masiva en tablas |
BULK INSERT o OPENROWSET(BULK ...) con INSERT ... SELECT |
¿Qué características están disponibles y dónde?
En la tabla siguiente se muestran qué características principales de virtualización de datos y PolyBase están disponibles en cada plataforma SQL. Use esta tabla para determinar lo que puede hacer en la plataforma antes de usar las guías detalladas.
| Feature | SQL Server 2019 | SQL Server 2022 | SQL Server 2025 | Azure SQL Database | Instancia Gestionada de Azure SQL | Base de datos SQL en Microsoft Fabric |
|---|---|---|---|---|---|---|
| tablas externas | Sí | Sí | Sí | Sí | Sí | Sí |
| OPENROWSET (BULK) | Sí 1 | Sí | Sí | Sí | Sí | Sí |
| CETAS (exportación) | No | Sí | Sí | No | Sí | No |
| Archivos CSV/delimitados | Sí 2 | Sí | Sí | Sí | Sí | Sí |
| Archivos de Parquet | No | Sí | Sí | Sí | Sí | Sí |
| Tablas de Delta Lake | No | Sí | Sí | No | No | No |
| Conexión a otra instancia de SQL Server | Sí | Sí | Sí | No | No | No |
| Conexión a Azure SQL Database o Instancia administrada de Azure SQL | Sí 3 | Sí 3 | Sí 3 | No | No | No |
| Conexión a Oracle/Teradata/MongoDB | Sí | Sí | Sí | No | No | No |
| Conexión con Azure Blob Storage | Sí | Sí | Sí | Sí | Sí | No |
| Conexión a ADLS Gen2 | No | Sí | Sí | Sí | Sí | No |
| Conexión al almacenamiento compatible con S3 | No | Sí | Sí | No | No | No |
| Conexión a OneLake (Fabric) | No | No | No | No | No | Sí |
| Cálculo de inserciones | Sí | Sí | Sí | No | No | No |
| Autenticación de identidad administrada | No | No | Sí 4 | Sí | Sí | No |
1 SQL Server 2019 (15.x) admite OPENROWSET(BULK...) rutas de acceso de archivos locales y de red. En SQL Server 2022 (16.x) y versiones posteriores, OPENROWSET(BULK...) también admite la lectura desde el almacenamiento en la nube con FORMAT = 'PARQUET', FORMAT = DELTAy FORMAT = 'CSV'.
2 Compatibilidad con CSV en SQL Server 2019 (15.x) requiere Hadoop. En SQL Server 2022 (16.x) y versiones posteriores, CSV se admite de forma nativa sin Hadoop.
3 Usa el conector de SQL Server (sqlserver://). La credencial con ámbito de base de datos tiene como destino el punto de conexión de Azure SQL, los mismos pasos que para conectarse a otro servidor SQL Server.
4 Se admite la autenticación de identidad administrada para conectarse a Azure Blob Storage (ABS) y ADLS Gen2. Requiere SQL Server habilitado para Azure Arc o SQL Server en una máquina virtual de Azure para SQL Server local. Está disponible de forma nativa en Azure SQL Database e Instancia administrada de Azure SQL.
Nota:
A partir de SQL Server 2025 (17.x), consultar archivos de datos (CSV, Parquet y Delta) en Azure Blob Storage, ADLS Gen2 o almacenamiento compatible con S3 es una funcionalidad de motor nativa y ya no requiere instalar o ejecutar servicios de PolyBase. Los conectores RDBMS (SQL Server, Oracle, Teradata, MongoDB, ODBC) todavía requieren que los servicios de PolyBase se instalen y ejecuten. SQL Server 2025 (17.x) también agrega compatibilidad con Linux para estos conectores, que anteriormente estaban disponibles solo en Windows.
Consulta de datos externos
Antes de elegir un escenario específico, comprenda las tres maneras de consultar datos externos:
| Enfoque | Sintaxis | Se utiliza cuando | Autenticación | PolyBase requerido |
|---|---|---|---|---|
| Consultas ad hoc de OLE DB | OPENROWSET(provider, connection, query) |
Quiere una consulta rápida y única, sin objetos persistentes, o necesita autenticación de Microsoft Entra ID. | Autenticación de SQL, autenticación de Windows, Id. de Microsoft Entra (MSOLEDBSQL) | No |
| Presentar consultas ad hoc | OPENROWSET(BULK ...) |
Quiere explorar los datos de archivos rápidamente o probar esquemas antes de crear una tabla. | Token de SAS, clave de acceso, identidad administrada, identificador de Microsoft Entra | Sí para Azure SQL Database e Instancia administrada de Azure SQL No para instancias de SQL Server |
| Conectores de datos persistentes |
CREATE EXTERNAL TABLE con sqlserver://, oracle://, teradata://, etc. |
Necesita acceso recurrente, gobernanza, estadísticas y cálculo de empuje para producción. | Solo autenticación SQL | Sí |
Los servicios de PolyBase son necesarios para el acceso a archivos en la nube en SQL Server 2019 (15.x) y SQL Server 2022 (16.x). SQL Server 2025 (17.x) y versiones posteriores tienen compatibilidad nativa con CSV, Parquet y Delta sin PolyBase.
Guía para la toma de decisiones
| Escenario | Recomendación |
|---|---|
| Necesito la autenticación de Id. de Microsoft Entra para SQL remoto o quiero evitar los servicios de PolyBase. | Uso OPENROWSET(MSOLEDBSQL, ...) (ad hoc, sin objetos persistentes) |
| Necesito tablas persistentes, estadísticas o cálculo delegado en bases de datos remotas | Uso CREATE EXTERNAL TABLE con conectores de PolyBase (sqlserver://, oracle://, teradata://, mongodb://, odbc://).
