Diseño de una solución de integración de datos con Azure Data Lake
Un data lake es un repositorio de datos almacenados en su formato natural, normalmente como blobs o archivos. Azure Data Lake Storage es una solución completa, escalable y rentable para el análisis de macrodatos integrado en Azure. Azure Data Lake Storage combina un sistema de archivos con una plataforma de almacenamiento para ayudarle a identificar rápidamente la información sobre los datos. La solución se basa en Azure Blob Storage funcionalidades para proporcionar optimizaciones para cargas de trabajo de análisis. Esta integración permite el rendimiento de análisis, la alta disponibilidad, la seguridad y las funcionalidades de durabilidad de Azure Storage. En este vídeo, no se proporciona la demostración.
Importante
Azure Data Lake Storage Gen1 fue retirado el 29 de febrero de 2024. Las cuentas de Gen1 existentes ya no son accesibles y no se pueden crear cuentas nuevas. Esta unidad cubre Azure Data Lake Storage Gen2 exclusivamente.
Cosas que se deben saber sobre Azure Data Lake Storage
Para comprender mejor Azure Data Lake Storage, examinemos las siguientes características.
Azure Data Lake Storage puede almacenar cualquier tipo de datos mediante el formato nativo de los datos. Con compatibilidad con cualquier formato de datos y tamaños de datos masivos, Azure Data Lake Storage puede trabajar con datos estructurados, semiestructurados y no estructurados.
La solución está diseñada principalmente para trabajar con Hadoop y todos los marcos que usan Sistema de archivos distribuido (HDFS) de Apache Hadoop como capa de acceso a los datos. Los marcos de análisis de datos que usan HDFS como capa de acceso a datos pueden acceder directamente.
Azure Data Lake Storage admite un alto rendimiento para el análisis intensivo de entrada y salida y el movimiento de datos.
El modelo de control de acceso de Azure Data Lake Storage admite tanto el control de acceso basado en roles de Azure (RBAC) como las listas de control de acceso (ACL) de la Interfaz Portátil de Sistemas Operativos para UNIX (POSIX).
Azure Data Lake Storage utiliza Azure modelos de replicación de blobs. Estos modelos admiten las mismas opciones de redundancia disponibles para Azure Blob Storage. Microsoft recomienda ZRS para cargas de trabajo de Azure Data Lake Storage.
Azure Data Lake Storage ofrece almacenamiento masivo y acepta numerosos tipos de datos para el análisis.
Azure Data Lake Storage tiene precios alineados a los niveles de Azure Blob Storage.
Funcionamiento de Azure Data Lake Storage
Hay tres pasos importantes para usar Azure Data Lake Storage:
Ingesta de datos. Azure Data Lake Storage ofrece muchos métodos de ingesta de datos diferentes:
- Para los datos no planeados, puede usar herramientas como AzCopy, el CLI de Azure, PowerShell y Explorador de Azure Storage.
- En el caso de los datos relacionales, se puede usar el servicio Azure Data Factory. Puede transferir datos desde cualquier origen, como Azure Cosmos DB, SQL Database, Azure SQL instancias administradas, etc.
- Para los datos de streaming, puede usar herramientas como Apache Storm en Azure HDInsight, Azure Stream Analytics, etc.
En el siguiente diagrama se muestra cómo los datos no planeados y los datos de streaming son ingeridos de manera masiva o de forma no planeada en Azure Data Lake Storage.
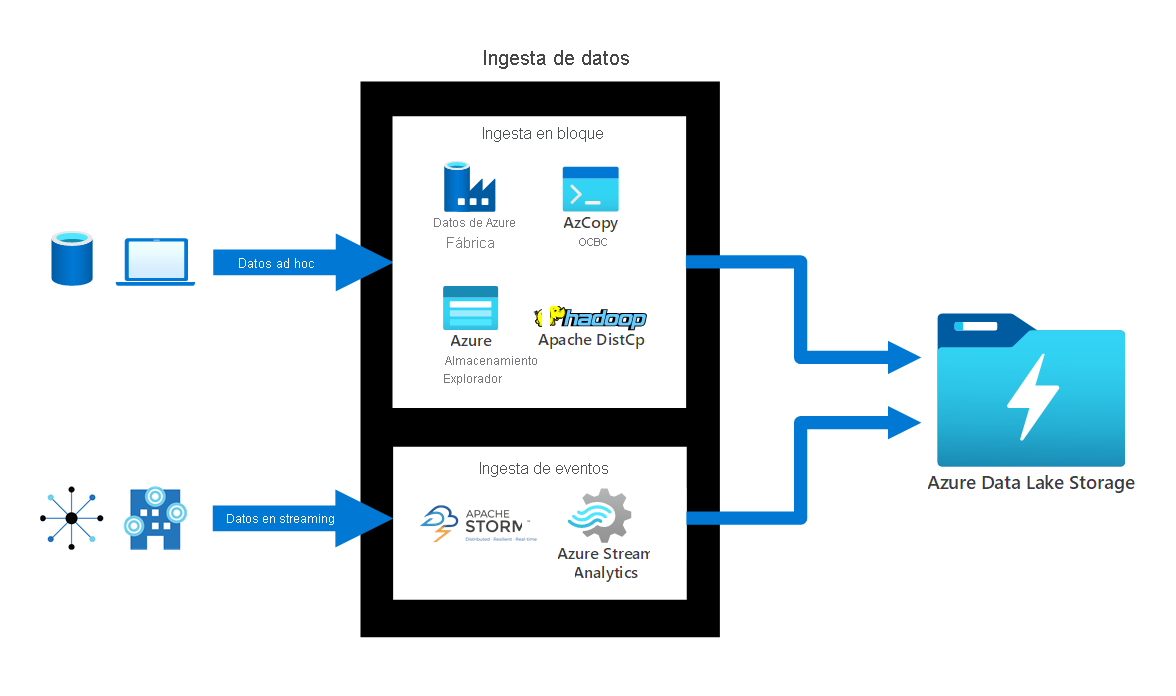
Acceso a los datos almacenados. La manera más fácil de acceder a los datos es usar Explorador de Azure Storage. Explorador de Storage es una aplicación independiente con una interfaz gráfica de usuario (GUI) para acceder a los datos de Azure Data Lake Storage. También puede usar PowerShell, el CLI de Azure, la CLI de HDFS u otros SDK de lenguaje de programación para acceder a los datos.
