Diseño de un esquema de almacenamiento de datos
Al igual que todas las bases de datos relacionales, un almacenamiento de datos contiene tablas en las que se almacenan los datos que quiere analizar. Normalmente, estas tablas se organizan en un esquema optimizado para el modelado multidimensional, en el que las medidas numéricas asociadas a eventos conocidos como hechos se pueden agregar mediante los atributos de las entidades asociadas en varias dimensiones. Por ejemplo, las medidas asociadas a un pedido de venta (como el importe pagado o la cantidad de artículos solicitados) se pueden agregar por los atributos de la fecha en que se produjo la venta, el cliente, la tienda, etc.
Tablas de un almacenamiento de datos
Un patrón común para almacenes de datos relacionales es definir un esquema que incluya dos tipos de tabla: tablas de dimensiones y tablas de hechos.
Tablas de dimensiones
Las tablas de dimensiones describen entidades empresariales, como productos, personas, lugares y fechas. Las tablas de dimensiones contienen columnas para los atributos de una entidad. Por ejemplo, una entidad de cliente podría tener un nombre, un apellido, una dirección de correo electrónico y una dirección postal (que podría constar de la calle, la ciudad, el código postal y el país o región). Además de las columnas de atributos, una tabla de dimensiones contiene una columna de clave única que identifica de forma única cada fila de la tabla. De hecho, es habitual que una tabla de dimensiones incluya dos columnas de clave:
- Una clave suplente que es específica del almacenamiento de datos e identifica de forma única cada fila de la tabla de dimensiones del almacenamiento de datos, normalmente un número entero incremental.
- Una clave alternativa, a menudo una clave natural o empresarial que se usa para identificar una instancia específica de una entidad en el sistema de origen transaccional del que se originó el registro de entidad, como un código de producto o un identificador de cliente.
Nota
¿Por qué tiene dos claves? Hay algunas buenas razones:
- El almacenamiento de datos se puede rellenar con datos de varios sistemas de origen, lo que puede provocar el riesgo de claves empresariales duplicadas o incompatibles.
- Por lo general, las claves numéricas simples funcionan mejor en las consultas que unen muchas tablas: un patrón común en los almacenamientos de datos.
- Los atributos de las entidades pueden cambiar con el tiempo; por ejemplo, un cliente podría cambiar su dirección. Dado que el almacenamiento de datos se usa para admitir informes históricos, es posible que quiera conservar un registro de cada instancia de una entidad en varios puntos en el tiempo; de modo que, por ejemplo, los pedidos de venta de un cliente específico se contabilicen por la ciudad donde vivió en el momento en que se realizó el pedido. En este caso, varios registros de cliente tendrían la misma clave empresarial asociada al cliente, pero claves suplentes diferentes para cada dirección discreta en la que el cliente vivió en diversos momentos.
Un ejemplo de una tabla de dimensiones para clientes podría contener los datos siguientes:
| CustomerKey | CustomerAltKey | Nombre | Calle | Ciudad | Código postal | CountryRegion | |
|---|---|---|---|---|---|---|---|
| 123 | I-543 | Navin Jones | navin1@contoso.com | 1 Main St. | Seattle | 90000 | Estados Unidos |
| 124 | R-589 | Mary Smith | mary2@contoso.com | 234 190th Ave | Buffalo | 50001 | Estados Unidos |
| 125 | I-321 | Antoine Dubois | antoine1@contoso.com | 2 Rue Jolie | Paris | 20098 | Francia |
| 126 | I-543 | Navin Jones | navin1@contoso.com | 24 125th Ave. | Nueva York | 50000 | Estados Unidos |
| ... | ... | ... | ... | ... | ... | ... | ... |
Nota
Observe que la tabla contiene dos registros para Navin Jones. Ambos registros usan la misma clave alternativa para identificar a esta persona (I-543), pero cada registro tiene una clave suplente diferente. A partir de aquí, puede suponer que el cliente se trasladó de Seattle a Nueva York. Las ventas realizadas al cliente mientras vive en Seattle están asociadas a la clave 123, mientras que las compras realizadas después de trasladarse a Nueva York se anotan en el registro 126.
Además de las tablas de dimensiones que representan entidades empresariales, es habitual que un almacenamiento de datos incluya una tabla de dimensiones que represente el tiempo. Esta tabla permite a los analistas de datos agregar datos a intervalos temporales. Dependiendo del tipo de datos que necesite analizar, la granularidad más baja (denominada intervalo de agregación) de una dimensión temporal podría representar horas (hasta la hora, segundo, milisegundos, nanosegundos o incluso menos) o fechas.