OPENROWSET
no admite conectores |
| Estoy explorando un nuevo archivo o probando un esquema | Uso OPENROWSET(BULK ...) (iteración rápida, sin objetos persistentes) |
| Ingreso datos del archivo en una tabla con transformaciones | Usa INSERT ... SELECT desde OPENROWSET(BULK ...) |
| Necesito gobernanza o acceso compartido para muchos usuarios o aplicaciones | Use CREATE EXTERNAL TABLE para que los permisos y los metadatos estén centralizados. |
| Trabajo en SQL Database en Fabric | Use OPENROWSET(BULK ...) para consultas ad hoc de OneLake o tablas externas para acceso reutilizable; para almacenamiento externo, use accesos directos de OneLake. |
Elección del escenario
Ahora que comprende los tres enfoques, use una de las siguientes guías para implementar su caso de uso específico.
Archivos de consulta (Parquet, CSV o Delta)
Si los datos están en archivos Parquet, CSV o Delta en Azure Blob Storage, ADLS Gen2, almacenamiento compatible con S3 o OneLake, siga una de estas guías:
| Escenario | Guía recomendada | Plataformas |
|---|---|---|
| Consulta rápida ad hoc en un archivo Parquet o CSV | Utilice OPENROWSET. No se necesita ninguna tabla externa |
SQL Server 2022 (16.x) y versiones posteriores, Azure SQL Database, Instancia administrada de Azure SQL, SQL Database en Fabric |
| Consultas repetidas en archivos Parquet con un esquema persistente | Crea una tabla externa sobre Parquet | SQL Server 2022 (16.x) y versiones posteriores, Azure SQL Database, Instancia administrada de Azure SQL, SQL Database en Fabric |
| Consulta de archivos CSV con una tabla externa | Creación de una tabla externa con un formato de archivo para texto delimitado | SQL Server 2019 (15.x) y versiones posteriores, Azure SQL Database, Instancia administrada de Azure SQL, SQL Database en Fabric |
| Consulta de tablas de Delta Lake | Creación de una tabla externa con FILE_FORMAT = DeltaLakeFileFormat |
SQL Server 2022 (16.x) y versiones posteriores |
| Exportar los resultados de la consulta a archivos Parquet o CSV (CETAS) | Utilice CREATE EXTERNAL TABLE AS SELECT |
SQL Server 2022 (16.x) y versiones posteriores, Azure SQL Managed Instance |
También puede seguir uno de estos tutoriales paso a paso:
| Tutorial | Descripción |
|---|---|
| Introducción a PolyBase en SQL Server 2022 | Cubre OPENROWSET con Parquet y CSV, tablas externas y navegación por carpetas. |
| Virtualización del archivo parquet en un almacenamiento de objetos compatible con S3 con PolyBase | Tutorial para SQL Server 2022 (16.x) y versiones posteriores. |
| Virtualizar archivo CSV con PolyBase | Tutorial para SQL Server 2022 (16.x) y versiones posteriores. |
| Virtualizar tabla delta con PolyBase | Tutorial para SQL Server 2022 (16.x) y versiones posteriores. |
| Virtualización de datos con Azure SQL Database (versión preliminar) | Guía de Azure SQL Database para Parquet y CSV. |
| Virtualización de datos con Azure SQL Managed Instance | Guía de Azure SQL Managed Instance para Parquet, CSV y CETAS. |
| Virtualización de datos en bases de datos SQL en Fabric | Guía de base de datos SQL en Fabric para archivos de OneLake. |
Conexión a otra instancia de SQL Server, Azure SQL Database o Instancia administrada de SQL
En SQL Server 2019 (15.x) y versiones posteriores, PolyBase puede consultar tablas en otra instancia de SQL Server, Azure SQL Database o Instancia administrada de Azure SQL, sin usar servidores vinculados.
Importante
El conector sqlserver:// no es compatible con la base de datos SQL en Fabric. Los conectores RDBMS de PolyBase usan la autenticación SQL a través de CREATE DATABASE SCOPED CREDENTIAL y no admiten la autenticación con Microsoft Entra ID, Managed Identity o principal de servicio. Dado que SQL Database en Fabric requiere la autenticación de Microsoft Entra, no se puede conectar a ella mediante PolyBase.
| Paso | Qué hacer |
|---|---|
| 1. Instalación de PolyBase | Instalación de PolyBase en Windows o instalación de PolyBase en Linux |
| 2. Crear una credencial |
CREATE DATABASE SCOPED CREDENTIAL con el login objetivo |
| 3. Crear un origen de datos externo | CREATE EXTERNAL DATA SOURCE ... WITH (LOCATION = 'sqlserver://<server>') |
| 4. Crear una tabla externa | CREATE EXTERNAL TABLE ... WITH (LOCATION = '<db>.<schema>.<table>') |
| 5. Consulta | SELECT * FROM <external_table> |
Sugerencia
El conector de SQL Server (sqlserver://) también funciona para Azure SQL Database e Instancia administrada de Azure SQL. Siga los mismos pasos y establezca en LOCATION el punto de conexión de Azure SQL (por ejemplo, sqlserver://myserver.database.windows.net).
Para obtener una guía detallada, consulte Configuración de PolyBase para acceder a datos externos en SQL Server.
Conexión a Oracle, Teradata o MongoDB
SQL Server 2019 (15.x) y versiones posteriores pueden consultar Oracle, Teradata, MongoDB y Cosmos DB mediante conectores ODBC de PolyBase.
| Origen de datos | Guía | Requisitos |
|---|---|---|
| Oracle | Configurar PolyBase para acceder a datos externos en Oracle | SQL Server 2019 (15.x) y versiones posteriores, controladores de cliente de Oracle |
| Teradata | Configurar PolyBase para obtener acceso a datos externos en Teradata | SQL Server 2019 (15.x) y versiones posteriores, controlador ODBC de Teradata |
| MongoDB/Cosmos DB | Configurar PolyBase para acceder a datos externos en MongoDB | SQL Server 2019 (15.x) y versiones posteriores, controlador ODBC de MongoDB |
| Cualquier origen ODBC | Configuración de PolyBase para acceder a datos externos con tipos genéricos de ODBC | SQL Server 2019 (15.x) y versiones posteriores (Windows) (Linux a partir de SQL Server 2025 (17.x)) |
Conexión a Azure Blob Storage o ADLS Gen2
| Plataforma SQL | Opciones de autenticación | Guía |
|---|---|---|
| SQL Server 2022 (16.x) y versiones posteriores | Token de SAS, clave de acceso, Identidad administrada (a partir de SQL Server 2025 (17.x)) | Configuración de PolyBase para acceder a datos externos en Azure Blob Storage |
| SQL Server 2019 (15.x) | Clave de acceso (a través del conector de Hadoop) | Configuración de PolyBase para acceder a datos externos en Azure Blob Storage |
| Azure SQL Database | Token de SAS, identidad administrada, paso a través de Microsoft Entra | Virtualización de datos con Azure SQL Database (versión preliminar) |
| Instancia Gestionada de Azure SQL | Token de SAS, identidad administrada | Virtualización de datos con Azure SQL Managed Instance |
En SQL Server 2022 (16.x), los prefijos de URI cambiaron. Al migrar desde SQL Server 2019 (15.x) o versiones anteriores:
-
Azure Blob Storage: Cambiar
wasb[s]://aabs:// -
ADLS Gen2: Cambiar
abfs[s]://aadls://
Para más información, consulte Configuración de PolyBase para acceder a datos externos en Azure Blob Storage.
