Definición de casos de uso para flujos de datos
Los flujos de datos de Power BI permiten crear tablas de datos reutilizables en un área de trabajo mediante Power Query en línea y compartirlas para usarlas en otros informes y con otros usuarios para su reutilización en otras áreas de trabajo. Los flujos de datos son objetos de un área de trabajo junto con los conjuntos de datos, los paneles, los informes y los libros. Cuando se actualiza un flujo de datos de Power BI, este carga en segundo plano los datos en archivos ubicados en un lago de datos, Azure Data Lake Storage Gen 2 (ADLS Gen 2).
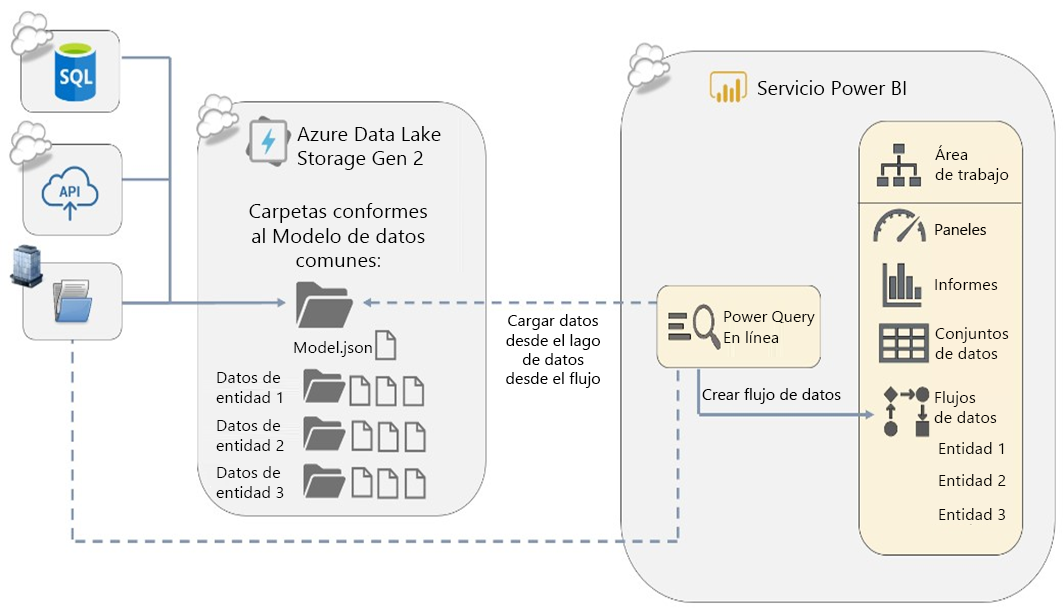
Los flujos de datos de Power BI se deben usar en la capacidad Premium para las soluciones empresariales, para aprovechar las ventajas de características como el proceso avanzado, la actualización incremental y las entidades vinculadas y calculadas.
Nota:
Los flujos de datos están admitidos para usuarios de Power BI Pro, Premium por usuario (PPU) y Power BI Premium. Obtenga más información sobre las características solo Premium de los flujos de datos.
Los datos que se usan con Power BI se almacenan en el almacenamiento interno proporcionado por Power BI de forma predeterminada. Con la integración de los flujos de datos y Azure Data Lake Storage Gen 2 (ADLS Gen2), puede almacenar los flujos de datos en la cuenta de Azure Data Lake Storage Gen2 de la organización. Esto le permite básicamente "traer su propio almacenamiento" para flujos de datos de Power BI y establecer una conexión en el nivel de inquilino o de área de trabajo.
¿Por qué usar flujos de datos?
Los flujos de datos se diseñaron para promover la lógica ETL reutilizable que evita la necesidad de crear conexiones adicionales al origen de datos.
Los flujos de datos son una opción ideal si:
- No hay ningún almacenamiento de datos en la organización.
- Quiere ampliar un conjunto de datos o datos principales en el almacenamiento de datos con datos coherentes.
- Los usuarios de autoservicio necesitan acceso frecuente a un subconjunto actualizado de datos del almacenamiento de datos sin tener acceso al propio almacenamiento de datos.
- Tiene orígenes de datos más lentos.
- Los flujos de datos extraen los datos una vez y los reutilizan varias veces, lo que puede reducir el tiempo de actualización general de los datos para los orígenes de datos más lentos.
- Las entidades calculadas pueden ser más rápidas que hacer referencia a consultas con el motor de proceso mejorado.
- Tiene orígenes de datos por los que se cobra.
- Los flujos de datos pueden reducir los costos asociados a la actualización de datos si obtiene datos de orígenes de datos por los que se cobra.