Configuración del control de acceso. Controlar quién puede acceder a los datos almacenados en Azure Data Lake Storage mediante la implementación de un mecanismo de autorización. Puede elegir Azure RBAC o ACL.
Escenario empresarial
Tailwind Traders cuenta con diversos orígenes de datos, como sitios web, sistemas de punto de venta (POS), redes sociales y dispositivos IoT (Internet de las cosas). La empresa está interesada en usar Azure para analizar todos sus datos empresariales. Tiene la tarea de proporcionar instrucciones sobre cómo Azure puede mejorar sus sistemas de BI existentes. Debe asesorar al equipo sobre cómo Azure funcionalidades de almacenamiento pueden agregar valor a la solución de BI de la empresa. Para cumplir los requisitos de datos, tiene previsto recomendar Azure Data Lake Storage. Data Lake Storage proporciona un repositorio donde puede cargar y almacenar grandes cantidades de datos no estructurados con un ojo hacia el análisis de macrodatos de alto rendimiento.
Vamos a revisar cómo Azure Data Lake Storage puede ser la opción adecuada para los requisitos de macrodatos de la organización.
| Escenario | Solución |
|---|---|
| Provisión de un almacenamiento de datos en la nube para administrar grandes volúmenes de datos. | Azure Data Lake Storage se ejecuta en hardware virtual en la plataforma Azure. El almacenamiento es escalable, rápido y confiable sin incurrir en cargos masivos. Separa los costos de almacenamiento de los costos de proceso. A medida que crece el volumen de datos, solo cambian los requisitos de almacenamiento. |
| Admite una colección variada de tipos de datos, como archivos JSON, CSV, archivos de registro u otros formatos diversos. | Azure Data Lake Storage permite la democratización de los datos para su organización almacenando todos los formatos de datos (incluidos los datos sin procesar) en una sola ubicación. Al eliminar los silos de datos, los usuarios pueden usar herramientas como Azure Data Explorer para acceder a todos los elementos de datos de su cuenta de almacenamiento y trabajar con ellos. |
| Posibilidad de almacenamiento e ingesta de datos en tiempo real. | Azure Data Lake Storage puede ingerir datos en tiempo real directamente desde una instancia de Apache Storm en Azure HDInsight, Azure IoT Hub, Azure Event Hubs o Azure Stream Analytics. También funciona con datos semiestructurados y permite ingerir todos los datos en tiempo real en la cuenta de almacenamiento. |
Aspectos que se deben tener en cuenta al elegir Azure Blob Storage o Azure Data Lake
En la tabla siguiente se comparan los criterios de solución de almacenamiento para usar Azure Blob Storage frente a Azure Data Lake. Revise los criterios y considere cuál es la solución óptima para Tailwind Traders.
| Comparación | Azure Data Lake | Azure Blob Storage |
|---|---|---|
| Tipos de datos | Conveniente para almacenar grandes volúmenes de datos de texto | Adecuado para almacenar datos no estructurados no basados en texto, como fotos, vídeos y copias de seguridad |
| Redundancia geográfica | Debe configurar manualmente la replicación de datos | De forma predeterminada, proporciona almacenamiento con redundancia geográfica |
| Espacios de nombres | Compatibilidad con espacios de nombres jerárquicos | Compatibilidad con espacios de nombres planos |
| Compatibilidad con Hadoop | Los servicios de Hadoop pueden usar datos almacenados en Azure Data Lake | Mediante el uso del Azure Blob Filesystem Driver, las aplicaciones y los frameworks pueden acceder a los datos en Azure Blob Storage. |
| Seguridad | Admite el acceso pormenorizado | No admite el acceso pormenorizado |
Sugerencia
Obtenga más información con el entrenamiento autodirigido, Introducción a Azure Data Lake Storage Gen2.