Conexión al almacenamiento de objetos compatible con S3
SQL Server 2022 (16.x) y versiones posteriores admiten almacenamiento compatible con S3, como Amazon S3, MinIO y Ceph.
Para obtener más información, vea Configuración de PolyBase para acceder a datos externos en el almacenamiento de objetos compatible con S3.
Exportación de datos con CREATE EXTERNAL TABLE AS SELECT (CETAS)
CETAS exporta los resultados de la consulta a archivos externos (Parquet o CSV) en Azure Blob Storage, ADLS Gen2 o almacenamiento compatible con S3.
| Plataforma SQL | Soportado | Formatos de exportación | Notas |
|---|---|---|---|
| SQL Server 2022 (16.x) y versiones posteriores | Sí | Parquet, CSV | Requiere configuración del servidor: permitir la exportación de polybase |
| Instancia Gestionada de Azure SQL | Sí | Parquet, CSV | Deshabilitado de forma predeterminada |
| Azure SQL Database | No | Ninguno | No disponible |
| Base de datos SQL en Fabric | No | Ninguno | No disponible |
Para obtener la referencia de Transact-SQL, vea CREATE EXTERNAL TABLE AS SELECT (CETAS).
Ejemplos de inicio rápido
Ejemplo 1: consulta ad hoc en un archivo Parquet (OPENROWSET)
No se necesita ninguna tabla externa. Funciona en SQL Server 2022 (16.x) y versiones posteriores, Azure SQL Database, Azure SQL Managed Instance y SQL Database en Fabric.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Ejemplo 2: Tabla externa sobre CSV en Azure Blob Storage
Este ejemplo funciona en todas las plataformas SQL que admiten PolyBase.
Paso 1: Crear una clave maestra de base de datos (DMK). Este paso es necesario porque la credencial almacena un secreto de token de SAS. Sin embargo, puede realizar este paso si usa la identidad administrada o la autenticación de Microsoft Entra.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Paso 2: Crear una credencial con un token de SAS. Omita el valor inicial
?.CREATE DATABASE SCOPED CREDENTIAL MyStorageCred WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<your_SAS_token>'; -- omit the leading '?'Paso 3: Crear un origen de datos externo.
CREATE EXTERNAL DATA SOURCE MyAzureStorage WITH ( LOCATION = 'abs://mycontainer@mystorageaccount.blob.core.windows.net', CREDENTIAL = MyStorageCred );Paso 4: Crear un formato de archivo para el CSV.
CREATE EXTERNAL FILE FORMAT CsvFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ',', STRING_DELIMITER = '"', FIRST_ROW = 2 ) );Paso 5: Crear la tabla externa.
CREATE EXTERNAL TABLE dbo.SalesExternal ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer NVARCHAR (100) ) WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/data/sales/', FILE_FORMAT = CsvFormat );Paso 6: Consultar la tabla externa.
SELECT * FROM dbo.SalesExternal WHERE OrderDate >= '2025-01-01';
Ejemplo 3: Consulta de una tabla en otro servidor SQL Server
Este ejemplo funciona en SQL Server 2019 (15.x) y versiones posteriores.
Paso 1: Crear una clave maestra de base de datos (necesaria porque la credencial almacena una contraseña).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';Paso 2: Crear una credencial para la instancia remota de SQL Server.
CREATE DATABASE SCOPED CREDENTIAL RemoteSqlCred WITH IDENTITY = 'remote_user', SECRET = '<password>';Paso 3: Crear el origen de datos externo.
CREATE EXTERNAL DATA SOURCE RemoteSqlServer WITH ( LOCATION = 'sqlserver://remote-server.contoso.com', PUSHDOWN = ON, CREDENTIAL = RemoteSqlCred );Paso 4: Crear la tabla externa (nombre de tres partes en
LOCATION).CREATE EXTERNAL TABLE dbo.RemoteCustomers ( CustomerId INT, CustomerName NVARCHAR (200) COLLATE SQL_Latin1_General_CP1_CI_AS ) WITH ( DATA_SOURCE = RemoteSqlServer, LOCATION = 'SalesDB.dbo.Customers' );Paso 5: Consultar entre servidores.
SELECT c.CustomerName, s.Amount FROM dbo.RemoteCustomers AS c INNER JOIN dbo.LocalSales AS s ON c.CustomerId = s.CustomerId;
Ejemplo 4: Exportación de resultados a Parquet con CETAS
Funciona en SQL Server 2022 (16.x) y versiones posteriores, Instancia administrada de Azure SQL.
Paso 1: Habilitar CETAS (solo SQL Server).
EXECUTE sp_configure 'allow polybase export', 1; RECONFIGURE;Paso 2: Creación de credenciales y orígenes de datos (reutilización de ejemplos anteriores).
Paso 3: Crear un formato de archivo para la exportación de Parquet.
CREATE EXTERNAL FILE FORMAT ParquetFormat WITH ( FORMAT_TYPE = PARQUET );Paso 4: Exportar los resultados de la consulta.