- Los flujos de datos aumentan el control y reducen el número de llamadas al sistema de origen.
- Los conjuntos de datos se actualizan en los flujos de datos sin afectar a los sistemas de origen.
- Tiene diferentes versiones de los conjuntos de datos en uso en la organización. Los flujos de datos aumentan la coherencia entre los conjuntos de datos.
- Mayor coherencia estructural al reducir la posibilidad de que los usuarios preparen los datos de forma diferente
- Mayor coherencia temporal al tener un único conjunto de datos extraídos de los sistemas de origen en un único momento dado
- Se pueden estandarizar en toda la organización las tablas compartidas que no tienen ningún origen, como una dimensión de fecha estándar.
- Quiere reducir u ocultar la complejidad de los orígenes de datos.
- Puede exponer entidades de datos comunes para grupos más grandes de analistas que ya se han transformado y simplificado.
- También puede crear particiones de los datos horizontalmente mediante varios flujos de datos. Por ejemplo, los flujos de datos ascendentes contienen todos los datos y solo están disponibles para un pequeño grupo de usuarios. Los flujos de datos descendentes contienen subconjuntos mantenidos de datos y se pueden poner a disposición de los miembros de los grupos de seguridad adecuados.
Beneficios y limitaciones
Aunque hay importantes ventajas en el uso de flujos de datos en el diseño del conjunto de datos, también hay algunas limitaciones que los usuarios deben tener en cuenta.
Ventajas:
- Carga reducida en las consultas de base de datos.
- Número reducido de usuarios que acceden a los datos de origen.
- Proporciona una sola versión de los datos estructurados correctamente para que los analistas creen informes.
Limitaciones:
- No es una sustitución de un almacenamiento de datos.
- No se admite la seguridad de nivel de fila.
- Si los flujos de datos no se usan en la capacidad Premium, el rendimiento puede ser un problema.
Importante
Consulte Consideraciones y limitaciones de flujos de datos para obtener una lista completa de consideraciones y limitaciones.
Flujos de datos en Power BI Premium
Power BI Premium se diseñó para implementaciones empresariales. Las características de flujos de datos disponibles en la capacidad Premium ofrecen ventajas de rendimiento considerables e incluyen el uso de:
- Motor de proceso mejorado
- DirectQuery
- Entidades calculadas
- Entidades vinculadas
- Actualización incremental
Optimización de flujos de datos mediante el motor de proceso mejorado
El motor de proceso mejorado en los flujos de datos de Power BI permite optimizar el uso de flujos de datos mediante:
- Aceleración de las operaciones de actualización cuando intervienen entidades calculadas o entidades vinculadas (por ejemplo, realizar combinaciones, usar cláusulas distinct y filtros, y agrupar por).
- Habilitación de la conectividad de DirectQuery en los flujos de datos mediante el motor de proceso.
- Consiga un rendimiento mejorado en los pasos de transformación de los flujos de datos cuando las entidades se almacenan en caché en el motor de proceso.
Sugerencia
Obtenga más información en Características prémium de flujos de datos.
Distinción entre flujos de datos
Quizás también haya oído hablar de los flujos de datos de Azure Data Factory y se pregunta cuál es el mejor tipo de flujo de datos para su uso en su escenario.
A menudo, se considera que los flujos de datos de Power BI y los flujos de datos de limpieza y transformación de Azure Data Factory (ADF) hacen lo mismo: extraer los datos de los sistemas de origen, transformar los datos y cargar los datos transformados en un destino. Ambos tienen la tecnología de Power Query en línea, pero hay diferencias en estos dos tipos de flujos de datos. Puede implementar una solución que funcione con una combinación de los dos.
Cuándo usar flujos de datos de limpieza y transformación de ADF o flujos de datos de Power BI
La transformación de datos siempre se debe realizar lo más cerca posible del origen. Si la solución de análisis incluye Azure Data Factory y tiene las aptitudes para implementar transformaciones ascendentes de Power BI, debe hacerlo.
| Características | Flujos de datos de Power BI | Flujos de datos de limpieza y transformación de Data Factory |
|---|---|---|
| Destinos | Dataverse o Azure Data Lake Storage | Muchos destinos |
| Transformación de Power Query | Se admiten todas las funciones de Power Query. | Se admite un conjunto limitado de funciones. |
| Orígenes | Se admiten muchos orígenes. | Solo unos pocos orígenes |
| Escalabilidad | Depende de la capacidad Premium y del uso del motor de proceso mejorado | Altamente escalable |
Sugerencia
Obtenga más información sobre cómo se relacionan entre sí los flujos de datos de Microsoft Power Platform y los flujos de datos de limpieza y transformación de Azure Data Factory.