Un ejemplo de una tabla de dimensiones de tiempo con un intervalo de agregación en el nivel de fecha puede contener los datos siguientes:
| DateKey | DateAltKey | DayOfWeek | DayOfMonth | Día de la semana | Month | MonthName | Quarter (Trimestre) | Year |
|---|---|---|---|---|---|---|---|---|
| 19990101 | 01-01-1999 | 6 | 1 | Viernes | 1 | January | 1 | 1999 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20220101 | 01-01-2022 | 7 | 1 | Sábado | 1 | January | 1 | 2022 |
| 20220102 | 02-01-2022 | 1 | 2 | Domingo | 1 | January | 1 | 2022 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20301231 | 31-12-2030 | 3 | 31 | Martes | 12 | Diciembre | 4 | 2030 |
El intervalo de tiempo cubierto por los registros de la tabla debe incluir los puntos más antiguos y más recientes en el tiempo de los eventos asociados registrados en una tabla de hechos relacionada. Normalmente, hay un registro entre medias por cada intervalo en el intervalo de agregación adecuado.
Tablas de hechos
Las tablas de hechos almacenan detalles de observaciones o eventos, por ejemplo, pedidos de ventas, existencias, tipos de cambio o temperaturas registradas. Una tabla de hechos contiene columnas para valores numéricos que pueden agregarse por las dimensiones. Además de las columnas numéricas, una tabla de hechos contiene columnas de clave que hacen referencia a claves únicas en tablas de dimensiones relacionadas.
Por ejemplo, una tabla de hechos que contiene detalles de pedidos de ventas puede contener los datos siguientes:
| OrderDateKey | CustomerKey | ClaveTienda | ProductKey | OrderNo | LineItemNo | Quantity | UnitPrice | Impuesto | ItemTotal |
|---|---|---|---|---|---|---|---|---|---|
| 20220101 | 123 | 5 | 701 | 1001 | 1 | 2 | 2,50 | 0,50 | 5.50 |
| 20220101 | 123 | 5 | 765 | 1001 | 2 | 1 | 2,00 | 0,20 | 2,20 |
| 20220102 | 125 | 2 | 723 | 1002 | 1 | 1 | 4,99 | 0,49 | 5.48 |
| 20220103 | 126 | 1 | 823 | 1003 | 1 | 1 | 7,99 | 0.80 | 8.79 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
Las columnas de clave de dimensión de una tabla de hechos determinan su intervalo de agregación. Por ejemplo, la tabla de hechos de pedidos de venta incluye claves para fechas, clientes, tiendas y productos. Un pedido puede incluir varios productos, por lo que el intervalo de agregación representa artículos de línea para productos individuales vendidos en tiendas a clientes en días específicos.
Diseños de esquemas de almacenamiento de datos
En la mayoría de las bases de datos transaccionales que se usan en aplicaciones empresariales, los datos se normalizan para reducir la duplicación. Sin embargo, en un almacenamiento de datos, los datos de dimensión generalmente se desnormalizan para reducir el número de combinaciones necesarias para consultar los datos.
A menudo, un almacenamiento de datos se organiza como un esquema de estrella, en el que una tabla de hechos está directamente relacionada con las tablas de dimensiones, como se muestra en este ejemplo:
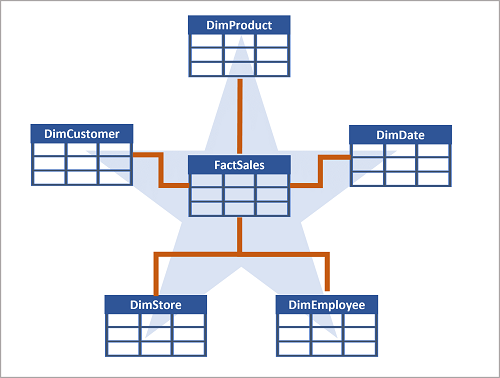
Los atributos de una entidad se pueden usar para agregar medidas en tablas de hechos en varios niveles jerárquicos, por ejemplo, para buscar los ingresos totales de ventas por país o región, ciudad, código postal o cliente. Los atributos de cada nivel se pueden almacenar en la misma tabla de dimensiones. Sin embargo, cuando una entidad tiene un gran número de niveles de atributo jerárquicos, o cuando algunos atributos se pueden compartir mediante varias dimensiones (por ejemplo, los clientes y las tiendas tienen una dirección geográfica), puede tener sentido aplicar cierta normalización a las tablas de dimensiones y crear un esquema de copo de nieve, como se muestra en el ejemplo siguiente:

En este caso, la tabla DimProduct se ha normalizado para crear tablas de dimensiones independientes para las categorías de producto y los proveedores, y se ha agregado una tabla DimGeography para representar atributos geográficos de los clientes y las tiendas. Cada fila de la tabla DimProduct contiene valores de clave para las filas correspondientes de las tablas DimCategory y DimSupplier; y cada fila de las tablas DimCustomer y DimStore contiene un valor de clave para la fila correspondiente de la tabla DimGeography.