CREATE EXTERNAL TABLE dbo.Sales2025Export WITH ( DATA_SOURCE = MyAzureStorage, LOCATION = '/exports/sales_2025.parquet', FILE_FORMAT = ParquetFormat ) AS SELECT * FROM Sales.Orders WHERE OrderDate >= '2025-01-01';
Bloques de creación de T-SQL para PolyBase
Antes de implementar cualquier escenario, comprenda los objetos T-SQL principales que usa PolyBase y cómo encajan juntos:
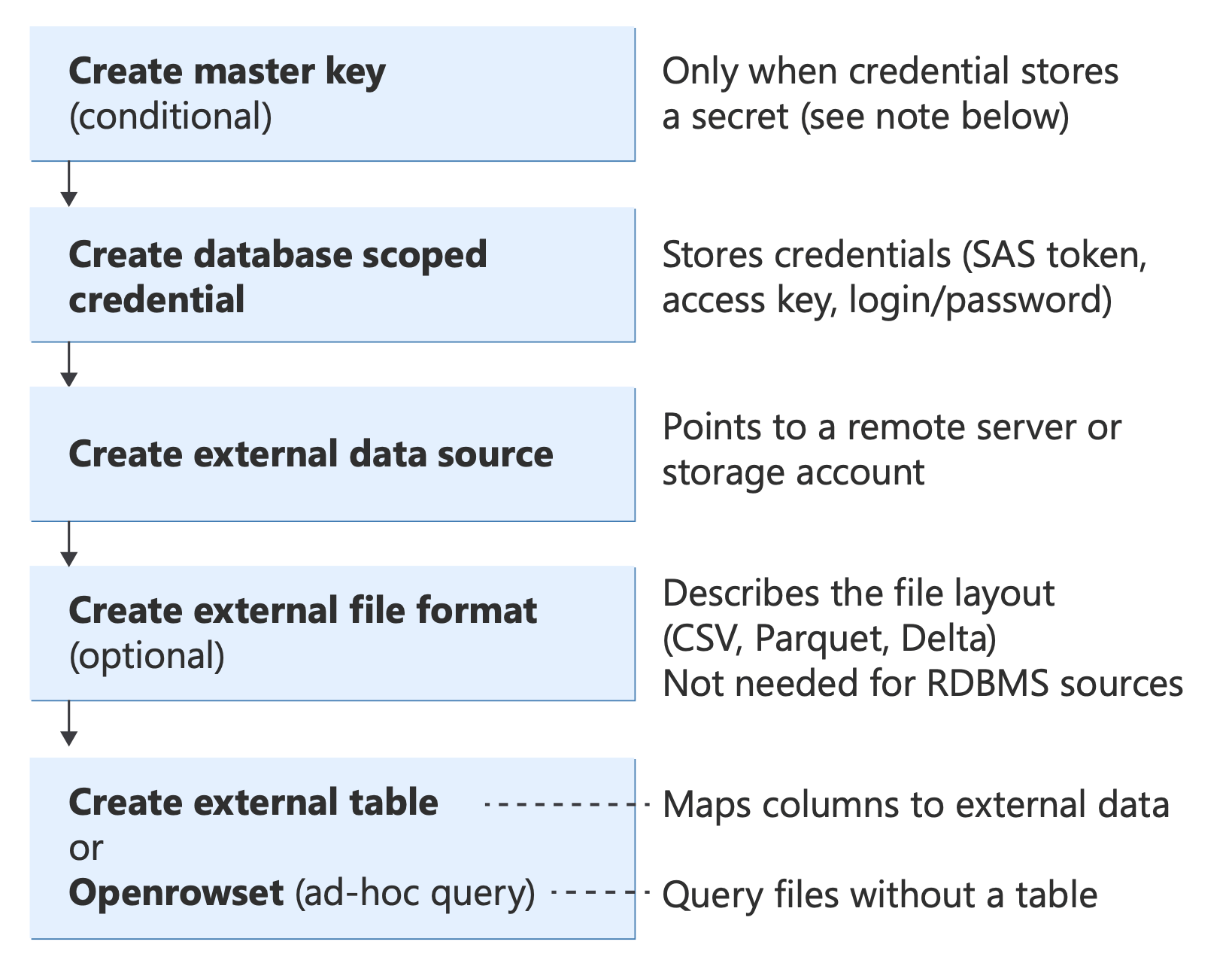
Diagrama que muestra los objetos T-SQL de PolyBase y sus relaciones, desde la autenticación (clave maestra de base de datos, credenciales) a través de orígenes de datos y formatos de archivo para consultar métodos (Tabla externa, OPENROWSET, BULK INSERT, CETAS).
Para obtener información sobre estas instrucciones T-SQL, vea:
- CREAR FUENTE DE DATOS EXTERNA
- CREAR FORMATO DE ARCHIVO EXTERNO
- CREATE EXTERNAL TABLE (CREAR TABLA EXTERNA)
- OPENROWSET
- CREATE EXTERNAL TABLE AS SELECT (CETAS) - Crear tabla externa como selección
Para obtener una referencia de Transact-SQL completa para todos los objetos, consulte Referencia de Transact-SQL polyBase.
Importante
Compruebe la asignación de tipos de datos para el formato de archivo externo. Al crear un formato de archivo externo o consultar archivos mediante OPENROWSET, PolyBase asigna automáticamente tipos de datos de origen (Parquet, CSV, Delta, Oracle, Teradata, MongoDB) a tipos de datos de SQL Server. Los tipos no coincidentes pueden provocar un truncamiento silencioso, una pérdida de precisión o errores de consulta. Por ejemplo, un Parquet DECIMAL(38,18) se mapea a DECIMAL(18,0). Revise las tablas de asignación antes de definir columnas de tablas externas o una cláusula WITH. Para obtener la referencia completa, consulte Asignación de tipos con PolyBase.
¿Cuándo se requiere CREATE MASTER KEY?
Se crea una clave maestra de base de datos (DMK) mediante la sintaxis CREATE MASTER KEY. DMK cifra los secretos almacenados en credenciales delimitadas por el ámbito de la base de datos. Solo es necesario cuando la credencial contiene un valor secreto, es decir, cuando almacena una contraseña, un token o una clave de acceso.
DmK es obligatorio (las credenciales almacenan un secreto):
Tipo de autenticación Valor de IDENTITYTiene secreto DMK Token de SAS 'SHARED ACCESS SIGNATURE'Sí Obligatorio Tecla de acceso S3 'S3 ACCESS KEY'Sí Obligatorio Inicio de sesión de SQL/autenticación básica '<username>'Sí Obligatorio Clave de acceso de la cuenta de almacenamiento '<storage_account_name>'Sí Obligatorio DMK no es necesario (no se almacena ningún secreto):
Tipo de autenticación Valor de IDENTITYTiene secreto DMK Identidad administrada 'Managed Identity'No No es necesario Microsoft Entra ID 'User Identity'o'Managed Identity'No No es necesario
Sugerencia
Si no hay ningún secreto en su instrucción CREATE DATABASE SCOPED CREDENTIAL, no necesita una DMK. Identidad administrada y la autenticación de Microsoft Entra ID delegan la confianza en la plataforma. La base de datos no almacena contraseñas ni tokens.
Ejemplos:
En esta consulta de ejemplo, se requiere la DMK (las credenciales almacenan un token de SAS).
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<strong_password>';
CREATE DATABASE SCOPED CREDENTIAL SasCred
WITH IDENTITY = 'SHARED ACCESS SIGNATURE',
SECRET = '<your_SAS_token>';
En esta consulta de ejemplo, la DMK no es necesaria (identidad administrada, ningún secreto).
CREATE DATABASE SCOPED CREDENTIAL ManagedIdentityCred
WITH IDENTITY = 'Managed Identity';
En esta consulta de ejemplo, la DMK no es necesaria (autenticación directa de Microsoft Entra, sin necesidad de secreto).
CREATE DATABASE SCOPED CREDENTIAL EntraIdCred
WITH IDENTITY = 'User Identity';
Acceso remoto a datos con OPENROWSET y tablas externas
SQL Server ofrece tres enfoques distintos para consultar datos remotos. Puede elegir el enfoque adecuado cuando comprenda las diferencias en la sintaxis, la autenticación y la arquitectura.
| Enfoque | Sintaxis | Se conecta a | Autenticación | Servicios de PolyBase | Plataformas |
|---|---|---|---|---|---|
| Consultas OLE DB | OPENROWSET(provider, connection, query) |
Cualquier origen OLE DB a través de MSOLEDBSQL, SQLOLEDB u otros proveedores | Autenticación de SQL, autenticación de Windows, Id. de Microsoft Entra (MSOLEDBSQL) | No | SQL Server (todas las versiones compatibles) |
| Consultas de archivos | OPENROWSET(BULK ...) |
Archivos en disco local, red o nube (Azure Blob, ADLS, S3, OneLake) | Token de SAS, clave de acceso, identidad administrada, identificador de Microsoft Entra | Sí para la nube*; No para local | SQL Server 2005; SQL Server 2022 (16.x) y versiones posteriores (nube); Azure SQL |
| Conectores de PolyBase |
CREATE EXTERNAL TABLE con CREATE EXTERNAL DATA SOURCE usando sqlserver://, oracle://, teradata://, mongodb://, odbc:// |
Orígenes SQL Server remoto, Oracle, Teradata, MongoDB y ODBC | Solo autenticación SQL | Sí | SQL Server 2019 (15.x) y versiones posteriores (Windows); SQL Server 2025 (17.x) y versiones posteriores (Linux) |
Los servicios de PolyBase son necesarios para el acceso a archivos en la nube en SQL Server 2019 (15.x) y SQL Server 2022 (16.x). SQL Server 2025 (17.x) y versiones posteriores tienen compatibilidad nativa con archivos en la nube y ya no requieren PolyBase para CSV, Parquet o Delta.
Cuándo usar cada enfoque
Use OLE DB OPENROWSET para:
- Consultas ad hoc rápidas y únicas sin crear objetos persistentes
- Autenticación de Microsoft Entra ID o Identidad Administrada (a través de MSOLEDBSQL)
- Evitar dependencias del servicio PolyBase
- Conexión a cualquier origen de datos con un proveedor OLE DB
Use el archivo OPENROWSET(BULK) para:
- Exploración de archivos ad hoc y detección de esquemas
- Transformaciones rápidas y vistas previas antes de aplicar una definición de tabla
- Transformaciones flexibles de columnas en línea (conversión, filtrado, columnas calculadas)
- Datos que no cambian con frecuencia y no necesitan metadatos persistentes
Utilice conectores PolyBase con CREATE EXTERNAL TABLE para:
- Definiciones de tabla persistentes y reutilizables a las que acceden varios usuarios o aplicaciones
- Cargas de trabajo de producción que requieren estadísticas y optimización del plan de consulta
- Procesamiento delegable en orígenes remotos (delegación de filtros en Oracle, SQL Server, etc.)
- Gobernanza y seguridad compartidas (una vez creados, los usuarios solo necesitan
SELECTpermiso) - Cuando tenga la autenticación de SQL disponible para el origen remoto
OPENROWSET (OLE DB): consultas remotas ad hoc (no se requieren servicios de PolyBase)
El formulario OLE DB de OPENROWSET se conecta a un origen de datos remoto a través de un proveedor OLE DB, ejecuta una consulta de paso a través y devuelve los resultados como un conjunto de filas. Es una alternativa ad hoc única a un servidor vinculado. No se crea ningún metadato persistente. Esta sintaxis no requiere servicios de PolyBase y no admite archivos en la nube ni orígenes de datos externos.
Esta consulta de ejemplo se conecta a un servidor SQL Server remoto a través de OLE DB (no PolyBase).
SELECT *
FROM OPENROWSET (
'MSOLEDBSQL',
'Server=remote-server;Database=AdventureWorks;Trusted_Connection=yes;',
'SELECT TOP 10 * FROM AdventureWorks.Sales.SalesOrderHeader'
);
OPENROWSET(BULK): consultas basadas en archivos (PolyBase)
El BULK formato de OPENROWSET lee datos directamente desde archivos. En SQL Server 2019 (15.x) y versiones anteriores, lee desde rutas de acceso de archivo locales o UNC y requiere un archivo de formato. En SQL Server 2022 (16.x) y versiones posteriores, puede leer desde el almacenamiento en la nube utilizando los parámetros DATA_SOURCE y FORMAT. Este enfoque es la versión integrada de PolyBase que se usa para la virtualización de datos.
En el contexto de PolyBase y la virtualización de datos, cuando esta guía hace referencia a OPENROWSET, se refiere a la sintaxis OPENROWSET(BULK ...) con una cláusula FORMAT para consultar archivos externos.
Ejemplos:
Esta consulta de ejemplo lee un archivo Parquet de Azure Blob Storage (SQL Server 2022 y versiones posteriores).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'data/sales/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET'
) AS [result];
En este ejemplo de consulta, se lee un archivo Parquet con una ruta de acceso en línea (Azure SQL Database, Instancia administrada de Azure SQL).
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet',
FORMAT = 'PARQUET'
) AS [result];
Cuándo usar OPENROWSET frente a tablas externas
Tanto OPENROWSET(BULK ...) como las tablas externas permiten consultar datos externos con T-SQL, pero están diseñadas para distintos casos de uso. En la tabla siguiente se resumen las diferencias clave que le ayudarán a decidir qué enfoque se ajusta a su escenario.
| Capacidad | OPENROWSET(BULK ...) |
Tabla externa |
|---|---|---|
| propósito | Exploración ad hoc y consultas puntuales | Definición de tabla persistente y reutilizable |
| Metadatos almacenados en la base de datos | N.º No se guarda nada después de que se ejecute la consulta | Sí. La definición de tabla, el origen de datos y el formato de archivo se almacenan como objetos de base de datos. |
| Definición de esquema | Se deduce automáticamente del archivo (Parquet) o definido directamente con una cláusula de WITH |
Se define explícitamente en la CREATE EXTERNAL TABLE instrucción |
| Permisos | Requiere ADMINISTER BULK OPERATIONS o ADMINISTER DATABASE BULK OPERATIONS |
Una vez creado, el permiso estándar SELECT en la tabla es suficiente. |
| Columnas calculadas | Sí. Agregue expresiones y columnas calculadas en la SELECT lista; las funciones de metadatos como filename() y filepath() solo están disponibles aquí. |
N.º Lista de columnas fija; realizar transformaciones en una vista o en la consulta que lee la tabla externa |
| Estadísticas | Azure SQL: estadísticas manuales de columna única a través de sys.sp_create_openrowset_statistics; SQL Server 2022 (16.x) y versiones posteriores: crear automáticamente estadísticas en predicados (sin estadísticas manuales en SQL Server). Consulte estadísticas manuales de OPENROWSET. |
Compatibilidad completa CREATE STATISTICS en todas las plataformas, además de crear automáticamente en SQL Server 2022 (16.x) y versiones posteriores. Consulte Creación de estadísticas manuales de tabla externa. |
| Pushdown | Soporte limitado. El motor podría insertar filtros en el análisis de archivos, pero no hay ningún empuje hacia los orígenes remotos de bases de datos relacionales (RDBMS). | Sí. Soporta el cálculo delegado para conectores RDBMS (SQL Server, Oracle, Teradata, MongoDB) |
| Más adecuado para | Exploración de datos, detección de esquemas, consultas de creación de prototipos, cargas de datos únicas, transformaciones flexibles | Cargas de trabajo de producción, consultas repetidas, acceso compartido entre usuarios, paneles e informes |
Utilice OPENROWSET cuando necesite flexibilidad
Use OPENROWSET para explorar un archivo, probar esquemas diferentes o agregar columnas calculadas y transformaciones sin crear objetos persistentes. Por ejemplo, puede extraer la ruta de acceso del archivo como una columna, convertir tipos de datos en línea o filtrar por expresiones calculadas en una sola consulta.
Esta consulta de ejemplo incluye columnas calculadas y transformaciones:
SELECT result.filename() AS [FileName],
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
CAST (OrderDate AS DATE) AS OrderDate,
Amount,
OrderDate
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025';
Sugerencia
Las filepath() funciones y filename() están disponibles en Azure SQL Database, Azure SQL Managed Instance y SQL Server 2022 (16.x) y versiones posteriores. Permiten filtrar por partes de la ruta de acceso de archivo (eliminación de particiones) y exponer el nombre de archivo de origen como una columna, lo cual no es posible directamente con tablas externas.
Utilice tablas externas cuando necesite persistencia y gestión
Use tablas externas cuando varios usuarios o aplicaciones necesiten consultar repetidamente los mismos datos externos. Defina el esquema, el origen de datos y las credenciales una vez y los almacene en la base de datos. Los consumidores solo necesitan SELECT permiso en la tabla.
Las tablas externas también admiten estadísticas, que el optimizador de consultas usa para crear mejores planes de ejecución. Puede crear estadísticas manualmente o dejar que el motor los cree automáticamente (SQL Server 2022 (16.x) y versiones posteriores).
Esta consulta de ejemplo crea estadísticas en una tabla externa para mejorar los planes de consulta.
CREATE STATISTICS Stats_OrderDate
ON dbo.SalesExternal(OrderDate)
WITH FULLSCAN;
Para obtener más información sobre las estadísticas de ambos enfoques, consulte Consideraciones de rendimiento de PolyBase: estadísticas.
BULK INSERT frente a OPENROWSET(BULK): ¿Cuál debo usar?
Tanto BULK INSERT como OPENROWSET(BULK ...) importan datos de archivos a SQL Server mediante el mismo motor de carga masiva subyacente. Sin embargo, difieren en la sintaxis, la flexibilidad y lo que puede hacer con los resultados. En la tabla siguiente se resumen las diferencias clave:
Nota:
BULK INSERT no está disponible en la base de datos SQL de Fabric. Para Fabric, usa OPENROWSET(BULK ...) en OneLake.
| Capacidad | BULK INSERT |
OPENROWSET(BULK ...) |
|---|---|---|
| Propósito básico | Carga datos de un archivo directamente en una tabla de destino | Devuelve un conjunto de filas que se utiliza en una instrucción SELECT o INSERT ... SELECT. |
| Patrón de uso | Declaración independiente: BULK INSERT <table> FROM '<file>' |
Debe usarse dentro de una consulta: SELECT * FROM OPENROWSET(BULK ...) o INSERT INTO <table> SELECT * FROM OPENROWSET(BULK ...) |
| ¿Requiere una tabla de destino? | Sí. Siempre escribe directamente en una tabla | N.º
SELECT Puede hacerlo sin insertar en ningún lugar o insertar en cualquier tabla o tabla temporal. |
| Transformaciones de columna durante la carga | Soporte limitado. Los datos fluyen de archivo a tabla tal cual (asignación controlada por archivo de formato o por orden de columna) | Soporte técnico completo. Puede agregar expresiones, CASTWHERE filtros, JOIN otras tablas y columnas calculadas en los alrededores.SELECT |
| Indicaciones para la tabla | La WITH cláusula incluye compatibilidad con BATCHSIZE, , CHECK_CONSTRAINTS, FIRE_TRIGGERSKEEPIDENTITY, KEEPNULLS, , TABLOCK, y más |
Admite sugerencias de tabla mediante la sintaxis INSERT ... SELECT * FROM OPENROWSET(BULK ...) WITH (TABLOCK, IGNORE_CONSTRAINTS, ...) |
| Importación de un solo valor de objeto grande (LOB) | No soportado | Sí. Admite SINGLE_BLOB, SINGLE_CLOB, SINGLE_NCLOB para importar un archivo completo como un valor varbinary(max), varchar(max) o nvarchar(max) |
| Formato de archivos | Sí. Compatible con (XML y no XML) | Sí. Compatible (XML y no XML) |
| Acceso a archivos en la nube (Azure Blob Storage, ADLS Gen2, S3) | Sí. Admitido mediante el parámetro DATA_SOURCE (SQL Server 2017 (14.x) y versiones posteriores, Azure SQL) |
Sí. Se admite
mediante el parámetro DATA_SOURCE o la URL en línea con la cláusula FORMAT
(SQL Server 2022 (16.x) y versiones posteriores, Azure SQL) |
| Archivos Parquet o Delta | No está soportado. Solo texto CSV/delimitado | Sí. Compatible con FORMAT = 'PARQUET' o FORMAT = 'DELTA' (SQL Server 2022 (16.x) y versiones posteriores, Azure SQL) |
| Permiso necesario |
ADMINISTER BULK OPERATIONS o ADMINISTER DATABASE BULK OPERATIONS, más INSERT en la tabla de destino |
ADMINISTER BULK OPERATIONS o ADMINISTER DATABASE BULK OPERATIONS |
| Registro mínimo | Sí. Compatible con modelos de recuperación simples o optimizados para cargas masivas con TABLOCK |
Sí. Se admite cuando se usa con INSERT ... SELECT y TABLOCK |
Cuándo elegir BULK INSERT
Use BULK INSERT cuando tenga una carga sencilla de archivos a tabla y no sea necesario transformar, filtrar ni unir datos durante la importación. Usa una sintaxis más sencilla para CSV u otros archivos delimitados:
En esta consulta de ejemplo se carga un archivo CSV de Azure Blob Storage directamente en una tabla.
BULK INSERT Sales.Invoices
FROM 'invoices/inv-2025-01.csv'
WITH (
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n'
);
En esta consulta de ejemplo se carga un archivo local con un archivo de formato para la asignación de columnas.
BULK INSERT dbo.Products
FROM 'C:\Data\products.csv'
WITH (
FORMATFILE = 'C:\Data\products.fmt',
FIRSTROW = 2,
TABLOCK
);
Cuándo elegir OPENROWSET(BULK)
Use OPENROWSET(BULK ...) cuando necesite una o varias de las condiciones siguientes:
- Consulte o obtenga una vista previa de los datos de archivo sin crear primero una tabla.
- Transformar, filtrar o combinar datos durante la importación.
-
Cargar archivos Parquet o Delta (solo
OPENROWSETadmite estos formatos). -
Importe un archivo completo como un único valor loB (
SINGLE_BLOB,SINGLE_CLOB,SINGLE_NCLOB).
En esta consulta de ejemplo se obtiene una vista previa de un archivo CSV de Azure Blob Storage sin insertar los datos en ningún lugar.
SELECT TOP 10 *
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2,
FIELDTERMINATOR = ','
) AS src;
En esta consulta de ejemplo se insertan datos con transformación y filtrado.
INSERT INTO Sales.Invoices (InvoiceDate, Amount, Customer)
SELECT CAST (InvoiceDate AS DATE),
Amount * 1.1, -- Apply a 10% markup
UPPER(Customer)
FROM OPENROWSET (
BULK 'invoices/inv-2025-01.csv',
DATA_SOURCE = 'MyAzureBlobStorage',
FORMAT = 'CSV',
FIRSTROW = 2
) WITH (
InvoiceDate VARCHAR (10),
Amount DECIMAL (18, 2),
Customer VARCHAR (100)
) AS src
WHERE Amount IS NOT NULL;
Esta consulta de ejemplo carga un archivo Parquet (no es posible con BULK INSERT).
INSERT INTO Sales.Invoices
SELECT *
FROM OPENROWSET (
BULK 'data/invoices/*.parquet',
DATA_SOURCE = 'MyAzureStorage',
FORMAT = 'PARQUET') AS src;
En esta consulta de ejemplo se importa un archivo XML completo como un único valor varbinary(max).
INSERT INTO dbo.XmlDocuments (DocContent)
SELECT BulkColumn
FROM OPENROWSET (
BULK 'C:\Data\catalog.xml',
SINGLE_BLOB
) AS x;
Sugerencia
Un enfoque consiste en empezar con OPENROWSET(BULK ...) en SELECT para explorar y validar los datos de archivo y, a continuación, cambiar a BULK INSERT para la carga de producción final si no necesita transformaciones. Si necesita compatibilidad con Parquet o Delta o filtrado en línea, manténgase con OPENROWSET.
Para obtener más información, consulte las siguientes guías relacionadas:
- Utilizar BULK INSERT o OPENROWSET(BULK...) para importar datos a SQL Server: una guía detallada en paralelo con consideraciones de seguridad.
-
Importación y exportación masiva de datos (SQL Server): información general de todos los métodos de movimiento de datos masivos (bcp,
BULK INSERT,OPENROWSET). - BULK INSERT (Transact-SQL): referencia completa de T-SQL.
- OPENROWSET BULK (Transact-SQL): referencia completa de T-SQL.
- Ejemplos de acceso masivo a datos en Azure Blob Storage: ejemplos en paralelo mediante ambos métodos con Azure Storage.
-
Importación masiva de datos de objetos grandes con OPENROWSET Bulk Rowset Provider (SQL Server):
SINGLE_BLOB,SINGLE_CLOBySINGLE_NCLOBejemplos. - Utilizar un archivo de formato para importar datos masivamente (SQL Server): Uso de archivos de formato con ambos métodos.
Funciones de metadatos útiles
Al consultar archivos externos con OPENROWSET o tablas externas, puede usar varias funciones y procedimientos integrados para inspeccionar metadatos de archivos, descubrir esquemas e implementar consultas optimizadas para particiones.
filepath() y filename()
Las filepath() funciones y filename() devuelven partes de la ruta de acceso del archivo o el nombre de archivo para cada fila del conjunto de resultados. Son especialmente útiles para:
Eliminación de particiones: filtre por segmentos de carpeta (por ejemplo, particiones de año/mes/día) para que el motor lea solo los archivos coincidentes en lugar de examinar todo.
Exponer metadatos de origen: incluya el nombre de archivo o la ruta de acceso de origen como una columna en los resultados de la consulta, lo que resulta útil para la auditoría o la depuración.
| Function | Devoluciones | Ejemplo |
|---|---|---|
filename() |
Nombre de archivo (incluida la extensión) del archivo de origen para cada fila | sales_2025_01.parquet |
filepath(N) |
El Nº segmento de carpeta desde el carácter comodín (*) en la ruta BULK, donde N comienza en 1 |
Para la ruta de acceso sales/2025/01/*.parquet, filepath(1) devuelve 2025, filepath(2) devuelve 01 |
Se aplica a: Azure SQL Database, Azure SQL Managed Instance, SQL Server 2022 (16.x) y versiones posteriores, SQL Database in Fabric.
En esta consulta de ejemplo se usa filepath() para la eliminación de particiones y filename() para identificar los archivos de origen. Solo lee los archivos de la /2025/ carpeta y solo lee los archivos de la /06/ subcarpeta.
SELECT result.filename() AS SourceFile,
result.filepath(1) AS [Year],
result.filepath(2) AS [Month],
*
FROM OPENROWSET (
BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*/*/*.parquet',
FORMAT = 'PARQUET'
) AS result
WHERE result.filepath(1) = '2025'
AND result.filepath(2) = '06';
Sugerencia
Coloque los filtros filepath() en la cláusula WHERE en lugar de en una subconsulta o CTE. Cuando el filtro está en la WHERE cláusula, el motor es capaz de realizar la eliminación de particiones a nivel de escaneo de archivos, lo que reduce significativamente la E/S.
sp_describe_first_result_set: detección de tipos de columna OPENROWSET
Cuando se usa OPENROWSET con archivos Parquet, el motor deduce automáticamente los tipos de datos de columna (inferencia de esquema). Los tipos inferidos pueden ser mayores de lo necesario. Por ejemplo, las columnas de caracteres a menudo se deducen como varchar(8000) porque los metadatos de Parquet no incluyen una longitud máxima. Esta opción puede degradar el rendimiento y consumir más memoria.
Use sp_describe_first_result_set para inspeccionar el esquema inferido antes de finalizar la consulta. Después de ver los tipos inferidos, especifique tipos más estrechos en una WITH cláusula para mejorar el rendimiento.
Paso 1: Inspeccionar el esquema inferido.
EXECUTE sp_describe_first_result_set N' SELECT * FROM OPENROWSET( BULK ''abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet'', FORMAT = ''PARQUET'' ) AS result';La salida muestra el nombre de cada columna, el tipo de datos inferido, la longitud máxima, la precisión y la escala. Si ve varchar(8000) donde bastaría un varchar(100), cámbielo:
Paso 2: Usar tipos explícitos para mejorar el rendimiento.
SELECT TOP 100 * FROM OPENROWSET ( BULK 'abs://mycontainer@mystorageaccount.blob.core.windows.net/data/sales/*.parquet', FORMAT = 'PARQUET' ) WITH ( OrderId INT, OrderDate DATE, Amount DECIMAL (18, 2), Customer VARCHAR (100) -- much narrower than the inferred varchar(8000) ) AS result;
La inferencia de esquema solo funciona con archivos Parquet. Para los archivos CSV, siempre especifique las definiciones de columna en una WITH cláusula (para OPENROWSET) o en la CREATE EXTERNAL TABLE instrucción.
sp_describe_first_result_set es un procedimiento general de SQL Server y Azure SQL, aunque es especialmente útil para las consultas de OPENROWSET. Para más información, véase sp_describe_first_result_set.
Rendimiento, solución de problemas y procedimientos recomendados
Después de implementar la virtualización de datos, use estas guías para optimizar el rendimiento, diagnosticar problemas y garantizar la preparación de producción:
| Area | Artículo | Detalles |
|---|---|---|
| Rendimiento de PolyBase | Consideraciones de rendimiento en PolyBase para SQL Server | Estadísticas, delegación, paralelismo y administración de memoria |
| Cálculo de inserciones | Computaciones delegadas en PolyBase | Especifica qué operaciones se suben al origen remoto. |
| Cómo saber si se produjo el empuje | Cómo saber si se ha producido un empuje externo | Planes de consulta y DMV |
| Solución de problemas | Supervisión y solución de problemas de PolyBase | Errores comunes y soluciones |
| Conectividad Kerberos | Solución de problemas de conectividad de Kerberos con PolyBase | |
| Preguntas más frecuentes | Preguntas más frecuentes sobre PolyBase | |
| Errores y soluciones | Errores de PolyBase y posibles soluciones |